Recognition: unknown
Structured Security Auditing and Robustness Enhancement for Untrusted Agent Skills
Pith reviewed 2026-05-07 16:17 UTC · model grok-4.3
The pith
Factorized auditing of Agent Skills packages reaches 97.3 percent exact match and 98.3 percent malicious recall by factoring review into role-aware extraction, semantic checks, and consistent adjudication.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SkillGuard-Robust treats pre-load auditing of untrusted Agent Skills as a three-way classification task and combines role-aware evidence extraction, selective semantic verification, and consistency-preserving adjudication to reach 97.30 percent overall exact match, 98.33 percent malicious-risk recall, and 98.89 percent attack exact consistency on a 404-package held-out aggregate, with 99.66 percent, 100.00 percent, and 100.00 percent respectively on a 254-package external-ecosystem view, thereby supporting the claim that factorized package auditing materially improves robustness for frozen and public-ecosystem cases while leaving harsher external-source transfer as an open challenge.
What carries the argument
SkillGuard-Robust, the three-component system that factors package auditing into role-aware evidence extraction from SKILL.md and related files, selective semantic verification, and consistency-preserving adjudication to resist semantics-preserving rewrites.
If this is right
- Pre-load security reviews for Agent Skills become reliable against common semantics-preserving evasion tactics.
- Robustness gains appear for both frozen-model settings and public-ecosystem packages.
- Attack exact consistency reaches 98.89 percent on held-out data, reducing inconsistent flagging of malicious intent.
- Factorized auditing outperforms single-prompt filtering by using the full package context.
Where Pith is reading between the lines
- The same factorized structure could apply to other composite AI artifacts such as multi-file tool bundles or prompt libraries.
- Closing the remaining gap on harsher external sources would require new benchmark families that stress transfer from truly unseen origins.
- Pairing the pre-load auditor with lightweight runtime monitoring would create a two-layer defense for deployed Agent Skills.
Load-bearing premise
The held-out and external benchmarks sufficiently represent real-world malicious Agent Skills and that semantics-preserving rewrites capture the main ways attackers evade detection.
What would settle it
A clear drop below 90 percent malicious recall or attack consistency on a fresh collection of real-world malicious Agent Skills or on rewrites that preserve semantics differently from those in the current benchmarks would falsify the robustness claim.
Figures






read the original abstract
Agent Skills package SKILL.md files, scripts, reference documents, and repository context into reusable capability units, turning pre-load auditing from single-prompt filtering into cross-file security review. Existing guardrails often flag risk but recover malicious intent inconsistently under semantics-preserving rewrites. This paper formulates pre-load auditing for untrusted Agent Skills as a robust three-way classification task and introduces SkillGuard-Robust, which combines role-aware evidence extraction, selective semantic verification, and consistency-preserving adjudication. We evaluate SkillGuard-Robust on SkillGuardBench and two public-ecosystem extensions through five large evaluation views ranging from 254 to 404 packages. On the 404-package held-out aggregate, SkillGuard-Robust reaches 97.30% overall exact match, 98.33% malicious-risk recall, and 98.89% attack exact consistency. On the 254-package external-ecosystem view, it reaches 99.66%, 100.00%, and 100.00%, respectively. These results support a bounded conclusion: factorized package auditing materially improves frozen and public-ecosystem robustness, while harsher external-source transfer remains an open challenge.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formulates pre-load auditing of untrusted Agent Skills packages (SKILL.md files, scripts, and context) as a three-way classification task and introduces SkillGuard-Robust, which integrates role-aware evidence extraction, selective semantic verification, and consistency-preserving adjudication. It reports results across five evaluation views on SkillGuardBench and two public-ecosystem extensions (254–404 packages), achieving 97.30% overall exact match, 98.33% malicious-risk recall, and 98.89% attack exact consistency on the 404-package held-out aggregate, plus 99.66% exact match, 100% malicious recall, and 100% consistency on the 254-package external view. The central claim is that factorized package auditing materially improves robustness for frozen and public-ecosystem cases, while harsher external-source transfer remains an open challenge.
