On-Policy Self-Distillation with Sampled Demonstrations Reduces Output Diversity
Pith reviewed 2026-06-25 19:21 UTC · model grok-4.3
The pith
Self-distillation amplifies probability gaps and reduces rollout diversity
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
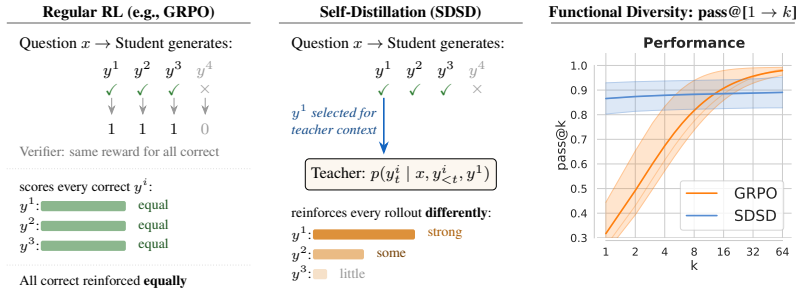
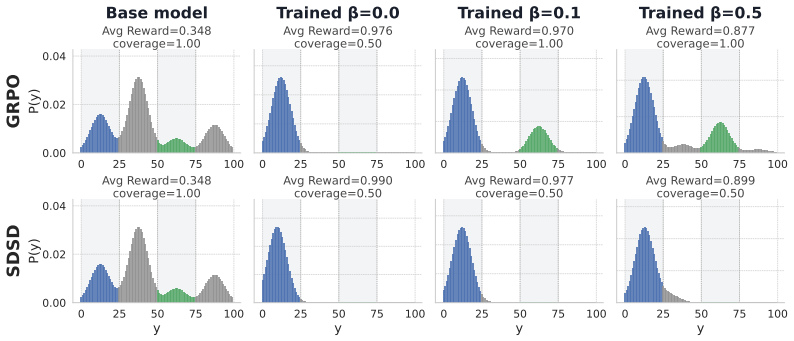
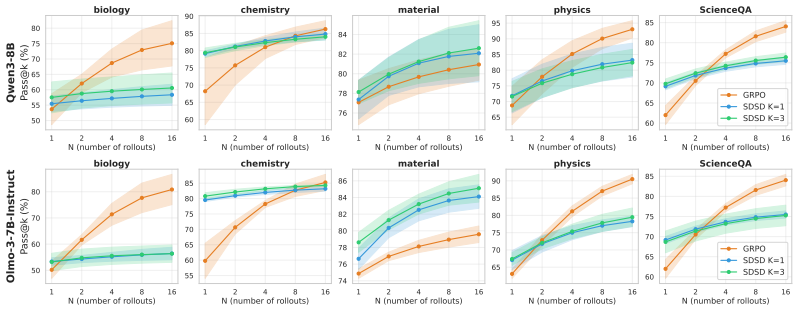
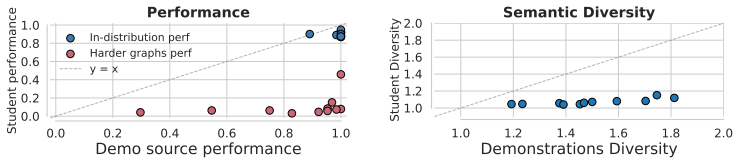
Self-distillation tilts the base distribution by a pointwise conditional mutual information score between the student's rollout and the correct rollout used as context. Unlike the ideal optimal on-policy reinforcement learning, which preserves probability ratios among equally correct rollouts, self-distillation can amplify existing probability gaps, concentrating mass on already-dominant modes. This results in lower functional and semantic diversity on a graph path-finding task and science question-answering benchmarks, where self-distilled models fail on out-of-distribution settings that require diverse strategies despite matching or exceeding RL on average performance.
