BCL: Bayesian In-Context Learning Framework for Information Extraction
Pith reviewed 2026-06-26 21:09 UTC · model grok-4.3
The pith
BCL applies particle filtering and Bayesian updates to refine label representations for information extraction tasks with large language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
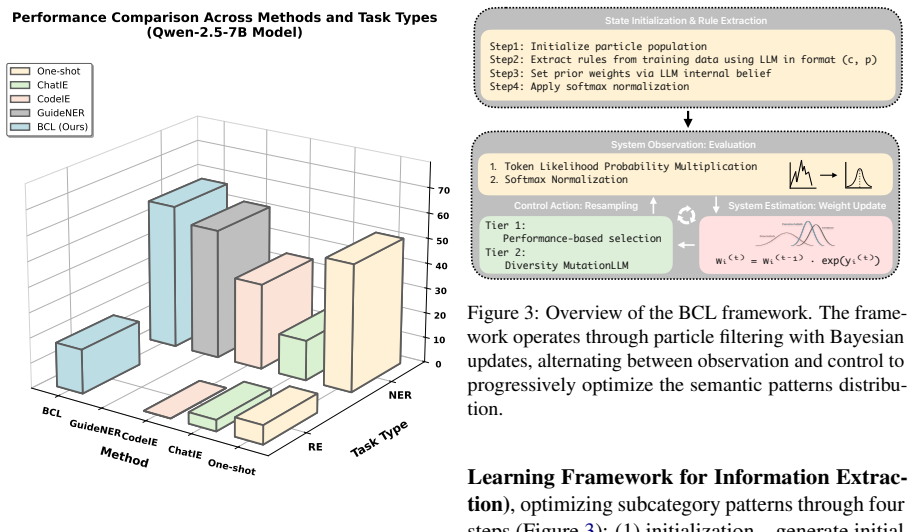
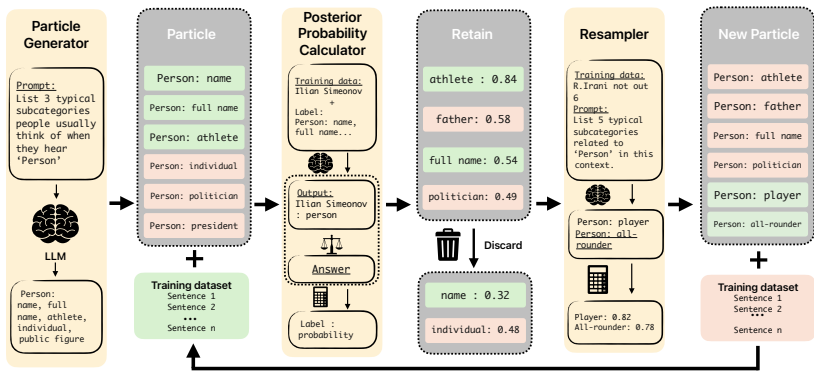
BCL is the first optimization framework that uses particle filtering with Bayesian updates to systematically refine label representations across IE tasks. Through four steps of initialization, observation, weight update, and resampling, BCL generalizes to both sequence labeling and relation classification paradigms and yields substantial and consistent improvements over existing approaches.
What carries the argument
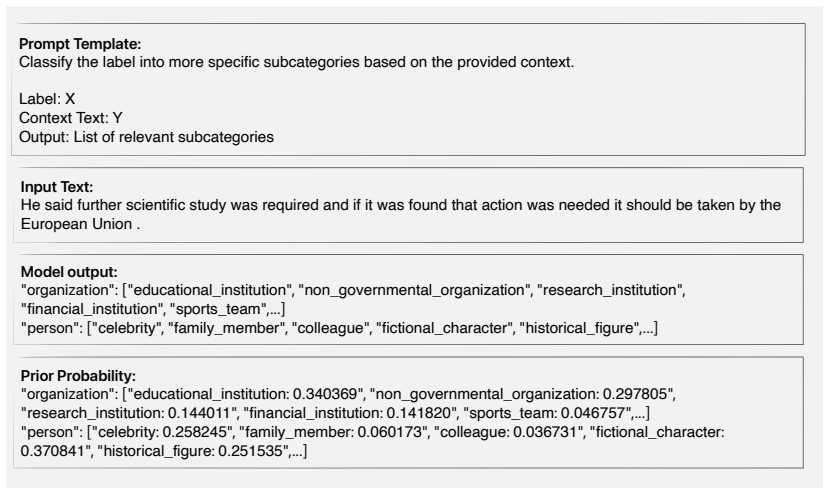
The four-step particle filtering process (initialization, observation, weight update, and resampling) combined with Bayesian updates, which iteratively refines label representations inside in-context prompts.
