One LR Doesn't Fit All: Heavy-Tail Guided Layerwise Learning Rates for LLMs
Pith reviewed 2026-05-22 07:40 UTC · model grok-4.3
The pith
Different learning rates for different Transformer layers, set by how heavy-tailed their weights are, speed up training and raise accuracy in LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By quantifying the heavy-tailedness of each layer's empirical spectral density using Heavy-Tailed Self-Regularization theory, one can assign larger learning rates to layers with weaker heavy-tailedness and smaller ones to layers with stronger heavy-tailedness. This layer-specific adjustment promotes more balanced training dynamics, resulting in up to 1.5 times faster training and an increase in average zero-shot accuracy from 47.09% to 49.02% across various LLM architectures and optimizers.
What carries the argument
The Heavy-Tailed Self-Regularization (HT-SR) measure of empirical spectral density (ESD) heavy-tailedness for each layer's weight correlation matrix, used to derive per-layer learning rate multipliers that accelerate weaker layers and stabilize stronger ones.
If this is right
- Training time for LLMs can be reduced by up to 1.5x while maintaining or improving performance.
- Zero-shot accuracy improves by about 2 percentage points on average without changing the optimizer or architecture.
- Optimal per-layer rates can be transferred from a single uniform learning rate baseline with minimal additional search.
- Balanced convergence across layers reduces the risk of some layers lagging behind others in large models.
Where Pith is reading between the lines
- The approach could be extended to other architectures beyond Transformers if their layer weight matrices show similar spectral heterogeneity.
- Combining LLR with other adaptive methods like cosine scheduling might yield further gains, though this is not tested in the paper.
- If the HT-SR measure correlates with layer importance or depth, it might explain why certain layers benefit from higher rates.
Load-bearing premise
The assumption that the heavy-tailedness measure from the spectral density directly indicates how much to adjust the learning rate for each layer, and that this adjustment remains effective without needing recalibration for different runs or scales.
What would settle it
Running the same model training twice, once with uniform learning rate and once with LLR assigned by HT-SR, and finding no statistically significant difference in final accuracy or training speed would falsify the claim.
Figures











read the original abstract
Learning rate configuration is a fundamental aspect of modern deep learning. The prevailing practice of applying a uniform learning rate across all layers overlooks the structural heterogeneity of Transformers, potentially limiting their effectiveness as the backbone of Large Language Models (LLMs). In this paper, we introduce Layerwise Learning Rate (LLR), an adaptive scheme that assigns distinct learning rates to individual Transformer layers. Our method is grounded in Heavy-Tailed Self-Regularization (HT-SR) theory, which characterizes the empirical spectral density (ESD) of weight correlation matrices to quantify heavy-tailedness. Layers with weaker heavy-tailedness are assigned larger learning rates to accelerate their training, while layers with stronger heavy-tailedness receive smaller learning rates. By tailoring learning rates in this manner, LLR promotes balanced training across layers, leading to faster convergence and improved generalization. Extensive experiments across architectures (from LLaMA to GPT-nano), optimizers (AdamW and Muon), and parameter scales (60M-1B) demonstrate that LLR achieves up to 1.5x training speedup and outperforms baselines, notably raising average zero-shot accuracy from 47.09% to 49.02%. A key advantage of LLR is its low tuning overhead: it transfers nearly optimal LR settings directly from the uniform baseline. Code is available at https://github.com/hed-ucas/Layer-wise-Learning-Rate.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Layerwise Learning Rate (LLR), an adaptive per-layer learning rate scheme for Transformer-based LLMs. It leverages Heavy-Tailed Self-Regularization (HT-SR) theory to quantify the heavy-tailedness of the empirical spectral density (ESD) of each layer's weight correlation matrix. Layers exhibiting weaker heavy-tailedness receive larger learning rates to accelerate convergence, while those with stronger heavy-tailedness are assigned smaller rates. Experiments span architectures (LLaMA to GPT-nano), optimizers (AdamW, Muon), and scales (60M–1B parameters), reporting up to 1.5× training speedup and an increase in average zero-shot accuracy from 47.09% to 49.02%, with the practical benefit of transferring near-optimal settings from a single uniform-LR baseline run.