What carries the argument
Conditioning the teacher on a sampled correct rollout when scoring student rollouts, which channels feedback through the model's biases via a pointwise conditional mutual information term
If this is right
- Self-distilled models match or exceed RL on average performance
- Self-distilled models exhibit substantially lower functional and semantic diversity
- Pass@k curves flatten for self-distilled models
- Self-distilled models fail on out-of-distribution settings that require diverse strategies
Where Pith is reading between the lines
- The bias amplification could grow stronger across multiple rounds of self-distillation
- Domains that reward multiple distinct solutions, such as planning or code generation, may see larger performance gaps from this training choice
- Training procedures that avoid conditioning the teacher on a specific demonstration might avoid the diversity reduction while retaining the dense feedback benefit
Load-bearing premise
The teacher scores each student rollout while conditioned on a sampled correct rollout, channeling its feedback through the model's own biases.
What would settle it
An experiment on the graph path-finding task that trains one model with self-distillation and one with RL to the same average accuracy, then measures whether the self-distilled model shows lower functional diversity and a flatter pass@k curve; absence of the difference would falsify the claim.
Figures

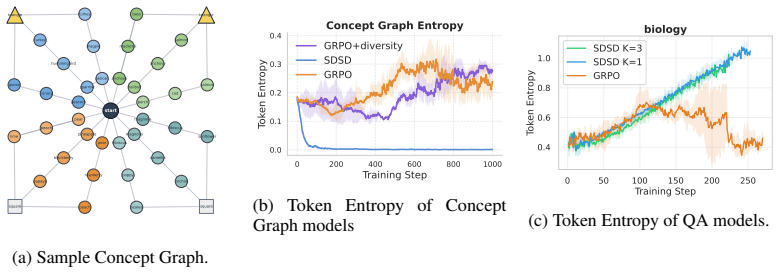
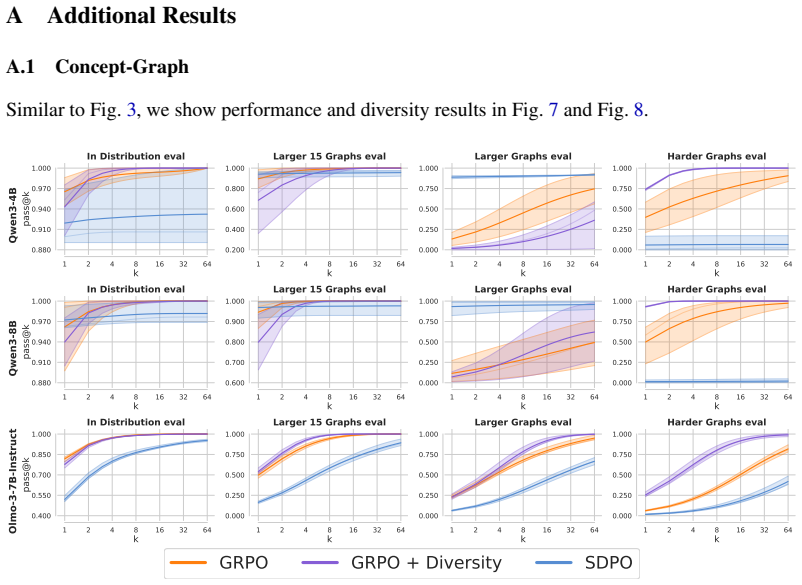
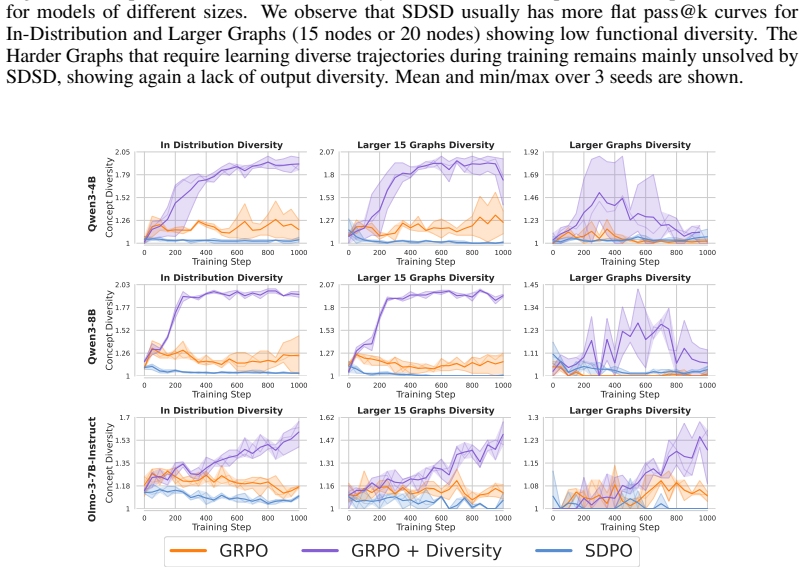
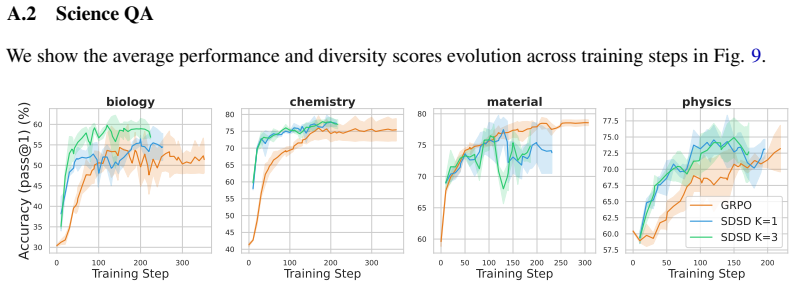
read the original abstract
On-policy self-distillation achieves strong pass@1 accuracy by using a single model as both teacher and student, with the teacher conditioned on a correct demonstration to provide dense token-level feedback. We show that this could come at a hidden cost: rollout diversity decreases and pass@k curves flatten (i.e., generating more rollouts fails to improve accuracy). We trace this to compounding biases in the design of self-distillation with sampled demonstrations. The teacher scores each student rollout while conditioned on a sampled correct rollout, channeling its feedback through the model's own biases. We theoretically analyze the optimal self-distillation policy and show that it tilts the base distribution by a pointwise conditional mutual information score between the student's rollout and the correct rollout used as context. Unlike the ideal optimal on-policy reinforcement learning (RL), which