STAR: Rethinking MoE Routing as Structure-Aware Subspace Learning
Pith reviewed 2026-06-27 18:26 UTC · model grok-4.3
The pith
STAR improves MoE expert specialization by aligning router decisions with an evolving principal subspace of input structure.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
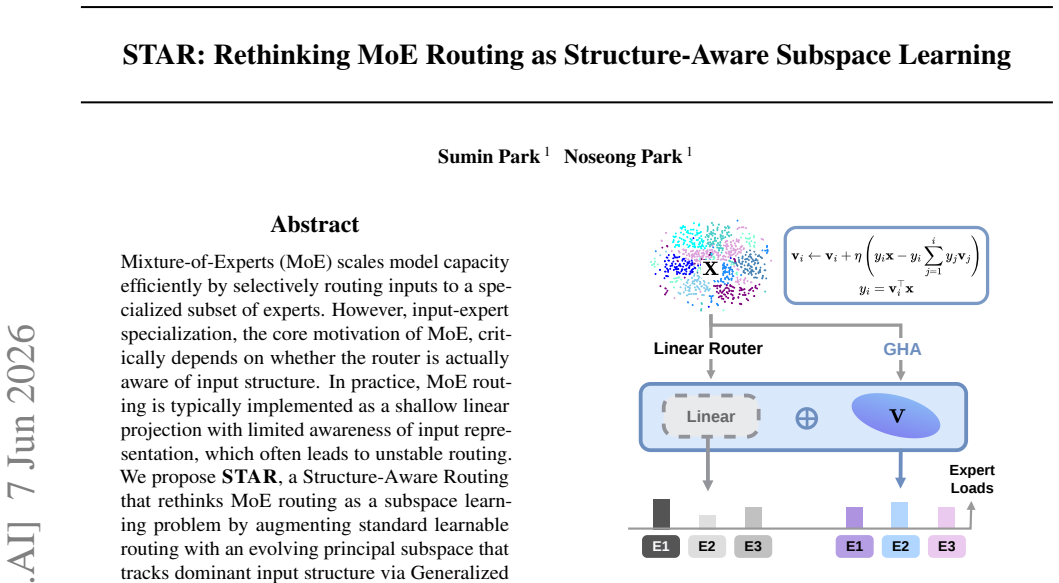
We propose STAR, a Structure Aware Routing that rethinks MoE routing as a subspace learning problem by augmenting standard learnable routing with an evolving principal subspace that tracks dominant input structure via Generalized Hebbian Algorithm (GHA). By aligning routing decisions directly with input structure, STAR enables stable expert specialization.
What carries the argument
The evolving principal subspace tracked by the Generalized Hebbian Algorithm (GHA) that is aligned with the standard routing projection to enforce structure awareness.
If this is right
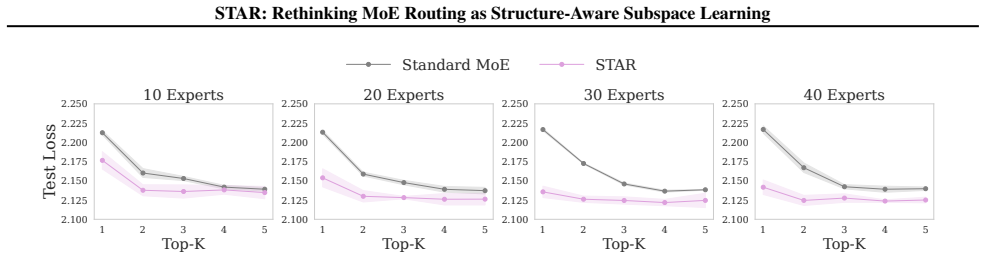
- Routing quality and downstream task performance improve consistently over standard MoE baselines on synthetic, language, and vision benchmarks.
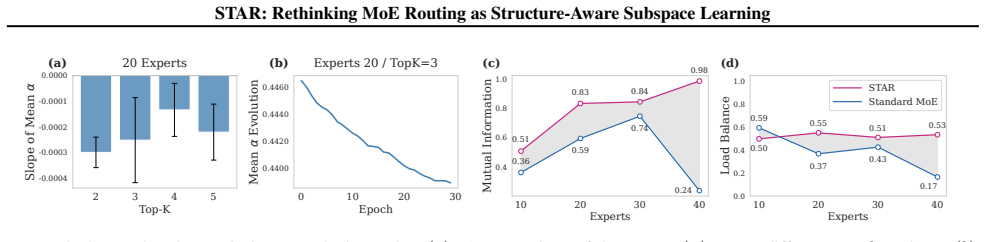
- Expert specialization becomes more stable because routing decisions are forced to respect the tracked input structure.
