Agent Skill Evaluation and Evolution: Frameworks and Benchmarks
Pith reviewed 2026-06-27 13:07 UTC · model grok-4.3
The pith
Agent skill development shifts from isolated creation to automated evaluation-driven evolution across four paradigms.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
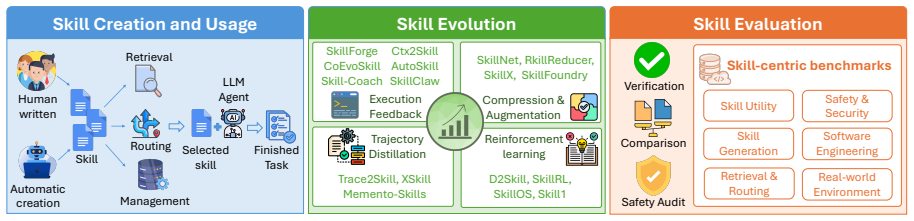
The authors argue that the field is moving to automated, evaluation-driven skill evolution and that this evolution falls into four distinct paradigms—execution feedback, trajectory distillation, compression, and reinforcement learning—each of which demonstrably improves skill performance.
What carries the argument
Four paradigms of skill evolution (execution feedback, trajectory distillation, compression, reinforcement learning) that turn evaluation signals into iterative skill improvement.
If this is right
- Execution feedback loops raise skill success rates on repeated tasks.
- Trajectory distillation transfers successful behaviors into reusable skills.
- Compression produces smaller yet functional skills that lower inference cost.
- Reinforcement learning tunes skills against reward signals derived from evaluations.
- Benchmark gaps in coverage and metric richness slow progress on safe, general skills.
Where Pith is reading between the lines
- A unified skill library could combine elements from multiple paradigms to handle both short and long tasks.
- New benchmarks focused on cross-domain transfer and safety verification would directly address the structural gaps noted.
- Hybrid evolution pipelines that switch paradigms based on task type may emerge as a practical next step.
Load-bearing premise
The four listed paradigms are distinct, exhaustive, and non-overlapping ways to perform skill evolution.
What would settle it
Identification of a widely used skill-evolution technique that cannot be placed in any of the four paradigms.
Figures
read the original abstract
The growth of agent skills has transformed how agentic systems are built, evaluated, and deployed. As skill libraries continue to scale, rigorous evaluation becomes critical to ensuring their utility, quality, and safety in real-world applications. Consequently, the field is undergoing an emerging paradigm shift from isolated skill creation to automated, evaluation-driven skill evolution. In this survey, we systematically examine the landscape of skill evolution and evaluation beyond foundational skill creation. We categorize evolution into four distinct paradigms, spanning execution feedback, trajectory distillation, compression, and reinforcement learning, showing how each element contributes to improving skill utility and reliability. We also provide an analysis of six skill-centric benchmark categories, identifying structural gaps in benchmark coverage, trade-offs, and metric richness to advance skill research. Finally, we identify open directions for building skill ecosystems that are generalizable, efficient, and verifiably safe. The project URL is https://github.com/Cassie07/AgentSkill_Survey
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper is a survey on agent skill evaluation and evolution in agentic systems. It claims an emerging paradigm shift from isolated skill creation to automated, evaluation-driven skill evolution. The authors categorize skill evolution into four distinct paradigms (execution feedback, trajectory distillation, compression, and reinforcement learning) and argue that each contributes to improving skill utility and reliability. They further analyze six skill-centric benchmark categories to identify structural gaps in coverage, trade-offs, and metric richness, and outline open directions for building generalizable, efficient, and verifiably safe skill ecosystems.
Significance. If the proposed taxonomy proves insightful and the benchmark gap analysis is comprehensive, the survey could serve as a useful organizing framework for a fast-growing subfield, helping researchers map methods to outcomes and prioritize benchmark improvements. As a primarily synthetic contribution rather than one presenting new data or derivations, its value depends on the clarity and non-redundancy of the four-paradigm categorization and the specificity of the identified gaps.
major comments (2)
- [Paradigms categorization section (near abstract claim)] The central taxonomy claim (four distinct, non-overlapping paradigms) is load-bearing yet presented descriptively; the manuscript should explicitly justify the partitioning criteria and address potential overlaps (e.g., between trajectory distillation and reinforcement learning) with concrete examples from the literature, as this directly affects the taxonomy's utility for the claimed paradigm shift.
