OncoSynth: Synthetic data generation for treatment effect estimation in oncology
Pith reviewed 2026-06-25 20:27 UTC · model grok-4.3
The pith
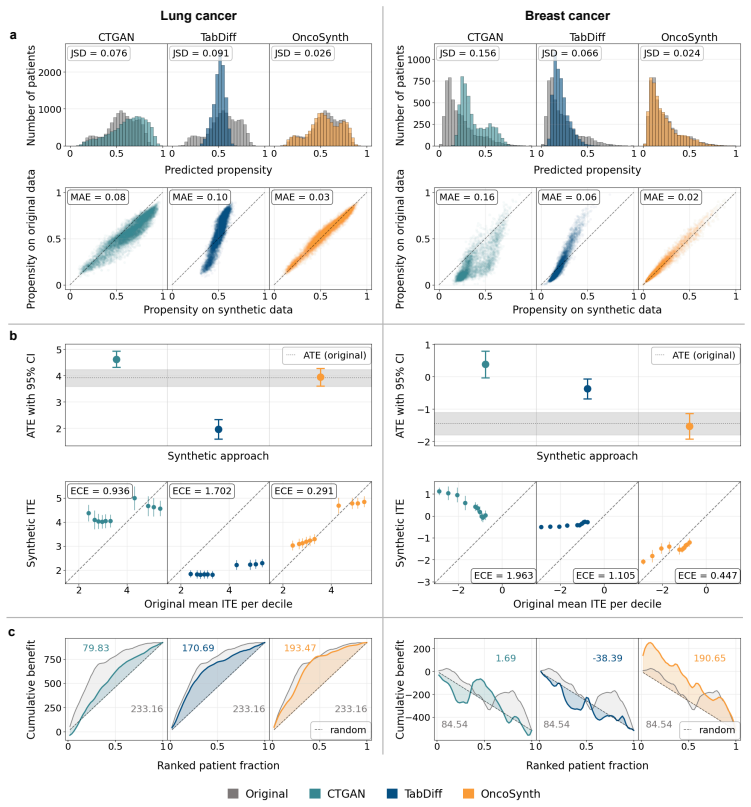
OncoSynth generates synthetic oncology data that reduces population-level treatment effect error by up to 66 percent and patient-level error by up to 58 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
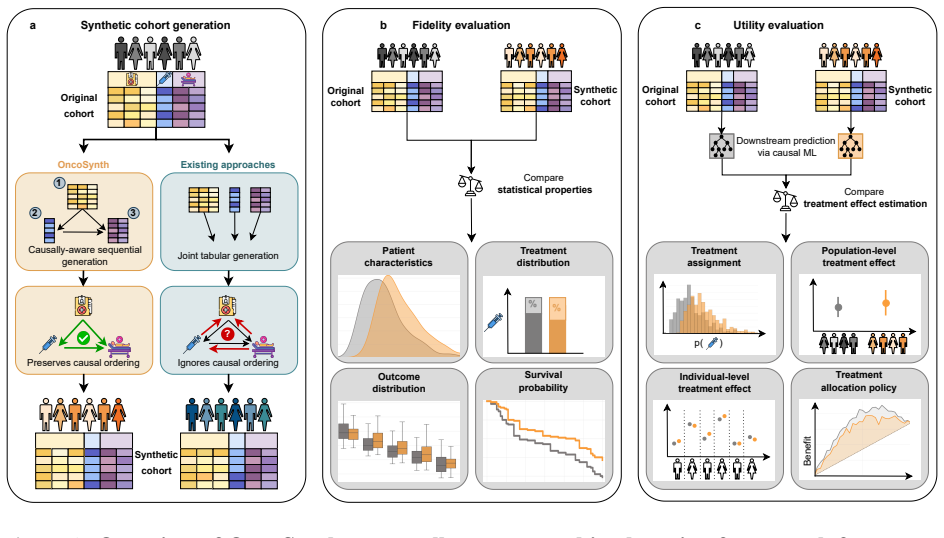
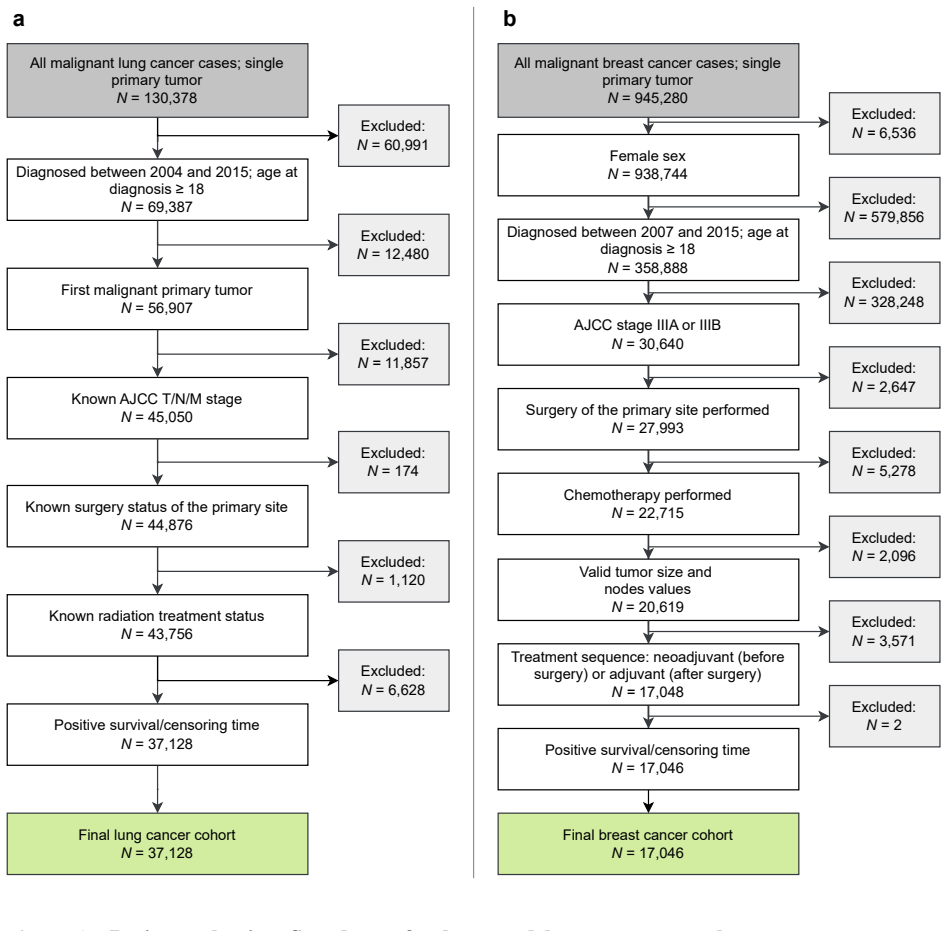
