Context-Instrumental Data Distillation for Kubernetes Manifest Generation: Method and Experimental Evaluation
Pith reviewed 2026-06-29 23:04 UTC · model grok-4.3
The pith
Strict output format requirements improve small language model Kubernetes manifest quality more than adding training examples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
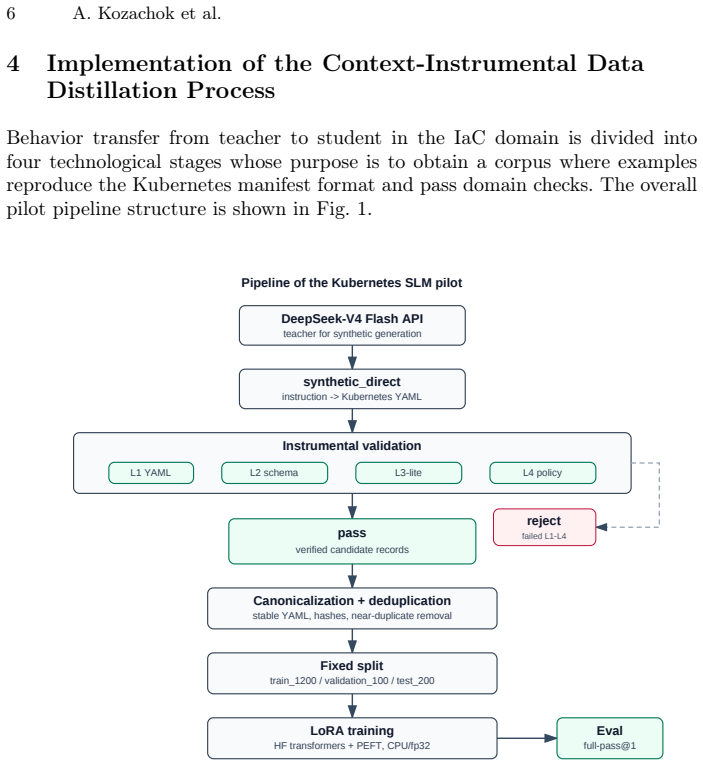
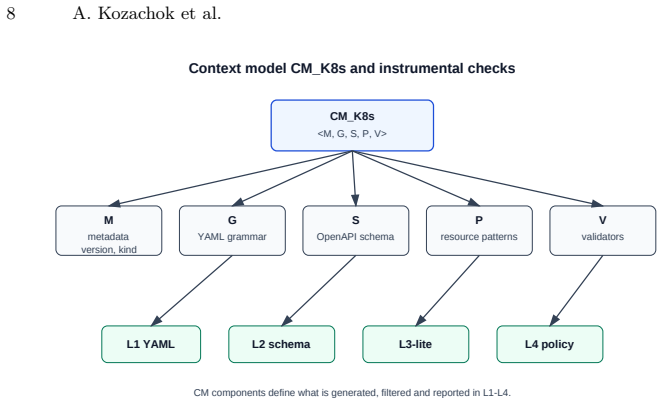
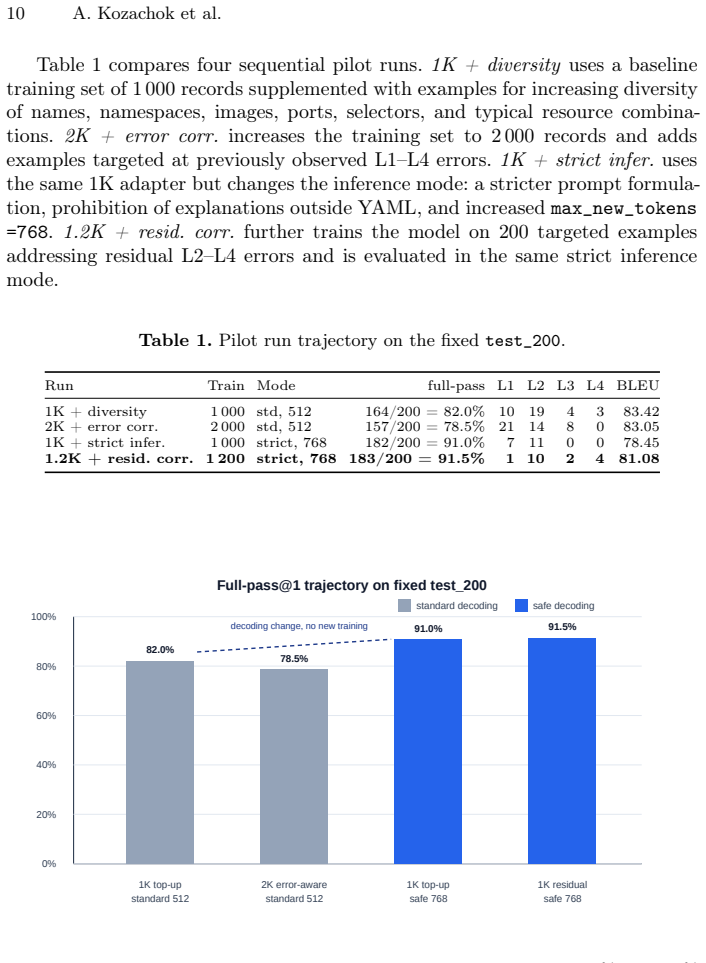
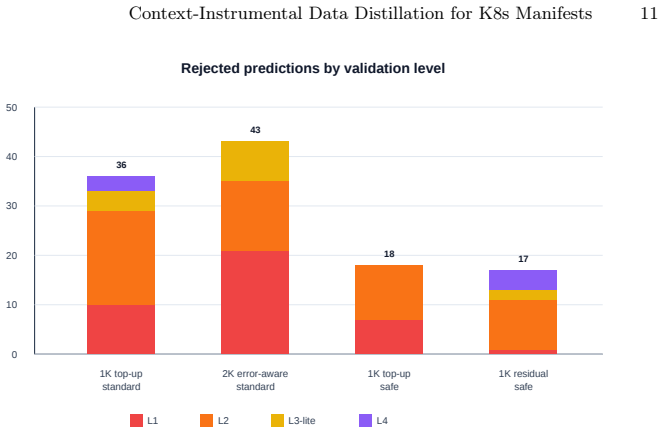
The context-instrumental data distillation method forms a corpus of synthetic and reverse-generated instruction pairs for Kubernetes manifests, includes them only after validation by external tools and a domain context model, and fine-tunes small models via supervised learning on the filtered data. In the pilot experiment, this produced a 91.5% full-pass@1 rate on 200 test cases when using strict prompt requirements and a token limit of 768, showing that format enforcement outweighed corpus size increases.
What carries the argument
Context-instrumental data distillation, which filters synthetic and reverse-instruction pairs using external validators and a domain context model before supervised fine-tuning.
If this is right
- Quality in Kubernetes YAML generation depends more on strict output format requirements than on the volume of training examples.
- Small language models with 1.5 billion parameters can achieve over 90 percent accuracy in generating valid manifests after fine-tuning on verified examples.
- The method allows specialization of models up to 4 billion parameters under resource constraints using CPU-based LoRA.
- Reverse instruction generation from real YAML files provides an additional source of training pairs when combined with validation.
Where Pith is reading between the lines
- This filtering approach might reduce the need for massive datasets in other domain-specific language generation tasks.
- Resource-constrained fine-tuning on CPU could extend to other infrastructure-as-code domains if similar validators exist.
- The emphasis on prompt strictness suggests that prompt engineering may interact strongly with data quality in DSL tasks.
Load-bearing premise
The external validators and domain context model correctly identify high-quality examples without excluding valid ones or allowing invalid data through.