- Optional test-time subspace updates increase robustness when inputs undergo distribution shift.
Where Pith is reading between the lines
- The same subspace-alignment idea could be applied to other sparse activation schemes such as Switch Transformers or sparse attention patterns.
- If the subspace remains useful across training epochs, it might reduce the amount of auxiliary losses needed to prevent expert collapse.
- Periodic subspace refresh could serve as a lightweight alternative to full router retraining when adapting a deployed MoE model to new domains.
Load-bearing premise
The principal subspace captured by the Generalized Hebbian Algorithm will contain the parts of input structure that actually determine good routing decisions.
What would settle it
A controlled experiment on data with known dominant subspaces where adding the GHA term produces no measurable gain in routing stability or downstream accuracy compared with the plain linear router.
Figures

read the original abstract
Mixture-of-Experts (MoE) scales model capacity efficiently by selectively routing inputs to a specialized subset of experts. However, input-expert specialization, the core motivation of MoE, critically depends on whether the router is actually aware of input structure. In practice, MoE routing is typically implemented as a shallow linear projection with limited awareness of input representation, which often leads to unstable routing. We propose STAR, a Structure Aware Routing that rethinks MoE routing as a subspace learning problem by augmenting standard learnable routing with an evolving principal subspace that tracks dominant input structure via Generalized Hebbian Algorithm (GHA). By aligning routing decisions directly with input structure, STAR enables stable expert specialization. We evaluate STAR on controlled synthetic setup and large-scale language and vision tasks, where it consistently improves routing quality and downstream performance over strong MoE baselines. Moreover, optional test-time subspace updates further enhance routing robustness and generalization under input distribution shifts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes STAR, which augments standard MoE linear routing with an evolving principal subspace tracked online via the Generalized Hebbian Algorithm (GHA). The central claim is that aligning router decisions with this input-structure subspace produces more stable expert specialization, yielding consistent gains in routing quality and downstream performance on synthetic, language, and vision benchmarks; optional test-time subspace updates are also claimed to improve robustness under distribution shift.
Significance. If the GHA subspace demonstrably supplies routing-relevant directions rather than low-level variance, the method offers a lightweight, online mechanism for injecting structural awareness into MoE routers without altering the expert architecture. The multi-domain evaluation and test-time adaptation option are positive features; however, the significance is tempered by the absence of direct evidence that the tracked subspace improves specialization beyond what extra parameters or regularization would achieve.
major comments (3)
- [§3] §3 (Method), GHA augmentation paragraph: the claim that the principal subspace 'tracks dominant input structure' relevant to routing is load-bearing, yet the manuscript provides no analysis showing that the top eigenvectors of the input covariance align with features that determine expert assignment rather than token-frequency or local correlation statistics. A concrete test (e.g., correlation between subspace projections and oracle routing labels on the synthetic task) is required.
- [§5.1] §5.1 (Synthetic experiments), routing-stability metric: the reported improvement in 'stable expert specialization' is quantified only by downstream accuracy; without an explicit measure such as routing entropy variance across training steps or expert activation overlap, it is impossible to verify that the GHA term, rather than the added capacity, drives the claimed stability.
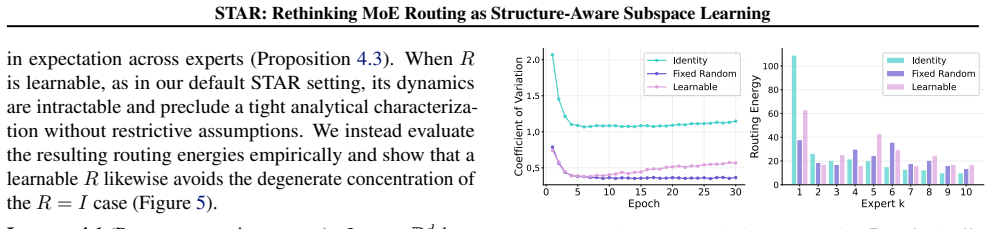
- [Table 2] Table 2 (large-scale results), ablation rows: the comparison to 'standard MoE' does not isolate the contribution of the GHA subspace from the extra parameters introduced by the subspace projection. An ablation that freezes the subspace or replaces it with random directions is needed to support the structure-awareness interpretation.
minor comments (2)
- [§3] Notation for the GHA update rule is introduced without an explicit equation number; adding Eq. (X) would improve traceability.