preserves probability ratios among equally correct rollouts, self-distillation can amplify existing probability gaps, concentrating mass on already-dominant modes. On a controlled graph path-finding task and science question-answering benchmarks, self-distilled models match or exceed RL on average performance but exhibit substantially lower functional and semantic diversity, failing on out-of-distribution settings that require diverse strategies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that on-policy self-distillation with sampled demonstrations reduces rollout diversity (flattening pass@k curves) relative to ideal RL because the teacher, conditioned on a sampled correct rollout, channels feedback through the model's own biases. Theoretically, the optimal self-distillation policy tilts the base distribution by pointwise conditional mutual information between the student rollout and the conditioned correct rollout, amplifying existing probability gaps among correct outputs; empirically this is shown on a controlled graph path-finding task and science QA benchmarks where self-distilled models match or exceed RL on average performance but exhibit lower functional/semantic diversity and fail on OOD settings requiring diverse strategies.
Significance. If the central claim holds, the work provides a mechanistic account of a hidden cost in self-distillation for generative models, with the theoretical derivation of the optimal policy (contrasted to RL's preservation of probability ratios) and the controlled graph task constituting clear strengths. The result would be relevant for practitioners choosing between self-distillation and RL when diversity matters for robustness.
major comments (1)
- [Theoretical analysis of optimal policy] The section deriving the optimal self-distillation policy states that it tilts the base distribution by pointwise conditional mutual information; however, the implemented teacher-scoring procedure (conditioning on a sampled correct demonstration) is presented without an explicit check that the practical loss or gradient matches this derived optimum. If the updates deviate, the reported diversity reduction on the graph task and QA benchmarks could arise from a different source, weakening the theory-experiment link that underpins the central claim.
minor comments (2)
- The abstract and experimental description mention 'substantially lower functional and semantic diversity' but do not define the precise metrics or diversity measures used; adding these definitions would improve reproducibility.