- [Benchmark analysis section] The analysis of six benchmark categories identifies 'structural gaps' but lacks a concrete mapping or table listing the categories, the specific omitted approaches, or quantitative coverage metrics; without this, the claim that the analysis advances skill research remains difficult to verify and is load-bearing for the benchmark contribution.
minor comments (2)
- [Abstract and introduction] The abstract states there are 'six skill-centric benchmark categories' but does not name them; the main text should introduce the categories early with a brief enumeration or table for reader orientation.
- [Throughout literature review sections] Ensure that every cited work in the survey is accompanied by a clear pointer to how it exemplifies one of the four paradigms or fits into a benchmark category, to strengthen the synthetic narrative.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to strengthen the taxonomy and benchmark analysis.
read point-by-point responses
-
Referee: [Paradigms categorization section (near abstract claim)] The central taxonomy claim (four distinct, non-overlapping paradigms) is load-bearing yet presented descriptively; the manuscript should explicitly justify the partitioning criteria and address potential overlaps (e.g., between trajectory distillation and reinforcement learning) with concrete examples from the literature, as this directly affects the taxonomy's utility for the claimed paradigm shift.
Authors: We agree that the partitioning criteria should be made explicit. In the revised manuscript, we will add a dedicated paragraph in the taxonomy section justifying the four paradigms based on their primary mechanism of skill improvement (direct execution signals, trajectory synthesis, skill compression, and reward-driven optimization). We will also address overlaps with concrete literature examples, such as noting that certain trajectory distillation approaches may incorporate RL components for fine-tuning but are categorized separately due to their emphasis on distilling successful trajectories rather than end-to-end policy learning; boundary cases will be discussed to clarify distinctions. revision: yes
-
Referee: [Benchmark analysis section] The analysis of six benchmark categories identifies 'structural gaps' but lacks a concrete mapping or table listing the categories, the specific omitted approaches, or quantitative coverage metrics; without this, the claim that the analysis advances skill research remains difficult to verify and is load-bearing for the benchmark contribution.
Authors: We concur that a concrete mapping is needed for verifiability. We will add a new table in the benchmark section that explicitly lists the six categories, maps covered approaches and paradigms, identifies specific omitted methods from the literature, and includes quantitative coverage metrics (e.g., number of benchmarks per category and dimensions like safety evaluation). This will directly substantiate the identified structural gaps. revision: yes
Circularity Check
No significant circularity in survey taxonomy
full rationale
This is a survey paper whose central contribution is an interpretive categorization of existing literature into four skill-evolution paradigms (execution feedback, trajectory distillation, compression, reinforcement learning) plus benchmark analysis. No equations, fitted parameters, or self-referential definitions appear in the provided text. The taxonomy draws on external works rather than reducing any claim to the paper's own inputs by construction. No self-citation load-bearing steps, ansatz smuggling, or renaming of results are present. The paper is self-contained against external benchmarks as a literature review.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The four paradigms (execution feedback, trajectory distillation, compression, reinforcement learning) form a complete and non-overlapping taxonomy of skill evolution methods.
Reference graph
Works this paper leans on
-
[1]
SkillCraft: Can LLM agents learn to use tools skillfully? arXiv preprint arXiv:2603.00718, 2026
Skillcraft: Can llm agents learn to use tools skillfully?arXiv preprint arXiv:2603.00718. Shuangrui Ding, Xuanlang Dai, Long Xing, Shengyuan Ding, Ziyu Liu, Yang JingYi, Penghui Yang, Zhix- iong Zhang, Xilin Wei, Xinyu Fang, and 1 oth- ers. 2026. Wildclawbench: A benchmark for real- world, long-horizon agent evaluation.arXiv preprint arXiv:2605.10912. Lin...
