Bayes-Sufficient Representations in Supervised Learning
Pith reviewed 2026-06-28 11:05 UTC · model grok-4.3
The pith
The distribution and loss determine a Bayes quotient that specifies the minimal information required for Bayes-optimal prediction in a representation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In the almost-surely unique Bayes-action case, the Bayes action induced by the distribution and loss partitions the input space into a quotient. Any representation that refines this quotient is Bayes-sufficient, as it distinguishes inputs precisely when their optimal actions differ. A Bayes-minimal representation is one that is informationally equivalent to this quotient. The framework recovers standard targets from property elicitation: the Bayes class for zero-one loss, the conditional mean for squared loss, and the predictive distribution for strictly proper scoring rules.
What carries the argument
The Bayes quotient: the equivalence relation on inputs that share the same Bayes-optimal action.
If this is right
- Zero-one loss requires only class information while log loss requires the full conditional distribution.
- A representation can retain extra information beyond what is needed for the loss without harming optimality.
- Sufficiency and minimality can be tested separately in controlled experiments and neural architectures.
- The same representation may be minimal for one loss but not for another.
Where Pith is reading between the lines
- Standard contrastive or information-maximizing objectives may keep more information than a loss-specific minimal representation would require.
- Architectures could be trained with explicit quotient-refining constraints rather than generic bottlenecks.
- This view could guide the design of representations that are portable across related but differently lossed tasks.
Load-bearing premise