Significance. If the evaluation methodology and benchmark construction are sound, the work would offer a meaningful advance in securing AI agent capability ecosystems by providing a structured, multi-component auditing approach that targets inconsistency under semantics-preserving rewrites. The emphasis on factorized auditing and consistency adjudication supplies a concrete framework that could inform practical guardrails, with the multi-view evaluation (held-out plus external) adding some breadth to the reported gains.
major comments (2)
- [Abstract] Abstract: the reported 99.66% exact match, 100.00% malicious-risk recall, and 100.00% attack exact consistency on the 254-package external-ecosystem view stands in tension with the explicit statement that 'harsher external-source transfer remains an open challenge.' This raises a load-bearing concern for the bounded conclusion, because the external numbers imply the selective semantic verification and consistency-preserving adjudication components were not stressed by the primary evasion patterns (e.g., control-flow flattening, identifier renaming, or docstring injection) that the abstract itself identifies as relevant.
- [Evaluation] Evaluation (across the five views): the manuscript does not supply sufficient detail on SkillGuardBench construction—specifically how malicious instances were generated, how semantics-preserving rewrites were applied to create the test cases, or what baseline systems were compared against. Without these elements, the high recall and consistency figures (e.g., 98.33% malicious recall on the 404-package aggregate) cannot be assessed for genuine robustness versus benchmark-specific tuning, directly affecting support for the claim that factorized auditing improves robustness.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address both major comments by clarifying the scope of the external evaluation results and committing to expanded methodological details in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] the reported 99.66% exact match, 100.00% malicious-risk recall, and 100.00% attack exact consistency on the 254-package external-ecosystem view stands in tension with the explicit statement that 'harsher external-source transfer remains an open challenge.' This raises a load-bearing concern for the bounded conclusion, because the external numbers imply the selective semantic verification and consistency-preserving adjudication components were not stressed by the primary evasion patterns (e.g., control-flow flattening, identifier renaming, or docstring injection) that the abstract itself identifies as relevant.
Authors: We agree the abstract wording risks misinterpretation. The 254-package external-ecosystem view draws directly from public repositories without additional adversarial rewrites. The phrase 'harsher external-source transfer' specifically denotes more aggressive post-sourcing transformations (control-flow flattening, identifier renaming, docstring injection) that are not instantiated in the current 254-package collection. We will revise the abstract to explicitly separate the evaluated external view from these harsher transfer scenarios that remain an open challenge. revision: yes
-
Referee: [Evaluation] Evaluation (across the five views): the manuscript does not supply sufficient detail on SkillGuardBench construction—specifically how malicious instances were generated, how semantics-preserving rewrites were applied to create the test cases, or what baseline systems were compared against. Without these elements, the high recall and consistency figures (e.g., 98.33% malicious recall on the 404-package aggregate) cannot be assessed for genuine robustness versus benchmark-specific tuning, directly affecting support for the claim that factorized auditing improves robustness.
Authors: We concur that additional detail is required for reproducibility and to substantiate the robustness claims. In the revised manuscript we will expand the Evaluation section with: (i) the exact procedure for generating malicious instances (rule-based injection combined with LLM-assisted obfuscation), (ii) the concrete semantics-preserving rewrite operators applied (variable renaming, dead-code insertion, control-flow flattening, docstring injection), and (iii) the full baseline suite together with their configurations and implementation references. These additions will allow readers to distinguish benchmark-specific effects from the contribution of factorized auditing. revision: yes
Circularity Check
No circularity: evaluation relies on held-out and external sets with independent method definition
full rationale
The paper defines SkillGuard-Robust via role-aware extraction, selective semantic verification, and consistency-preserving adjudication, then evaluates it on explicitly separated SkillGuardBench held-out aggregates (404 packages) and external-ecosystem views (254 packages). No equations, parameter fits, or self-citations are shown that reduce the reported metrics (exact match, recall, consistency) to the inputs by construction. The central claim of material robustness improvement is supported by these external benchmarks rather than being definitionally equivalent to them. This is the normal case of a self-contained empirical evaluation.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 2 Pith papers
-
Proteus: A Self-Evolving Red Team for Agent Skill Ecosystems
Proteus demonstrates that adaptive red-teaming achieves 40-90% attack success after five rounds and bypasses even strong auditors at up to 41% joint success, revealing that static skill vetting underestimates residual risk.
