Representation-Conditioned Diffusion Models for Guided Training Data Generation
Pith reviewed 2026-06-29 18:08 UTC · model grok-4.3
The pith
Conditioning latent diffusion models on DINO and CLIP representations generates synthetic images that train ImageNet classifiers to higher accuracy than real data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
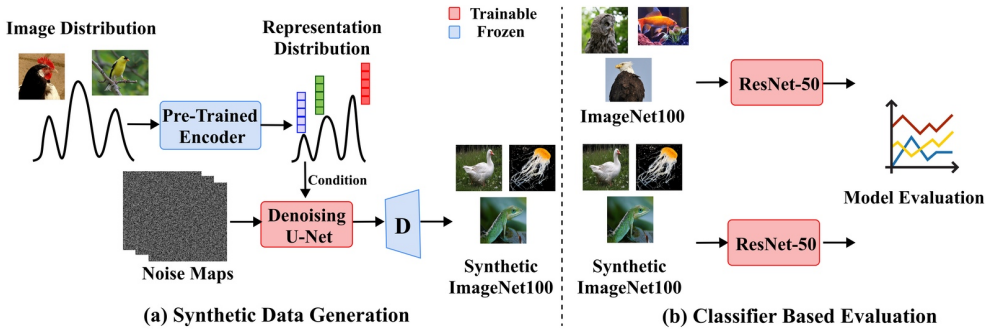
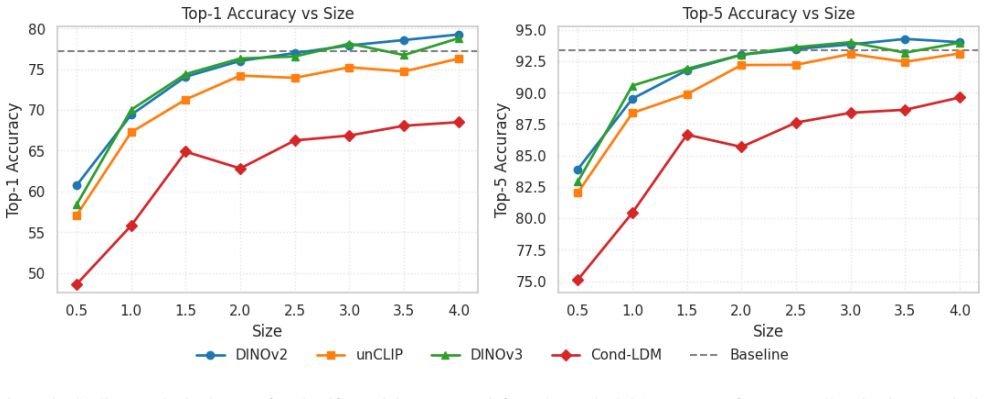
Latent diffusion models conditioned on learned representations from DINOv2, DINOv3, and CLIP produce synthetic images whose quality and mode coverage exceed those of class-conditioned generation, yielding +10.76 p.p. top-1 accuracy on ImageNet100; scaling the synthetic set size further allows a classifier trained only on generated images to surpass one trained on the real data by +2.0 p.p.
What carries the argument
Representation-conditioned latent diffusion, in which the denoising network receives a feature vector extracted by a frozen self-supervised model (DINO or CLIP) instead of a one-hot class label.
If this is right
- Increasing the volume of representation-conditioned synthetic images produces monotonic gains in downstream classifier accuracy.
- The same generated set can be filtered by proximity in the conditioning space to remove low-value samples and raise training performance further.
- Representation-conditioned images serve as effective augmentation data that outperform classical geometric and photometric augmentations.
- The performance gap over class-conditioned generation arises from both higher per-sample fidelity and better coverage of the real data distribution.
Where Pith is reading between the lines
- If the conditioning mechanism transfers to other modalities, the same approach could generate training data for audio or video tasks where labeled corpora are even scarcer.
- The method implicitly assumes access to a strong frozen representation model; weaker conditioning signals might narrow or eliminate the observed gains.
- Because the generated images are produced from the same representation space used for filtering, the pipeline could be closed-loop: generate, filter, retrain the conditioner, and repeat.
Load-bearing premise
Classifiers trained on the generated images will generalize to real test images without harmful distribution shift or mode-specific artifacts that would invalidate the reported accuracy numbers.
What would settle it
Train the reported classifier on a large set of the generated images and evaluate its top-1 accuracy on the real ImageNet100 validation set; if accuracy does not exceed the real-data baseline when the synthetic set is scaled, the central claim is false.