- Figure captions or tables reporting pass@k curves should include error bars or run counts to allow assessment of the statistical reliability of the flattening effect.
Simulated Author's Rebuttal
We thank the referee for their careful reading and for identifying a potential gap in the theory-experiment linkage. We address the single major comment below.
read point-by-point responses
-
Referee: [Theoretical analysis of optimal policy] The section deriving the optimal self-distillation policy states that it tilts the base distribution by pointwise conditional mutual information; however, the implemented teacher-scoring procedure (conditioning on a sampled correct demonstration) is presented without an explicit check that the practical loss or gradient matches this derived optimum. If the updates deviate, the reported diversity reduction on the graph task and QA benchmarks could arise from a different source, weakening the theory-experiment link that underpins the central claim.
Authors: We agree that an explicit verification connecting the derived optimum to the implemented loss is not present in the current manuscript. The theoretical section shows that the optimal self-distillation policy reweights the base distribution by the pointwise conditional mutual information between the student rollout and the conditioned correct rollout. The practical procedure conditions the teacher on a sampled correct demonstration precisely to realize this reweighting via the resulting token-level scores. Nevertheless, we acknowledge that the manuscript does not contain a direct derivation or gradient-matching argument confirming that the training objective used in the graph and QA experiments is identical to the PMI-tilted optimum. In the revision we will add this verification, either as an appendix derivation showing equivalence of the gradients or as a controlled check on the graph task, to strengthen the claimed connection. revision: yes
Circularity Check
No circularity; theoretical derivation and empirical comparison are self-contained
full rationale
The paper derives the optimal self-distillation policy via pointwise conditional mutual information between student rollout and conditioned correct rollout, contrasts it explicitly with ideal RL (which preserves ratios among correct rollouts), and reports experimental outcomes on graph path-finding and QA benchmarks. No step reduces by construction to a fitted parameter, self-citation chain, or renamed input; the MI tilting is presented as an independent first-principles result rather than an ansatz or self-definition. The implementation is described as realizing the mechanism but is not asserted to be numerically identical to the derived optimum, so no load-bearing reduction occurs. This matches the reader's assessment of score 2.0 with no evidence of circular reasoning.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The optimal self-distillation policy tilts the base distribution by a pointwise conditional mutual information score between the student's rollout and the correct rollout used as context.
Reference graph
Works this paper leans on
-
[1]
2025 , howpublished =
Amirhossein Kazemnejad and Milad Aghajohari and Alessandro Sordoni and Aaron Courville and Siva Reddy , title =. 2025 , howpublished =
2025
-
[2]
Findings of the Association for Computational Linguistics: EMNLP 2022 , pages=
RL with KL penalties is better viewed as Bayesian inference , author=. Findings of the Association for Computational Linguistics: EMNLP 2022 , pages=
2022
-
[3]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in
Yang Yue and Zhiqi Chen and Rui Lu and Andrew Zhao and Zhaokai Wang and Yang Yue and Shiji Song and Gao Huang , booktitle=. Does Reinforcement Learning Really Incentivize Reasoning Capacity in. 2026 , url=
2026
-
[4]
2026 , journal =
Reinforcement Learning via Self-Distillation , author =. 2026 , journal =
2026
-
[5]
arXiv preprint arXiv:2601.18734 , year=
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models , author=. arXiv preprint arXiv:2601.18734 , year=
-
[6]
arXiv preprint arXiv:2601.19897 , year=
Self-Distillation Enables Continual Learning , author=. arXiv preprint arXiv:2601.19897 , year=
