Towards Multi-Agent-Simulation-Based Community Note Evaluation
Pith reviewed 2026-06-28 04:10 UTC · model grok-4.3
The pith
A multi-agent framework clusters real raters and prompts persona agents to predict community note ratings at 84.7 percent accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
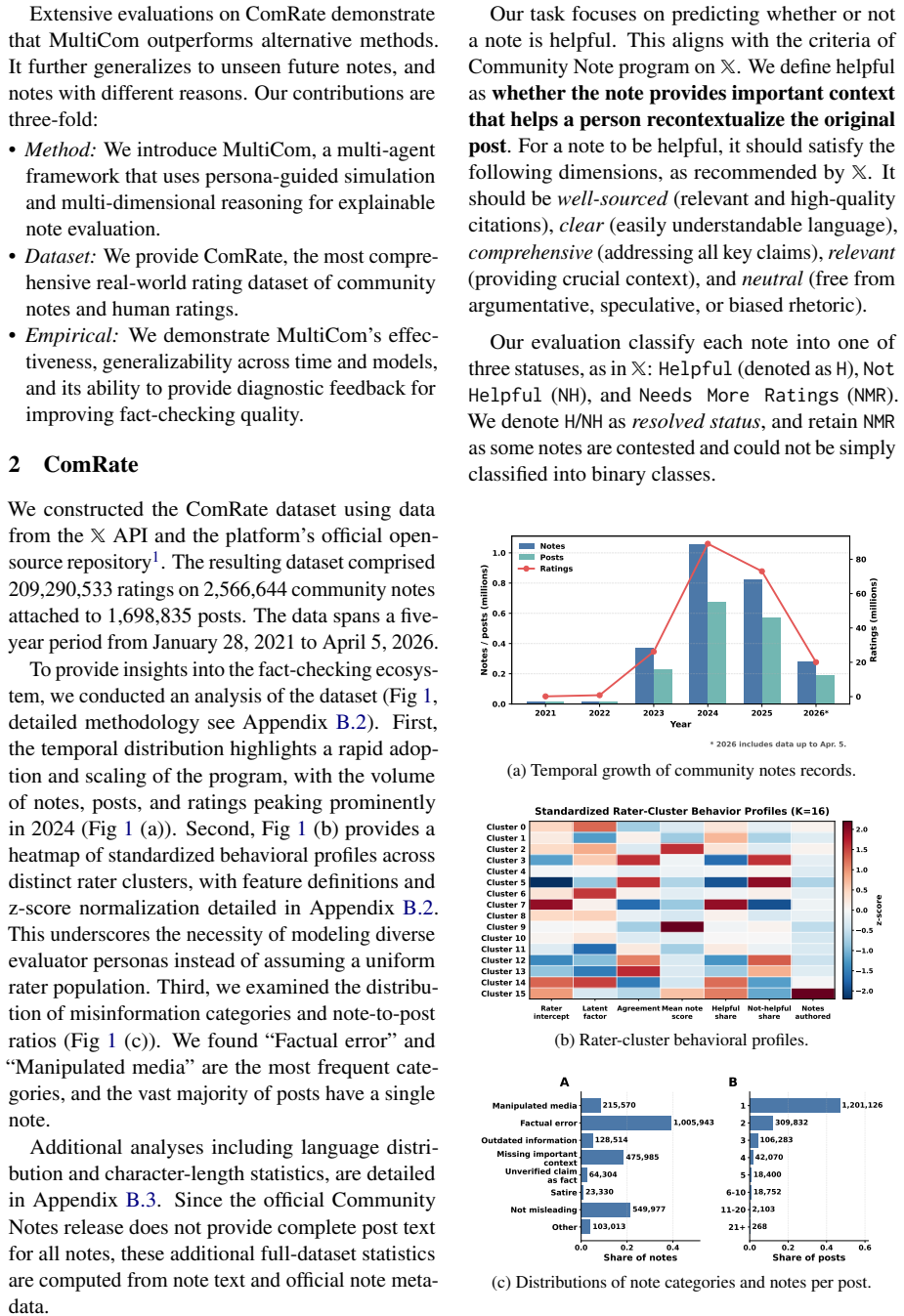
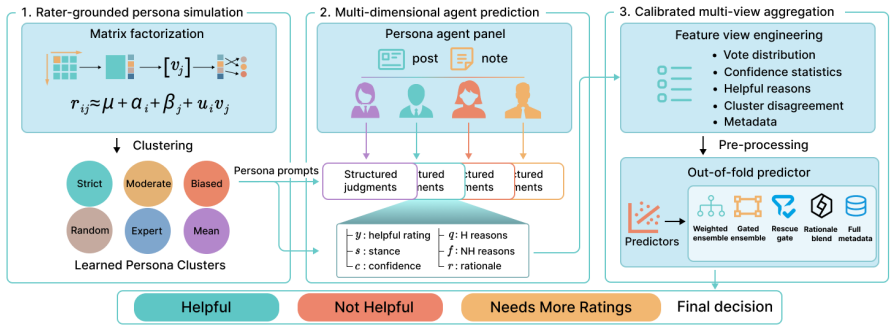
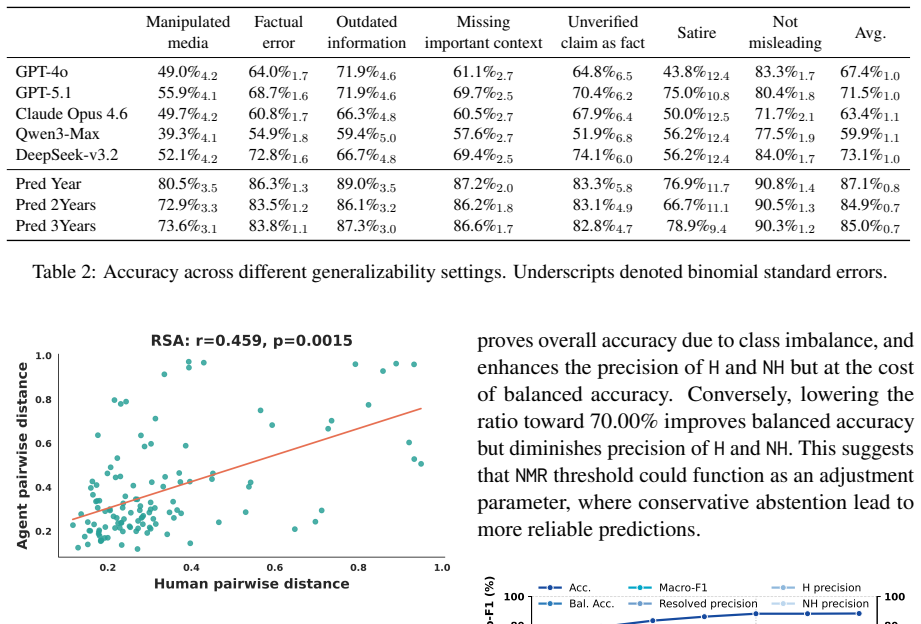
MultiCom simulates a diverse rater population by clustering contributors in a matrix-factorized rater space and prompting persona agents to generate structured assessments based on the official community notes rating schema. These agents output judgments such as confidence, agreement signals and reasons. An out-of-fold calibrated aggregation algorithm combines raw votes and diagnostic reason signals for reliable prediction, achieving 84.7 percent average accuracy, 68.3 percent balanced accuracy and 60.1 percent macro-F1 on the evaluation set.
What carries the argument
The MultiCom persona-guided multi-agent rating framework that clusters contributors in a matrix-factorized rater space and prompts agents to output structured assessments.
If this is right
- The simulation yields explainable judgments that include diagnostic signals beyond raw votes.
- Out-of-fold calibrated aggregation produces more reliable forecasts than direct alternatives.
- The method addresses delays and low coverage in cross-consensus fact-checking by supplying immediate structured evaluations.
- Performance is demonstrated on a dataset of 2.5 million notes and over 209 million ratings.
Where Pith is reading between the lines
- The same persona clusters could be reused across successive waves of new notes without repeated factorization.