If this is right
- The same particle-filtering steps can be applied to both sequence labeling and relation classification without redesigning the core loop.
- Label representations become more stable across different large language model scales.
- Systematic refinement reduces the need for manual prompt engineering in information extraction.
- The Bayesian weight update step allows incremental incorporation of new observations into the label set.
Where Pith is reading between the lines
- The approach might transfer to other structured prediction tasks such as named entity recognition or event extraction by reusing the same four steps.
- If resampling introduces little bias, BCL could serve as a lightweight alternative to full fine-tuning for domain adaptation in extraction.
- Testing the framework on non-English or low-resource languages would reveal whether the Bayesian updates remain effective when initial label quality varies.
Load-bearing premise
The four-step particle filtering process will produce reliable improvements without requiring task-specific tuning or introducing bias from the choice of initial particles or resampling strategy.
What would settle it
A controlled test on standard IE benchmarks where BCL shows no gain or a decline relative to plain in-context learning, or where performance shifts sharply when the initial particle set or resampling method is altered.
Figures



read the original abstract
Existing information extraction (IE) tasks increasingly adopt in-context learning (ICL) with large language models. However, current approaches either show inconsistent performance across model scales or lack systematic optimization and generalizability. Building on this, we propose BCL (Bayesian In-Context Learning Framework for Information Extraction), the first optimization framework that uses particle filtering with Bayesian updates to systematically refine label representations across IE tasks. Through four steps initialization, observation, weight update, and resampling, BCL generalizes to both sequence labeling and relation classification paradigms. Extensive experiments demonstrate substantial and consistent improvements over existing approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes BCL, a Bayesian In-Context Learning framework for information extraction that applies particle filtering with Bayesian updates via four steps (initialization, observation, weight update, resampling) to refine label representations. It claims to be the first such optimization framework, generalizes to sequence labeling and relation classification, and reports substantial consistent improvements over existing ICL approaches on standard benchmarks.
Significance. If the empirical gains are reproducible and the Bayesian updates operate independently of fitted quantities, BCL could provide a systematic wrapper for optimizing ICL in IE tasks, addressing performance inconsistency across model scales. The particle-filtering integration is a potentially useful contribution if the four-step process yields reliable refinements without task-specific tuning.
minor comments (2)
- The abstract and introduction should include a brief comparison table or explicit statement of how BCL's particle-filtering steps differ from prior ICL optimization methods referenced in the framework description.
- Clarify in the method section whether the resampling strategy or initial particle choice introduces any bias, with a short ablation or sensitivity analysis to support the claim of reliable improvements.
Simulated Author's Rebuttal
We thank the referee for their positive summary of BCL and the recommendation of minor revision. We appreciate the recognition that the particle-filtering approach could serve as a useful wrapper for ICL optimization in IE tasks.
