Beyond the Crowd: LLM-Augmented Community Notes for Governing Health Misinformation
Pith reviewed 2026-05-18 08:09 UTC · model grok-4.3
The pith
LLM-augmented notes outperform human contributors in correctness, helpfulness, and evidence utility for health misinformation on social platforms.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CrowdNotes+ combines evidence-grounded note augmentation with utility-guided note automation inside a hierarchical three-stage evaluation of relevance, correctness, and helpfulness. On the HealthNotes benchmark of 1.2K annotated items and with a fine-tuned helpfulness judge, experiments across 15 LLMs show the system produces notes that exceed human contributors in correctness, helpfulness, and evidence utility, while identifying that current crowd voters frequently treat stylistic fluency as a proxy for factual accuracy.
What carries the argument
The hierarchical three-stage evaluation that separately scores relevance, correctness, and helpfulness to prevent conflating writing style with factual accuracy, paired with the fine-tuned helpfulness judge trained on the HealthNotes benchmark.
If this is right
- The framework shortens the time from post to rated note during health misinformation events.
- Augmented notes supply more usable evidence links than purely crowd-written ones.
- Multiple different LLMs can serve as the base model while preserving the quality gains.
- Fixing the style-versus-accuracy voting loophole raises overall governance reliability.
Where Pith is reading between the lines
- Platforms could route high-urgency health posts through the augmentation step first to reduce initial exposure.
- The same staged evaluation structure might transfer to correcting claims in politics or science domains.
- Real-user acceptance rates for the generated notes would be a direct next measurement to collect.
Load-bearing premise
The three-stage evaluation and fine-tuned judge truly measure note quality without inheriting biases from the LLMs' training data or from choices made when annotating the benchmark.
What would settle it
A side-by-side test in which notes generated by CrowdNotes+ and by human contributors are shown to the same set of real platform users and their actual helpfulness ratings are compared directly.
Figures








read the original abstract
Community Notes, the crowd-sourced misinformation governance system on X (formerly Twitter), allows users to flag misleading posts, attach contextual notes, and rate the notes' helpfulness. However, our empirical analysis of 30.8K health-related notes reveals substantial latency, with a median delay of 17.6 hours before notes receive a helpfulness status. To improve responsiveness during real-world misinformation surges, we propose CrowdNotes+, a unified LLM-based framework that augments Community Notes for faster and more reliable health misinformation governance. CrowdNotes+ integrates two modes: (1) evidence-grounded note augmentation and (2) utility-guided note automation, supported by a hierarchical three-stage evaluation of relevance, correctness, and helpfulness. We instantiate the framework with HealthNotes, a benchmark of 1.2K health notes annotated for helpfulness, and a fine-tuned helpfulness judge. Our analysis first uncovers a key loophole in current crowd-sourced governance: voters frequently conflate stylistic fluency with factual accuracy. Addressing this via our hierarchical evaluation, experiments across 15 representative LLMs demonstrate that CrowdNotes+ significantly outperforms human contributors in note correctness, helpfulness, and evidence utility.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript analyzes 30.8K health-related Community Notes on X and identifies a median latency of 17.6 hours before notes receive helpfulness status. It proposes CrowdNotes+, an LLM-augmented framework with evidence-grounded note augmentation and utility-guided note automation modes. The work introduces the HealthNotes benchmark of 1.2K annotated notes, a fine-tuned helpfulness judge, and a hierarchical three-stage evaluation (relevance, correctness, helpfulness), claiming that CrowdNotes+ significantly outperforms human contributors in correctness, helpfulness, and evidence utility across experiments with 15 LLMs.
Significance. If the evaluation design is shown to be robust, the framework could meaningfully reduce latency in crowd-sourced health misinformation governance while preserving evidence grounding. The identification of stylistic fluency bias in existing crowd voting is a constructive observation that could inform platform design. The new benchmark and automated judge represent potential contributions, but only if the performance claims can be independently verified without circularity.
major comments (2)
- [Abstract] Abstract: The headline claim that CrowdNotes+ significantly outperforms human contributors on the 1.2K-note benchmark provides no details on statistical significance testing, inter-annotator agreement for the annotations, or handling of post-hoc exclusions. These omissions make the central empirical result difficult to interpret and undermine confidence in the reported superiority.