The Bayes-optimal action is almost surely unique for each input, so that the quotient is well-defined without ambiguity.
What would settle it
A counterexample would be a representation that achieves the Bayes risk for the loss yet maps two inputs with different optimal actions to the same representation value.
Figures
read the original abstract
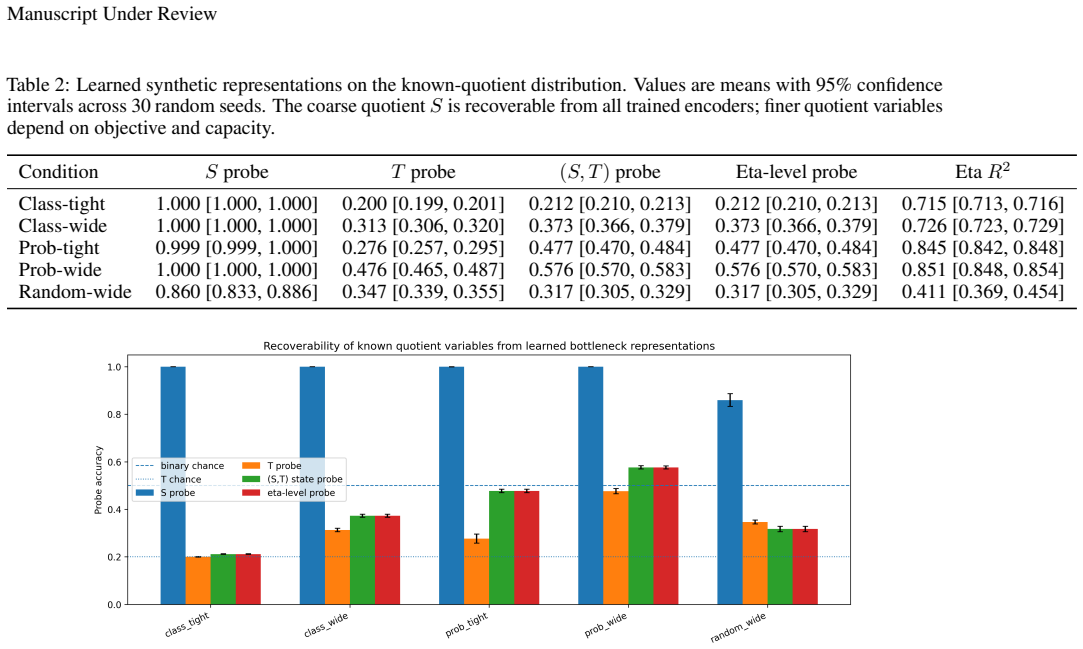
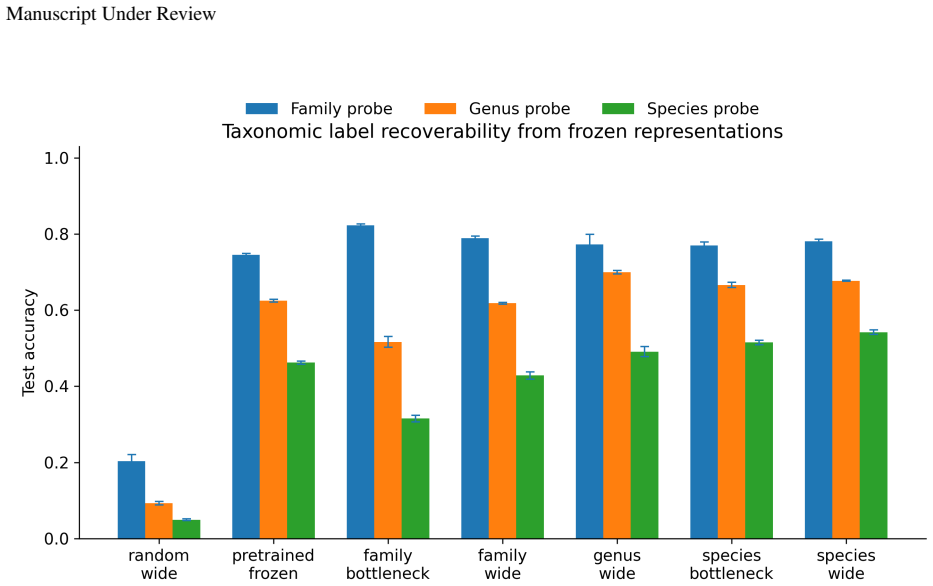
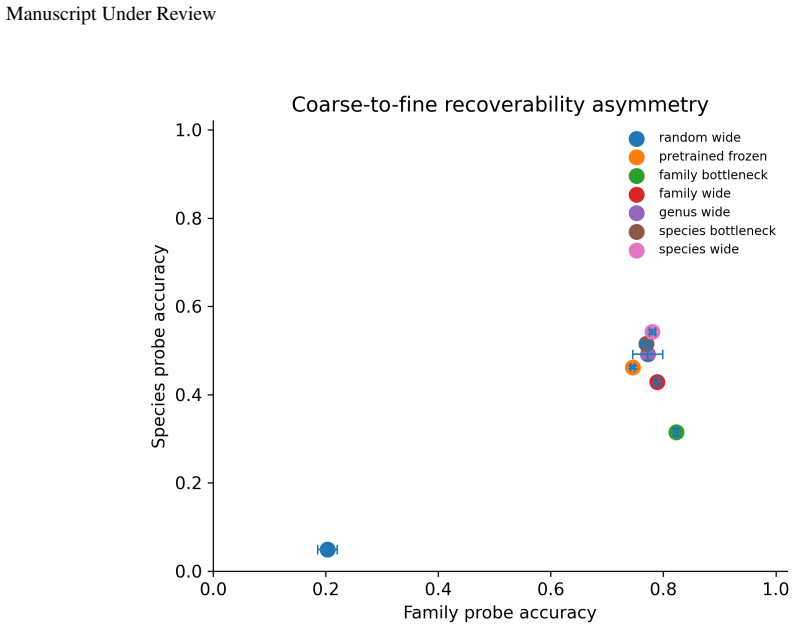
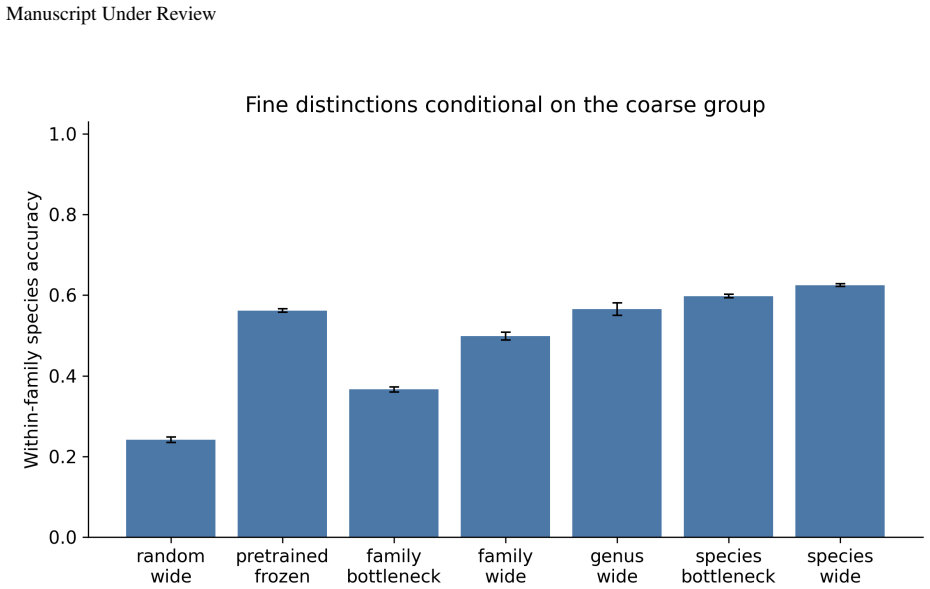
Representation learning is often described as preserving the information in an input that is relevant for prediction. This work asks what relevance means for a fixed supervised decision problem. A representation is defined to be Bayes-sufficient for a joint distribution and loss if some prediction head can use it to implement a Bayes-optimal action rule. This makes the target information loss-dependent. In the almost-surely unique Bayes-action case, the relevant object is a Bayes quotient, which identifies inputs that require the same Bayes-optimal action. A representation is sufficient when it refines this quotient, and Bayes-minimal when it is informationally equivalent to it. The framework connects naturally to property elicitation: zero-one loss requires the Bayes class, squared loss the conditional mean, Brier loss the conditional probability in binary prediction, and log loss or strictly proper scoring rules the predictive distribution. Controlled finite experiments, learned neural bottleneck experiments, and a real-data iNaturalist taxonomic refinement experiment illustrate the distinction between sufficiency, minimality, and retained non-required information. For a fixed supervised problem, the distribution and the loss determine the Bayes action, the Bayes action determines the quotient, and the quotient determines the minimal information required for Bayes-optimal prediction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper defines Bayes-sufficient representations for a fixed supervised problem: a representation is Bayes-sufficient w.r.t. a joint distribution P and loss L if there exists a head that achieves the Bayes risk using only the representation. In the a.s.-unique Bayes-action case it introduces the Bayes quotient (the equivalence relation on inputs that share the same Bayes action) as the minimal sigma-algebra permitting Bayes-optimal prediction; sufficiency means refinement of this quotient and minimality means equality. The construction is shown to recover standard objects from property elicitation (Bayes class for 0-1 loss, conditional mean for squared loss, etc.). Controlled synthetic experiments, neural-bottleneck training, and an iNaturalist taxonomic-refinement study illustrate the distinction between sufficiency, minimality, and retention of non-required information.
Significance. If the framework is adopted, it supplies a decision-theoretic criterion for what information must be preserved in representation learning that is explicitly loss-dependent and minimal. The link to property elicitation is natural and the experimental illustrations separate the notions of sufficiency and minimality in a concrete way. The contribution is primarily clarificatory and definitional rather than the derivation of new existence or approximation results.
minor comments (3)
- The abstract states that the framework 'connects naturally to property elicitation' but does not cite the specific elicitation literature (e.g., the works on proper scoring rules or the characterization of Bayes actions) that would make the connection immediate for readers.
- Notation for the Bayes quotient and the induced sigma-algebra is introduced only in the abstract; a short dedicated paragraph or diagram in the main text would help readers track the equivalence relation and its measurability properties.