Circularity Check
No significant circularity detected
full rationale
The paper introduces BCL as a new wrapper framework around existing ICL methods, defining it explicitly via a four-step particle filtering process (initialization, observation, weight update, resampling) that is presented as an independent construction rather than derived from or fitted to the target outputs. No equations, self-citations, or prior results from the same authors are invoked as load-bearing premises that reduce the central claim to a tautology or renaming. The generalization across IE paradigms and empirical improvements are asserted via the method definition and benchmark results, with no evidence of self-definitional steps, fitted inputs relabeled as predictions, or ansatzes smuggled through citations. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=
-
[2]
2001 , publisher=
Sequential Monte Carlo methods in practice , author=. 2001 , publisher=
2001
-
[3]
Proceedings of the IEEE , volume=
Taking the human out of the loop: A review of Bayesian optimization , author=. Proceedings of the IEEE , volume=. 2015 , publisher=
2015
-
[4]
, author=
Handbook of Approximate Bayesian Computation. , author=. 2020 , publisher=
2020
-
[5]
Genetics , volume=
Approximate Bayesian computation in population genetics , author=. Genetics , volume=. 2002 , publisher=
2002
-
[6]
arXiv preprint arXiv:1807.02811 , year=
A tutorial on Bayesian optimization , author=. arXiv preprint arXiv:1807.02811 , year=
-
[7]
IEE proceedings F (radar and signal processing) , volume=
Novel approach to nonlinear/non-Gaussian Bayesian state estimation , author=. IEE proceedings F (radar and signal processing) , volume=. 1993 , organization=
1993
-
[8]
Automatic prompt optimization with" gradient descent" and beam search , author=. arXiv preprint arXiv:2305.03495 , year=
-
[9]
2021 , publisher=
Feedback systems: an introduction for scientists and engineers , author=. 2021 , publisher=
2021
-
[10]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[11]
International conference on machine learning , pages=
Calibrate before use: Improving few-shot performance of language models , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[12]
The eleventh international conference on learning representations , year=
Large language models are human-level prompt engineers , author=. The eleventh international conference on learning representations , year=
-
[13]
Communication, Simulation, and Intelligent Agents: Implications of Personal Intelligent Machines for Medical Education
Clancey, William J. Communication, Simulation, and Intelligent Agents: Implications of Personal Intelligent Machines for Medical Education. Proceedings of the Eighth International Joint Conference on Artificial Intelligence (IJCAI-83)
-
[14]
Classification Problem Solving
Clancey, William J. Classification Problem Solving. Proceedings of the Fourth National Conference on Artificial Intelligence
-
[15]
and De Meulder, Fien
Tjong Kim Sang, Erik F. and De Meulder, Fien. Introduction to the C o NLL -2003 Shared Task: Language-Independent Named Entity Recognition. Proceedings of the Seventh Conference on Natural Language Learning at HLT - NAACL 2003. 2003
2003
-
[16]
, title =
Robinson, Arthur L. , title =. 1980 , doi =. https://science.sciencemag.org/content/208/4447/1019.full.pdf , journal =
1980
-
[17]
New Ways to Make Microcircuits Smaller---Duplicate Entry
Robinson, Arthur L. New Ways to Make Microcircuits Smaller---Duplicate Entry. Science
-
[18]
Clancey and Glenn Rennels , abstract =
Diane Warner Hasling and William J. Clancey and Glenn Rennels , abstract =. Strategic explanations for a diagnostic consultation system , journal =. 1984 , issn =. doi:https://doi.org/10.1016/S0020-7373(84)80003-6 , url =
-
[19]
and Rennels, Glenn R
Hasling, Diane Warner and Clancey, William J. and Rennels, Glenn R. and Test, Thomas. Strategic Explanations in Consultation---Duplicate. The International Journal of Man-Machine Studies
-
[20]
Proceedings of the AAAI Conference on Artificial Intelligence , volume =
Xu, Tianyi and Liu, Jiaxin and Mattei, Nicholas and Zheng, Zizhan , title =. Proceedings of the AAAI Conference on Artificial Intelligence , volume =. 2026 , month = mar, doi =
2026
-
[21]
2026 , eprint=
Discovering What You Can Control: Interventional Boundary Discovery for Reinforcement Learning , author=. 2026 , eprint=
2026
-
[22]
Poligon: A System for Parallel Problem Solving
Rice, James. Poligon: A System for Parallel Problem Solving
-
[23]
Transfer of Rule-Based Expertise through a Tutorial Dialogue
Clancey, William J. Transfer of Rule-Based Expertise through a Tutorial Dialogue
-
[24]
The Engineering of Qualitative Models
Clancey, William J. The Engineering of Qualitative Models
-
[25]