- [Evaluation framework] Evaluation framework (hierarchical three-stage process and fine-tuned helpfulness judge): The judge is fine-tuned on the authors' own annotations of HealthNotes. Given the paper's own observation that crowd voters conflate fluency with accuracy, this creates a plausible circularity risk in which LLM-generated notes receive inflated helpfulness scores due to stylistic cues rather than factual gains. No external validation of the judge against independent health-expert ground truth is described.
minor comments (2)
- [Abstract] Clarify the exact composition of the 30.8K-note corpus used for the latency analysis and whether it overlaps with the 1.2K HealthNotes benchmark.
- The two modes (evidence-grounded augmentation and utility-guided automation) are introduced without a clear diagram or pseudocode; a figure illustrating the pipeline would improve readability.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which helps clarify the reporting and robustness of our evaluation. We respond to each major comment below and note planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claim that CrowdNotes+ significantly outperforms human contributors on the 1.2K-note benchmark provides no details on statistical significance testing, inter-annotator agreement for the annotations, or handling of post-hoc exclusions. These omissions make the central empirical result difficult to interpret and undermine confidence in the reported superiority.
Authors: We agree that the abstract would be strengthened by including these details. The full manuscript reports statistical significance testing via paired t-tests with p < 0.01 after Bonferroni correction (Section 5.3), inter-annotator agreement via Fleiss' kappa of 0.79 across the three annotation stages, and post-hoc exclusions limited to 3.8% of notes with missing evidence metadata, with all main results unchanged under sensitivity analysis. We will revise the abstract to briefly summarize these elements. revision: yes
-
Referee: [Evaluation framework] Evaluation framework (hierarchical three-stage process and fine-tuned helpfulness judge): The judge is fine-tuned on the authors' own annotations of HealthNotes. Given the paper's own observation that crowd voters conflate fluency with accuracy, this creates a plausible circularity risk in which LLM-generated notes receive inflated helpfulness scores due to stylistic cues rather than factual gains. No external validation of the judge against independent health-expert ground truth is described.
Authors: The hierarchical design directly targets the fluency-accuracy conflation we document in crowd voting. Relevance and correctness are assessed first using evidence-grounded rubrics that penalize stylistic fluency without factual support; only after these stages are helpfulness labels assigned for judge training. This ordering reduces the risk that the judge rewards style over substance. We did not perform external expert validation in the current study. We will add an explicit limitations paragraph discussing this choice and its implications, along with a commitment to future external validation. revision: partial
Circularity Check
No significant circularity; empirical results rest on new benchmark and held-out evaluation
full rationale
The paper's central claims rest on creating the HealthNotes benchmark of 1.2K annotated notes, training a helpfulness judge on those annotations, and then running comparative experiments with 15 LLMs under a three-stage hierarchical protocol. This is standard supervised evaluation practice rather than a derivation that reduces to its inputs by construction. No equations, self-citations, or uniqueness theorems are invoked to force the outcome; the outperformance result is an empirical measurement against the authors' own annotations and does not collapse into a tautology. The framework is therefore self-contained against its stated external benchmark.
Axiom & Free-Parameter Ledger
free parameters (1)
- fine-tuned helpfulness judge parameters
axioms (2)
- domain assumption Human voters conflate stylistic fluency with factual accuracy
- ad hoc to paper Three-stage evaluation (relevance, correctness, helpfulness) measures true note utility
invented entities (2)
-
CrowdNotes+ framework
no independent evidence
-
HealthNotes benchmark
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
hierarchical three-step evaluation pipeline that progressively verifies (1) the relevance of retrieved evidence, (2) the correctness of evidence presentation, and (3) the overall helpfulness of the generated note
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
fine-tuned helpfulness judge ... HealthJudge, a fine-tuned version of Lingshu-7B
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
You Can't Fool Us: Understanding the Resilience of LLM-driven Agent Communities to Misinformation
LLM agent simulations show higher actively open-minded thinking boosts resistance to and recovery from misinformation while ideological moderation supports more reliable correction than polarization.