- [Abstract / §4] The abstract states 'consistently improves ... over strong MoE baselines' but does not name the baselines; the experimental section should list them explicitly in the first paragraph.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will incorporate the suggested analyses and ablations in the revised manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Method), GHA augmentation paragraph: the claim that the principal subspace 'tracks dominant input structure' relevant to routing is load-bearing, yet the manuscript provides no analysis showing that the top eigenvectors of the input covariance align with features that determine expert assignment rather than token-frequency or local correlation statistics. A concrete test (e.g., correlation between subspace projections and oracle routing labels on the synthetic task) is required.
Authors: We agree that a direct correlation analysis would strengthen the interpretation. The synthetic task provides oracle routing labels derived from the underlying generative structure. In the revision we will add the requested correlation between GHA subspace projections and these oracle labels (as well as a comparison against token-frequency baselines) to demonstrate that the tracked directions align with routing-relevant features rather than low-level statistics. revision: yes
-
Referee: [§5.1] §5.1 (Synthetic experiments), routing-stability metric: the reported improvement in 'stable expert specialization' is quantified only by downstream accuracy; without an explicit measure such as routing entropy variance across training steps or expert activation overlap, it is impossible to verify that the GHA term, rather than the added capacity, drives the claimed stability.
Authors: We concur that an explicit stability metric is needed to isolate the GHA contribution. In the revised §5.1 we will report routing entropy variance across training steps and expert activation overlap (Jaccard index between consecutive activation sets) for both STAR and the baseline, allowing direct verification that the observed stability gains are attributable to the subspace term. revision: yes
-
Referee: [Table 2] Table 2 (large-scale results), ablation rows: the comparison to 'standard MoE' does not isolate the contribution of the GHA subspace from the extra parameters introduced by the subspace projection. An ablation that freezes the subspace or replaces it with random directions is needed to support the structure-awareness interpretation.
Authors: We will add the requested controls to Table 2: (i) a frozen-subspace variant (GHA directions fixed after an initial warm-up phase) and (ii) a random-direction variant (orthogonal random projections of the same dimensionality). These ablations will be run on the language and vision benchmarks and reported alongside the existing rows, directly isolating the benefit of the learned structure-aware subspace from mere parameter count. revision: yes
Circularity Check
No circularity detected; derivation is self-contained
full rationale
The paper introduces STAR as an augmentation to standard MoE routing by adding a GHA-based principal subspace tracker. The central claim (improved routing stability and expert specialization) rests on this new mechanism plus empirical evaluation on synthetic, language, and vision tasks. No load-bearing step reduces by construction to fitted parameters, self-citations, or renamed inputs; GHA is a standard external algorithm, and performance gains are presented as experimental outcomes rather than algebraic identities. The derivation chain therefore remains independent of its own outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Generalized Hebbian Algorithm produces a principal subspace that captures dominant input structure relevant to expert routing.
Reference graph
Works this paper leans on
-
[1]
Cai, W., Jiang, J., Wang, F., Tang, J., Kim, S., and Huang, J
URL https://arxiv.org/abs/ 1911.11641. Cai, W., Jiang, J., Wang, F., Tang, J., Kim, S., and Huang, J. A survey on mixture of experts in large language models.IEEE Transactions on Knowledge and Data Engineering, pp. 1–20,
Pith/arXiv arXiv 1911
-
[2]
A Survey on Mixture of Experts in Large Language Models , ISSN=
ISSN 2326-3865. doi: 10.1109/tkde.2025.3554028. URL http://dx.doi. org/10.1109/TKDE.2025.3554028. Clark, C., Lee, K., Chang, M.-W., Kwiatkowski, T., Collins, M., and Toutanova, K. BoolQ: Exploring the surprising difficulty of natural yes/no questions. In Burstein, J., Do- ran, C., and Solorio, T. (eds.),Proceedings of the 2019 Conference of the North Amer...