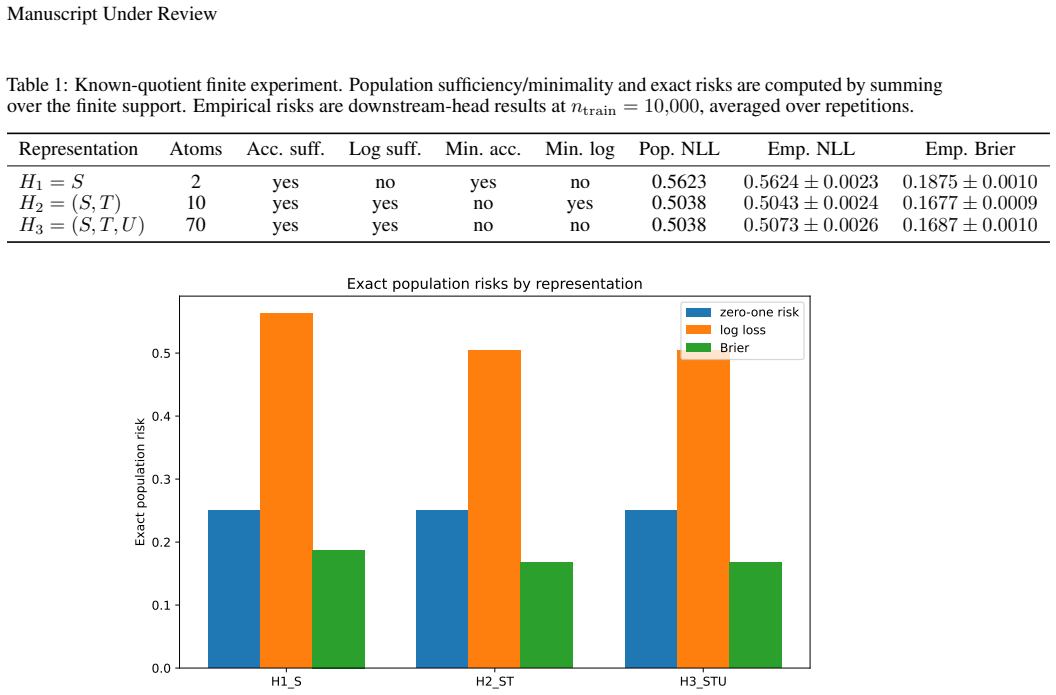
- The iNaturalist experiment description would benefit from an explicit statement of the loss function used and the precise definition of 'taxonomic refinement' so that the reader can verify that the retained information is indeed non-required under that loss.
Simulated Author's Rebuttal
We thank the referee for their positive summary of the paper and their recommendation to accept. The report accurately captures the contribution as a clarificatory framework linking Bayes sufficiency to property elicitation, with experiments distinguishing sufficiency from minimality. There are no major comments requiring response or revision.
Circularity Check
No significant circularity; derivation is self-contained from standard decision theory
full rationale
The paper defines Bayes-sufficiency directly from the joint distribution, loss, and the induced Bayes action map (assumed a.s. unique), then applies the standard quotient sigma-algebra construction to obtain the minimal sufficient representation. This chain uses only measure-theoretic facts about equivalence relations and refinements; no fitted parameters are relabeled as predictions, no self-citation supplies a uniqueness theorem, and no ansatz is smuggled in. The connection to property elicitation is presented as an illustration of known results rather than a new derivation. The central claim therefore reduces to definitions plus textbook facts once the Bayes action is fixed, with no load-bearing step that collapses to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption There exists a Bayes-optimal action rule for any joint distribution and loss under consideration.