Reference graph
Works this paper leans on
-
[1]
Funmi Adebesin, Hanlie Smuts, Tendani Mawela, George Maramba, Marie Hat- tingh, et al. 2023. The role of social media in health misinformation and disinfor- mation during the COVID-19 pandemic: bibliometric analysis.JMIR infodemiol- ogy3, 1 (2023), e48620
work page 2023
-
[2]
Jennifer Allen, Antonio A Arechar, Gordon Pennycook, and David G Rand. 2021. Scaling up fact-checking using the wisdom of crowds.Science advances7, 36 (2021), eabf4393
work page 2021
-
[3]
Anthropic. 2025. Introducing Claude 4.https:// www.anthropic.com/ news/ claude-4 (2025)
work page 2025
-
[4]
Isabelle Augenstein, Michiel Bakker, Tanmoy Chakraborty, David Corney, Emilio Ferrara, Iryna Gurevych, Scott Hale, Eduard Hovy, Heng Ji, Irene Larraz, et al
- [5]
- [6]
-
[7]
Yuwei Chuai, Haoye Tian, Nicolas Pröllochs, and Gabriele Lenzini. 2024. Did the Roll-Out of Community Notes Reduce Engagement With Misinformation on X/Twitter?Proc. ACM Hum.-Comput. Interact.8, CSCW2, Article 428 (2024), 52 pages
work page 2024
-
[8]
Bakker, Jay Baxter, and Martin Saveski
Soham De, Michiel A. Bakker, Jay Baxter, and Martin Saveski. 2025. Supernotes: Driving Consensus in Crowd-Sourced Fact-Checking. InProceedings of the ACM on Web Conference 2025. 3751–3761
work page 2025
-
[9]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Max Glockner, Yufang Hou, Preslav Nakov, and Iryna Gurevych. 2024. Missci: Reconstructing Fallacies in Misrepresented Science. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Lun-Wei Ku, Andre Martins, and Vivek Srikumar (Eds.). Association for Computational Linguistics, Bangkok, Thailand,...
-
[11]
William Godel, Zeve Sanderson, Kevin Aslett, Jonathan Nagler, Richard Bonneau, Nathaniel Persily, and Joshua A Tucker. 2021. Moderating with the mob: Eval- uating the efficacy of real-time crowdsourced fact-checking.Journal of Online Trust and Safety1, 1 (2021)
work page 2021
-
[12]
Google. 2025. Gemini 2.5 Pro.https:// deepmind.google/ technologies/ gemini/ pro/ (2025)
work page 2025
-
[13]
Beizhe Hu, Qiang Sheng, Juan Cao, Yuhui Shi, Yang Li, Danding Wang, and Peng Qi. 2024. Bad actor, good advisor: Exploring the role of large language models in fake news detection. InProceedings of the AAAI conference on artificial intelligence, Vol. 38. 22105–22113
work page 2024
-
[14]
Md Saiful Islam, Tonmoy Sarkar, Sazzad Hossain Khan, Abu-Hena Mostofa Kamal, SM Murshid Hasan, Alamgir Kabir, Dalia Yeasmin, Mohammad Ariful Islam, Kamal Ibne Amin Chowdhury, Kazi Selim Anwar, et al. 2020. COVID-19– related infodemic and its impact on public health: A global social media analysis. The American journal of tropical medicine and hygiene103, ...