Figures
read the original abstract
Data availability remains a critical bottleneck in many deep learning applications. Large-scale datasets are often expensive to collect, curate and annotate, which can limit the scalability and applicability of supervised learning methods. In this work, we evaluate the classification performance of models trained on synthetic image datasets produced by generative deep learning. In particular, we use latent diffusion models conditioned on learned representations from DINOv2, DINOv3, and CLIP. Our results demonstrates that this representation-conditioned formulation significantly outperforms class-conditioned generation by a large margin (+10.76 p.p. top-1 accuracy on ImageNet100), by improving sample quality and mode coverage. Furthermore, by scaling the size of the synthetic dataset, we are able to outperform a classifier trained on the real data (+2.0 p.p top-1 accuracy). We also demonstrate how generated images can be used for augmentation purposes, outperforming classical augmentation methods, and how the conditioning space can be used for sample filtering to further improve training value. Collectively, these findings highlight that representation-conditioned diffusion models provide a promising approach for augmenting, complementing, or potentially replacing real-world datasets in large-scale visual learning tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes using latent diffusion models conditioned on learned representations from DINOv2, DINOv3, and CLIP (rather than class labels) to generate synthetic image datasets. It claims this representation-conditioned approach yields synthetic data that, when used to train classifiers on ImageNet100, outperforms class-conditioned generation by +10.76 p.p. top-1 accuracy and, when the synthetic dataset is scaled, outperforms a classifier trained on real data by +2.0 p.p. Additional uses for augmentation and conditioning-based filtering are demonstrated.
Significance. If the empirical gains prove robust, the work would be significant for data-scarce regimes in computer vision, as it suggests a practical route to generating training data whose downstream utility exceeds that of real data in at least one setting. The core idea of leveraging rich representation spaces for conditioning addresses a known limitation of class-conditional generators (mode collapse) and could influence future synthetic-data pipelines.
major comments (2)
- [Abstract] Abstract: the headline results (+10.76 p.p. over class-conditioned diffusion and +2.0 p.p. over real data) are presented with no description of experimental protocol, baseline implementations, data splits, training hyperparameters, statistical testing, or controls for confounding factors. Without these details the central empirical claim cannot be evaluated or reproduced.
- [Abstract] Abstract: the assertion that the method improves 'sample quality and mode coverage' rests solely on the downstream top-1 accuracy figures; no independent quantitative evidence (FID, precision/recall, per-class diversity, or distribution-shift diagnostics on held-out real data) is supplied to support that the synthetic marginal is close enough to the real marginal to avoid spurious features or harmful shift.
minor comments (2)
- [Abstract] Abstract: grammatical error ('Our results demonstrates' should read 'Our results demonstrate').
- [Abstract] Abstract: 'DINOv3' is referenced without citation or clarification; if it is a non-standard variant, a pointer to the implementation or paper is needed.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback. We agree that the abstract would benefit from greater self-containment and will revise it accordingly while preserving its brevity. Detailed responses to the major comments follow.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline results (+10.76 p.p. over class-conditioned diffusion and +2.0 p.p. over real data) are presented with no description of experimental protocol, baseline implementations, data splits, training hyperparameters, statistical testing, or controls for confounding factors. Without these details the central empirical claim cannot be evaluated or reproduced.
Authors: The full experimental protocol, including the ImageNet100 subset, class-conditioned LDM baselines, classifier training hyperparameters, and data splits, is provided in Sections 3 and 4 of the manuscript. No multiple-run statistical testing or explicit confounding controls beyond standard practices were performed. To address the concern, we will expand the abstract with a single sentence summarizing the core setup (dataset, conditioning sources, and evaluation protocol) while keeping the length appropriate for an abstract. revision: yes
-
Referee: [Abstract] Abstract: the assertion that the method improves 'sample quality and mode coverage' rests solely on the downstream top-1 accuracy figures; no independent quantitative evidence (FID, precision/recall, per-class diversity, or distribution-shift diagnostics on held-out real data) is supplied to support that the synthetic marginal is close enough to the real marginal to avoid spurious features or harmful shift.
