Poster: Exploring the Limits of Audio-Based Detection of Turkish Phone Call Scams
Pith reviewed 2026-06-25 23:49 UTC · model grok-4.3
The pith
Transcript inputs let LLMs detect Turkish phone scams better than raw audio.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
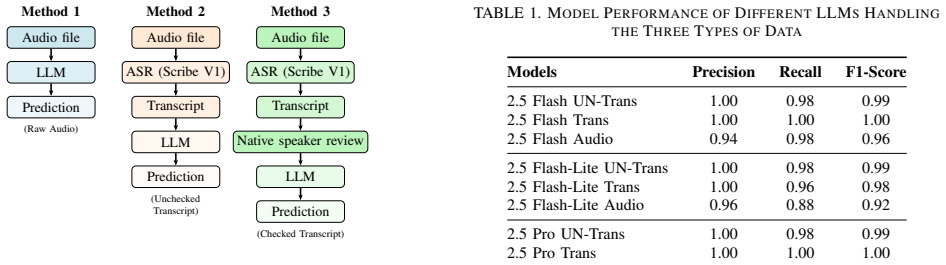
A new dataset of 100 Turkish audio-transcript pairs demonstrates that transcript-based inputs to LLMs consistently outperform direct audio processing for scam versus benign classification, with human correction adding little gain over automatic transcripts.
What carries the argument
Multi-modal evaluation across raw audio, automatic speech-to-text transcripts, and human-refined transcripts on seven LLMs from three families.
If this is right
- Automatic transcripts alone support effective LLM-based scam detection without extra human editing.
- Direct audio processing remains weaker than text routes in current models for this language and task.
- Public datasets centered on low-resource languages can expose gaps in existing multi-modal fraud systems.
- Transcript pipelines offer an immediate, low-cost way to extend detection to languages beyond English.
Where Pith is reading between the lines
- The same transcript-first pattern may appear when testing other low-resource languages that face phone scams.
- Future work could measure how much better audio models need to become to close the gap with transcripts.
- The released pairs could function as a shared test set for comparing new multi-modal detection methods.
Load-bearing premise
The 100 audio-transcript pairs capture enough variety of real Turkish scam calls for the observed performance gaps to hold on new calls.
What would settle it
Running the same seven models on a fresh collection of Turkish calls and finding that raw audio accuracy meets or exceeds transcript accuracy.
Figures
read the original abstract
Scam phone calls exploit vulnerable communities worldwide, yet research on detection has focused almost exclusively on English and other high-resource languages. In low-resource settings such as Turkish, detection is especially difficult, as annotated data is scarce and technological defenses remain limited. This research investigates how large language models (LLMs) can support scam detection in Turkish by introducing the first public multi-modal dataset of 100 aligned audio-transcript pairs of scam and benign conversations. We evaluate seven LLMs spanning three model families: Gemini 2.5 (Flash, Flash-Lite, Pro), GPT-4o, and Qwen (Max, Plus, Turbo), under three input conditions: raw audio, automatic speech-to-text transcripts, and transcripts refined by a native speaker. Our results suggest that transcript-based inputs consistently outperform direct audio processing, while human-corrected and uncorrected transcripts perform comparably. By centering a low-resource language and real world threat, this work highlights the urgent need for culturally and linguistically inclusive AI safety research and more robust multi-modal systems for fraud prevention.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the first public multi-modal dataset of 100 aligned audio-transcript pairs of Turkish scam and benign phone conversations. It evaluates seven LLMs (Gemini 2.5 variants, GPT-4o, Qwen variants) under three input conditions—raw audio, automatic speech-to-text transcripts, and human-corrected transcripts—and claims that transcript-based inputs consistently outperform direct audio processing while human-corrected and uncorrected transcripts perform comparably.