work page 2020
- [15]
-
[16]
Cameron Martel, Jennifer Allen, Gordon Pennycook, and David G Rand. 2024. Crowds can effectively identify misinformation at scale.Perspectives on Psycho- logical Science19, 2 (2024), 477–488
work page 2024
-
[17]
OpenAI. 2025. Introducing GPT-4.1 in the API.https:// openai.com/ index/ gpt-4-1/ (2025)
work page 2025
-
[18]
OpenAI. 2025. Introducing OpenAI o3 and o4-mini.https:// openai.com/ index/ introducing-o3-and-o4-mini/(2025)
work page 2025
-
[19]
Liangming Pan, Xiaobao Wu, Xinyuan Lu, Anh Tuan Luu, William Yang Wang, Min-Yen Kan, and Preslav Nakov. 2023. Fact-Checking Complex Claims with Program-Guided Reasoning. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 6981–7004
work page 2023
-
[20]
Jan Pfänder and Sacha Altay. 2025. Spotting false news and doubting true news: a systematic review and meta-analysis of news judgements.Nature human behaviour(2025), 1–12
work page 2025
-
[21]
Martin Potthast, Johannes Kiesel, Kevin Reinartz, Janek Bevendorff, and Benno Stein. 2017. A stylometric inquiry into hyperpartisan and fake news.arXiv preprint arXiv:1702.05638(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [22]
-
[23]
Jon Saad-Falcon, Omar Khattab, Christopher Potts, and Matei Zaharia. 2024. ARES: An Automated Evaluation Framework for Retrieval-Augmented Genera- tion Systems. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 338–354
work page 2024
-
[24]
Rodrygo L. T. Santos, Craig Macdonald, and Iadh Ounis. 2015. Search Result Diversification.Found. Trends Inf. Retr.9, 1 (2015), 1–90
work page 2015
-
[25]
Andrew Sellergren, Sahar Kazemzadeh, Tiam Jaroensri, Atilla Kiraly, Madeleine Traverse, Timo Kohlberger, Shawn Xu, Fayaz Jamil, Cían Hughes, Charles Lau, et al. 2025. Medgemma technical report.arXiv preprint arXiv:2507.05201(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Maryam Shahbazi and Deborah Bunker. 2024. Social media trust: Fighting misin- formation in the time of crisis.International Journal of Information Management 77 (2024), 102780
work page 2024
-
[27]
Gautam Kishore Shahi, Anne Dirkson, and Tim A Majchrzak. 2021. An ex- ploratory study of COVID-19 misinformation on Twitter.Online social networks and media22 (2021), 100104
work page 2021
- [28]
-
[29]
Sahajpreet Singh, Jiaying Wu, Svetlana Churina, and Kokil Jaidka. 2025. On the Limitations of LLM-Synthesized Social Media Misinformation Moderation. In ICLR 2025 Workshop ICBINB
work page 2025
-
[30]
Isaac Slaughter, Axel Peytavin, Johan Ugander, and Martin Saveski. 2025. Com- munity notes reduce engagement with and diffusion of false information online. Proceedings of the National Academy of Sciences122, 38 (2025), e2503413122
work page 2025
-
[31]
Mistral AI Team. 2024. Un Ministral, des Ministraux.https:// mistral.ai/ news/ ministraux(2024)
work page 2024
- [32]
-
[33]
Yuyan Wang, Cheenar Banerjee, Samer Chucri, Fabio Soldo, Sriraj Badam, Ed H. Chi, and Minmin Chen. 2025. Beyond Item Dissimilarities: Diversifying by Intent in Recommender Systems. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.1. 2672–2681
work page 2025
- [34]
-
[35]
Haolun Wu, Yansen Zhang, Chen Ma, Fuyuan Lyu, Bowei He, Bhaskar Mitra, and Xue Liu. 2024. Result Diversification in Search and Recommendation: A Survey .IEEE Transactions on Knowledge & Data Engineering36, 10 (2024), 5354–5373
work page 2024
-
[36]
Jiaying Wu, Jiafeng Guo, and Bryan Hooi. 2024. Fake News in Sheep’s Cloth- ing: Robust Fake News Detection Against LLM-Empowered Style Attacks. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 3367–3378
work page 2024
-
[37]
Jiaying Wu and Bryan Hooi. 2023. DECOR: Degree-Corrected Social Graph Refinement for Fake News Detection. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 2582–2593
