Preregistration for Experiments with AI Agents
Pith reviewed 2026-07-01 00:12 UTC · model grok-4.3
The pith
Preregistration should be extended to experiments with AI agents to reduce hidden researcher flexibility.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
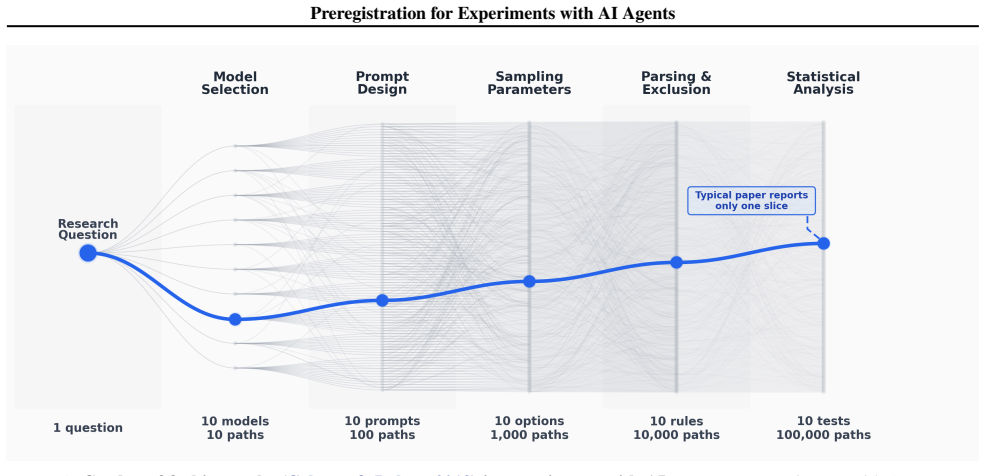
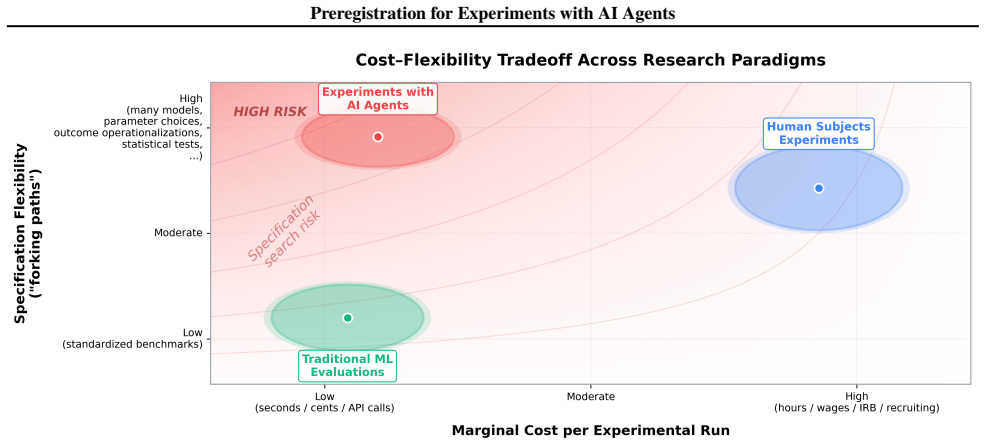
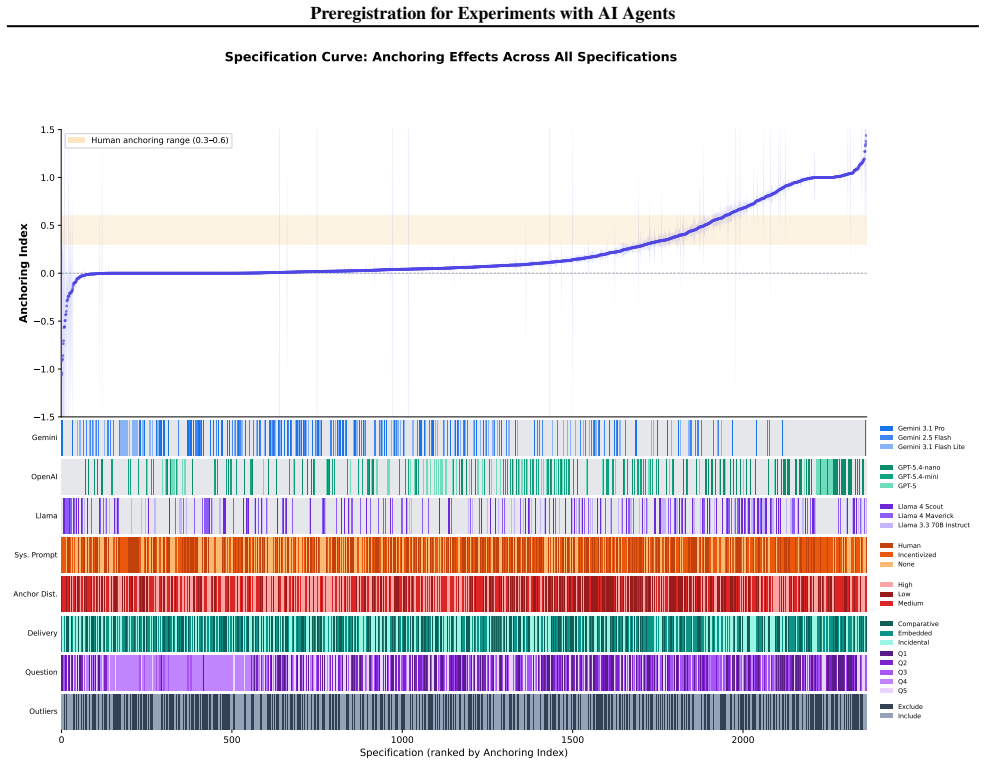
Experiments with AI agents introduce researcher degrees of freedom such as model selection, prompt wording, settings, and outcome-contingent redesign; the low cost of iteration and lack of reporting norms make these choices easy to exploit and difficult to detect; therefore preregistration practices from human subjects research should be extended to this domain through a tailored template to improve credibility.
What carries the argument
A preregistration template tailored to AI agent experiments that requires advance specification of model choice, prompt details, experimental settings, and analysis plans.
If this is right
- Journals and conferences would require preregistration for papers involving AI agent experiments.
- Researchers would need to declare model and prompt choices before collecting results.
- Outcome-contingent redesigns would be labeled as exploratory rather than planned.
- Funding agencies could condition support on use of the preregistration template.
Where Pith is reading between the lines
- Widespread adoption might prompt creation of logging tools that automatically record AI experiment parameters.
- The approach could reveal whether AI-specific issues like prompt sensitivity require additional safeguards beyond standard preregistration.
- Success here might encourage similar registration norms in other low-cost computational behavioral studies.
Load-bearing premise
The methodological problems in AI agent experiments are similar enough to those in human studies that preregistration will address them effectively.
What would settle it
An audit comparing published AI agent studies that finds equivalent rates of selective reporting or post-hoc changes in both preregistered and non-preregistered work would undermine the claim.