-
Skill Drift Is Contract Violation: Proactive Maintenance for LLM Agent Skill Libraries
SkillGuard extracts executable environment contracts from LLM skill documents to detect only relevant drifts, reporting zero false positives on 599 cases, 100% precision in known-drift tests, and raising one-round rep...
Reference graph
Works this paper leans on
-
[1]
Ipi- guard: A novel tool dependency graph-based defense against indirect prompt injection in LLM agents. arXiv preprint arXiv:2508.15310. Anthropic
-
[2]
https: //platform.claude.com/docs/en/agents-and-tools/age nt-skills/overview
Agent skills – claude api docs. https: //platform.claude.com/docs/en/agents-and-tools/age nt-skills/overview. Accessed: 2026-04-07. Elias Bassani and Ignacio Sanchez
2026
-
[3]
InFindings of the Association for Compu- tational Linguistics: EMNLP 2025, pages 16995– 17006, Suzhou, China
On guardrail models’ robustness to mutations and adversarial at- tacks. InFindings of the Association for Compu- tational Linguistics: EMNLP 2025, pages 16995– 17006, Suzhou, China. Association for Computa- tional Linguistics. Julius Broomfield, Tom Gibbs, George Ingebretsen, Ethan Kosak-Hine, Tia Nasir, Jason Zhang, Rei- haneh Iranmanesh, Sara Pieri, Rei...
2025
-
[4]
InFindings of the Association for Computational Linguistics: ACL 2025, pages 22134–22173, Vienna, Austria
The structural safety gen- eralization problem. InFindings of the Association for Computational Linguistics: ACL 2025, pages 22134–22173, Vienna, Austria. Association for Com- putational Linguistics. Sizhe Chen, Arman Zharmagambetov, Saeed Mahlouji- far, Kamalika Chaudhuri, David Wagner, and Chuan Guo
2025
-
[5]
Secalign: Defending against prompt injection with preference optimization
Secalign: Defending against prompt in- jection with preference optimization.arXiv preprint arXiv:2410.05451. Florian Holzbauer, David Schmidt, Gabriel Gegenhuber, Sebastian Schrittwieser, and Johanna Ullrich
-
[6]
Malicious or not: Adding repository context to agent skill classification.arXiv preprint arXiv:2603.16572. Hakan Inan, Kartikeya Upasani, Jianfeng Chi, Rashi Rungta, Krithika Iyer, Yuning Mao, Michael Tontchev, Qing Hu, Brian Fuller, Davide Testuggine, and Madian Khabsa
-
[7]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
Llama guard: LLM- based input-output safeguard for human-ai conversa- tions.arXiv preprint arXiv:2312.06674. Xiaojun Jia, Jie Liao, Simeng Qin, Jindong Gu, Wenqi Ren, Xiaochun Cao, Yang Liu, and Philip Torr
work page internal anchor Pith review arXiv
-
[8]
Skillject: Automating stealthy skill-based prompt injection for coding agents with trace-driven closed- loop refinement.arXiv preprint arXiv:2602.14211. Hao Li and Xiaogeng Liu
-
[9]
arXiv preprint arXiv:2410.22770 , year=
Injecguard: Benchmarking and mitigating over-defense in prompt injection guardrail models.arXiv preprint arXiv:2410.22770. Hao Li, Xiaogeng Liu, Ning Zhang, and Chaowei Xiao
-
[10]
Reasalign: Reasoning enhanced safety alignment against prompt injection attack.arXiv preprint arXiv:2601.10173. Yi Liu, Zhihao Chen, Yanjun Zhang, Gelei Deng, Yuekang Li, Jianting Ning, Ying Zhang, and Leo Yu Zhang. 2026a. Malicious agent skills in the wild: A large-scale security empirical study.arXiv preprint arXiv:2602.06547. Yi Liu, Weizhe Wang, Ruita...