What would settle it
Re-running the fine-tuning with human-validated examples instead of the automatic validators and measuring if full-pass@1 drops below 91.5%.
Figures
read the original abstract
This paper examines the specialization of Small Language Models (SLMs) with up to 4 billion parameters for generating artifacts in domain-specific languages (DSL). Kubernetes manifests are chosen as the target domain. We propose the context-instrumental data distillation method: the source corpus is formed through synthetic generation and, in an extended scheme, through reverse instruction generation from real Kubernetes YAML files, with pairs included in training only upon passing external validators and matching the domain context model. Unlike classical KL-divergence knowledge distillation, the baseline implementation reduces to supervised fine-tuning on instrumentally verified examples. The experimental section presents a pilot implementation under resource-constrained conditions: the DeepSeek-V4 Flash API serves as the teacher for synthetic generation, while Qwen2.5-Coder-1.5B-Instruct is fine-tuned via LoRA on CPU. On the K8s-Distill-Pilot corpus (train_1200, validation_100, test_200), we achieved full-pass@1 = 91.5% (183/200) with a stricter prompt formulation and max_new_tokens=768. The key empirical finding is that for Kubernetes YAML, result quality in the pilot depended more on strict output format requirements than on simply increasing the number of training examples.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the context-instrumental data distillation method for fine-tuning small language models (≤4B parameters) to generate Kubernetes manifests. The source corpus is built via synthetic generation (DeepSeek-V4 teacher) and reverse instruction from real YAML, with pairs retained only after passing external validators and a domain context model. This reduces to supervised fine-tuning (LoRA on Qwen2.5-Coder-1.5B-Instruct under CPU constraints). On the K8s-Distill-Pilot corpus (train_1200 / val_100 / test_200), the pilot reports full-pass@1 = 91.5% (183/200) using stricter prompt formulation and max_new_tokens=768. The central empirical claim is that output-format strictness affected quality more than simply increasing the number of training examples.