- Retraining the rater-space clustering on data from other platforms could adapt the approach beyond X.
- Showing agent-generated reasons alongside predictions might let human reviewers focus effort more efficiently.
Load-bearing premise
That clustering real contributors in a matrix-factorized rater space and prompting persona agents will produce judgments that reliably predict how actual diverse human raters would rate new notes.
What would settle it
Collecting fresh human ratings on a held-out set of new notes and measuring whether MultiCom predictions reach the reported accuracy levels against those ratings.
Figures


read the original abstract
Community-based fact-checking that relies on cross-consensus is expanding rapidly on social media platforms. However, the delay and low-ratio of cross-consensus community fact-checks rated by human contributors remains a significant challenge. To address this, we first created ComRate, a large-scale dataset comprising 2.5 million community notes and over 209 million ratings sourced from $\mathbb{X}$. We then propose MultiCom, a persona-guided multi-agent rating framework for community note evaluation. MultiCom simulates diverse rater population by clustering contributors in a matrix-factorized rater space and prompting persona agents to generate structured assessments based on the official community notes rating schema. These agents output structured and explainable judgments, such as confidence, agreement signals and reasons. An out-of-fold calibrated aggregation algorithm combines features such as raw votes and diagnostic reason signals for reliable prediction. Extensive evaluations demonstrate that MultiCom outperforms alternative methods, achieving an average accuracy of 84.7% (balanced accuracy 68.3%, macro-F1 60.1%) on the evaluation set.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ComRate, a dataset of 2.5 million community notes and 209 million ratings from X, and proposes MultiCom, a multi-agent framework that clusters raters via matrix factorization of the rating matrix, prompts LLM persona agents to produce structured ratings (confidence, agreement, reasons) according to the official Community Notes schema, and applies an out-of-fold calibrated aggregator combining raw votes and diagnostic signals. It reports that MultiCom achieves 84.7% accuracy (68.3% balanced accuracy, 60.1% macro-F1) and outperforms alternative methods on an evaluation set.
Significance. If the simulation reliably predicts real human ratings on unseen notes, the work could help mitigate delays in cross-consensus Community Notes by providing scalable, explainable proxies for diverse rater populations. The scale of ComRate is a clear asset for the field. The matrix-factorization-plus-LLM-persona design is a novel direction, but its significance depends on whether the reported metrics reflect genuine out-of-distribution predictive power rather than in-sample fitting or simulation artifacts.
major comments (3)
- [Abstract] Abstract: performance numbers (84.7% accuracy, 68.3% balanced accuracy, 60.1% macro-F1) are stated without any description of the baseline methods, the train/evaluation split protocol, or how out-of-fold calibration was implemented. This absence prevents assessment of whether the central claim of outperformance is supported.
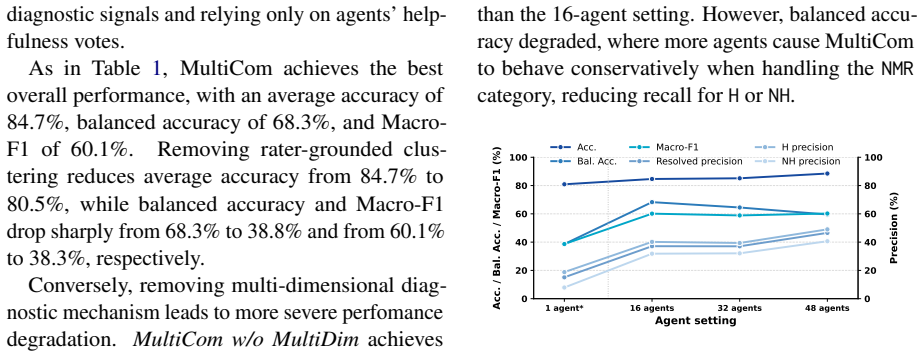
- [Method] Method (clustering and persona prompting): the load-bearing assumption that matrix-factorized clusters plus LLM persona prompts reproduce the decision boundaries of actual diverse human raters on new notes is not accompanied by any diagnostic experiments (e.g., stability of clusters across time periods, comparison of persona outputs to held-out human ratings on the same notes, or checks for transient platform effects captured by the factorization).