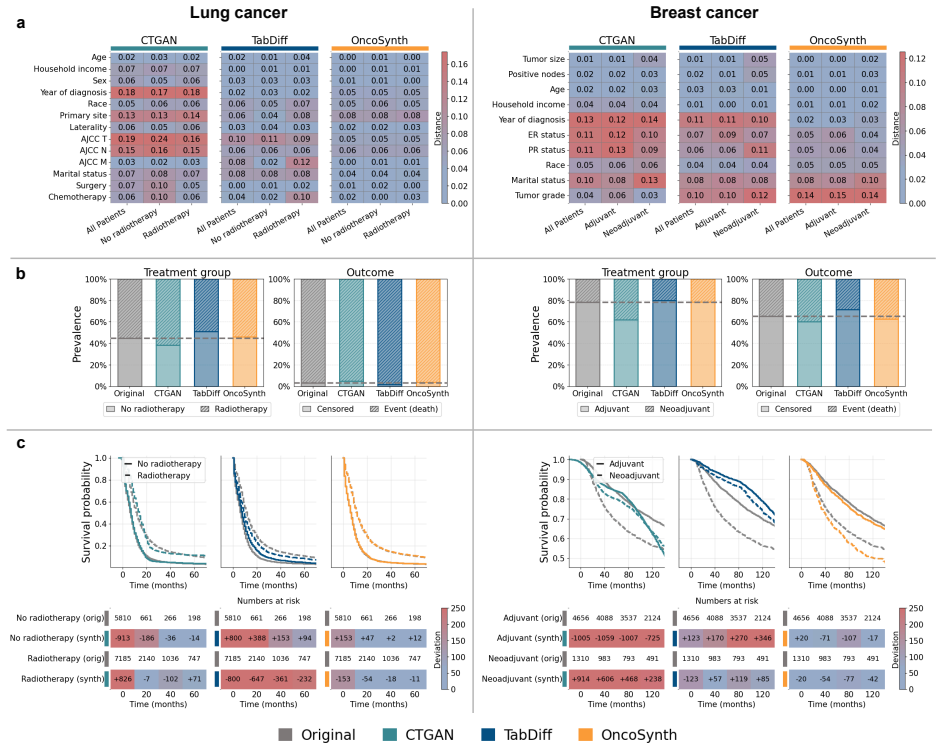
OncoSynth uses a diffusion-based sequential approach to generate synthetic cohorts from large lung cancer (N=37,128) and breast cancer (N=17,046) datasets. These cohorts preserve real-world distributions of patients, treatments, and outcomes, enabling treatment effect estimation with up to 66 percent lower population-level error and 58 percent lower patient-level error than prior methods.