-
[3]
Associ- ation for Computational Linguistics. doi: 10.18653/v1/ N19-1300. URL https://aclanthology.org/ N19-1300/. Clark, P., Cowhey, I., Etzioni, O., Khot, T., Sabharwal, A., Schoenick, C., and Tafjord, O. Think you have solved question answering? try arc, the ai2 reasoning challenge,
-
[4]
Dai, D., Deng, C., Zhao, C., Xu, R
URL https://arxiv.org/abs/ 1803.05457. Dai, D., Deng, C., Zhao, C., Xu, R. X., Gao, H., Chen, D., Li, J., Zeng, W., Yu, X., Wu, Y ., Xie, Z., Li, Y . K., Huang, P., Luo, F., Ruan, C., Sui, Z., and Liang, W. Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts language models,
-
[5]
URLhttps: //arxiv.org/abs/2401.06066. DeepSeek-AI, Liu, A., Feng, B., Wang, B., Wang, B., Liu, B., Zhao, C., Dengr, C., Ruan, C., Dai, D., Guo, D., Yang, D., Chen, D., Ji, D., Li, E., Lin, F., Luo, F., Hao, G., Chen, G., Li, G., Zhang, H., Xu, H., Yang, H., Zhang, H., Ding, H., Xin, H., Gao, H., Li, H., Qu, H., Cai, J. L., Liang, J., Guo, J., Ni, J., Li, ...
-
[6]
Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K
URL https://arxiv.org/abs/2405.04434. Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. Bert: Pre-training of deep bidirectional transformers for lan- guage understanding. InProceedings of the 2019 confer- ence of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), ...
Pith/arXiv arXiv 2019
-
[7]
URL https: //arxiv.org/abs/2010.11929. Dou, S., Zhou, E., Liu, Y ., Gao, S., Zhao, J., Shen, W., Zhou, Y ., Xi, Z., Wang, X., Fan, X., Pu, S., Zhu, J., Zheng, R., Gui, T., Zhang, Q., and Huang, X. Loramoe: Alleviate world knowledge forgetting in large language models via moe-style plugin,
Pith/arXiv arXiv 2010
-
[8]
Eigen, D., Ranzato, M., and Sutskever, I
URL https://arxiv.org/ abs/2312.09979. Eigen, D., Ranzato, M., and Sutskever, I. Learning factored representations in a deep mixture of experts,
-
[9]
Fedus, W., Zoph, B., and Shazeer, N
URL https://arxiv.org/abs/1312.4314. Fedus, W., Zoph, B., and Shazeer, N. Switch transformers: Scaling to trillion parameter models with simple and ef- ficient sparsity,
-
[10]
URL https://arxiv.org/ abs/2101.03961. Gao, L., Biderman, S., Black, S., Golding, L., Hoppe, T., Foster, C., Phang, J., He, H., Thite, A., Nabeshima, N., Presser, S., and Leahy, C. The pile: An 800gb dataset of diverse text for language modeling,
-
[11]
Guo, Y ., Cheng, Z., Tang, X., Tu, Z., and Lin, T
URL https: //arxiv.org/abs/2101.00027. Guo, Y ., Cheng, Z., Tang, X., Tu, Z., and Lin, T. Dy- namic mixture of experts: An auto-tuning approach for efficient transformer models,
-
[12]
URL https: //arxiv.org/abs/2405.14297. Hendrycks, D. and Dietterich, T. Benchmarking neural network robustness to common corruptions and pertur- bations,
-
[13]
URL https://arxiv.org/abs/ 1903.12261. Jacobs, R. A., Jordan, M. I., Nowlan, S. J., and Hinton, G. E. Adaptive mixtures of local experts.Neural Computation, 3(1):79–87,
Pith/arXiv arXiv 1903
-
[14]
doi: 10.1162/neco.1991.3.1.79. Jiang, A. Q., Sablayrolles, A., Roux, A., Mensch, A., Savary, B., Bamford, C., Chaplot, D. S., de las Casas, D., Hanna, E. B., Bressand, F., Lengyel, G., Bour, G., Lample, G., Lavaud, L. R., Saulnier, L., Lachaux, M.-A., Stock, P., Subramanian, S., Yang, S., Antoniak, S., Scao, T. L., Gervet, T., Lavril, T., Wang, T., Lacroi...