-
[7]
arXiv preprint arXiv:2602.12275 , year=
On-policy context distillation for language models , author=. arXiv preprint arXiv:2602.12275 , year=
-
[8]
arXiv preprint arXiv:2604.03128 , year=
Self-Distilled RLVR , author=. arXiv preprint arXiv:2604.03128 , year=
-
[9]
arXiv preprint arXiv:2602.04942 , year=
Privileged Information Distillation for Language Models , author=. arXiv preprint arXiv:2602.04942 , year=
-
[10]
arXiv preprint arXiv:2603.23871 , year=
HDPO: Hybrid Distillation Policy Optimization via Privileged Self-Distillation , author=. arXiv preprint arXiv:2603.23871 , year=
-
[11]
arXiv preprint arXiv:2406.09098 , year=
Sciknoweval: Evaluating multi-level scientific knowledge of large language models , author=. arXiv preprint arXiv:2406.09098 , year=
-
[12]
The twelfth international conference on learning representations , year=
On-policy distillation of language models: Learning from self-generated mistakes , author=. The twelfth international conference on learning representations , year=
-
[13]
Thinking Machines Lab: Connectionism , year =
Lu, Kevin and Thinking Machines, Lab , title =. Thinking Machines Lab: Connectionism , year =
-
[14]
arXiv preprint arXiv:1503.02531 , year=
Distilling the knowledge in a neural network , author=. arXiv preprint arXiv:1503.02531 , year=
-
[15]
Proceedings of the 12th ACM SIGKDD international conference on Knowledge discovery and data mining , pages=
Model compression , author=. Proceedings of the 12th ACM SIGKDD international conference on Knowledge discovery and data mining , pages=
-
[16]
arXiv preprint arXiv:2507.14843 , year=
The invisible leash: Why rlvr may or may not escape its origin , author=. arXiv preprint arXiv:2507.14843 , year=
-
[17]
2026 , url=
Anthony GX-Chen and Jatin Prakash and Jeff Guo and Rob Fergus and Rajesh Ranganath , booktitle=. 2026 , url=
2026
-
[18]
arXiv preprint arXiv:2210.02410 , year=
The vendi score: A diversity evaluation metric for machine learning , author=. arXiv preprint arXiv:2210.02410 , year=
-
[19]
arXiv preprint arXiv:2509.02534 , year=
Jointly reinforcing diversity and quality in language model generations , author=. arXiv preprint arXiv:2509.02534 , year=
-
[21]
Understanding the Effects of
Robert Kirk and Ishita Mediratta and Christoforos Nalmpantis and Jelena Luketina and Eric Hambro and Edward Grefenstette and Roberta Raileanu , booktitle=. Understanding the Effects of. 2024 , url=
2024
-
[22]
Understanding the effects of
Kirk, Robert and Mediratta, Ishita and Nalmpantis, Christoforos and Luketina, Jelena and Hambro, Eric and Grefenstette, Edward and Raileanu, Roberta , booktitle=. Understanding the effects of
-
[23]
The Thirteenth International Conference on Learning Representations , year=
Diverse Preference Learning for Capabilities and Alignment , author=. The Thirteenth International Conference on Learning Representations , year=
-
[24]
arXiv preprint arXiv:2501.18101 , year=
Diverse Preference Optimization , author=. arXiv preprint arXiv:2501.18101 , year=
-
[25]
Making Language Models Better Reasoners with Step-Aware Verifier
Li, Yifei and Lin, Zeqi and Zhang, Shizhuo and Fu, Qiang and Chen, Bei and Lou, Jian-Guang and Chen, Weizhu. Making Language Models Better Reasoners with Step-Aware Verifier. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.291
-
[26]
Forty-first International Conference on Machine Learning , year=
Improving factuality and reasoning in language models through multiagent debate , author=. Forty-first International Conference on Machine Learning , year=
-
[27]
arXiv preprint arXiv:2305.19118 , year=
Encouraging divergent thinking in large language models through multi-agent debate , author=. arXiv preprint arXiv:2305.19118 , year=
-
[28]
The Twelfth International Conference on Learning Representations , year=
Curiosity-driven Red-teaming for Large Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[29]
arXiv preprint arXiv:2306.09442 , year=
Explore, establish, exploit: Red teaming language models from scratch , author=. arXiv preprint arXiv:2306.09442 , year=
-
[30]
doi:10.18653/v1/2022.emnlp-main.225 , url =