What carries the argument
Diffusion-based sequential generative model that first captures covariate effects on treatment assignment and then models treatment effects on outcomes.
If this is right
- Synthetic cohorts enable treatment effect studies in oncology settings where data sharing is restricted.
- Population-level treatment effect estimates become more accurate than with existing synthetic data approaches.
- Patient-level treatment effect estimates improve, supporting individualized analysis.
- High-fidelity synthetic data maintains the distributions of real patients, treatments, and outcomes.
Where Pith is reading between the lines
- The framework might be applied to other cancer types or medical domains with similar data access limits to test broader utility.
- Integration with real data in hybrid analyses could further refine estimates in future work.
- Validation on independent external datasets would check whether the error reductions generalize beyond the lung and breast cohorts studied.
Load-bearing premise
The diffusion-based sequential model accurately captures and preserves the true causal relationships between covariates, treatment assignment, and outcomes without introducing new biases.
What would settle it
A comparison on held-out real patient records showing that treatment effect estimates from the synthetic data deviate substantially from those computed on the original data would falsify the accuracy claim.
Figures
read the original abstract
In oncology, access to patient-level data is often restricted. Synthetic data provides an alternative for analyzing treatment effectiveness, but existing methods for synthetic data generation fail to preserve the causal relationships between covariates, treatments, and outcomes, thereby leading to biased estimates of treatment effects. Here, we introduce OncoSynth, a generative, causally-aware machine learning framework designed to produce synthetic cohorts that enable accurate estimation of population- and patient-level treatment effects. OncoSynth uses a diffusion-based sequential approach to model how covariates influence treatment assignment and how treatment affects survival. We evaluate OncoSynth using large lung (N = 37,128) and breast cancer (N = 17,046) cohorts. Our results show that OncoSynth generates high-fidelity synthetic patient cohorts that preserve real-world patient, treatment, and outcome distributions. Notably, OncoSynth improves treatment effect estimation over existing approaches, by reducing population-level treatment effect error by up to 66%, and patient-level treatment effect error by up to 58%. Thereby, OncoSynth supports reliable evidence generation for precision oncology in settings where data sharing is restricted.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces OncoSynth, a diffusion-based sequential generative model for synthetic oncology cohorts that aims to preserve causal relationships between covariates, treatment assignment, and survival outcomes. Evaluated on lung cancer (N=37,128) and breast cancer (N=17,046) cohorts, it claims to generate high-fidelity data and reduce population-level treatment effect error by up to 66% and patient-level error by up to 58% relative to existing synthetic data methods.
Significance. If the central claims hold under rigorous validation, OncoSynth would address a practical barrier in oncology research by enabling treatment-effect studies from synthetic data when real patient-level records cannot be shared. The diffusion sequential construction is a plausible direction for causally-aware generation, but the significance hinges on whether the reported error reductions reflect improved causal fidelity rather than reproduction of observational confounding structures.
major comments (2)
- [Evaluation / Results] Evaluation section (results on treatment effect error): the patient-level treatment effect error is computed by comparing estimates induced by synthetic cohorts to estimates from the same real observational data. Because patient-level effects are not point-identified in observational oncology data without untestable assumptions (no unmeasured confounding, correct model specification, positivity), this metric risks rewarding synthetic data that reproduces rather than corrects the original confounding; the manuscript does not report sensitivity analyses or explicit do-operator interventions to break this dependence.