-
[15]
URLhttps://arxiv. org/abs/2401.04088. Jordan, M. and Jacobs, R. Hierarchical mixtures of ex- perts and the em algorithm. InProceedings of 1993 International Conference on Neural Networks (IJCNN- 93-Nagoya, Japan), volume 2, pp. 1339–1344 vol.2,
Pith/arXiv arXiv 1993
-
[16]
Lai, G., Xie, Q., Liu, H., Yang, Y ., and Hovy, E
doi: 10.1109/IJCNN.1993.716791. Lai, G., Xie, Q., Liu, H., Yang, Y ., and Hovy, E. Race: Large-scale reading comprehension dataset from exam- inations,
-
[17]
URL https://arxiv.org/abs/ 1704.04683. Lepikhin, D., Lee, H., Xu, Y ., Chen, D., Firat, O., Huang, Y ., Krikun, M., Shazeer, N., and Chen, Z. Gshard: Scaling giant models with conditional computation and automatic sharding,
-
[18]
Li, B., Shen, Y ., Yang, J., Wang, Y ., Ren, J., Che, T., Zhang, J., and Liu, Z
URL https://arxiv.org/abs/ 2006.16668. Li, B., Shen, Y ., Yang, J., Wang, Y ., Ren, J., Che, T., Zhang, J., and Liu, Z. Sparse mixture-of-experts are domain generalizable learners,
Pith/arXiv arXiv 2006
-
[19]
URL https://arxiv. org/abs/2206.04046. Oja, E. and Karhunen, J. On stochastic approximation of the eigenvectors and eigenvalues of the expectation of a random matrix.Journal of mathematical analysis and applications, 106(1):69–84,
-
[20]
URL https: //arxiv.org/abs/1606.06031. Qiu, Z., Huang, Z., and Fu, J. Unlocking emergent mod- ularity in large language models,
-
[21]
Qiu, Z., Huang, Z., Zheng, B., Wen, K., Wang, Z., Men, R., Titov, I., Liu, D., Zhou, J., and Lin, J
URL https: //arxiv.org/abs/2310.10908. Qiu, Z., Huang, Z., Zheng, B., Wen, K., Wang, Z., Men, R., Titov, I., Liu, D., Zhou, J., and Lin, J. Demons in the detail: On implementing load balancing loss for train- ing specialized mixture-of-expert models,
-
[22]
URL https://arxiv.org/abs/2501.11873. 11 STAR: Rethinking MoE Routing as Structure-Aware Subspace Learning Qwen, :, Yang, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Li, C., Liu, D., Huang, F., Wei, H., Lin, H., Yang, J., Tu, J., Zhang, J., Yang, J., Yang, J., Zhou, J., Lin, J., Dang, K., Lu, K., Bao, K., Yang, K., Yu, L., Li, M., Xue, M., Zhang,...
-
[23]
URL https: //arxiv.org/abs/2412.15115. Sanger, T. D. Optimal unsupervised learning in a single- layer linear feedforward neural network.Neural Net- works, 2(459-473):8,
-
[24]
Touvron, H., Cord, M., Douze, M., Massa, F., Sablayrolles, A., and J ´egou, H
URLhttps://arxiv.org/abs/1701.06538. Touvron, H., Cord, M., Douze, M., Massa, F., Sablayrolles, A., and J ´egou, H. Training data-efficient image trans- formers & distillation through attention,
-
[25]
Wang, A., Singh, A., Michael, J., Hill, F., Levy, O., and Bowman, S
URL https://arxiv.org/abs/2012.12877. Wang, A., Singh, A., Michael, J., Hill, F., Levy, O., and Bowman, S. R. Glue: A multi-task benchmark and anal- ysis platform for natural language understanding,
arXiv 2012
-
[26]
GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding
URLhttps://arxiv.org/abs/1804.07461. Wang, L., Gao, H., Zhao, C., Sun, X., and Dai, D. Auxiliary- loss-free load balancing strategy for mixture-of-experts. ArXiv, abs/2408.15664, 2024a. doi: 10.48550/arxiv.2408. 15664. Wang, L., Gao, H., Zhao, C., Sun, X., and Dai, D. Auxiliary-loss-free load balancing strategy for mixture-of- experts, 2024b. URL https://...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2408
-
[27]
Warstadt, A., Singh, A., and Bowman, S
URL https: //arxiv.org/abs/2412.14711. Warstadt, A., Singh, A., and Bowman, S. R. Neural network acceptability judgments,
-
[28]
URL https://arxiv. org/abs/1805.12471. Xie, S. M., Raghunathan, A., Liang, P., and Ma, T. An explanation of in-context learning as implicit bayesian inference,
-
[29]
URL https://arxiv.org/abs/ 2111.02080. Xu, L., Hu, H., Zhang, X., Li, L., Cao, C., Li, Y ., Xu, Y ., Sun, K., Yu, D., Yu, C., Tian, Y ., Dong, Q., Liu, W., Shi, B., Cui, Y ., Li, J., Zeng, J., Wang, R., Xie, W., Li, Y ., Pat- terson, Y ., Tian, Z., Zhang, Y ., Zhou, H., Liu, S., Zhao, Z., Zhao, Q., Yue, C., Zhang, X., Yang, Z., Richardson, K., and Lan, Z....