2017 , eprint=
Attention Is All You Need , author=. 2017 , eprint=
2017
-
[26]
Pluto: The 'Other' Red Planet
NASA. Pluto: The 'Other' Red Planet
-
[27]
arXiv preprint arXiv:2301.00234 , year=
A survey on in-context learning , author=. arXiv preprint arXiv:2301.00234 , year=
-
[28]
International Conference on Learning Representations (ICLR) , year =
Intrinsic Entropy of Context Length Scaling in LLMs , author =. International Conference on Learning Representations (ICLR) , year =
-
[29]
Annual Meeting of the Association for Computational Linguistics (ACL) , year =
The Role of Deductive and Inductive Reasoning in Large Language Models , author =. Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[30]
Luo, Man and Xu, Xin and Dai, Zhuyun and Pasupat, Panupong and Kazemi, Mehran and Baral, Chitta and Imbrasaite, Vaiva and Zhao, Vincent , Title =. DATA INTELLIGENCE , Year =. doi:10.3724/2096-7004.di.2024.0012 , Keywords =
-
[31]
Chen, Chao and Luo, Pengfei and Feng, Changkai and Wu, Tian and Jiang, Wenbin and Xu, Tong , Title =. DATA INTELLIGENCE , Year =. doi:10.3724/2096-7004.di.2025.0025 , Unique-ID =
-
[32]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Multiple Human Motion Understanding , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[33]
Wang, Zihang and Liang, Ye and Sun, Wenwei and Lin, Qicong and Xu, Chao and Zhang, Yong , Title =. DATA INTELLIGENCE , Year =. doi:10.3724/2096-7004.di.2025.0078 , Unique-ID =
-
[34]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Human Motion Instruction Tuning , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[35]
The VLDB Journal , volume =
Li, Shuaimin and Chen, Xuanang and Song, Yuanfeng and Song, Yunze and Zhang, Chen Jason and Hao, Fei and Chen, Lei , title =. The VLDB Journal , volume =. 2025 , month =
2025
-
[36]
Proceedings of the 34th ACM International Conference on Information and Knowledge Management , series =
Xiong, Xubang and Wong, Raymond Chi-Wing and Song, Yuanfeng , title =. Proceedings of the 34th ACM International Conference on Information and Knowledge Management , series =. 2025 , month =
2025
-
[37]
Ji, Yuelyu and Li, Zhuochun and Meng, Rui and He, Daqing , title =. Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages =. 2025 , isbn =. doi:10.1145/3726302.3730070 , abstract =
-
[38]
Findings of the Association for Computational Linguistics: EMNLP , year =
Attention Consistency for LLMs Explanation , author =. Findings of the Association for Computational Linguistics: EMNLP , year =
-
[39]
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
CountLLM: Towards Generalizable Repetitive Action Counting via Large Language Model , author =. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[40]
Annual Meeting of the Association for Computational Linguistics (ACL) , year =
Bayesian Optimization for Controlled Image Editing via LLMs , author =. Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[41]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , pages =
Is Meta-Learning Out? Rethinking Unsupervised Few-Shot Classification with Limited Entropy , author =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , pages =
-
[42]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[43]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
Beyond Step Pruning: Information Theory Based Step-level Optimization for Self-Refining Large Language Models , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2026 , month=. doi:10.1609/aaai.v40i41.40798 , number=
-
[44]
arXiv preprint arXiv:2509.24253 , year=
MRAG-Suite: A Diagnostic Evaluation Platform for Visual Retrieval-Augmented Generation , author=. arXiv preprint arXiv:2509.24253 , year=
-
[45]
Pretraining on the Test Set Is No Longer All You Need: A Debate-Driven Approach to
Linbo Cao and Jinman Zhao , booktitle=. Pretraining on the Test Set Is No Longer All You Need: A Debate-Driven Approach to. 2025 , url=
2025
-
[46]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
GuideNER: Annotation Guidelines Are Better than Examples for In-Context Named Entity Recognition , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[47]
ACM computing surveys , volume=
Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing , author=. ACM computing surveys , volume=. 2023 , publisher=
2023
-
[48]
arXiv preprint arXiv:2109.01652 , year=
Finetuned language models are zero-shot learners , author=. arXiv preprint arXiv:2109.01652 , year=
-
[49]
arXiv preprint arXiv:2101.06804 , year=
What Makes Good In-Context Examples for GPT- 3 ? , author=. arXiv preprint arXiv:2101.06804 , year=
-
[50]
arXiv preprint arXiv:2112.08633 , year=
Learning to retrieve prompts for in-context learning , author=. arXiv preprint arXiv:2112.08633 , year=
-
[51]
arXiv preprint arXiv:2305.04320 , year=
