Reliability without Validity: A Systematic, Large-Scale Evaluation of LLM-as-a-Judge Models Across Agreement, Consistency, and Bias
Pith reviewed 2026-06-26 20:42 UTC · model grok-4.3
The pith
Exact-match agreement overstates LLM-as-a-Judge discriminative ability because it ignores chance agreement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
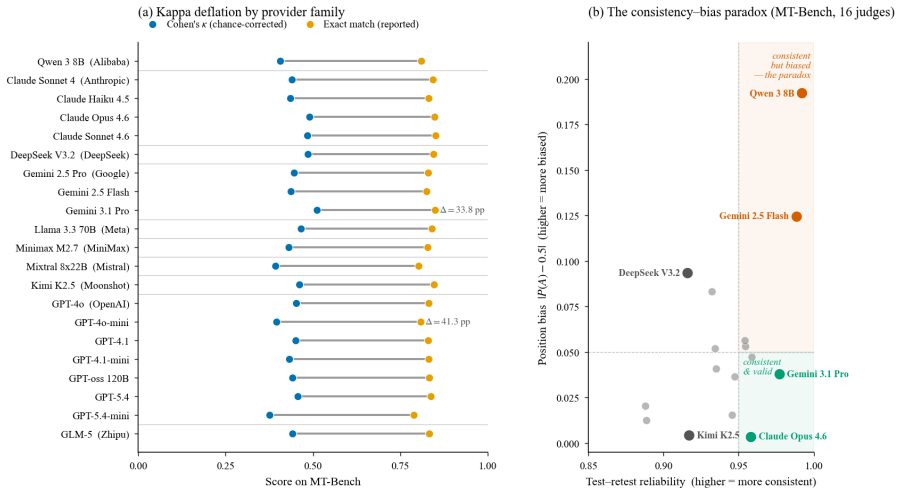
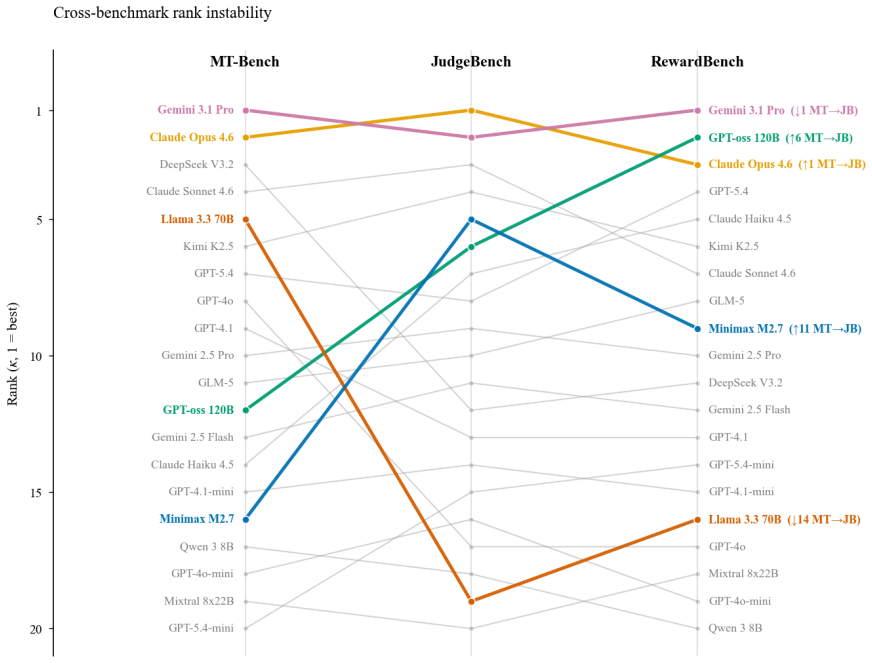
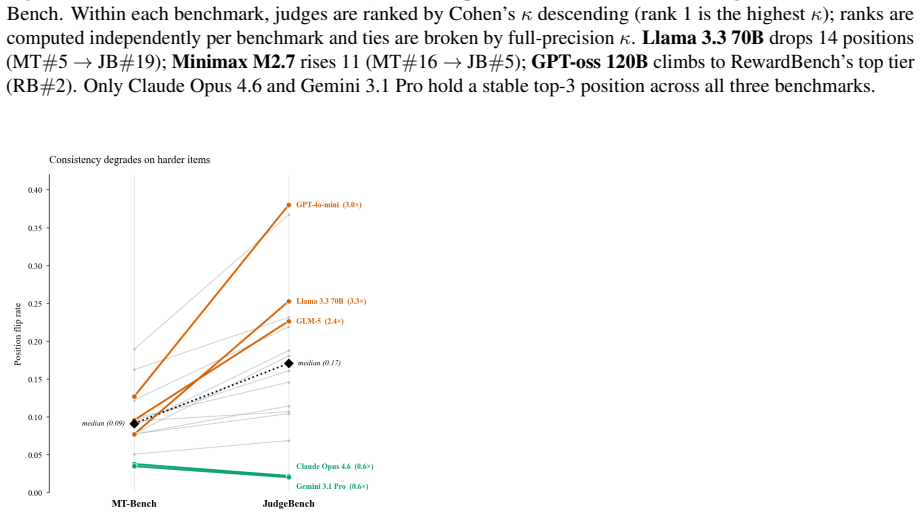
LLM-as-a-Judge validation in practice relies on exact-match agreement, a metric that does not correct for chance and systematically overstates discriminative ability. Across 21 judges evaluated on MT-Bench, JudgeBench, and RewardBench under agreement, consistency, and bias-audit protocols, kappa deflation is universal, judge orderings shift substantially with benchmark choice, high test-retest reliability can coexist with large position bias, and verbosity bias stays small under a fixed pairwise rubric.
What carries the argument
Comparison of exact-match agreement against Cohen's kappa, combined with separate consistency and bias audits, to expose overstatement in standard LLM-judge validation.
If this is right
- Judge rankings change by up to 14 positions when the benchmark is swapped.
- High test-retest consistency can coexist with position bias above 0.10 in deployed judges.
- Verbosity bias remains below 0.011 across the full cohort under one pairwise rubric.
- A Minimum Viable Validation Protocol that checks agreement, consistency, and bias together can be derived directly from the observed patterns.
Where Pith is reading between the lines
- Adopting chance-corrected metrics would likely change which judges are selected for production use.
- The consistency-bias paradox suggests that reliability numbers alone cannot certify a judge for downstream tasks.
- Reconciliation of divergent benchmark rankings may require new meta-benchmarks that combine multiple evaluation axes.
Load-bearing premise
The three selected benchmarks and three evaluation protocols are representative of typical real-world LLM-judge usage.
What would settle it