-
[30]
In: Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)
International Committee on Computational Linguistics. doi: 10.18653/v1/2020. coling-main.419. URL https://aclanthology. org/2020.coling-main.419/. Yang, L., Zhang, S., Qin, L., Li, Y ., Wang, Y ., Liu, H., Wang, J., Xie, X., and Zhang, Y . Glue-x: Evaluat- ing natural language understanding models from an out- of-distribution generalization perspective,
-
[31]
Zellers, R., Holtzman, A., Bisk, Y ., Farhadi, A., and Choi, Y
URL https://arxiv.org/abs/2211.08073. Zellers, R., Holtzman, A., Bisk, Y ., Farhadi, A., and Choi, Y . Hellaswag: Can a machine really finish your sentence?,
-
[32]
Zhang, Z., Lin, Y ., Liu, Z., Li, P., Sun, M., and Zhou, J
URL https://arxiv.org/abs/ 1905.07830. Zhang, Z., Lin, Y ., Liu, Z., Li, P., Sun, M., and Zhou, J. Moefication: Transformer feed-forward layers are mix- tures of experts,
Pith/arXiv arXiv 1905
-
[33]
Zhou, Y .-Q., Lei, T., Liu, H.-C., Du, N., Huang, Y ., Zhao, V ., Dai, A
URL https://arxiv.org/ abs/2110.01786. Zhou, Y .-Q., Lei, T., Liu, H.-C., Du, N., Huang, Y ., Zhao, V ., Dai, A. M., Chen, Z., Le, Q. V ., and Laudon, J. Mixture-of-experts with expert choice routing.ArXiv, abs/2202.09368,
-
[34]
12 STAR: Rethinking MoE Routing as Structure-Aware Subspace Learning A
URL https: //arxiv.org/abs/2406.16554. 12 STAR: Rethinking MoE Routing as Structure-Aware Subspace Learning A. Computation Analysis In this section, we analyze the computational complexity of STAR in comparison to standard MoE gating mechanisms. We break down the cost of each stage, GHA basis updates, subspace mixing, and routing. The goal is to clarify t...
arXiv 2022
-
[35]
Performance with Smaller GHA Updates Table 5 reports results with smaller numbers of GHA iterations m∈ {1,2,3}
65.03±0.76 89.62±0.96 92.48±0.08 86.55±0.24 75.10±0.29 81.76 3 (8,1) 65.54±0.47 90.25±0.55 92.56±0.23 86.52±0.18 74.61±0.74 81.90 (8,2) 65.81±0.80 90.03±0.32 92.52±0.15 86.63±0.08 75.57±0.61 82.11 (8,4) 66.62±0.65 89.68±0.20 92.61±0.10 86.74±0.11 75.57±0.68 82.24 D.1. Performance with Smaller GHA Updates Table 5 reports results with smaller numbers of GHA...
2017
-
[36]
We evaluate on five representative GLUE subtasks: CoLA (Warstadt et al.,
on the GLUE benchmark (Wang et al., 2019). We evaluate on five representative GLUE subtasks: CoLA (Warstadt et al.,
2019
-
[37]
These datasets jointly cover grammaticality, semantic similarity, and entailment, providing a comprehensive testbed for expert specialization in language understanding
(textual entailment). These datasets jointly cover grammaticality, semantic similarity, and entailment, providing a comprehensive testbed for expert specialization in language understanding. GLUE-X OOD Benchmark.To evaluate robustness under distribution shift, we additionally consider GLUE-X (Yang et al., 2023), an extension of GLUE that augments each in-...