- [Aggregation] Aggregation section: the out-of-fold calibrated aggregator uses features that include raw votes; without an explicit statement of whether the global clustering step occurs before or after the data split, indirect leakage cannot be ruled out, undermining the claim that the metrics demonstrate deployment-time utility.
minor comments (2)
- [Method] Provide the exact Community Notes rating schema fields used to structure the agent outputs and any prompt templates employed.
- [Dataset] Clarify how the 2.5 million notes were sampled or filtered from the full rating stream.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important aspects of clarity in the abstract, the need for additional diagnostics on the clustering and persona approach, and potential data leakage concerns in the aggregation procedure. We address each major comment below and indicate where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: performance numbers (84.7% accuracy, 68.3% balanced accuracy, 60.1% macro-F1) are stated without any description of the baseline methods, the train/evaluation split protocol, or how out-of-fold calibration was implemented. This absence prevents assessment of whether the central claim of outperformance is supported.
Authors: We agree that the abstract would benefit from additional context to allow readers to evaluate the reported metrics. In the revised manuscript, we will expand the abstract to briefly describe the baseline methods compared, the train/evaluation split protocol used, and the implementation of out-of-fold calibration. This change will directly address the concern without altering the core claims. revision: yes
-
Referee: [Method] Method (clustering and persona prompting): the load-bearing assumption that matrix-factorized clusters plus LLM persona prompts reproduce the decision boundaries of actual diverse human raters on new notes is not accompanied by any diagnostic experiments (e.g., stability of clusters across time periods, comparison of persona outputs to held-out human ratings on the same notes, or checks for transient platform effects captured by the factorization).
Authors: The referee correctly identifies that the manuscript would be strengthened by explicit diagnostic experiments validating the clustering and persona prompting assumptions. While the current evaluation relies on out-of-fold performance as an indirect check, we acknowledge the value of direct diagnostics. In the revision, we will add a dedicated subsection presenting cluster stability analysis across time periods and, where feasible, comparisons of persona outputs against held-out human ratings on the same notes. Checks for transient platform effects will also be discussed based on available data. revision: partial
-
Referee: [Aggregation] Aggregation section: the out-of-fold calibrated aggregator uses features that include raw votes; without an explicit statement of whether the global clustering step occurs before or after the data split, indirect leakage cannot be ruled out, undermining the claim that the metrics demonstrate deployment-time utility.