Figures
read the original abstract
The proliferation of large language models (LLMs) and autonomous AI agents has given rise to a rapidly growing methodological paradigm: "in silico" behavioral experiments. Originally conceived as a way to use AI agents as proxies for human participants in studies of cognition, decision-making, and social dynamics, this approach has taken on new significance -- as AI agents increasingly negotiate, transact, and make consequential decisions on behalf of people and organizations, understanding their behavior has become a research priority in its own right. While these experiments with AI agents offer unprecedented advantages in terms of scalability, cost efficiency, and experimental control, they also inherit, and in some cases amplify, methodological vulnerabilities that have long plagued human subjects research. To address these issues, this paper argues that preregistration practices -- central to improving the credibility of human subjects experiments -- should now be extended to experiments with AI agents. We systematically catalog the researcher degrees of freedom that experiments with AI agents introduce -- model selection, prompt wording, settings, and outcome-contingent redesign, for example -- and show how the low cost of iteration and lack of reporting norms make these choices both easy to exploit and difficult to detect. We propose a preregistration template tailored to experiments with AI agents and call on conferences, journals, and funding agencies to make preregistration standard practice for this emerging research paradigm.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that preregistration practices from human subjects research should be extended to 'in silico' behavioral experiments with AI agents. It catalogs researcher degrees of freedom including model selection, prompt wording, settings, and outcome-contingent redesign; notes that low iteration costs and absent reporting norms make these choices easy to exploit; and proposes a tailored preregistration template while calling for its adoption by conferences, journals, and funders.
Significance. If adopted, the proposal could help establish methodological norms in an emerging research area where scalability and low costs amplify flexibility in experimental design. The systematic catalog of vulnerabilities is a useful contribution, but the significance is constrained by the absence of any empirical test of whether the template actually constrains behavior or improves credibility.
major comments (2)
- [Abstract / proposal section] Abstract and main argument: the central recommendation that the same preregistration mechanism will mitigate the listed degrees of freedom rests on an untested analogy to human-subjects research; no pilot data, simulation, or formal argument is supplied showing that advance locking of model/prompt choices reduces selective reporting when parallel evaluation of multiple LLMs is near-zero cost.
- [Catalog of researcher degrees of freedom] Section cataloging vulnerabilities (model selection, prompt wording, outcome-contingent redesign): the claim that these are 'sufficiently analogous' to p-hacking is load-bearing for the extension argument, yet the manuscript provides no concrete test or counter-example analysis addressing whether low-cost iteration allows researchers to evade the template in ways not possible with human subjects.
minor comments (2)
- [Proposed template] The template itself is described at a high level; including an explicit example filled-out template (even a short one) would improve clarity and usability.
- [Call to action] No discussion of enforcement mechanisms or incentives for adoption is provided, which is a practical gap for a normative proposal.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for recognizing the value of the systematic catalog of vulnerabilities. We respond to each major comment below and note planned revisions.
read point-by-point responses
-
Referee: [Abstract / proposal section] Abstract and main argument: the central recommendation that the same preregistration mechanism will mitigate the listed degrees of freedom rests on an untested analogy to human-subjects research; no pilot data, simulation, or formal argument is supplied showing that advance locking of model/prompt choices reduces selective reporting when parallel evaluation of multiple LLMs is near-zero cost.
Authors: We agree that the proposal rests on an analogy without new empirical validation or simulation specific to AI agents. The manuscript's primary contribution is the identification of AI-specific degrees of freedom and the design of a corresponding template; the claim that preregistration can mitigate them follows from the mechanism of advance commitment rather than from cost considerations alone. Advance locking of model, prompt, and analysis choices still constrains post-outcome adjustments even when parallel runs are inexpensive. To address the concern directly, we will add a subsection providing explicit reasoning on this point, including why low iteration costs do not eliminate the value of pre-commitment. This is a partial revision. revision: partial
-
Referee: [Catalog of researcher degrees of freedom] Section cataloging vulnerabilities (model selection, prompt wording, outcome-contingent redesign): the claim that these are 'sufficiently analogous' to p-hacking is load-bearing for the extension argument, yet the manuscript provides no concrete test or counter-example analysis addressing whether low-cost iteration allows researchers to evade the template in ways not possible with human subjects.