Perez, Ethan and Huang, Saffron and Song, Francis and Cai, Trevor and Ring, Roman and Aslanides, John and Glaese, Amelia and McAleese, Nat and Irving, Geoffrey. Red Teaming Language Models with Language Models. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.225
-
[31]
arXiv preprint arXiv:2508.10751 , year=
Pass@ k training for adaptively balancing exploration and exploitation of large reasoning models , author=. arXiv preprint arXiv:2508.10751 , year=
-
[32]
The Thirteenth International Conference on Learning Representations , year=
Inference-Aware Fine-Tuning for Best-of-N Sampling in Large Language Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[33]
2025 , journal=
BARE: Leveraging Base Language Models for Few-Shot Synthetic Data Generation , author=. 2025 , journal=
2025
-
[34]
arXiv preprint arXiv:2502.17543 , year=
Training a generally curious agent , author=. arXiv preprint arXiv:2502.17543 , year=
-
[35]
International conference on machine learning , pages=
Curiosity-driven exploration by self-supervised prediction , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[36]
A possibility for implementing curiosity and boredom in model-building neural controllers , author=. Proc. of the international conference on simulation of adaptive behavior: From animals to animats , pages=
-
[37]
arXiv preprint arXiv:2506.18880 , year=
OMEGA: Can LLMs Reason Outside the Box in Math? Evaluating Exploratory, Compositional, and Transformative Generalization , author=. arXiv preprint arXiv:2506.18880 , year=
-
[38]
arXiv preprint arXiv:2504.05228 , year=
NoveltyBench: Evaluating Language Models for Humanlike Diversity , author=. arXiv preprint arXiv:2504.05228 , year=
-
[39]
2024 , booktitle =
Tajwar, Fahim and Singh, Anikait and Sharma, Archit and Rafailov, Rafael and Schneider, Jeff and Xie, Tengyang and Ermon, Stefano and Finn, Chelsea and Kumar, Aviral , title =. 2024 , booktitle =
2024
-
[40]
arXiv preprint arXiv:2510.18874 , year=
Retaining by doing: The role of on-policy data in mitigating forgetting , author=. arXiv preprint arXiv:2510.18874 , year=
-
[41]
arXiv preprint arXiv:2512.07783 , year=
On the interplay of pre-training, mid-training, and rl on reasoning language models , author=. arXiv preprint arXiv:2512.07783 , year=
-
[42]
arXiv preprint arXiv:2510.03264 , year=
Front-loading reasoning: The synergy between pretraining and post-training data , author=. arXiv preprint arXiv:2510.03264 , year=
-
[43]
Proceedings of the 41st International Conference on Machine Learning , pages =
The Pitfalls of Next-Token Prediction , author =. Proceedings of the 41st International Conference on Machine Learning , pages =. 2024 , editor =
2024
-
[44]
Forty-second International Conference on Machine Learning , year=
Roll the dice & look before you leap: Going beyond the creative limits of next-token prediction , author=. Forty-second International Conference on Machine Learning , year=
-
[45]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[46]
2025 , eprint=
OLMo 3 , author=. 2025 , eprint=
2025
-
[47]
2025 , note =
Google , title =. 2025 , note =
2025
-
[48]
Learning to Reason with LLMs , author =
-
[49]
arXiv preprint arXiv:2412.16720 , year=
Openai o1 system card , author=. arXiv preprint arXiv:2412.16720 , year=
-
[50]
arXiv preprint arXiv:2501.12948 , year=
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
-
[51]
arXiv preprint arXiv:2402.03300 , year=
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
-
[52]
Qwen2. 5 technical report , author=. arXiv preprint arXiv:2412.15115 , year=
-
[53]
arXiv preprint arXiv:2407.21783 , year=
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
-
[54]
arXiv preprint arXiv:2107.03374 , year=
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
-
[55]
arXiv preprint arXiv:2110.14168 , year=
Training Verifiers to Solve Math Word Problems , author=. arXiv preprint arXiv:2110.14168 , year=
-
[56]
NeurIPS , year=
Measuring Mathematical Problem Solving With the MATH Dataset , author=. NeurIPS , year=
-
[57]
Advances in Neural Information Processing Systems , volume=
Solving quantitative reasoning problems with language models , author=. Advances in Neural Information Processing Systems , volume=
-
[58]