- [Abstract / §3] Abstract and §3 (model description): the claim that OncoSynth 'preserves the causal relationships' and thereby improves treatment effect estimation is not accompanied by an explicit identification strategy (e.g., simulated interventions, propensity-score matching within the generative process, or falsification tests against known RCT benchmarks). Without such a mechanism, the 66% / 58% reductions cannot be distinguished from improved imitation of the real-data estimator.
minor comments (2)
- [Abstract] Abstract: the performance claims omit the specific baselines, error metric definitions (e.g., absolute vs. relative error, ATE vs. CATE), confidence intervals, and statistical significance tests; these details are required to interpret the 'up to 66%' and 'up to 58%' figures.
- [Experiments] Data description: the lung and breast cohorts are referenced only by sample size; the manuscript should state the source registries, inclusion criteria, and any preprocessing steps that could affect causal structure.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the evaluation of causal fidelity in synthetic data generation. We provide point-by-point responses to the major comments below.
read point-by-point responses
-
Referee: [Evaluation / Results] Evaluation section (results on treatment effect error): the patient-level treatment effect error is computed by comparing estimates induced by synthetic cohorts to estimates from the same real observational data. Because patient-level effects are not point-identified in observational oncology data without untestable assumptions (no unmeasured confounding, correct model specification, positivity), this metric risks rewarding synthetic data that reproduces rather than corrects the original confounding; the manuscript does not report sensitivity analyses or explicit do-operator interventions to break this dependence.
Authors: We agree that this is a valid concern, as patient-level treatment effects cannot be point-identified from observational data alone. Our sequential diffusion model aims to better capture the underlying causal structure by generating data according to the temporal and causal ordering of variables. Nevertheless, to strengthen the claims, we will incorporate sensitivity analyses for unmeasured confounding and explicit simulation of interventions (do-operator) in the revised version of the manuscript. revision: yes
-
Referee: [Abstract / §3] Abstract and §3 (model description): the claim that OncoSynth 'preserves the causal relationships' and thereby improves treatment effect estimation is not accompanied by an explicit identification strategy (e.g., simulated interventions, propensity-score matching within the generative process, or falsification tests against known RCT benchmarks). Without such a mechanism, the 66% / 58% reductions cannot be distinguished from improved imitation of the real-data estimator.
Authors: The model description in §3 details a diffusion-based sequential generative process that conditions on the causal graph implied by the oncology data: first generating covariates, then treatment assignment based on covariates, and finally outcomes conditional on treatment and covariates. This is our mechanism for preserving causal relationships. We will revise the abstract and §3 to more explicitly articulate this identification strategy and discuss how it differs from standard imitation. Regarding RCT benchmarks, while not available in our current observational cohorts, we can add a discussion of potential future validation approaches. revision: partial
Circularity Check
No significant circularity; evaluation uses external real cohorts
full rationale