A study that applies the same three protocols to a fresh set of judges and benchmarks and finds no meaningful gap between exact-match agreement and chance-corrected kappa would falsify the central claim.
Figures
read the original abstract
LLM-as-a-Judge has become the dominant evaluation paradigm for language models, but judge validation in practice relies on exact-match agreement, a metric that does not correct for chance and systematically overstates discriminative ability. We present the largest systematic evaluation of LLM-as-a-Judge to date: 21 judges from nine providers across MT-Bench, JudgeBench, and RewardBench, evaluated under three protocols (agreement, consistency, bias audit) over 118 runs and approximately 541,000 individual judgments. Four findings emerge, consistent across the full cohort, including the April 2026 frontier: kappa deflation between exact match and Cohen's kappa is universal (33--41 pp on MT-Bench), judge rankings shift by up to 14 positions across benchmarks, high test--retest reliability (>0.95) coexists with severe position bias (>0.10) in two production-deployed judges (instantiating a consistency--bias paradox), and verbosity bias is small (<0.011) across our cohort under a single pairwise rubric. We distill these into a Minimum Viable Validation Protocol.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents the largest systematic evaluation to date of 21 LLM-as-a-Judge models from nine providers on MT-Bench, JudgeBench, and RewardBench under three protocols (agreement, consistency, bias audit), comprising 118 runs and approximately 541,000 judgments. It claims that validation in practice relies on exact-match agreement, which fails to correct for chance and systematically overstates discriminative ability (with universal kappa deflation of 33-41 pp on MT-Bench), that judge rankings shift by up to 14 positions across benchmarks, that high test-retest reliability (>0.95) can coexist with severe position bias (>0.10) in production judges, that verbosity bias is small (<0.011), and that these findings support a Minimum Viable Validation Protocol.