2023
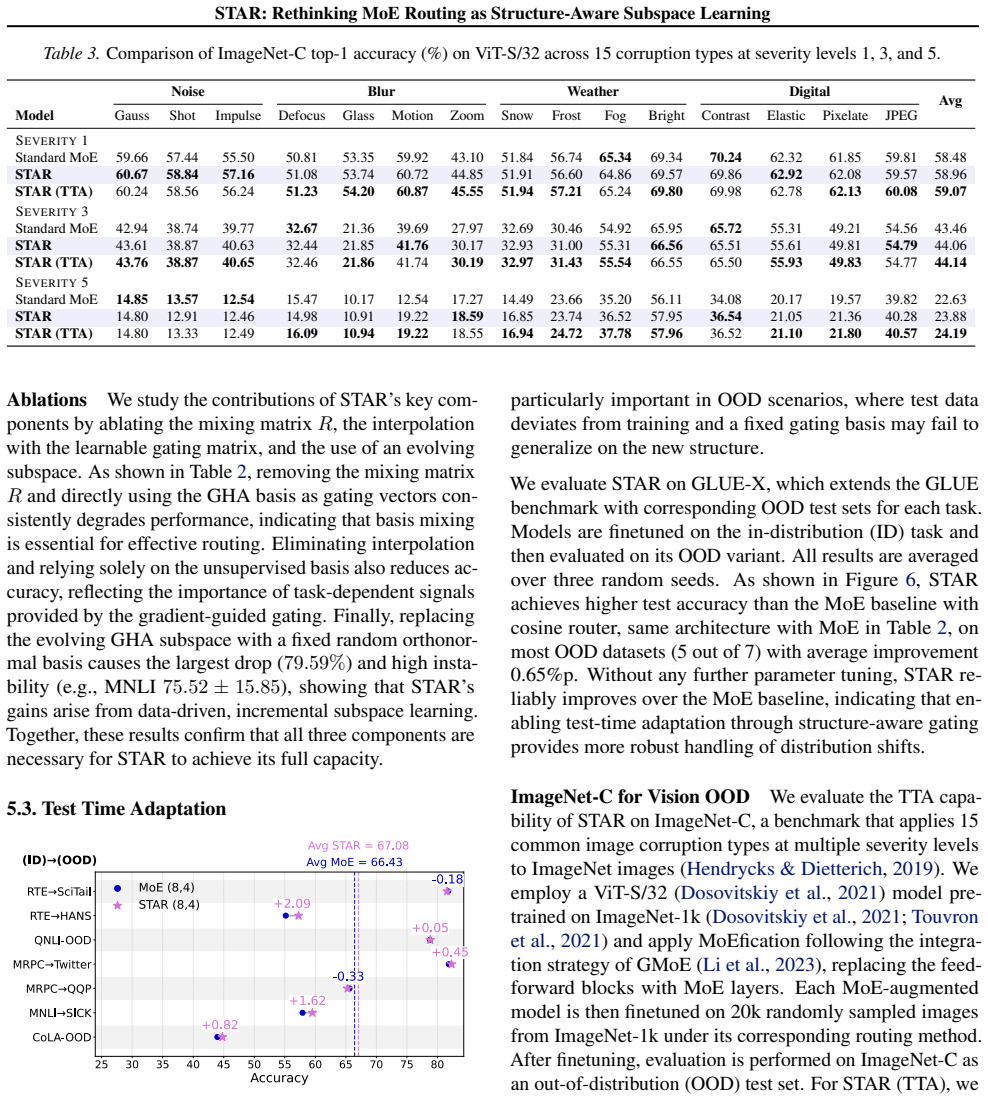
-
[38]
ImageNet-1k and ImageNet-C.ImageNet-1k is a large-scale visual classification benchmark containing 1,000 object categories and 1.28M training images, serving as the pretraining source for our ViT-S/32 backbone. For robustness evaluation, we adopt ImageNet-C, which applies 15 corruption types spanning noise, blur, weather, and digital distortions, each at ...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.