Authors: We appreciate this point on potential leakage. The global clustering is performed exclusively on the training portion of the data prior to any evaluation split, and the out-of-fold calibration is designed to avoid using test-set information. However, we agree that an explicit statement is needed to rule out ambiguity. In the revised Aggregation section, we will add a clear description of the ordering (clustering before split) and confirm that no test data influences the clustering or calibration steps. revision: yes
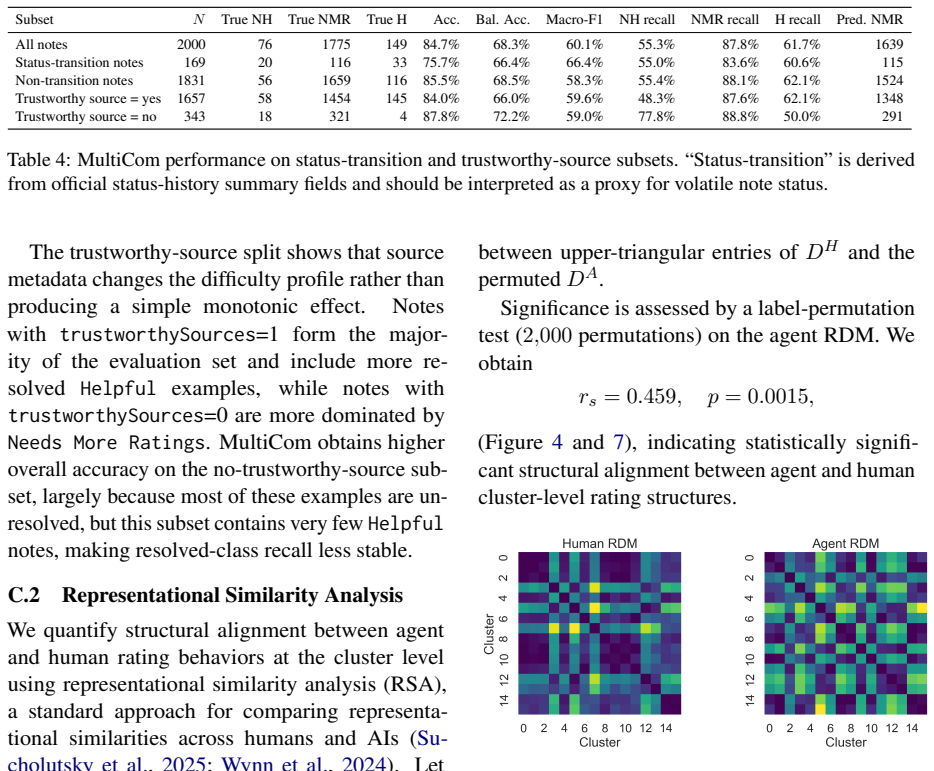
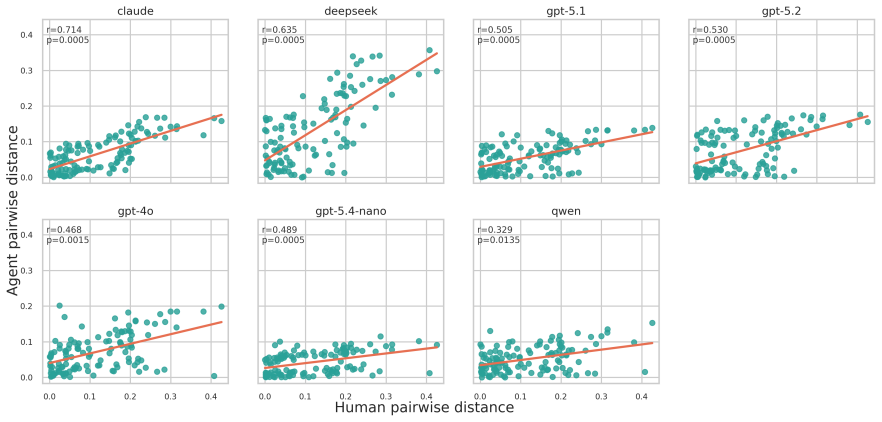
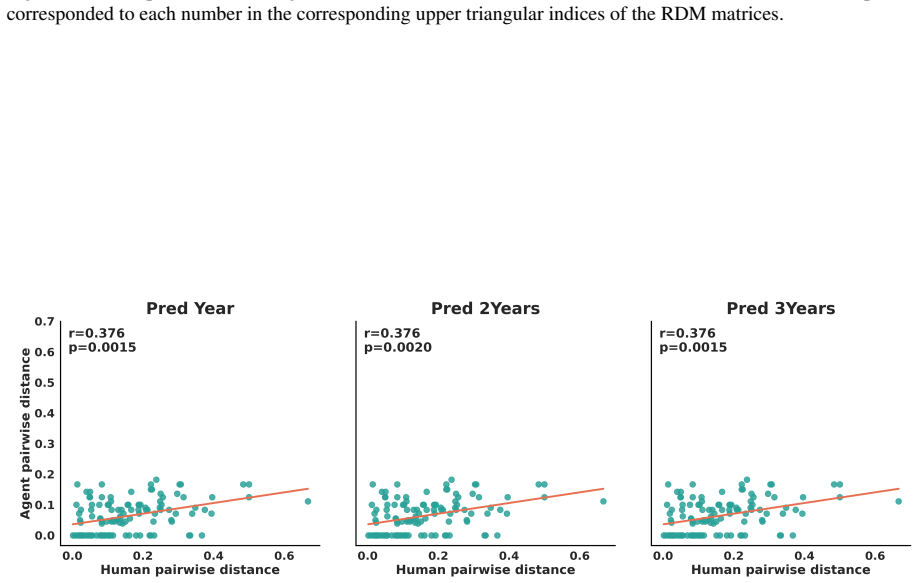
Circularity Check
No significant circularity detected
full rationale
The paper describes dataset construction from external X ratings, matrix factorization for rater clustering, LLM persona prompting under an official schema, and out-of-fold calibrated aggregation of votes plus diagnostic signals. Reported metrics are on a held-out evaluation set. No equations, self-citations, or method descriptions in the abstract or reader summary exhibit a reduction of the claimed accuracy to fitted inputs by construction, self-definitional loops, or load-bearing author citations. The evaluation methodology is presented as independent of the target predictions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
Factcheck-bench: Fine-grained evaluation benchmark for automatic fact-checkers , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[2]
Proceedings of the 30th ACM international conference on information & knowledge management , pages=
Sciclops: Detecting and contextualizing scientific claims for assisting manual fact-checking , author=. Proceedings of the 30th ACM international conference on information & knowledge management , pages=
-
[3]
Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems , pages=
Show Me the Work: Fact-Checkers' Requirements for Explainable Automated Fact-Checking , author=. Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems , pages=
2025
-
[4]
Proceedings of the ACM on Human-Computer Interaction , volume=
Human and technological infrastructures of fact-checking , author=. Proceedings of the ACM on Human-Computer Interaction , volume=. 2022 , publisher=
2022
-
[5]
IJCAI , pages=
Automated Fact-Checking for Assisting Human Fact-Checkers , author=. IJCAI , pages=. 2021 , organization=
2021
-
[6]
Findings of the Association for Computational Linguistics: EACL 2026 , pages=
COMMUNITYNOTES: A Dataset for Exploring the Helpfulness of Fact-Checking Explanations , author=. Findings of the Association for Computational Linguistics: EACL 2026 , pages=
2026
-
[7]
Proceedings of the National Academy of Sciences , volume=
Science audiences, misinformation, and fake news , author=. Proceedings of the National Academy of Sciences , volume=. 2019 , publisher=
2019
-
[8]
Proceedings of the International AAAI Conference on Web and Social Media , volume=
Community-based fact-checking on Twitter’s Birdwatch platform , author=. Proceedings of the International AAAI Conference on Web and Social Media , volume=
-
[9]
Proceedings of the ACM on human-computer interaction , volume=