Significance. If the empirical patterns hold, the work provides a valuable large-scale demonstration of the limitations of exact-match agreement and the utility of chance-corrected metrics like Cohen's kappa, along with evidence of a consistency-bias paradox. The scale, consistency across the full cohort (including frontier models), and proposal of a concrete protocol are strengths that could inform improved evaluation practices in the field.
major comments (2)
- [Abstract] Abstract: The claim that exact-match agreement 'systematically overstates discriminative ability' in LLM-judge validation 'in practice' rests on an untested assumption that the label marginals, task distributions, and rubric structures of MT-Bench, JudgeBench, and RewardBench are representative of real-world deployments (e.g., open-ended summarization, code review, or safety filtering); no supporting analysis or comparison to production base rates is provided, which directly affects whether the observed 33-41 pp kappa deflation generalizes at the claimed scale.
- [Abstract] Abstract / implied Methods: No error bars, confidence intervals, or details on data exclusion rules are reported for the kappa deflation, ranking shifts, or bias metrics, and there is no indication of public access to raw judgments or code; this prevents verification of whether post-hoc choices influenced the central patterns reported as 'consistent across the full cohort'.
minor comments (1)
- [Abstract] Abstract: The phrase 'April 2026 frontier' lacks a clear definition or reference to specific model release dates or evaluation cutoffs.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that exact-match agreement 'systematically overstates discriminative ability' in LLM-judge validation 'in practice' rests on an untested assumption that the label marginals, task distributions, and rubric structures of MT-Bench, JudgeBench, and RewardBench are representative of real-world deployments (e.g., open-ended summarization, code review, or safety filtering); no supporting analysis or comparison to production base rates is provided, which directly affects whether the observed 33-41 pp kappa deflation generalizes at the claimed scale.
Authors: We agree that the generalization from the three evaluated benchmarks to all real-world deployments is an assumption rather than a directly tested claim. MT-Bench, JudgeBench, and RewardBench are the primary benchmarks used for LLM-judge validation in the current literature, and our multi-benchmark design was intended to demonstrate consistency across them. However, we did not include a direct comparison against production base rates or task distributions from deployed systems. In the revised manuscript we will qualify the abstract and discussion to state that the observed kappa deflation applies to validation practices using these standard benchmarks, and we will add an explicit limitations paragraph noting the absence of production data. revision: partial
-
Referee: [Abstract] Abstract / implied Methods: No error bars, confidence intervals, or details on data exclusion rules are reported for the kappa deflation, ranking shifts, or bias metrics, and there is no indication of public access to raw judgments or code; this prevents verification of whether post-hoc choices influenced the central patterns reported as 'consistent across the full cohort'.
Authors: We acknowledge that the current manuscript does not report error bars or confidence intervals for the key metrics and provides insufficient detail on data exclusion rules or data availability. In the revision we will add bootstrap confidence intervals for all reported statistics (kappa deflation, ranking shifts, bias scores) and include a dedicated subsection in Methods describing any exclusion criteria. We will also state that the full set of judgments and analysis code will be released publicly upon acceptance. revision: yes
Circularity Check
No circularity: purely empirical evaluation against external benchmarks.
full rationale
This is an empirical measurement study that reports observed agreement rates, kappa values, consistency scores, and bias metrics across 21 judges on three fixed external benchmarks (MT-Bench, JudgeBench, RewardBench) under three protocols. No equations, derivations, or predictions are present that reduce to the paper's own fitted parameters or self-referential definitions. All quantities are computed directly from the judgment data against human labels; no self-citation chains, uniqueness theorems, or ansatzes are invoked to justify core claims. The reported kappa deflation (33-41 pp) and ranking shifts are measured outcomes, not tautological restatements of inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The selected benchmarks (MT-Bench, JudgeBench, RewardBench) and protocols capture the primary failure modes of LLM judges in typical use.