The paper introduces OncoSynth as a diffusion-based generative model and reports empirical improvements (up to 66% and 58% error reduction) on held-out real lung (N=37,128) and breast cancer (N=17,046) cohorts. No equations or text in the provided abstract or description show a prediction or uniqueness result that reduces by construction to a fitted parameter or self-citation. The central claims rest on external data fidelity checks rather than internal re-derivation of the same quantities. Self-citation load-bearing or ansatz smuggling is not exhibited. This is the common honest case of a self-contained empirical method.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
M., Karim, S
Booth, C. M., Karim, S. & Mackillop, W. J. Real-world data: towards achieving the achiev- able in cancer care.Nature Reviews Clinical Oncology16, 312–325 (2019)
2019
-
[2]
Keyl, J.et al.Decoding pan-cancer treatment outcomes using multimodal real-world data and explainable artificial intelligence.Nature Cancer6, 307–322 (2025)
2025
-
[3]
GDPR obstructs cancer research data sharing.The Lancet Oncology22, 592 (2021)
Gourd, E. GDPR obstructs cancer research data sharing.The Lancet Oncology22, 592 (2021)
2021
-
[4]
M., Triantis, G., Stanton, R., Blumenkranz, E
Mello, M. M., Triantis, G., Stanton, R., Blumenkranz, E. & Studdert, D. M. Waiting for data: Barriers to executing data use agreements.Science367, 150–152 (2020)
2020
-
[5]
G., Page, M
Hamilton, D. G., Page, M. J., Finch, S., Everitt, S. & Fidler, F. How often do cancer re- searchers make their data and code available and what factors are associated with sharing? BMC Medicine20, 438 (2022)
2022
-
[6]
J., Lu, M
Chen, R. J., Lu, M. Y ., Chen, T. Y ., Williamson, D. F. & Mahmood, F. Synthetic data in machine learning for medicine and healthcare.Nature Biomedical Engineering5, 493–497 (2021)
2021
-
[7]
npj Digital Medicine8, 60 (2025)
Kaabachi, B.et al.A scoping review of privacy and utility metrics in medical synthetic data. npj Digital Medicine8, 60 (2025)
2025
-
[8]
& Smith, S
Gonzales, A., Guruswamy, G. & Smith, S. R. Synthetic data in health care: A narrative review.PLOS Digital Health2, e0000082 (2023)
2023
-
[9]
& Shung, D
Giuffrè, M. & Shung, D. L. Harnessing the power of synthetic data in healthcare: innovation, application, and privacy.npj Digital Medicine6, 186 (2023). 43
2023
-
[10]
Kingma, D. P. & Welling, M. Auto-encoding variational Bayes.arXiv:1312.6114(2013)
Pith/arXiv arXiv 2013
-
[11]
J.et al.Generative adversarial nets
Goodfellow, I. J.et al.Generative adversarial nets. InAdvances in Neural Information Processing Systems (NeurIPS), 27 (2014)
2014
-
[12]
& Veeramachaneni, K
Xu, L., Skoularidou, M., Cuesta-Infante, A. & Veeramachaneni, K. Modeling tabular data using conditional GAN.Advances in Neural Information Processing Systems (NeurIPS)32 (2019)
2019
-
[13]
& Ganguli, S
Sohl-Dickstein, J., Weiss, E., Maheswaranathan, N. & Ganguli, S. Deep unsupervised learn- ing using nonequilibrium thermodynamics.International Conference on Machine Learning (ICML)2256–2265 (2015)
2015
-
[14]
InInterna- tional Conference on Learning Representations (ICLR)(2025)
Shi, J.et al.TabDiff: A mixed-type diffusion model for tabular data generation. InInterna- tional Conference on Learning Representations (ICLR)(2025)
2025
-
[15]
& Babenko, A
Kotelnikov, A., Baranchuk, D., Rubachev, I. & Babenko, A. TabDDPM: Modelling tabu- lar data with diffusion models. InInternational Conference on Machine Learning (ICML), 17564–17579 (2023)
2023
-
[16]
Choi, E.et al.Generating multi-label discrete patient records using generative adversarial networks.Machine Learning for Healthcare Conference286–305 (2017)
2017
-
[17]
K., Lin, C.-C., Liu, C.-L
Baowaly, M. K., Lin, C.-C., Liu, C.-L. & Chen, K.-T. Synthesizing electronic health records using improved generative adversarial networks.Journal of the American Medical Informat- ics Association26, 228–241 (2019)
2019
-
[18]
He, H., Zhao, S., Xi, Y . & Ho, J. C. MedDiff: Generating electronic health records using accelerated denoising diffusion model.arXiv:2302.04355(2023)