Significance. If the comparative claim on format versus quantity were substantiated with controlled ablations, the work could usefully inform data-curation priorities for resource-constrained DSL generation. The emphasis on instrumentally verified filtering is a methodological strength of the pilot. At present the absence of the required comparative results limits the strength of that specific finding.
major comments (2)
- [Abstract] Abstract: the claim that 'result quality in the pilot depended more on strict output format requirements than on simply increasing the number of training examples' is unsupported. No pass rates, ablation tables, or descriptions are supplied for non-strict prompts at matched example counts or for varying example counts under fixed prompt strictness, so the relative magnitude of the two factors cannot be assessed.
- [Experimental section] Experimental section (K8s-Distill-Pilot corpus description): the 91.5% full-pass@1 result is given without details on test-set construction, potential train/test leakage, or any baseline comparisons. This directly weakens the soundness of the key empirical finding.
minor comments (1)
- [Abstract] Abstract: the phrasing 'reduces to supervised fine-tuning on instrumentally verified examples' is accurate but could briefly contrast the approach with standard knowledge-distillation objectives for readers outside the subfield.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the central claim requires explicit supporting evidence and that the experimental section needs additional details on methodology and validation. We will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'result quality in the pilot depended more on strict output format requirements than on simply increasing the number of training examples' is unsupported. No pass rates, ablation tables, or descriptions are supplied for non-strict prompts at matched example counts or for varying example counts under fixed prompt strictness, so the relative magnitude of the two factors cannot be assessed.
Authors: We acknowledge that the manuscript does not provide the ablation studies or pass-rate comparisons needed to substantiate the relative impact of strict output formatting versus training example count. This claim was based on internal pilot observations that were not reported with quantitative details. In the revised version we will add the required ablation tables (comparing strict vs. non-strict prompts at matched example counts and varying example counts under fixed prompt strictness) or, if space constraints prevent full inclusion, we will qualify or remove the claim from the abstract. revision: yes
-
Referee: [Experimental section] Experimental section (K8s-Distill-Pilot corpus description): the 91.5% full-pass@1 result is given without details on test-set construction, potential train/test leakage, or any baseline comparisons. This directly weakens the soundness of the key empirical finding.
Authors: We agree that the experimental section lacks necessary details on test-set construction, checks for train/test leakage, and baseline comparisons, which limits evaluation of the 91.5% result. We will expand this section to describe how the 200 test examples were selected, any deduplication or leakage detection steps performed against the training set, and comparisons against baselines including the untuned Qwen2.5-Coder-1.5B-Instruct model under identical prompting conditions. revision: yes
Circularity Check
No circularity: purely empirical method and measurement
full rationale
The paper presents a data-generation and fine-tuning pipeline evaluated on held-out test examples. No equations, fitted parameters, or derivations are described. The reported 91.5% full-pass@1 is a direct count on the test_200 set after training on the filtered train_1200 set; it is not obtained by re-using the same quantity as an input or by any self-referential definition. The claim that format strictness mattered more than example count is an informal observation from a single pilot run and does not rely on any of the enumerated circular patterns. No self-citations or uniqueness theorems are invoked as load-bearing premises.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
https://connect.uptimeinstitute.com/resources/research-and-reports/annual- outage-analysis-2023
Uptime Institute: Annual Outage Analysis 2023 (2023). https://connect.uptimeinstitute.com/resources/research-and-reports/annual- outage-analysis-2023
2023
-
[2]
https://www.qualys.com/2023/totalcloud-security-insights/
Qualys Threat Research Unit: 2023 Qualys TotalCloud Security Insights (2023). https://www.qualys.com/2023/totalcloud-security-insights/