Authors: The analogy is grounded in the shared structural problem of researcher flexibility enabling selective reporting, which the paper illustrates with concrete examples of outcome-contingent redesign. We acknowledge that no formal test or counter-example analysis is supplied. In revision we will expand the catalog section with additional hypothetical scenarios that explicitly consider low-cost evasion routes (e.g., running many parallel models before locking) and show how the template's requirements for pre-specifying the full evaluation plan are intended to limit them. We will also note remaining limitations. This is a partial revision. revision: partial
Circularity Check
No circularity detected; normative proposal draws on external field practices without self-referential derivation or fitted predictions.
full rationale
The paper is a conceptual/normative argument advocating extension of preregistration from human-subjects research to AI-agent experiments. It catalogs researcher degrees of freedom (model selection, prompt wording, etc.) and proposes a template, but contains no equations, derivations, fitted parameters, or self-citations that reduce the central claim to its own inputs by construction. The analogy to human-subjects preregistration is presented as an external precedent rather than a self-defined or self-cited uniqueness theorem. No load-bearing step matches any enumerated circularity pattern; the argument is self-contained as a direct proposal.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Preregistration improves the credibility of experiments by limiting researcher degrees of freedom
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 40th International Conference on Machine Learning , pages =
Using Large Language Models to Simulate Multiple Humans and Replicate Human Subject Studies , author =. Proceedings of the 40th International Conference on Machine Learning , pages =. 2023 , editor =
2023
-
[2]
Nature Human Behaviour , year =
Playing repeated games with large language models , author =. Nature Human Behaviour , year =
-
[3]
Political Analysis , volume =
Out of One, Many: Using Language Models to Simulate Human Samples , author =. Political Analysis , volume =. 2023 , publisher =
2023
-
[4]
Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence , pages =
When Will Negotiation Agents Be Able to Represent Us? The Challenges and Opportunities for Autonomous Negotiators , author =. Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence , pages =
-
[5]
arXiv preprint arXiv:2402.05863 , year=
Federico Bianchi and Patrick John Chia and Mert Yuksekgonul and Jacopo Tagliabue and Dan Jurafsky and James Zou , year=. How Well Can. 2402.05863 , journal=
-
[6]
Using Cognitive Psychology to Understand
Binz, Marcel and Schulz, Eric , journal =. Using Cognitive Psychology to Understand. 2023 , volume =
2023
-
[7]
Political Analysis , pages =
Synthetic Replacements for Human Survey Data? The Perils of Large Language Models , author =. Political Analysis , pages =. 2023 , publisher =
2023
-
[8]
2021 , eprint =
On the Opportunities and Risks of Foundation Models , author =. 2021 , eprint =
2021
-
[9]
Nature , year =
Variability in the analysis of a single neuroimaging dataset by many teams , author =. Nature , year =
-
[10]
Nature Reviews Neuroscience , volume =
Power Failure: Why Small Sample Size Undermines the Reliability of Neuroscience , author =. Nature Reviews Neuroscience , volume =. 2013 , publisher =
2013
-
[11]
Science , volume =
Evaluating Replicability of Laboratory Experiments in Economics , author =. Science , volume =. 2016 , publisher =
2016
-
[12]
Evaluating the Replicability of Social Science Experiments in
Camerer, Colin F and Dreber, Anna and Holzmeister, Felix and Ho, Teck-Hua and Huber, J. Evaluating the Replicability of Social Science Experiments in. Nature Human Behaviour , volume =. 2018 , publisher =
2018
-
[13]