Authors: Downstream accuracy on a held-out real test set is our primary and most application-relevant indicator of sample quality and mode coverage, as it directly measures whether the generated data enables better generalization than alternatives. We recognize that complementary distribution-level metrics would strengthen the claims. In the revision we will add FID, precision/recall, and per-class diversity statistics computed against the real ImageNet100 validation set. revision: yes
Circularity Check
No circularity; purely empirical comparisons without derivations or self-referential reductions.
full rationale
The paper reports empirical accuracy gains from training classifiers on synthetic images generated by representation-conditioned diffusion models versus class-conditioned baselines and real data. No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. All claims rest on direct experimental measurements against external baselines, satisfying the condition for a self-contained result with no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shekoofeh Azizi, Simon Kornblith, Chitwan Saharia, Mo- hammad Norouzi, and David J. Fleet. Synthetic data from diffusion models improves imagenet classification.Transac- tions on Machine Learning Research, 2023. 1
2023
-
[2]
High fidelity visual- ization of what your self-supervised representation knows about,
Florian Bordes, Randall Balestriero, and Pascal Vincent. High fidelity visualization of what your self-supervised rep- resentation knows about.arXiv preprint arXiv:2112.09164,
-
[3]
AutoAugment: Learning Augmentation Policies from Data
Ekin D Cubuk, Barret Zoph, Dandelion Mane, Vijay Vasude- van, and Quoc V Le. Autoaugment: Learning augmentation policies from data.arXiv preprint arXiv:1805.09501, 2018. 3
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[4]
Randaugment: Practical automated data augmen- tation with a reduced search space
Ekin D Cubuk, Barret Zoph, Jonathon Shlens, and Quoc V Le. Randaugment: Practical automated data augmen- tation with a reduced search space. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, pages 702–703, 2020. 2, 3
2020
-
[5]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016. 2
2016
-
[6]
Is syn- thetic data from generative models ready for image recogni- tion? InThe Eleventh International Conference on Learning Representations, 2023
Ruifei He, Shuyang Sun, Xin Yu, Chuhui Xue, Wenqing Zhang, Philip Torr, Song Bai, and XIAOJUAN QI. Is syn- thetic data from generative models ready for image recogni- tion? InThe Eleventh International Conference on Learning Representations, 2023. 1
2023
-
[7]
Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020. 1, 2
2020
-
[8]
Dino-diffusion: Scaling medical dif- fusion models via self-supervised pre-training
Guillermo Jimenez-Perez, Pedro Os ´orio, Josef Cersovsky, Javier Montalt-Tordera, Jens Hooge, Steffen V ogler, and Sadegh Mohammadi. Dino-diffusion: Scaling medical dif- fusion models via self-supervised pre-training. InAnnual Conference on Medical Image Understanding and Analysis, pages 257–274. Springer, 2025. 1
2025
-
[9]
Evaluating representation conditioned diffusion models: A comparative study of representation encoders
Nithesh Chandher Karthikeyan, Jonas Unger, and Gabriel Eilertsen. Evaluating representation conditioned diffusion models: A comparative study of representation encoders. Available at SSRN 5772685, 2025. 2
2025
-
[10]
Return of unconditional generation: A self-supervised representation generation method.Advances in Neural Information Pro- cessing Systems, 37:125441–125468, 2024
Tianhong Li, Dina Katabi, and Kaiming He. Return of unconditional generation: A self-supervised representation generation method.Advances in Neural Information Pro- cessing Systems, 37:125441–125468, 2024. 1
2024
-
[11]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 2
2021
-
[13]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image gener- ation with clip latents.arXiv preprint arXiv:2204.06125, 1 (2):3, 2022. 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[14]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 1, 2, 3
2022
-
[15]
Imagenet large scale visual recognition challenge.International journal of computer vision, 115(3):211–252, 2015
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, San- jeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al. Imagenet large scale visual recognition challenge.International journal of computer vision, 115(3):211–252, 2015. 2
2015
-
[16]
Oriane Sim ´eoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Micha ¨el Ramamonjisoa, et al. Dinov3.arXiv preprint arXiv:2508.10104, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Deep unsupervised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. InInternational confer- ence on machine learning, pages 2256–2265. pmlr, 2015. 1
2015
-
[18]
Effective data augmentation with diffu- sion models
Brandon Trabucco, Kyle Doherty, Max A Gurinas, and Rus- lan Salakhutdinov. Effective data augmentation with diffu- sion models. InThe Twelfth International Conference on Learning Representations, 2024. 1
2024
-
[19]
mixup: Beyond Empirical Risk Minimization
Hongyi Zhang, Moustapha Cisse, Yann N Dauphin, and David Lopez-Paz. mixup: Beyond empirical risk minimiza- tion.arXiv preprint arXiv:1710.09412, 2017. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[20]
Maximum-entropy adversarial data augmentation for im- proved generalization and robustness.Advances in Neural Information Processing Systems, 33:14435–14447, 2020
Long Zhao, Ting Liu, Xi Peng, and Dimitris Metaxas. Maximum-entropy adversarial data augmentation for im- proved generalization and robustness.Advances in Neural Information Processing Systems, 33:14435–14447, 2020. 3
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.