Reference graph
Works this paper leans on
-
[1]
and Zhang, Hao and Gonzalez, Joseph E
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric P. and Zhang, Hao and Gonzalez, Joseph E. and Stoica, Ion , booktitle=. Judging. 2023 , url=
2023
-
[2]
Wang, Peiyi and Li, Lei and Chen, Liang and Cai, Zefan and Zhu, Dawei and Lin, Binghuai and Cao, Yunbo and Kong, Lingpeng and Liu, Qi and Liu, Tianyu and Sui, Zhifang. Large Language Models are not Fair Evaluators. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.ac...
-
[3]
G- eval: NLG evaluation using gpt-4 with better human alignment
Liu, Yang and Iter, Dan and Xu, Yichong and Wang, Shuohang and Xu, Ruochen and Zhu, Chenguang. G -Eval: NLG Evaluation using Gpt-4 with Better Human Alignment. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.153
-
[4]
and Hajishirzi, Hannaneh and Lambert, Nathan , booktitle=
Malik, Saumya and Pyatkin, Valentina and Land, Sander and Morrison, Jacob and Smith, Noah A. and Hajishirzi, Hannaneh and Lambert, Nathan , booktitle=. 2026 , url=
2026
-
[5]
Smith, and Hannaneh Hajishirzi
Lambert, Nathan and Pyatkin, Valentina and Morrison, Jacob and Miranda, LJ and Lin, Bill Yuchen and Chandu, Khyathi and Dziri, Nouha and Kumar, Sachin and Zick, Tom and Choi, Yejin and Smith, Noah A. and Hajishirzi, Hannaneh. R eward B ench: Evaluating Reward Models for Language Modeling. Findings of the Association for Computational Linguistics: NAACL 20...
-
[6]
2025 , url=
Tan, Sijun and Mavandadi, Sana and Tan, Amir and Tan, Rui and Tan, Dong-Ho and Mahyari, Arash , booktitle=. 2025 , url=
2025
-
[7]
Length-Controlled
Dubois, Yann and Galambosi, Bal. Length-Controlled. Conference on Language Modeling (COLM) , year=
-
[8]
From Crowdsourced Data to High-quality Benchmarks: Arena-Hard and Benchbuilder Pipeline , booktitle =
Tianle Li and Wei. From Crowdsourced Data to High-quality Benchmarks: Arena-Hard and Benchbuilder Pipeline , booktitle =. 2025 , url =
2025
-
[9]
The Thirteenth International Conference on Learning Representations,
Bill Yuchen Lin and Yuntian Deng and Khyathi Raghavi Chandu and Abhilasha Ravichander and Valentina Pyatkin and Nouha Dziri and Ronan Le Bras and Yejin Choi , title =. The Thirteenth International Conference on Learning Representations,. 2025 , url =
2025
-
[10]
, journal=
Jiang, Hongchao and Chen, Yiming and Cao, Yushi and Lee, Hung-yi and Tan, Robby T. , journal=. 2025 , url=
2025
-
[11]
2025 , url=
Whitehouse, Chenxi and Wang, Tianlu and Yu, Ping and Li, Xian and Weston, Jason and Kulikov, Ilia and Saha, Swarnadeep , journal=. 2025 , url=
2025
-
[12]
Judging the Judges: A Systematic Study of Position Bias in
Shi, Lin and Lei, Chiyu and Huang, Wenwen and Li, Ruiqi and Fu, Yankai , booktitle=. Judging the Judges: A Systematic Study of Position Bias in. 2025 , url=
2025
-
[13]
Style Over Substance: Evaluation Biases for Large Language Models
Wu, Minghao and Aji, Alham Fikri. Style Over Substance: Evaluation Biases for Large Language Models. Proceedings of the 31st International Conference on Computational Linguistics. 2025
2025
-
[14]
Bowman and Shi Feng , editor =
Arjun Panickssery and Samuel R. Bowman and Shi Feng , editor =. Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024 , year =
2024
-
[15]
arXiv preprint arXiv:2405.01724 , year=
Large Language Models are Inconsistent and Biased Evaluators , author=. arXiv preprint arXiv:2405.01724 , year=
-
[16]
Benchmarking cognitive biases in large language models as evaluators