-
[11]
Formalizing and benchmarking prompt injection attacks and de- fenses
Formalizing and bench- marking prompt injection attacks and defenses.arXiv preprint arXiv:2310.12815. Lingrui Mei, Shenghua Liu, Yiwei Wang, Baolong Bi, Jiayi Mao, and Xueqi Cheng
-
[12]
https: //huggingface.co/meta-llama/Llama-Prompt-Guard -2-86M
Llama prompt guard 2 model card. https: //huggingface.co/meta-llama/Llama-Prompt-Guard -2-86M. Accessed: 2026-04-07. Honglin Mu, Han He, Yuxin Zhou, Yunlong Feng, Yang Xu, Libo Qin, Xiaoming Shi, Zeming Liu, Xudong Han, Qi Shi, Qingfu Zhu, and Wanxiang Che
2026
-
[13]
Stealthy jailbreak attacks on large language mod- els via benign data mirroring. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Lin- guistics: Human Language Technologies (Volume 1: Long Papers), pages 1784–1799, Albuquerque, New Mexico. Association for Computational Linguistics. Itay Nakas...
2025
-
[14]
InFindings of the Association for Computational Linguistics: NAACL 2025, pages 6499–6524, Albuquerque, New Mexico
Breaking ReAct agents: Foot-in- the-door attack will get you in. InFindings of the Association for Computational Linguistics: NAACL 2025, pages 6499–6524, Albuquerque, New Mexico. Association for Computational Linguistics. OpenAI
2025
-
[15]
https://developers .openai.com/codex/skills
Agent skills – codex. https://developers .openai.com/codex/skills. Accessed: 2026-04-07. Inkit Padhi, Manish Nagireddy, Giandomenico Cornac- chia, Subhajit Chaudhury, Tejaswini Pedapati, Pierre Dognin, Keerthiram Murugesan, Erik Miehling, Martín Santillán Cooper, Kieran Fraser, Giulio Zizzo, Muhammad Zaid Hameed, Mark Purcell, Michael Desmond, Qian Pan, Z...
2026
- [16]
-
[17]
Accessed: 2026-04-07
Qwen2.5: A party of foundation models! https://qwenlm.github.io/blog/qwen2.5/. Accessed: 2026-04-07. David Schmotz, Sahar Abdelnabi, and Maksym An- driushchenko
2026
-
[18]
Agent skills enable a new class of realistic and trivially simple prompt injections,
Agent skills enable a new class of realistic and trivially simple prompt injections. arXiv preprint arXiv:2510.26328. David Schmotz, Luca Beurer-Kellner, Sahar Abdelnabi, and Maksym Andriushchenko
-
[19]
Skill-inject: Measuring agent vulnerability to skill file attacks. arXiv preprint arXiv:2602.20156. Tianneng Shi, Kaijie Zhu, Zhun Wang, Yuqi Jia, Will Cai, Weida Liang, Haonan Wang, Hend Alzahrani, Joshua Lu, Kenji Kawaguchi, Basel Alomair, Xuan- dong Zhao, William Yang Wang, Neil Gong, Wenbo Guo, and Dawn Song
-
[20]
Promptarmor: Sim- ple yet effective prompt injection defenses.arXiv preprint arXiv:2507.15219. Makesh Narsimhan Sreedhar, Traian Rebedea, and Christopher Parisien
-
[21]
InFindings of the Association for Compu- tational Linguistics: EMNLP 2025, pages 21862– 21880, Suzhou, China
Safety through rea- soning: An empirical study of reasoning guardrail models. InFindings of the Association for Compu- tational Linguistics: EMNLP 2025, pages 21862– 21880, Suzhou, China. Association for Computa- tional Linguistics. Yihong Tang, Bo Wang, Xu Wang, Dongming Zhao, Jing Liu, Ruifang He, and Yuexian Hou
2025
-
[22]
The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions
The in- struction hierarchy: Training LLMs to prioritize privi- leged instructions.arXiv preprint arXiv:2404.13208. Zhun Wang, Vincent Siu, Zhe Ye, Tianneng Shi, Yuzhou Nie, Xuandong Zhao, Chenguang Wang, Wenbo Guo, and Dawn Song