Did the roll-out of community notes reduce engagement with misinformation on X/Twitter? , author=. Proceedings of the ACM on human-computer interaction , volume=. 2024 , publisher=
2024
-
[10]
Nature Communications , volume=
Community-based fact-checking reduces the spread of misleading posts on X (formerly Twitter) , author=. Nature Communications , volume=. 2026 , publisher=
2026
-
[11]
Proceedings of the ACM Web Conference 2026 , pages=
Consensus stability of community notes on X , author=. Proceedings of the ACM Web Conference 2026 , pages=
2026
-
[12]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages=
Can community notes replace professional fact-checkers? , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages=
-
[13]
Proceedings of the ACM on Web Conference 2025 , pages=
Supernotes: Driving consensus in crowd-sourced fact-checking , author=. Proceedings of the ACM on Web Conference 2025 , pages=
2025
-
[14]
arXiv preprint arXiv:2509.11052 , year=
Commenotes: Synthesizing organic comments to support community-based fact-checking , author=. arXiv preprint arXiv:2509.11052 , year=
-
[15]
arXiv preprint arXiv:2510.11423 , year=
Beyond the Crowd: LLM-Augmented Community Notes for Governing Health Misinformation , author=. arXiv preprint arXiv:2510.11423 , year=
-
[16]
Journal of Online Trust and Safety , volume=
Scaling Human Judgment in Community Notes with LLMs , author=. Journal of Online Trust and Safety , volume=
-
[17]
Proceedings of the ACM on Human-Computer Interaction , volume=
True or false: Studying the work practices of professional fact-checkers , author=. Proceedings of the ACM on Human-Computer Interaction , volume=. 2022 , publisher=
2022
-
[18]
Transactions of the association for computational linguistics , volume=
A survey on automated fact-checking , author=. Transactions of the association for computational linguistics , volume=
-
[19]
Frontiers in Oncology , volume=
Development of a machine learning model for optimal applicator selection in high-dose-rate cervical brachytherapy , author=. Frontiers in Oncology , volume=. 2021 , publisher=
2021
-
[20]
Frontiers in Pharmacology , volume=
Ensemble learning approach with explainable AI for improved heart disease prediction , author=. Frontiers in Pharmacology , volume=. 2025 , publisher=
2025
-
[21]
Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
G-eval: NLG evaluation using gpt-4 with better human alignment , author=. Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
2023
-
[22]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Llm-rubric: A multidimensional, calibrated approach to automated evaluation of natural language texts , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[23]
arXiv preprint arXiv:2307.10928 , year=
Flask: Fine-grained language model evaluation based on alignment skill sets , author=. arXiv preprint arXiv:2307.10928 , year=
-
[24]
Neural networks , volume=
Stacked generalization , author=. Neural networks , volume=. 1992 , publisher=
1992
-
[25]
ACM Transactions on Knowledge Discovery from Data (TKDD) , volume=
Leakage in data mining: Formulation, detection, and avoidance , author=. ACM Transactions on Knowledge Discovery from Data (TKDD) , volume=. 2012 , publisher=