work page 2023
-
[38]
Jiaying Wu, Shen Li, Ailin Deng, Miao Xiong, and Bryan Hooi. 2023. Prompt- and-Align: Prompt-Based Social Alignment for Few-Shot Fake News Detection. InProceedings of the 32nd ACM International Conference on Information and Knowledge Management. 2726–2736
work page 2023
-
[39]
Amelie Wuehrl, Dustin Wright, Roman Klinger, and Isabelle Augenstein. 2024. Understanding Fine-grained Distortions in Reports of Scientific Findings. In Findings of the Association for Computational Linguistics: ACL 2024. 6175–6191
work page 2024
-
[40]
xAI. 2025. Grok 4.https:// x.ai/ news/ grok-4(2025)
work page 2025
-
[41]
Weiwen Xu, Hou Pong Chan, Long Li, Mahani Aljunied, Ruifeng Yuan, Jianyu Wang, Chenghao Xiao, Guizhen Chen, Chaoqun Liu, Zhaodonghui Li, et al
-
[42]
Lingshu: A Generalist Foundation Model for Unified Multimodal Medical Understanding and Reasoning.arXiv preprint arXiv:2506.07044(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Hao Yu, Aoran Gan, Kai Zhang, Shiwei Tong, Qi Liu, and Zhaofeng Liu. 2025. Evaluation of Retrieval-Augmented Generation: A Survey. InBig Data. 102–120
work page 2025
-
[45]
Hengran Zhang, Ruqing Zhang, Jiafeng Guo, Maarten de Rijke, Yixing Fan, and Xueqi Cheng. 2024. Are Large Language Models Good at Utility Judgments?. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1941–1951
work page 2024
-
[46]
Xueyao Zhang, Juan Cao, Xirong Li, Qiang Sheng, Lei Zhong, and Kai Shu
-
[47]
InProceedings of the Web Conference 2021
Mining Dual Emotion for Fake News Detection. InProceedings of the Web Conference 2021. 3465–3476. Jiaying Wu et al
work page 2021
-
[48]
Xuan Zhang and Wei Gao. 2023. Towards LLM-based Fact Verification on News Claims with a Hierarchical Step-by-Step Prompting Method. InProceedings of the 13th International Joint Conference on Natural Language Processing and the 3rd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics (Volume 1: Long Papers). 996–1011
work page 2023
-
[49]
arXiv preprint arXiv:2403.11169 , year=
Xinyi Zhou, Ashish Sharma, Amy X Zhang, and Tim Althoff. 2024. Correcting misinformation on social media with a large language model.arXiv preprint arXiv:2403.11169(2024). Beyond the Crowd: LLM-Augmented Community Notes for Governing Health Misinformation A Details ofCrowdNotes+Framework A.1 Utility-Guided Evidence Curation In the automation mode (Section...
-
[51]
If at least one snippet meets the requirements, output "Final decision: yes"; otherwise output "Final decision: no". Jiaying Wu et al. Correctness.Conditioned on passing relevance, we evaluate whether the note faithfully represents the provided sources without factual errors, exaggerations, or misleading framing. Step 2: Note Correctness Evaluation (Secti...
-
[52]
Check each snippet independently
-
[53]
If at least one distortion is found, output "Final decision: yes"; otherwise output "Final decision: no". Helpfulness.Conditioned on passing correctness, we evaluate whether the note offers useful context that helps readers understand or assess the post, following X Community Notes guidelines. We use HealthJudge(temperature 0) for domain-adapted, determin...
-
[54]
Carefully read the Tweet and the Note
-
[55]
Analyze the Note using the Helpful and Not Helpful criteria above
-
[56]
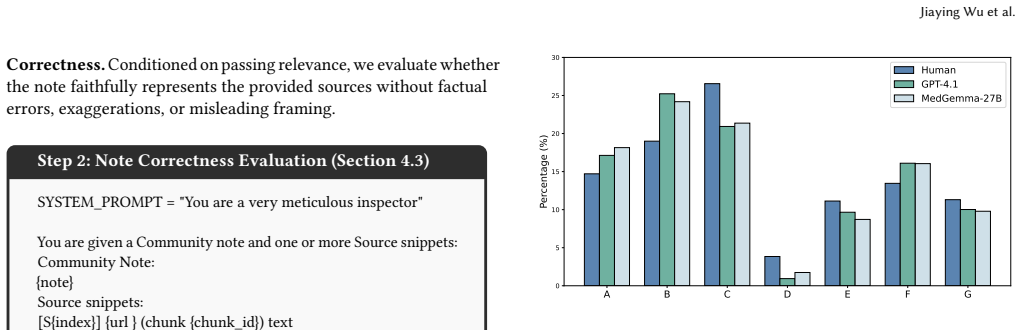
Respond with "Final decision: yes" (if Helpful) or "Final decision: no" (if Not Helpful). A B C D E F G 0 5 10 15 20 25 30Percentage (%) Human GPT-4.1 MedGemma-27B Figure 8: Human and LLM evidence source preferences. A: Health Authorities; B: Research Literature; C: News Media; D: Social Media; E: Health Portals; F: Commercial / Advocacy / NGO Sites; G: O...
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.