Specializing Large Language Models to Simulate Survey Response Distributions for Global Populations , author =. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , month = apr, year =
2025
-
[14]
, journal =
Chambers, Christopher D. , journal =. Registered Reports: A New Publishing Initiative at. 2013 , volume =
2013
-
[15]
2024 , publisher =
Chen, Lingjiao and Zaharia, Matei and Zou, James , journal =. 2024 , publisher =
2024
-
[16]
Trends and Charts on Registered Studies , author =
-
[17]
Surpassing 100,000 Registrations on
Pfeiffer, Nici and Call, Mark , year =. Surpassing 100,000 Registrations on
-
[18]
Registered Reports , author =
-
[19]
2024 , doi =
Cui, Justin and Chiang, Wei-Lin and Stoica, Ion and Hsieh, Cho-Jui , journal =. 2024 , doi =
2024
-
[20]
Dillion, Danica and Tandon, Niket and Gu, Yuling and Gray, Kurt , journal =. Can. 2023 , publisher =
2023
-
[21]
Advances in Neural Information Processing Systems (NeurIPS 2024) , year =
Questioning the Survey Responses of Large Language Models , author =. Advances in Neural Information Processing Systems (NeurIPS 2024) , year =
2024
-
[22]
Science , year =
The reusable holdout: Preserving validity in adaptive data analysis , author =. Science , year =
-
[23]
What Did
Errica, Federico and Siracusano, Giuseppe and Sanvito, Davide and Bifulco, Roberto , journal =. What Did
-
[24]
2013 , note =
The Garden of Forking Paths: Why Multiple Comparisons Can Be a Problem, Even When There Is No ``Fishing Expedition'' or ``p-Hacking'' and the Research Hypothesis Was Posited Ahead of Time , author =. 2013 , note =
2013
-
[25]
Proceedings of the AAAI Conference on Artificial Intelligence , pages =
State of the Art: Reproducibility in Artificial Intelligence , author =. Proceedings of the AAAI Conference on Artificial Intelligence , pages =. 2018 , url =
2018
-
[26]
Proceedings of the AAAI Conference on Artificial Intelligence , year =
Deep Reinforcement Learning That Matters , author =. Proceedings of the AAAI Conference on Artificial Intelligence , year =
-
[27]
Frontiers in Artificial Intelligence , VOLUME=
Herrera-Poyatos, David and Peláez-González, Carlos and Zuheros, Cristina and Herrera-Poyatos, Andrés and Tejedor, Virilo and Herrera, Francisco and Montes, Rosana , TITLE=. Frontiers in Artificial Intelligence , VOLUME=. 2025 , URL=
2025
-
[28]
The Curious Case of Neural Text Degeneration
The Curious Case of Neural Text Degeneration , author =. International Conference on Learning Representations , year =. 1904.09751 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[29]
Horton, Apostolos Filippas, and Benjamin S
Large Language Models as Simulated Economic Agents: What Can We Learn from Homo Silicus? , author =. 2023 , institution =. doi:10.48550/arXiv.2301.07543 , url =. 2301.07543 , archivePrefix =
-
[30]
Science , volume =
Artificial Intelligence Faces Reproducibility Crisis , author =. Science , volume =. 2018 , publisher =
2018
-
[31]
PLoS Medicine , volume =
Why Most Published Research Findings Are False , author =. PLoS Medicine , volume =. 2005 , publisher =
2005
-
[32]
Psychological Science , volume =
Measuring the Prevalence of Questionable Research Practices with Incentives for Truth Telling , author =. Psychological Science , volume =. 2012 , publisher =
2012
-
[33]
Patterns , volume=
Leakage and the reproducibility crisis in machine-learning-based science , author=. Patterns , volume=. 2023 , publisher=
2023
-
[34]
Larsen, Erik , year =. The Instability of Safety:. 2512.12066 , publisher =
-
[35]
Retrieval-Augmented Generation for Knowledge-Intensive
Lewis, Patrick and Perez, Ethan and Piktus, Aleksandra and Petroni, Fabio and Karpukhin, Vladimir and Goyal, Naman and K. Retrieval-Augmented Generation for Knowledge-Intensive. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[36]
A survey on
Li, Xinyi and Wang, Sai and Zeng, Siqi and Wu, Yu and Yang, Yi , journal=. A survey on. 2024 , publisher=
2024
-
[37]
2022 , eprint =
Holistic Evaluation of Language Models , author =. 2022 , eprint =
2022
-
[38]
Registered report adoption in academic journals:
Lin, Ting. Registered report adoption in academic journals:. Scientometrics , year =
-
[39]
ACM Computing Surveys , year =
Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing , author =. ACM Computing Surveys , year =
-
[40]
Ma, Wei and Yang, Yixiao and Ge, Jingquan and Xie, Xiaofei and Jiang, Lingxiao , year =. Prompt Stability in Code. doi:10.48550/arXiv.2509.13680 , url =. 2509.13680 , archivePrefix =
-
[41]
The Greatest Good Benchmark: Measuring
Marraffini, Gonzalo F. The Greatest Good Benchmark: Measuring. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , year =
2024
-
[42]
Mei, Qiaozhu and Xie, Yutong and Yuan, Walter and Jackson, Matthew O , journal =. A. 2024 , publisher =
2024
-
[43]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , month = dec, year =
Rethinking the Role of Demonstrations: What Makes In-Context Learning Work? , author =. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , month = dec, year =
2022
-
[44]
Model Cards for Model Reporting , author =. Proceedings of the Conference on Fairness, Accountability, and Transparency (FAT* '19) , year =. doi:10.1145/3287560.3287596 , url =
-
[45]
2016 , month = sep, day =
2016
-
[46]
2025 , month = apr, url =
A 25-Year Journey to a Half-Million Registered Studies , author =. 2025 , month = apr, url =
2025
-
[47]
Proceedings of the National Academy of Sciences , volume =
The Preregistration Revolution , author =. Proceedings of the National Academy of Sciences , volume =. 2018 , publisher =. doi:10.1073/pnas.1708274114 , url =
-
[48]
Royal Society Open Science , year =
Robustness of large language models in moral judgements , author =. Royal Society Open Science , year =
-
[49]
Science , year =
Estimating the reproducibility of psychological science , author =. Science , year =
-
[50]
Journal of Machine Learning Research , year =
Improving Reproducibility in Machine Learning Research , author =. Journal of Machine Learning Research , year =. 2003.12206 , archivePrefix =
-
[51]
Advances in Neural Information Processing Systems , year =
A Step Toward Quantifying Independently Reproducible Machine Learning Research , author =. Advances in Neural Information Processing Systems , year =. 1909.06674 , archivePrefix =
-
[52]
Ethical Reasoning over Moral Alignment: A Case and Framework for In-Context Ethical Policies in
Rao, Abhinav and Khandelwal, Aditi and Tanmay, Kumar and Agrawal, Utkarsh and Chadha, Aman , booktitle =. Ethical Reasoning over Moral Alignment: A Case and Framework for In-Context Ethical Policies in
-
[53]
Prompt Programming for Large Language Models: Beyond the Few-Shot Paradigm , author =. Extended Abstracts of the 2021 CHI Conference on Human Factors in Computing Systems (CHI EA '21) , year =. doi:10.1145/3411763.3451760 , eprint =
-
[54]
Advances in Neural Information Processing Systems (NeurIPS 2019) , year =
A Meta-Analysis of Overfitting in Machine Learning , author =. Advances in Neural Information Processing Systems (NeurIPS 2019) , year =
2019
-
[55]
Findings of the Association for Computational Linguistics: ACL 2024 , month = aug, year =
The Butterfly Effect of Altering Prompts: How Small Changes and Jailbreaks Affect Large Language Model Performance , author =. Findings of the Association for Computational Linguistics: ACL 2024 , month = aug, year =
2024
-
[56]
Psychology & Marketing , volume =
Using Large Language Models to Generate Silicon Samples in Consumer and Marketing Research: Challenges, Opportunities, and Guidelines , author =. Psychology & Marketing , volume =. 2024 , publisher =
2024
-
[57]
Frontiers in Psychology , volume =
The Meaningfulness of Effect Sizes in Psychological Research: Differences Between Sub-Disciplines and the Impact of Potential Biases , author =. Frontiers in Psychology , volume =. 2019 , publisher =
2019
-
[58]
Advances in Methods and Practices in Psychological Science , volume =
An Excess of Positive Results: Comparing the Standard Psychology Literature with Registered Reports , author =. Advances in Methods and Practices in Psychological Science , volume =. 2021 , publisher =