arXiv 2023
-
[19]
Yuan, H., Zhou, S. & Yu, S. EHRDiff: Exploring realistic EHR synthesis with diffusion models.Transactions on Machine Learning Research(2024). 44
2024
-
[20]
Kühnel, L.et al.Synthetic data generation for a longitudinal cohort study - evaluation, method extension and reproduction of published data analysis results.Scientific Reports14, 14412 (2024)
2024
-
[21]
Kuo, N. I.-H., Jorm, L. & Barbieri, S. Synthetic health-related longitudinal data with mixed- type variables generated using diffusion models.arXiv:2303.12281(2023)
arXiv 2023
-
[22]
Ceritli, T.et al.Synthesizing mixed-type electronic health records using diffusion models. arXiv:2302.14679(2023)
arXiv 2023
-
[23]
& Sun, J
Theodorou, B., Xiao, C. & Sun, J. Synthesize high-dimensional longitudinal electronic health records via hierarchical autoregressive language model.Nature Communications14, 5305 (2023)
2023
-
[24]
Alaa, A., Van Breugel, B., Saveliev, E. S. & van der Schaar, M. How faithful is your synthetic data? Sample-level metrics for evaluating and auditing generative models. InInternational Conference on Machine Learning (ICML), 290–306 (PMLR, 2022)
2022
- [25]
-
[26]
InAdvances in Neural Information Processing Systems (NeurIPS) (2025)
Amad, H.et al.Improving the generation and evaluation of synthetic data for downstream medical causal inference. InAdvances in Neural Information Processing Systems (NeurIPS) (2025)
2025
-
[27]
Yan, C.et al.A multifaceted benchmarking of synthetic electronic health record generation models.Nature Communications13, 7609 (2022)
2022
-
[28]
& Norgeot, B
Shi, J., Wang, D., Tesei, G. & Norgeot, B. Generating high-fidelity privacy-conscious syn- thetic patient data for causal effect estimation with multiple treatments.Frontiers in Artificial Intelligence5, 918813 (2022). 45
2022
-
[29]
Eckardt, J.-N.et al.Mimicking clinical trials with synthetic acute myeloid leukemia patients using generative artificial intelligence.npj Digital Medicine7, 76 (2024)
2024
-
[30]
R., Sverdrup, E., Wager, S
Cui, Y ., Kosorok, M. R., Sverdrup, E., Wager, S. & Zhu, R. Estimating heterogeneous treat- ment effects with right-censored data via causal survival forests.Journal of the Royal Statis- tical Society, Series B (Statistical Methodology)85, 179–211 (2023)
2023
-
[31]
Feuerriegel, S.et al.Causal machine learning for predicting treatment outcomes.Nature Medicine30, 958–968 (2024)
2024
-
[32]
SEER*Stat Database
Surveillance, Epidemiology, and End Results (SEER) Program. SEER*Stat Database. Na- tional Cancer Institute, DCCPS, Surveillance Research Program (2025). Released April 2025, based on the November 2024 submission
2025
-
[33]
& Kehl, K
Weberpals, J., Feuerriegel, S., van der Schaar, M. & Kehl, K. L. Opportunities for causal machine learning in precision oncology.NEJM AI2, AIp2500277 (2025)
2025
-
[34]
Chen, Y .et al.A retrospective study on the impact of radiotherapy on the survival outcomes of small cell lung cancer patients based on the SEER database.Scientific Reports14, 15552 (2024)
2024
-
[35]
J.et al.Use of thoracic radiotherapy for extensive stage small-cell lung cancer: a phase 3 randomised controlled trial.Lancet385, 36–42 (2015)
Slotman, B. J.et al.Use of thoracic radiotherapy for extensive stage small-cell lung cancer: a phase 3 randomised controlled trial.Lancet385, 36–42 (2015)
2015
-
[36]
Xu, Y .et al.Impact of neoadjuvant and adjuvant chemotherapy on breast cancer prognosis in a propensity score matched population.Scientific Reports15, 36220 (2025)
2025
-
[37]
J., Hayward, R
Dahabreh, I. J., Hayward, R. & Kent, D. M. Using group data to treat individuals: under- standing heterogeneous treatment effects in the age of precision medicine and patient-centred evidence.International Journal of Epidemiology45, 2184–2193 (2016). 46
2016
-
[38]