Koo, Ryan and Lee, Minhwa and Raheja, Vipul and Park, Jong Inn and Kim, Zae Myung and Kang, Dongyeop. Benchmarking Cognitive Biases in Large Language Models as Evaluators. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.29
-
[17]
Split and Merge: Aligning Position Biases in
Li, Zongjie and Wang, Chaozheng and Liu, Pingchuan and Wang, Daoyuan and Yang, Dong and Wang, Shuai and Liu, Cuiyun , booktitle=. Split and Merge: Aligning Position Biases in. 2024 , url=
2024
-
[18]
Is LLM -as-a-Judge Robust? Investigating Universal Adversarial Attacks on Zero-shot LLM Assessment
Raina, Vyas and Liusie, Adian and Gales, Mark. Is LLM -as-a-Judge Robust? Investigating Universal Adversarial Attacks on Zero-shot LLM Assessment. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.427
-
[19]
Can You Trust
Schroeder, Kayla and Wood-Doughty, Zach , journal=. Can You Trust. 2024 , url=
2024
-
[20]
Bowman and Esin Durmus and Zac Hatfield
Mrinank Sharma and Meg Tong and Tomasz Korbak and David Duvenaud and Amanda Askell and Samuel R. Bowman and Esin Durmus and Zac Hatfield. Towards Understanding Sycophancy in Language Models , booktitle =. 2024 , url =
2024
-
[21]
International Conference on Learning Representations (ICLR) , year=
Prometheus: Inducing Fine-grained Evaluation Capability in Language Models , author=. International Conference on Learning Representations (ICLR) , year=
-
[22]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year=
Prometheus 2: An Open Source Language Model Specialized in Evaluating Other Language Models , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year=
2024
-
[23]
2025 , url=
Zhu, Lianghui and Wang, Xinggang and Wang, Xinlong , booktitle=. 2025 , url=
2025
-
[24]
Replacing Judges with Juries: Evaluating
Verga, Pat and Hofstatter, Sebastian and Althammer, Sophia and Su, Yixuan and Gurevych, Iryna and Hajishirzi, Hannaneh , journal=. Replacing Judges with Juries: Evaluating. 2024 , url=
2024
-
[25]
ChatEval: Towards Better LLM-based Evaluators through Multi-Agent Debate , booktitle =
Chi. ChatEval: Towards Better LLM-based Evaluators through Multi-Agent Debate , booktitle =. 2024 , url =
2024
-
[26]
A Survey on
Gu, Jiawei and Liang, Xuhui and Zheng, Yicheng and Wang, Heng and Zhu, Klara and Cai, Shangdi and Chen, Junyi and Wu, Shichao and Liu, Yong and Wang, Lingpeng , journal=. A Survey on. 2024 , url=
2024
-
[27]
2024 , url=
Li, Haitao and Li, Qianqian and others , journal=. 2024 , url=
2024
-
[28]
ACM Transactions on Intelligent Systems and Technology , year=
A Survey on Evaluation of Large Language Models , author=. ACM Transactions on Intelligent Systems and Technology , year=
-
[29]
2025 , url=
Bavaresco, Anna and Vecchi, Eva Maria and others , booktitle=. 2025 , url=
2025
-
[30]
Judging the Judges: Evaluating Alignment and Vulnerabilities in
Thakur, Aman Singh and Choudhary, Kartik and Venkatesh, Amod and Gaur, Pratibha and Liu, Shengjia , booktitle=. Judging the Judges: Evaluating Alignment and Vulnerabilities in. 2025 , url=
2025
-
[31]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL) , year=
Can Large Language Models Be an Alternative to Human Evaluations? , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL) , year=
-
[32]
Judge's Verdict: A Comprehensive Analysis of
Han, Steve and Titericz, Gilberto Junior and Balough, Tom and Zhou, Wenfei , journal=. Judge's Verdict: A Comprehensive Analysis of. 2025 , url=
2025
-
[33]
and Willi, Timon and Leontiadis, Ilias , journal=