Significance. If the empirical comparisons hold after proper quantification, the work is significant for releasing the first such Turkish dataset and for drawing attention to scam detection in a low-resource language setting, which could stimulate further multi-modal AI safety research focused on real-world fraud prevention.
major comments (3)
- [Abstract] Abstract: The central claim that 'transcript-based inputs consistently outperform direct audio processing' is unsupported by any reported accuracy, F1 scores, confusion matrices, or statistical tests, rendering the performance difference unverifiable and potentially attributable to sampling noise.
- [Abstract] Abstract: With a fixed n=100 and no variance estimates, confidence intervals, class balance details (scam vs. benign), or paired significance tests, the generalizability of the observed differences to new Turkish scam calls cannot be assessed.
- [Abstract] Abstract: No information is provided on prompt templates, audio tokenization/processing details for the LLMs, exact per-model/per-condition metrics, or error analysis, all of which are required to substantiate the comparative results.
minor comments (1)
- [Abstract] The manuscript is labeled a 'Poster' but provides no indication of space constraints or additional figures/tables that might contain the missing quantitative results.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater quantitative transparency in the abstract. We will revise the abstract to include key performance metrics, class balance, and methodological details while noting inherent limitations of the poster format and small dataset. Point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'transcript-based inputs consistently outperform direct audio processing' is unsupported by any reported accuracy, F1 scores, confusion matrices, or statistical tests, rendering the performance difference unverifiable and potentially attributable to sampling noise.
Authors: We agree the abstract should report concrete metrics rather than a qualitative summary. We will add representative accuracy and F1 scores showing the transcript advantage across models. No confusion matrices or statistical tests were computed; we will explicitly note this in the revision. revision: yes
-
Referee: [Abstract] Abstract: With a fixed n=100 and no variance estimates, confidence intervals, class balance details (scam vs. benign), or paired significance tests, the generalizability of the observed differences to new Turkish scam calls cannot be assessed.
Authors: We will insert the class balance (50 scam / 50 benign) and a limitations statement on the fixed n=100. Variance estimates, confidence intervals, and significance tests were not performed; we will acknowledge this restricts strong claims about generalizability. revision: yes
-
Referee: [Abstract] Abstract: No information is provided on prompt templates, audio tokenization/processing details for the LLMs, exact per-model/per-condition metrics, or error analysis, all of which are required to substantiate the comparative results.
Authors: We will expand the abstract with a concise description of the zero-shot prompts and input conditions. Exact per-model metrics will be summarized; a brief error analysis note will be added where space allows in the poster format. revision: partial
Circularity Check
No significant circularity: purely empirical comparison with no derivations
full rationale
The paper introduces a dataset of 100 audio-transcript pairs and reports empirical performance of seven LLMs across three input conditions (raw audio, automatic transcripts, human-corrected transcripts). The central claims are observational comparisons of these results, with no equations, fitted parameters, predictions derived from the data, uniqueness theorems, or self-citations used to justify any derivation chain. All content is self-contained as direct experimental outcomes on the provided data, with no reduction of any result to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
It warned me just at the right moment: Exploring LLM-based real-time detection of phone scams,
Z. Shen, S. Yan, Y . Zhang, X. Luo, G. Ngai, and E. Y . Fu, “It warned me just at the right moment: Exploring LLM-based real-time detection of phone scams,” inProc. Extended Abstracts CHI Conf. Human Factors in Computing Systems, 2025, pp. 1–7
2025
-
[2]
Challenges encountered in Turkish natural language processing studies,
K. Tohma and Y . Kutlu, “Challenges encountered in Turkish natural language processing studies,”Natural and Engineering Sciences, vol. 5, no. 3, pp. 204–211, 2020
2020
-
[3]
Detecting telecommu- nication fraud by understanding the contents of a call,
Q. Zhao, K. Chen, T. Li, Y . Yang, and X. Wang, “Detecting telecommu- nication fraud by understanding the contents of a call,”Cybersecurity, vol. 1, no. 1, p. 8, 2018
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.