work page internal anchor Pith review arXiv
-
[23]
InFindings of the Association for Computational Linguistics: EMNLP 2025, pages 23159–23172, Suzhou, China
AGENTVIGIL: Automatic black-box red-teaming for indirect prompt injection against LLM agents. InFindings of the Association for Computational Linguistics: EMNLP 2025, pages 23159–23172, Suzhou, China. Association for Com- putational Linguistics. Xiaofei Wen, Wenxuan Zhou, Wenjie Jacky Mo, and Muhao Chen
2025
-
[24]
InFindings of the Association for Computational Linguistics: ACL 2025, pages 13698–13713, Vienna, Austria
Thinkguard: Deliberative slow thinking leads to cautious guardrails. InFindings of the Association for Computational Linguistics: ACL 2025, pages 13698–13713, Vienna, Austria. Associa- tion for Computational Linguistics. Jingwei Yi, Yueqi Xie, Bin Zhu, Emre Kiciman, Guangzhong Sun, Xing Xie, and Fangzhao Wu
2025
-
[25]
Benchmarking and defending against indirect prompt injection attacks on large language models.arXiv preprint arXiv:2312.14197. Qiusi Zhan, Richard Fang, Henil Shalin Panchal, and Daniel Kang
-
[26]
InFindings of the Association for Computa- tional Linguistics: NAACL 2025, pages 7116–7132, Albuquerque, New Mexico
Adaptive attacks break defenses against indirect prompt injection attacks on LLM agents. InFindings of the Association for Computa- tional Linguistics: NAACL 2025, pages 7116–7132, Albuquerque, New Mexico. Association for Compu- tational Linguistics. Qiusi Zhan, Zhixiang Liang, Zifan Ying, and Daniel Kang
2025
-
[27]
InFindings of the Association for Computational Linguistics: ACL 2024, pages 10471– 10506, Bangkok, Thailand
Injecagent: Benchmarking indirect prompt injections in tool-integrated large language model agents. InFindings of the Association for Computational Linguistics: ACL 2024, pages 10471– 10506, Bangkok, Thailand. Association for Compu- tational Linguistics. Tian Zhang, Yiwei Xu, Juan Wang, Keyan Guo, Xi- aoyang Xu, Bowen Xiao, Quanlong Guan, Jinlin Fan, Jiaw...
2024
-
[28]
Agentsentry: Mitigating indirect prompt injection in LLM agents via temporal causal diagnostics and con- text purification.arXiv preprint arXiv:2602.22724. Zhihan Zhang, Shiyang Li, Zixuan Zhang, Xin Liu, Haoming Jiang, Xianfeng Tang, Yifan Gao, Zheng Li, Haodong Wang, Zhaoxuan Tan, Yichuan Li, Qingyu Yin, Bing Yin, and Meng Jiang
-
[29]
IHEval: Eval- uating language models on following the instruction hierarchy. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Asso- ciation for Computational Linguistics: Human Lan- guage Technologies (Volume 1: Long Papers), pages 8374–8398, Albuquerque, New Mexico. Association for Computational Linguistics. A Appendix R...
2025
-
[30]
clas- sification over 30 prompts per split,
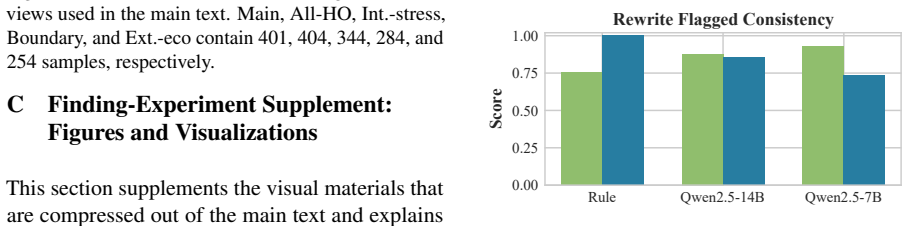
The important point is not the absolute score of any one model, but the fact that two different baselines improve in the same direction once the input view is switched. Under skill-md-only, PEB nearly loses the abil- ity to recover malicious cases; Qwen2.5-14B also becomes clearly unstable on risk and rewrite met- rics. This indicates that skill auditing ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.