2021
-
[59]
Evaluating the Moral Beliefs Encoded in
Scherrer, Nino and Shi, Claudia and Feder, Amir and Blei, David M , booktitle =. Evaluating the Moral Beliefs Encoded in. 2024 , url=
2024
-
[60]
Quantifying Language Models' Sensitivity to Spurious Features in Prompt Design , author =. arXiv preprint arXiv:2310.11324 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[61]
Psychological Science , year =
False-Positive Psychology: Undisclosed Flexibility in Data Collection and Analysis Allows Presenting Anything as Significant , author =. Psychological Science , year =
-
[62]
Nature Human Behaviour , year =
Specification Curve Analysis , author =. Nature Human Behaviour , year =
-
[63]
Snell, Charlie and Lee, Jaehoon and Xu, Kelvin and Kumar, Aviral , year =. Scaling. 2408.03314 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[64]
Perspectives on Psychological Science , year =
Increasing Transparency Through a Multiverse Analysis , author =. Perspectives on Psychological Science , year =
-
[65]
Why prospective registration of systematic reviews makes sense , author =. Systematic Reviews , volume =. 2012 , publisher =. doi:10.1186/2046-4053-1-7 , url=
-
[66]
Behavior Research Methods , year =
Preregistration in practice: A comparison of preregistered and non-preregistered studies in psychology , author =. Behavior Research Methods , year =
-
[67]
Perspectives on Psychological Science , volume =
An Agenda for Purely Confirmatory Research , author =. Perspectives on Psychological Science , volume =. 2012 , publisher =
2012
-
[68]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , month = jul, year =
Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models , author =. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , month = jul, year =
-
[69]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author =. International Conference on Learning Representations , year =. 2203.11171 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[70]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author =. Advances in Neural Information Processing Systems , year =. 2201.11903 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[71]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation Framework , author =. 2023 , eprint =. doi:10.48550/arXiv.2308.08155 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2308.08155 2023
-
[72]
Zamfirescu-Pereira, J. D. and Wong, Richmond and Hartmann, Bjoern and Yang, Qian , booktitle =. Why Johnny Can't Prompt: How Non-. 2023 , url =
2023
-
[73]
Update on Trial Registration 11 Years After the
Zarin, Deborah A and Tse, Tony and Williams, Rebecca J and Rajakannan, Thiyagu , journal =. Update on Trial Registration 11 Years After the. 2017 , publisher =
2017
-
[74]
Proceedings of the 38th International Conference on Machine Learning , pages =
Calibrate Before Use: Improving Few-shot Performance of Language Models , author =. Proceedings of the 38th International Conference on Machine Learning , pages =. 2021 , editor =
2021
-
[75]
Advances in Neural Information Processing Systems , volume=
Judging llm-as-a-judge with mt-bench and chatbot arena , author=. Advances in Neural Information Processing Systems , volume=. 2023 , url=
2023
-
[76]
Science , volume=
Judgment under Uncertainty: Heuristics and Biases , author=. Science , volume=. 1974 , url=
1974
-
[77]
Personality and Social Psychology Bulletin , volume=
Measures of Anchoring in Estimation Tasks , author=. Personality and Social Psychology Bulletin , volume=. 1995 , url=
1995
-
[78]
The Journal of Socio-Economics , volume=
A Literature Review of the Anchoring Effect , author=. The Journal of Socio-Economics , volume=. 2011 , url=
2011
-
[79]
Journal of Open Psychology Data , volume=
The open anchoring quest dataset: Anchored estimates from 96 studies on anchoring effects , author=. Journal of Open Psychology Data , volume=. 2022 , url=
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.