2012
-
[26]
International workshop on multiple classifier systems , pages=
Ensemble methods in machine learning , author=. International workshop on multiple classifier systems , pages=. 2000 , organization=
2000
-
[27]
Proceedings of the twenty-first international conference on Machine learning , pages=
Ensemble selection from libraries of models , author=. Proceedings of the twenty-first international conference on Machine learning , pages=
-
[28]
Neural computation , volume=
Adaptive mixtures of local experts , author=. Neural computation , volume=. 1991 , publisher=
1991
-
[29]
, author=
Parameter-efficient fine-tuning of small language models for code generation: a comparative study of Gemma, Qwen 2.5 and Llama 3.2. , author=. International Journal of Electrical & Computer Engineering (2088-8708) , volume=
2088
-
[30]
International Conference on Learning Representations , year=
LoRA: Low-Rank Adaptation of Large Language Models , author=. International Conference on Learning Representations , year=
-
[31]
The 14th International Joint Conference on Natural Language Processing and The 4th Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics , pages=
VariantBench: A Framework for Evaluating LLMs on Justifications for Genetic Variant Interpretation , author=. The 14th International Joint Conference on Natural Language Processing and The 4th Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics , pages=
-
[32]
Transactions on Machine Learning Research , volume=
Getting aligned on representational alignment , author=. Transactions on Machine Learning Research , volume=. 2025 , publisher=
2025
-
[33]
Advances in Neural Information Processing Systems , volume=
Learning human-like representations to enable learning human values , author=. Advances in Neural Information Processing Systems , volume=
-
[34]
Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
Chatdev: Communicative agents for software development , author=. Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
-
[35]
First conference on language modeling , year=
Autogen: Enabling next-gen LLM applications via multi-agent conversations , author=. First conference on language modeling , year=
-
[36]
Proceedings of the 36th annual acm symposium on user interface software and technology , pages=
Generative agents: Interactive simulacra of human behavior , author=. Proceedings of the 36th annual acm symposium on user interface software and technology , pages=
-
[37]
Proceedings of the 2026 CHI Conference on Human Factors in Computing Systems , pages=
Collab: Fostering Critical Identification of Deepfake Videos on Social Media via Synergistic Annotation , author=. Proceedings of the 2026 CHI Conference on Human Factors in Computing Systems , pages=
2026
-
[38]
Proceedings of the 2026 CHI Conference on Human Factors in Computing Systems , pages=
Request a note: How the request function shapes X's Community Notes system , author=. Proceedings of the 2026 CHI Conference on Human Factors in Computing Systems , pages=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.