Collot, Stephane and Fraser, Colin and Zhao, Justin and Shen, William F. and Willi, Timon and Leontiadis, Ilias , journal=. Balanced Accuracy: The Right Metric for Evaluating. 2025 , url=
2025
-
[34]
Validating
Guerdan, Luke and others , booktitle=. Validating. 2025 , url=
2025
-
[35]
Educational and Psychological Measurement , volume=
A Coefficient of Agreement for Nominal Scales , author=. Educational and Psychological Measurement , volume=
-
[36]
Computing
Krippendorff, Klaus , journal=. Computing
-
[37]
Communication Methods and Measures , volume=
Answering the Call for a Standard Reliability Measure for Coding Data , author=. Communication Methods and Measures , volume=. 2007 , publisher=
2007
-
[38]
The Twelfth International Conference on Learning Representations,
Seonghyeon Ye and Doyoung Kim and Sungdong Kim and Hyeonbin Hwang and Seungone Kim and Yongrae Jo and James Thorne and Juho Kim and Minjoon Seo , title =. The Twelfth International Conference on Learning Representations,. 2024 , url =
2024
-
[39]
Choi, Junhyuk and Park, Sohhyung and Cho, Chanhee and Park, Hyeonchu and Kim, Bugeun , year=. Diagnosing the Reliability of. 2602.00521 , archivePrefix=
-
[40]
Strick van Linschoten, Alex , howpublished=. What 1. 2025 , month=
2025
-
[41]
, booktitle=
Doddapaneni, Sumanth and Khan, Mohammed Safi Ur Rahman and Verma, Sshubam and Khapra, Mitesh M. , booktitle=. Finding Blind Spots in Evaluator. 2024 , url=
2024
-
[42]
Rating Roulette: Self-Inconsistency in
Haldar, Rajarshi and Hockenmaier, Julia. Rating Roulette: Self-Inconsistency in LLM -As-A-Judge Frameworks. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.1361
-
[43]
Humans or LLMs as the judge? a study on judgement bias
Chen, Guiming Hardy and Chen, Shunian and Liu, Ziche and Jiang, Feng and Wang, Benyou. Humans or LLM s as the Judge? A Study on Judgement Bias. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.474
-
[44]
Improving LLM -as-a-Judge Inference with the Judgment Distribution
Wang, Victor and Zhang, Michael JQ and Choi, Eunsol. Improving LLM -as-a-Judge Inference with the Judgment Distribution. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.1259
-
[45]
From generation to judgment: Opportunities and challenges of LLM-as-a-judge
Li, Dawei and Jiang, Bohan and Huang, Liangjie and Beigi, Alimohammad and Zhao, Chengshuai and Tan, Zhen and Bhattacharjee, Amrita and Jiang, Yuxuan and Chen, Canyu and Wu, Tianhao and Shu, Kai and Cheng, Lu and Liu, Huan. From Generation to Judgment: Opportunities and Challenges of LLM -as-a-judge. Proceedings of the 2025 Conference on Empirical Methods ...
-
[46]
Not All Voices Are Rewarded Equally: Probing and Repairing Reward Models across Human Diversity
Li, Zihao and Fang, Feihao and Zhang, Xitong and Zou, Jiaru and Liu, Zhining and Xiong, Wei and Wu, Ziwei and Jing, Baoyu and He, Jingrui. Not All Voices Are Rewarded Equally: Probing and Repairing Reward Models across Human Diversity. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.183
-
[47]
Can You Trick the Grader? Adversarial Persuasion of LLM Judges
Hwang, Yerin and Lee, Dongryeol and Kang, Taegwan and Kim, Yongil and Jung, Kyomin. Can You Trick the Grader? Adversarial Persuasion of LLM Judges. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.790
-
[48]
How Reliable is Multilingual LLM -as-a-Judge?
Fu, Xiyan and Liu, Wei. How Reliable is Multilingual LLM -as-a-Judge?. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.587
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.