2023
-
[3]
Qwen2.5-Coder Technical Report
Hui, B., Yang, J., Cui, Z., et al.: Qwen2.5-Coder Technical Report. arXiv:2409.12186 (2024). https://doi.org/10.48550/arXiv.2409.12186
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2409.12186 2024
-
[4]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Abdin, M., Jacobs, S.A., Awan, A.A., et al.: Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone. arXiv:2404.14219 (2024). https://doi.org/10.48550/arXiv.2404.14219
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2404.14219 2024
-
[5]
Gunasekar, S., Zhang, Y., Aneja, J., et al.: Textbooks Are All You Need. arXiv:2306.11644 (2023). https://doi.org/10.48550/arXiv.2306.11644
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2306.11644 2023
-
[6]
Wei, Y., Wang, Z., Liu, J., Ding, Y., Zhang, L.: Magicoder: Source Code Is All You Need. arXiv:2312.02120 (2023). https://doi.org/10.48550/arXiv.2312.02120
-
[7]
Luo, Z., Xu, C., Zhao, P., et al.: WizardCoder: Empowering Code Large Language Models with Evol-Instruct. arXiv:2306.08568 (2023). https://doi.org/10.48550/arXiv.2306.08568
-
[8]
Patel, A., Raffel, C., Callison-Burch, C.: DataDreamer: A Tool for Synthetic Data Generation and Reproducible LLM Workflows. arXiv:2402.10379 (2024). https://doi.org/10.48550/arXiv.2402.10379
-
[9]
Foerster, Roberta Raileanu, and Maria Lomeli
Lupidi, A.M., Gemmell, C., Cancedda, N., et al.: Source2Synth: Synthetic Data Generation and Curation Grounded in Real Data Sources. arXiv:2409.08239 (2024). https://doi.org/10.48550/arXiv.2409.08239
-
[10]
Programming and Computer Software41(1), 49–64 (2015)
Zakharov, I.S., Mandrykin, M.U., Mutilin, V.S., Novikov, E.M., Petrenko, A.K., Khoroshilov, A.V.: Configurable Toolset for Static Verification of Operating Sys- tems Kernel Modules. Programming and Computer Software41(1), 49–64 (2015). https://doi.org/10.1134/S0361768815010065
-
[12]
Trudy ISP RAN29(3), 43–56 (2017)
Khoroshilov,A.V.,Shchepetkov,I.V.:ADV_SPM–FormalSecurityPolicyModels in Practice. Trudy ISP RAN29(3), 43–56 (2017). https://doi.org/10.15514/ispras- 2017-29(3)-4
-
[13]
Willard, B.T., Louf, R.: Efficient Guided Generation for Large Language Models. arXiv:2305.19234 (2023). https://doi.org/10.48550/arXiv.2305.19234
-
[14]
In: Proceedings of EMNLP 2023, pp
Geng, S., Josifoski, M., Peyrard, M., West, R.: Grammar-Constrained Decoding for Structured NLP Tasks without Finetuning. In: Proceedings of EMNLP 2023, pp. 10932–10952 (2023). https://doi.org/10.18653/v1/2023.emnlp-main.674
-
[15]
Park, K., Wang, J., Berg-Kirkpatrick, T., Polikarpova, N., D’Antoni, L.: Grammar-Aligned Decoding. arXiv:2405.21047 (2024). https://doi.org/10.48550/arXiv.2405.21047
-
[16]
Distilling the Knowledge in a Neural Network
Hinton, G., Vinyals, O., Dean, J.: Distilling the Knowledge in a Neural Network. arXiv:1503.02531 (2015). https://doi.org/10.48550/arXiv.1503.02531
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1503.02531 2015
-
[17]
Kocetkov, D., Li, R., Ben Allal, L., et al.: The Stack: 3 TB of Permissively Licensed SourceCode.arXiv:2211.15533(2022).https://doi.org/10.48550/arXiv.2211.15533
-
[18]
https://huggingface.co/datasets/substratusai/the-stack-yaml-k8s
Substratus AI: The Stack YAML K8s Dataset. https://huggingface.co/datasets/substratusai/the-stack-yaml-k8s
-
[19]
https://artifacthub.io/docs/api/ Context-Instrumental Data Distillation for K8s Manifests 15
Artifact Hub: API Documentation. https://artifacthub.io/docs/api/ Context-Instrumental Data Distillation for K8s Manifests 15
-
[20]
https://kubeconform.mandragor.org/docs/overview/
Kubeconform Documentation: A Fast Kubernetes Manifests Validator. https://kubeconform.mandragor.org/docs/overview/
-
[21]
https://github.com/bridgecrewio/checkov
Bridgecrew: Checkov – Static Code Analysis for Infrastructure as Code. https://github.com/bridgecrewio/checkov
-
[22]
https://trivy.dev/docs/
Aqua Security: Trivy Documentation – Misconfiguration Scanning for IaC and Kubernetes. https://trivy.dev/docs/
-
[23]
QLoRA: Efficient Finetuning of Quantized LLMs
Dettmers, T., Pagnoni, A., Holtzman, A., Zettlemoyer, L.: QLoRA: Efficient Finetuning of Quantized LLMs. arXiv:2305.14314 (2023). https://doi.org/10.48550/arXiv.2305.14314
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2305.14314 2023
-
[24]
Evaluating Large Language Models Trained on Code
Chen, M., Tworek, J., Jun, H., et al.: Evaluating Large Language Models Trained on Code. arXiv:2107.03374 (2021). https://doi.org/10.48550/arXiv.2107.03374
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2107.03374 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.