Hernán, M. A. & Robins, J. M. Using big data to emulate a target trial when a randomized trial is not available.American Journal of Epidemiology183, 758–764 (2016)
2016
-
[39]
M., Steyerberg, E
Kent, D. M., Steyerberg, E. & van Klaveren, D. Personalized evidence based medicine: predictive approaches to heterogeneous treatment effects.BMJ363, k4245 (2018)
2018
-
[40]
N., Meurers, T., Johns, M
Wirth, F. N., Meurers, T., Johns, M. & Prasser, F. Privacy-preserving data sharing infrastruc- tures for medical research: systematization and comparison.BMC Medical Informatics and Decision Making21, 242 (2021)
2021
-
[41]
& Abbeel, P
Ho, J., Jain, A. & Abbeel, P. Denoising diffusion probabilistic models.Advances in Neural Information Processing Systems (NeurIPS)33, 6840–6851 (2020)
2020
-
[42]
& Ermon, S
Song, J., Meng, C. & Ermon, S. Denoising diffusion implicit models. InInternational Conference on Learning Representations (ICLR)(2021)
2021
-
[43]
& Elkan, C
Zadrozny, B. & Elkan, C. Obtaining calibrated probability estimates from decision trees and naive Bayesian classifiers. InInternational Conference on Machine Learning (ICML)(2001)
2001
-
[44]
R., Sekhon, J
Künzel, S. R., Sekhon, J. S., Bickel, P. J. & Yu, B. Metalearners for estimating heterogeneous treatment effects using machine learning.Proceedings of the National Academy of Sciences 116, 4156–4165 (2019)
2019
-
[45]
B., Blackstone, E
Ishwaran, H., Kogalur, U. B., Blackstone, E. H. & Lauer, M. S. Random survival forests.The Annals of Applied Statistics2, 841–860 (2008)
2008
-
[46]
Advances in Neural Information Processing Systems (NeurIPS)32(2019)
Paszke, A.et al.PyTorch: An imperative style, high-performance deep learning library. Advances in Neural Information Processing Systems (NeurIPS)32(2019)
2019
-
[47]
& Wager, S
Athey, S., Tibshirani, J. & Wager, S. Generalized random forests.The Annals of Statistics 47, 1148–1178 (2019). 47
2019
-
[48]
Pedregosa, F.et al.scikit-learn: Machine learning in Python.Journal of Machine Learning Research12, 2825–2830 (2011)
2011
-
[49]
scikit-survival: A library for time-to-event analysis built on top of scikit-learn
Pölsterl, S. scikit-survival: A library for time-to-event analysis built on top of scikit-learn. Journal of Machine Learning Research21, 1–6 (2020)
2020
-
[50]
& Koyama, M
Akiba, T., Sano, S., Yanase, T., Ohta, T. & Koyama, M. Optuna: A next-generation hy- perparameter optimization framework. InProceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD)(2019)
2019
-
[51]
M.et al.The predictive approaches to treatment effect heterogeneity (PATH) state- ment.Annals of Internal Medicine172, 35–45 (2020)
Kent, D. M.et al.The predictive approaches to treatment effect heterogeneity (PATH) state- ment.Annals of Internal Medicine172, 35–45 (2020)
2020
-
[52]
Kantorovich, L. V . Mathematical methods of organizing and planning production.Manage- ment Science6, 366–422 (1960)
1960
-
[53]
Divergence measures based on the Shannon entropy.IEEE Transactions on Informa- tion Theory37, 145–151 (1991)
Lin, J. Divergence measures based on the Shannon entropy.IEEE Transactions on Informa- tion Theory37, 145–151 (1991)
1991
-
[54]
PLOS Digital Health4, e0000721 (2025)
Doutreligne, M.et al.Step-by-step causal analysis of EHRs to ground decision-making. PLOS Digital Health4, e0000721 (2025)
2025
-
[55]
A., Wang, W
Hernán, M. A., Wang, W. & Leaf, D. E. Target trial emulation: A framework for causal inference from observational data.JAMA328, 2446–2447 (2022)
2022
-
[56]
other/unknown
Radcliffe, N. Using control groups to target on predicted lift: Building and assessing uplift model.Direct Marketing Analytics Journal14–21 (2007). 48 Author contributions O.-A.C, J.W., D.F., H.A., T.C., M.v.d.S., and S.F. contributed to conceptualization. O.-A.C., D.F., M.S., and S.F. designed the methodology. O.-A.C., J.W., and M.B. extracted the datase...
2007
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.