Unified demonstration retriever for in-context learning , author=. arXiv preprint arXiv:2305.04320 , year=
-
[52]
arXiv , year=
Learning an Efficient Optimizer via Hybrid-Policy Sub-Trajectory Balance , author=. arXiv , year=
-
[53]
arXiv preprint arXiv:2412.07779 , year=
Evolution of Thought: Diverse and High-Quality Reasoning via Multi-Objective Optimization , author=. arXiv preprint arXiv:2412.07779 , year=
-
[54]
arXiv preprint arXiv:2203.15556 , year=
Training compute-optimal large language models , author=. arXiv preprint arXiv:2203.15556 , year=
-
[55]
B ayesian Optimization for Controlled Image Editing via LLM s
Cai, Chengkun and Liu, Haoliang and Zhao, Xu and Jiang, Zhongyu and Zhang, Tianfang and Wu, Zongkai and Lee, John and Hwang, Jenq-Neng and Li, Lei. B ayesian Optimization for Controlled Image Editing via LLM s. Findings of the Association for Computational Linguistics: ACL 2025. 2025
2025
-
[56]
arXiv preprint cs/0306050 , year=
Introduction to the CoNLL-2003 shared task: Language-independent named entity recognition , author=. arXiv preprint cs/0306050 , year=
Pith/arXiv arXiv 2003
-
[57]
arXiv preprint arXiv:2601.00536 , year=
Retrieval--Reasoning Processes for Multi-hop Question Answering: A Four-Axis Design Framework and Empirical Trends , author=. arXiv preprint arXiv:2601.00536 , year=
-
[58]
(No Title) , year=
Ace 2005 multilingual training corpus , author=. (No Title) , year=
2005
-
[59]
Bioinformatics , volume=
GENIA corpus—a semantically annotated corpus for bio-textmining , author=. Bioinformatics , volume=. 2003 , publisher=
2003
-
[60]
Joint European conference on machine learning and knowledge discovery in databases , pages=
Modeling relations and their mentions without labeled text , author=. Joint European conference on machine learning and knowledge discovery in databases , pages=. 2010 , organization=
2010
-
[61]
A linear programming formulation for global inference in natural language tasks , author=
-
[62]
arXiv preprint arXiv:2206.07682 , year=
Emergent abilities of large language models , author=. arXiv preprint arXiv:2206.07682 , year=
-
[63]
arXiv preprint arXiv:2202.12837 , year=
Rethinking the role of demonstrations: What makes in-context learning work? , author=. arXiv preprint arXiv:2202.12837 , year=
-
[64]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
GPT-RE: In-context Learning for Relation Extraction using Large Language Models , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[65]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Revisiting Relation Extraction in the era of Large Language Models , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[66]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
CodeIE: Large Code Generation Models are Better Few-Shot Information Extractors , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[67]
International Conference on Intelligent Computing , pages=
Reassessing the role of chain-of-thought in sentiment analysis: Insights and limitations , author=. International Conference on Intelligent Computing , pages=. 2025 , organization=
2025
-
[68]
arXiv preprint arXiv:2412.03944 , year=
Chain-of-Thought in Large Language Models: Decoding, Projection, and Activation , author=. arXiv preprint arXiv:2412.03944 , year=
-
[69]
arXiv preprint arXiv:2410.02892 , year=
The role of deductive and inductive reasoning in large language models , author=. arXiv preprint arXiv:2410.02892 , year=
-
[70]
arXiv preprint arXiv:2502.18180 , year=
Chatmotion: A multimodal multi-agent for human motion analysis , author=. arXiv preprint arXiv:2502.18180 , year=
-
[71]
arXiv preprint arXiv:2412.00091 , year=
Graph canvas for controllable 3d scene generation , author=. arXiv preprint arXiv:2412.00091 , year=
-
[72]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
C-ICL: Contrastive In-context Learning for Information Extraction , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[73]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
A Simple but Effective Approach to Improve Structured Language Model Output for Information Extraction , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[74]
Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence , pages=
Recall, retrieve and reason: towards better in-context relation extraction , author=. Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence , pages=
-
[75]
arXiv preprint arXiv:2302.10205 , year=
Chatie: Zero-shot information extraction via chatting with chatgpt , author=. arXiv preprint arXiv:2302.10205 , year=
-
[76]
arXiv preprint arXiv:2410.21155 , year=
SciER: An entity and relation extraction dataset for datasets, methods, and tasks in scientific documents , author=. arXiv preprint arXiv:2410.21155 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.