Significance. If the HT-SR-guided mapping from layer-wise heavy-tailedness to LR multipliers can be shown to be robust, near-optimal, and superior to generic heterogeneous schedules, the work would offer a principled, low-overhead approach to handling structural heterogeneity in large Transformers. The broad experimental coverage across models, optimizers, and scales, together with public code, provides a reproducible empirical basis that could influence practical LLM training pipelines.
major comments (2)
- [Experiments] Experiments section: No ablation isolates the specific HT-SR-to-LR mapping. Controls such as reversed assignment (stronger heavy-tailed ESD receiving larger LR), random per-layer multipliers sampled from the same range, or a learned mapping are absent. Without them the reported speedups and accuracy gains cannot be attributed to the heavy-tailedness signal rather than heterogeneity alone.
- [Method] Method and abstract: The precise functional form or selection procedure that converts the HT-SR heavy-tailedness metric into a per-layer LR multiplier is not specified in sufficient detail, nor is its stability across random seeds, optimizer choice, or model scale demonstrated. This mapping is load-bearing for the transferability claim.
minor comments (2)
- [Abstract] Abstract: The baseline against which the 47.09% to 49.02% zero-shot accuracy lift is measured should be stated explicitly, along with the precise set of tasks contributing to the average.
- [Results] Figures/tables: Layer-wise ESD heavy-tailedness values and the resulting LR multipliers should be tabulated or plotted for at least one representative model to allow direct inspection of the mapping.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important areas for strengthening the empirical validation and methodological clarity of our work. We address each major comment below and commit to incorporating the suggested improvements in the revised manuscript.
read point-by-point responses
-
Referee: [Experiments] Experiments section: No ablation isolates the specific HT-SR-to-LR mapping. Controls such as reversed assignment (stronger heavy-tailed ESD receiving larger LR), random per-layer multipliers sampled from the same range, or a learned mapping are absent. Without them the reported speedups and accuracy gains cannot be attributed to the heavy-tailedness signal rather than heterogeneity alone.
Authors: We agree that the current experiments do not fully isolate the contribution of the specific HT-SR-guided mapping from the general benefit of using heterogeneous learning rates. In the revision, we will add the requested ablation studies, including a reversed assignment (larger LRs for stronger heavy-tailed layers), random per-layer multipliers sampled from the same range as our method, and, if feasible within compute limits, a comparison against a learned mapping. These additions will allow us to more rigorously attribute the observed speedups and accuracy improvements to the heavy-tailedness signal. revision: yes
-
Referee: [Method] Method and abstract: The precise functional form or selection procedure that converts the HT-SR heavy-tailedness metric into a per-layer LR multiplier is not specified in sufficient detail, nor is its stability across random seeds, optimizer choice, or model scale demonstrated. This mapping is load-bearing for the transferability claim.
Authors: We acknowledge that the manuscript does not provide sufficient detail on the exact functional form or selection procedure used to derive per-layer LR multipliers from the HT-SR heavy-tailedness metric. In the revised version, we will expand the Method section to explicitly describe the computation of the metric from the ESD and the precise mapping rule (including any thresholds or scaling factors). We will also add results showing the stability of this mapping across multiple random seeds, both AdamW and Muon optimizers, and the full range of model scales (60M to 1B). These changes will better support the transferability claim. revision: yes
Circularity Check
No significant circularity; derivation applies external HT-SR measurements independently
full rationale
The paper grounds LLR in HT-SR theory by computing ESD heavy-tailedness on a uniform-LR baseline run and then assigning per-layer multipliers (weaker heavy-tailedness → larger LR). These multipliers are applied in a separate training run whose final accuracy and speedup are measured independently. No equation or step reduces the reported gains to a fit or definition drawn from the same data used for evaluation. The mapping rule is presented as a direct consequence of the cited theory rather than an ansatz fitted to target metrics or a self-citation chain that forbids alternatives. This is the common honest case of a self-contained method whose central claim rests on external measurements.