Charlie Victor Snell and Jaehoon Lee and Kelvin Xu and Aviral Kumar , booktitle=. Scaling. 2025 , url=
2025
-
[59]
Scaling test-time compute with open models , author=
-
[60]
arXiv preprint arXiv:2502.06703 , year=
Can 1B LLM Surpass 405B LLM? Rethinking Compute-Optimal Test-Time Scaling , author=. arXiv preprint arXiv:2502.06703 , year=
-
[61]
Evaluating the Evaluation of Diversity in Natural Language Generation
Tevet, Guy and Berant, Jonathan. Evaluating the Evaluation of Diversity in Natural Language Generation. Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume. 2021. doi:10.18653/v1/2021.eacl-main.25
-
[62]
2017 , url=
Diverse Beam Search: Decoding Diverse Solutions from Neural Sequence Models , author=. 2017 , url=
2017
-
[63]
arXiv preprint arXiv:2407.21787 , year=
Large language monkeys: Scaling inference compute with repeated sampling , author=. arXiv preprint arXiv:2407.21787 , year=
-
[64]
Advances in Neural Information Processing Systems , volume=
Are more llm calls all you need? towards the scaling properties of compound ai systems , author=. Advances in Neural Information Processing Systems , volume=
-
[65]
Advances in Neural Information Processing Systems , volume=
Language models don't always say what they think: Unfaithful explanations in chain-of-thought prompting , author=. Advances in Neural Information Processing Systems , volume=
-
[66]
Reasoning Models Don’t Always Say What They Think , author=
-
[67]
The Eleventh International Conference on Learning Representations , year=
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author=. The Eleventh International Conference on Learning Representations , year=
-
[68]
British Machine Vision Conference (BMVC 2018) , year=
Mining for meaning: from vision to language through multiple networks consensus , author=. British Machine Vision Conference (BMVC 2018) , year=
2018
-
[69]
arXiv preprint arXiv:2310.01798 , year=
Large language models cannot self-correct reasoning yet , author=. arXiv preprint arXiv:2310.01798 , year=
-
[70]
The Eleventh International Conference on Learning Representations , year=
Generating Sequences by Learning to Self-Correct , author=. The Eleventh International Conference on Learning Representations , year=
-
[71]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Recursive Introspection: Teaching Language Model Agents How to Self-Improve , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[72]
arXiv preprint arXiv:2409.12917 , year=
Training language models to self-correct via reinforcement learning , author=. arXiv preprint arXiv:2409.12917 , year=
-
[73]
Science , volume=
Competition-level code generation with alphacode , author=. Science , volume=. 2022 , publisher=
2022
-
[74]
arXiv preprint arXiv:2503.01307 , year=
Cognitive behaviors that enable self-improving reasoners, or, four habits of highly effective stars , author=. arXiv preprint arXiv:2503.01307 , year=
-
[75]
arXiv preprint arXiv:2503.20783 , year=
Understanding r1-zero-like training: A critical perspective , author=. arXiv preprint arXiv:2503.20783 , year=
-
[76]
The Twelfth International Conference on Learning Representations , year=
SalUn: Empowering Machine Unlearning via Gradient-based Weight Saliency in Both Image Classification and Generation , author=. The Twelfth International Conference on Learning Representations , year=
-
[77]
out-of-distribution data in LLMs under gradient-based method , author=
Unlearning in-vs. out-of-distribution data in LLMs under gradient-based method , author=. arXiv preprint arXiv:2411.04388 , year=
-
[78]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[79]
Advances in Neural Information Processing Systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in Neural Information Processing Systems , volume=
-
[80]
Advances in Neural Information Processing Systems , volume=
Star: Bootstrapping reasoning with reasoning , author=. Advances in Neural Information Processing Systems , volume=
-
[81]
arXiv preprint arXiv:2312.06585 , year=
Beyond human data: Scaling self-training for problem-solving with language models , author=. arXiv preprint arXiv:2312.06585 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.