-
[2]
Minedojo: Building open-ended embodied agents with internet-scale knowledge.Advances in Neural Information Processing Systems, 35:18343– 18362. Bofei Gao, Feifan Song, Zhe Yang, Zefan Cai, Yibo Miao, Qingxiu Dong, Lei Li, Chenghao Ma, Liang Chen, Zhengyang Tang, and 1 others. 2025a. Omni- math: A universal olympiad level mathematic bench- mark for large l...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Measuring Massive Multitask Language Understanding
Measuring massive multitask language under- standing.arXiv preprint arXiv:2009.03300. Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. 2020. Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps. InProceedings of the 28th International Con- ference on Computational Linguistics, pages 6609– 6625. Guanyu Jiang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[4]
Structured Security Auditing and Robustness Enhancement for Untrusted Agent Skills
Deepscaler: Surpassing o1-preview with a 1.5 b model by scaling rl.Notion Blog, 3(5). Lijia Lv, Xuehai Tang, Jie Wen, Jizhong Han, and Songlin Hu. 2026. Structured security auditing and robustness enhancement for untrusted agent skills. arXiv preprint arXiv:2604.25109. Zeyao Ma, Bohan Zhang, Jing Zhang, Jifan Yu, Xi- aokang Zhang, Xiaohan Zhang, Sijia Luo...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Evaluating very long-term conversational memory of llm agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 13851– 13870. Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Hajishirzi. 2023. When not to trust language models: Investigating effectiv...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Trace2Skill: Distill Trajectory-Local Lessons into Transferable Agent Skills
Trace2skill: Distill trajectory-local lessons into transferable agent skills.arXiv preprint arXiv:2603.25158. Siru Ouyang, Jun Yan, Yanfei Chen, Rujun Han, Zifeng Wang, Bhavana Dalvi Mishra, Rui Meng, Chun- Liang Li, Yizhu Jiao, Kaiwen Zha, and 1 others. 2026. Skillos: Learning skill curation for self-evolving agents.arXiv preprint arXiv:2605.06614. Panup...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
SKILLFOUNDRY: Building Self-Evolving Agent Skill Libraries from Heterogeneous Scientific Resources
Skillfoundry: Building self-evolving agent skill libraries from heterogeneous scientific resources. arXiv preprint arXiv:2604.03964. Yaorui Shi, Yuxin Chen, Zhengxi Lu, Yuchun Miao, Shugui Liu, Qi Gu, Xunliang Cai, Xiang Wang, and An Zhang. 2026. Skill1: Unified evolution of skill- augmented agents via reinforcement learning.arXiv preprint arXiv:2605.0613...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
Dynamic Dual-Granularity Skill Bank for Agentic RL
Appworld: A controllable world of apps and people for benchmarking interactive coding agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 16022–16076. Songjun Tu, Chengdong Xu, Qichao Zhang, Yaocheng Zhang, Xiangyuan Lan, Linjing Li, and Dongbin Zhao. 2026. Dynamic dual-granular...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning
Skillrl: Evolving agents via recursive skill- augmented reinforcement learning.arXiv preprint arXiv:2602.08234. Yutao Yang, Junsong Li, Qianjun Pan, Bihao Zhan, Yux- uan Cai, Lin Du, Jie Zhou, Kai Chen, Qin Chen, Xin Li, and 1 others. 2026. Autoskill: Experience- driven lifelong learning via skill self-evolution.arXiv preprint arXiv:2603.01145. Zhilin Yan...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
SkillRouter: Skill Routing for
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information pro- cessing systems, 36:46595–46623. YanZhao Zheng, ZhenTao Zhang, Chao Ma, YuanQiang Yu, JiHuai Zhu, Yong Wu, Tianze Xu, Baohua Dong, Hangcheng Zhu, Ruohui Huang, and 1 others. 2026. Skillrouter: Skill routing for llm agents at scale. arXiv preprint arXiv:2603.22455. S...
-
[11]
Instead, SkillRouter adopts a retriever and a reranker to de- termine candidate skills by using full skill content
finds that skill names and descriptions alone are inaccurate for skill selection at scale. Instead, SkillRouter adopts a retriever and a reranker to de- termine candidate skills by using full skill content. To reduce the cost of skill retrieval, SkillFlow (Li et al., 2025a) avoids repeating skill retrieval by first identifying the missing skill required t...
2020
-
[12]
provides 15,908 multiple-choice questions across 57 subjects spanning STEM, humani- ties, social sciences, and professional domains. ALPACAEVAL(Li et al., 2023) comprises 805 instruction prompts with GPT-4-based pairwise win-rate annotation against a reference model, MT-BENCH(Zheng et al., 2023) contains 80 multi-turn questions across 8 categories evaluat...
2023
-
[13]
Memory and Conversational Benchmarks
consists of 1,024 challenging tasks carefully curated from over one million real WildChat user-chatbot conversation logs; collectively these form the instruction-following suite used by SkillOrchestra (Wang et al., 2026b). Memory and Conversational Benchmarks. Memory-centric benchmarks evaluate whether agents can extract, consolidate, and recall infor- ma...
2024
-
[14]
simulates a student’s holistic college journey across three core phases and ten sub-scenarios in a persistent, stateful campus environment (1,284 in- terdependent tasks spanning a full academic year), and is referenced by AutoSkill (Yang et al., 2026) as a representative experience-driven lifelong learn- ing benchmark for evaluating self-evolving agents. ...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.