Axiom & Free-Parameter Ledger
free parameters (1)
- heavy-tailedness-to-LR mapping function
axioms (1)
- domain assumption Heavy-Tailed Self-Regularization theory correctly quantifies the training difficulty of a Transformer layer via the empirical spectral density of its weight correlation matrix.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
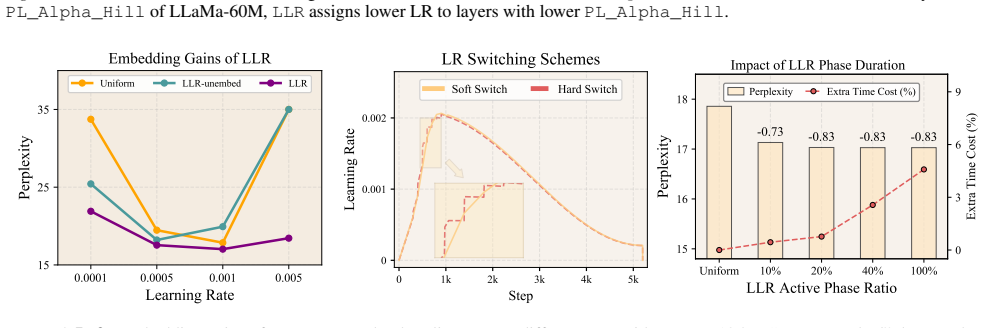
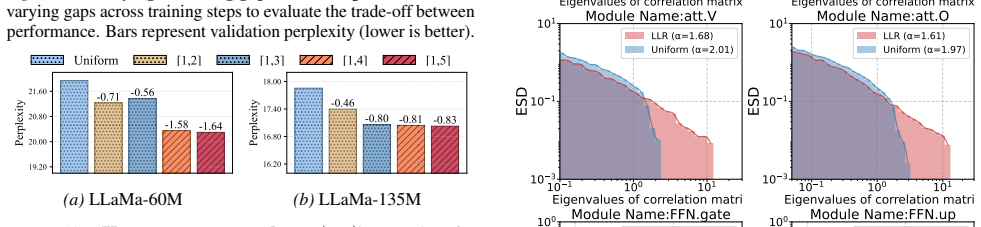
Layers with weaker heavy-tailedness are assigned larger learning rates... PL_Alpha_Hill... fT(i)=η·(αiT−αminT)/(αmaxT−αminT)(s−1)+1
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
grounded in Heavy-Tailed Self-Regularization (HT-SR) theory... ESD of weight correlation matrices
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Clark, P., Cowhey, I., Etzioni, O., Khot, T., Sabharwal, A., Schoenick, C., and Tafjord, O. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Dey, N., Zhang, B. C., Noci, L., Li, M., Bordelon, B., Bergsma, S., Pehlevan, C., Hanin, B., and Hestness, J. Don’t be lazy: Completep enables compute-efficient deep transformers.arXiv preprint arXiv:2505.01618,
-
[3]
Hayou, S. and Liu, L. Optimal embedding learning rate in llms: The effect of vocabulary size.arXiv preprint arXiv:2506.15025,
-
[4]
He, D., Jaiswal, A., Tu, S., Shen, L., Yuan, G., Liu, S., and Yin, L. Alphadecay: Module-wise weight de- cay for heavy-tailed balancing in llms.arXiv preprint arXiv:2506.14562,
-
[5]
Hoffmann, J., Borgeaud, S., Mensch, A., Buchatskaya, E., Cai, T., Rutherford, E., Casas, D. d. L., Hendricks, L. A., Welbl, J., Clark, A., et al. Training compute-optimal large language models.arXiv preprint arXiv:2203.15556,
work page internal anchor Pith review Pith/arXiv arXiv
- [6]
-
[7]
Muon is Scalable for LLM Training
Liu, J., Su, J., Yao, X., Jiang, Z., Lai, G., Du, Y ., Qin, Y ., Xu, W., Lu, E., Yan, J., et al. Muon is scalable for llm training.arXiv preprint arXiv:2502.16982,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Liu, Y ., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., Levy, O., Lewis, M., Zettlemoyer, L., and Stoyanov, V . Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692,
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[9]
Model balancing helps low-data training and fine-tuning
Liu, Z., Hu, Y ., Pang, T., Zhou, Y ., Ren, P., and Yang, Y . Model balancing helps low-data training and fine-tuning. arXiv preprint arXiv:2410.12178,
-
[10]
Decoupled Weight Decay Regularization
Loshchilov, I. and Hutter, F. Decoupled weight decay regu- larization.arXiv preprint arXiv:1711.05101,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Martin, C. H. and Mahoney, M. W. Traditional and heavy- tailed self regularization in neural network models.arXiv preprint arXiv:1901.08276,
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[12]
Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering
Mihaylov, T., Clark, P., Khot, T., and Sabharwal, A. Can a suit of armor conduct electricity? a new dataset for open book question answering.arXiv preprint arXiv:1809.02789,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale
URL https://arxiv.org/abs/ 2406.17557. Radford, A., Narasimhan, K., Salimans, T., Sutskever, I., et al. Improving language understanding by generative pre-training
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
SocialIQA: Commonsense Reasoning about Social Interactions
ISSN 0001-0782. doi: 10.1145/3474381. URL https: //doi.org/10.1145/3474381. Sap, M., Rashkin, H., Chen, D., LeBras, R., and Choi, Y . Socialiqa: Commonsense reasoning about social interac- tions.arXiv preprint arXiv:1904.09728,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1145/3474381 1904
-
[15]
Wang, J., Wang, M., Zhou, Z., Yan, J., Wu, L., et al. The sharpness disparity principle in transformers for ac- celerating language model pre-training.arXiv preprint arXiv:2502.19002,
- [16]
-
[17]
Large Batch Training of Convolutional Networks
You, Y ., Gitman, I., and Ginsburg, B. Large batch training of convolutional networks.arXiv preprint arXiv:1708.03888,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Large Batch Optimization for Deep Learning: Training BERT in 76 minutes
You, Y ., Li, J., Reddi, S., Hseu, J., Kumar, S., Bhojanapalli, S., Song, X., Demmel, J., Keutzer, K., and Hsieh, C.-J. Large batch optimization for deep learning: Training bert in 76 minutes.arXiv preprint arXiv:1904.00962,
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[19]
HellaSwag: Can a Machine Really Finish Your Sentence?