invented entities (2)
-
Bayes quotient
no independent evidence
-
Bayes-sufficient representation
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Wald, Abraham , title =
-
[2]
, title =
Ferguson, Thomas S. , title =
-
[3]
, title =
Berger, James O. , title =
-
[4]
, title =
Fisher, Ronald A. , title =. Philosophical Transactions of the Royal Society of London. Series A , volume =
-
[5]
Giornale dell'Istituto Italiano degli Attuari , volume =
Neyman, Jerzy , title =. Giornale dell'Istituto Italiano degli Attuari , volume =
-
[6]
Lehmann, E. L. and Scheff. Completeness, Similar Regions, and Unbiased Estimation: Part I , journal =
-
[7]
Proceedings of the Second Berkeley Symposium on Mathematical Statistics and Probability , pages =
Blackwell, David , title =. Proceedings of the Second Berkeley Symposium on Mathematical Statistics and Probability , pages =
-
[8]
The Annals of Mathematical Statistics , volume =
Blackwell, David , title =. The Annals of Mathematical Statistics , volume =
-
[9]
Journal of the American Statistical Association , volume =
Li, Ker-Chau , title =. Journal of the American Statistical Association , volume =
-
[10]
Dennis , title =
Cook, R. Dennis , title =
-
[11]
Dennis and Li, Bing , title =
Cook, R. Dennis and Li, Bing , title =. The Annals of Statistics , volume =
-
[12]
and Jordan, Michael I
Fukumizu, Kenji and Bach, Francis R. and Jordan, Michael I. , title =. The Annals of Statistics , volume =
-
[13]
, title =
Savage, Leonard J. , title =. Journal of the American Statistical Association , volume =
-
[14]
, title =
Gneiting, Tilmann and Raftery, Adrian E. , title =. Journal of the American Statistical Association , volume =
-
[15]
and Pennock, David M
Lambert, Nicolas S. and Pennock, David M. and Shoham, Yoav , title =. Proceedings of the 9th ACM Conference on Electronic Commerce , pages =
-
[16]
, title =
Frongillo, Rafael and Kash, Ian A. , title =. Proceedings of Machine Learning Research , volume =
-
[17]
and Bialek, William , title =
Tishby, Naftali and Pereira, Fernando C. and Bialek, William , title =. Proceedings of the 37th Annual Allerton Conference on Communication, Control, and Computing , pages =
-
[18]
2015 IEEE Information Theory Workshop , pages =
Tishby, Naftali and Zaslavsky, Noga , title =. 2015 IEEE Information Theory Workshop , pages =
2015
-
[19]
Journal of Machine Learning Research , volume =
Achille, Alessandro and Soatto, Stefano , title =. Journal of Machine Learning Research , volume =
-
[20]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume =
Achille, Alessandro and Soatto, Stefano , title =. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume =
-
[21]
International Conference on Learning Representations Workshop , year =
Alain, Guillaume and Bengio, Yoshua , title =. International Conference on Learning Representations Workshop , year =
-
[22]
Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing , pages =
Hewitt, John and Liang, Percy , title =. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing , pages =
2019
-
[23]
Computational Linguistics , volume =
Belinkov, Yonatan , title =. Computational Linguistics , volume =
-
[24]
Pearl, Judea , title =
-
[25]
Proceedings of the Thirteenth International Conference on Machine Learning , pages =
Koller, Daphne and Sahami, Mehran , title =. Proceedings of the Thirteenth International Conference on Machine Learning , pages =
-
[26]
and Tsamardinos, Ioannis and Statnikov, Alexander , title =
Aliferis, Constantin F. and Tsamardinos, Ioannis and Statnikov, Alexander , title =. AMIA Annual Symposium Proceedings , pages =
-
[27]
, title =
Shalizi, Cosma Rohilla and Crutchfield, James P. , title =. Journal of Statistical Physics , volume =
-
[28]
and Sutton, Richard S
Littman, Michael L. and Sutton, Richard S. and Singh, Satinder P. , title =. Advances in Neural Information Processing Systems , volume =
-
[29]
Causal Inference by Using Invariant Prediction: Identification and Confidence Intervals , journal =
Peters, Jonas and B. Causal Inference by Using Invariant Prediction: Identification and Confidence Intervals , journal =
-
[30]
Invariant Risk Minimization , journal =
Arjovsky, Martin and Bottou, L. Invariant Risk Minimization , journal =
-
[31]
Journal of Artificial Intelligence Research , volume =
Mandi, Jayanta and Kotary, James and Berden, Senne and Mulamba, Maxime and Guns, Tias , title =. Journal of Artificial Intelligence Research , volume =
-
[32]
arXiv preprint arXiv:2505.03953 , year =
Schutte, Noah and Veviurko, Grigorii and Postek, Krzysztof and Yorke-Smith, Neil , title =. arXiv preprint arXiv:2505.03953 , year =
-
[33]
2026 , eprint=
A Fiber Criterion for Representation Identifiability in Supervised Learning , author=. 2026 , eprint=
2026
-
[34]
The Fourteenth International Conference on Learning Representations , year=
Gauge-invariant representation holonomy , author=. The Fourteenth International Conference on Learning Representations , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.