Zellers, R., Holtzman, A., Bisk, Y ., Farhadi, A., and Choi, Y . Hellaswag: Can a machine really finish your sentence? arXiv preprint arXiv:1905.07830,
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[20]
Zhang, Y ., Chen, C., Ding, T., Li, Z., Sun, R., and Luo, Z. Why transformers need adam: A hessian perspective. Advances in neural information processing systems, 37: 131786–131823, 2024a. Zhang, Y ., Chen, C., Li, Z., Ding, T., Wu, C., Kingma, D. P., Ye, Y ., Luo, Z.-Q., and Sun, R. Adam-mini: Use fewer learning rates to gain more.arXiv preprint arXiv:24...
-
[21]
11 One LR Doesn’t Fit All: Heavy-Tail Guided Layerwise Learning Rates for LLMs Appendix A. Details of Experiments This section provides detailed configurations for both pre- training and finetuning experiments. In Table 11 and Ta- ble 12, we present the architectural parameters of LLaMa models and the learning rate and weight decay settings for different ...
work page 2048
-
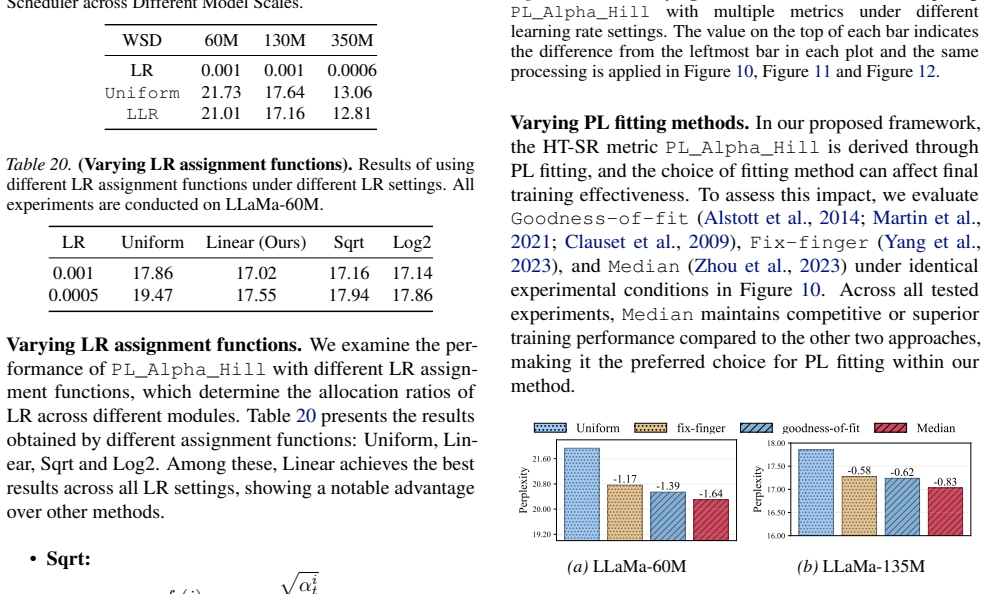
[22]
Varying PL fitting methods.In our proposed framework, the HT-SR metric PL_Alpha_Hill is derived through PL fitting, and the choice of fitting method can affect final training effectiveness. To assess this impact, we evaluate Goodness-of-fit (Alstott et al., 2014; Martin et al., 2021; Clauset et al., 2009), Fix-finger (Yang et al., 2023), and Median (Zhou et al.,
work page 2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.