FP8 is All You Need (Part 2): Efficient Ozaki-Bailey Style FFT Through Tensor-core Garner Reformulation and Kulisch Escape Route
Pith reviewed 2026-06-29 05:54 UTC · model grok-4.3
The pith
Ozaki-Bailey FFT delivers FP64 accuracy on low-FP64 GPUs by using FP8 tensor cores and Kulisch reconstruction
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
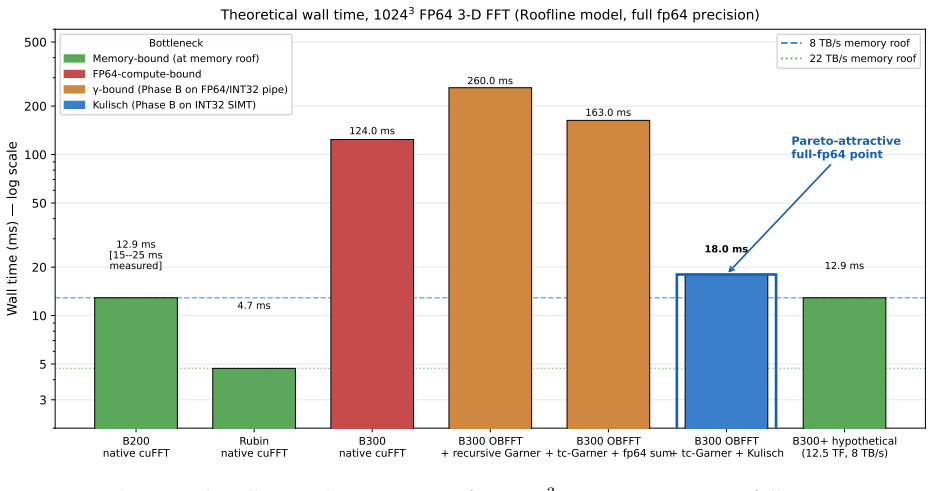
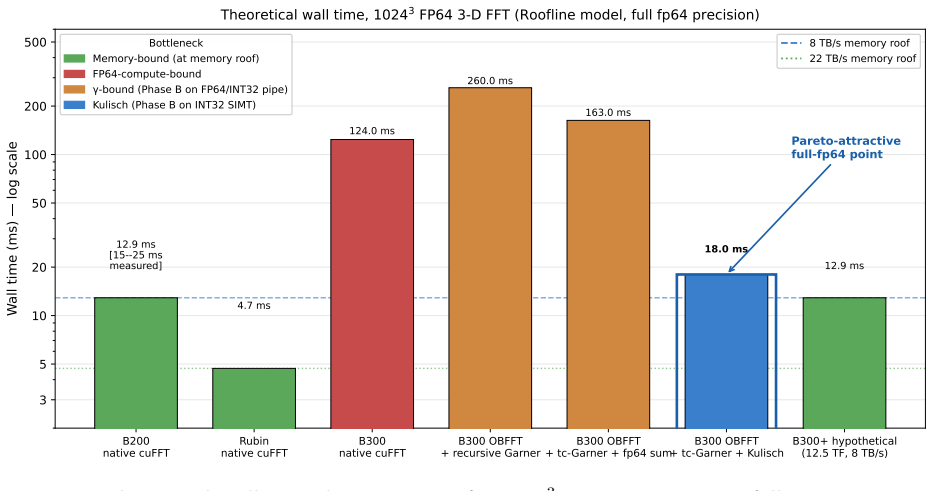
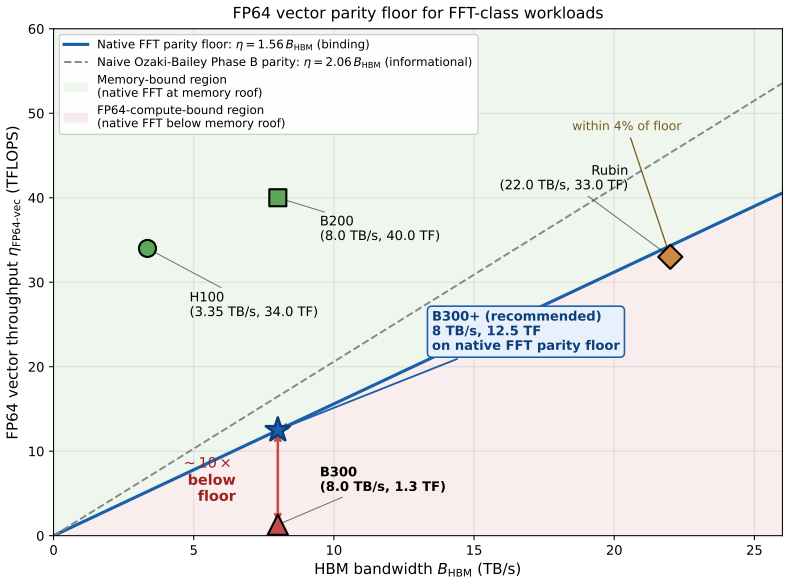
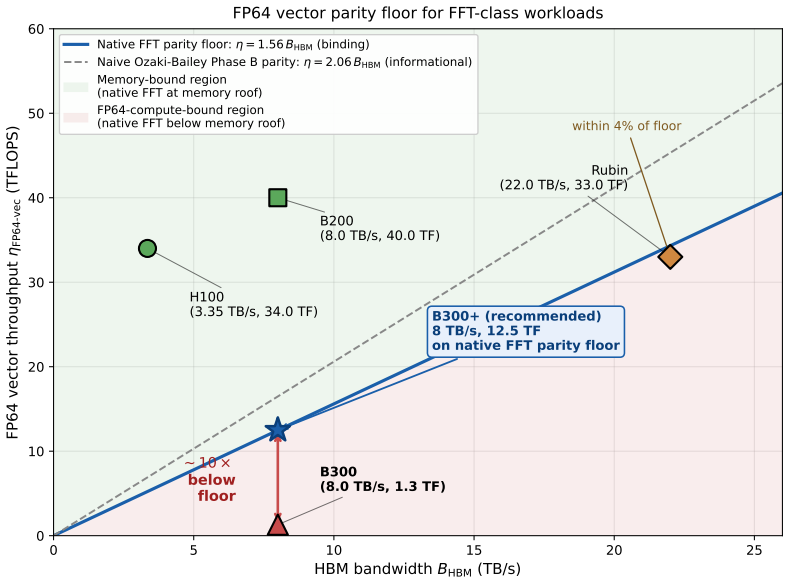
Ozaki-Bailey FFT achieves full FP64-equivalent precision for 3-D transforms by routing 1-D FFT GEMMs through FP8 tensor cores and reformulating the Garner reconstruction's Phase B reduction as Kulisch complete arithmetic on the INT32 SIMT pipe, satisfying derived bandwidth-parity floors of 8.25 times HBM bandwidth for INT32 and 170 times HBM for FP8 on B300 and projecting execution times near 18 ms for size 1024 cubed, essentially the 12.9 ms memory roof.
What carries the argument
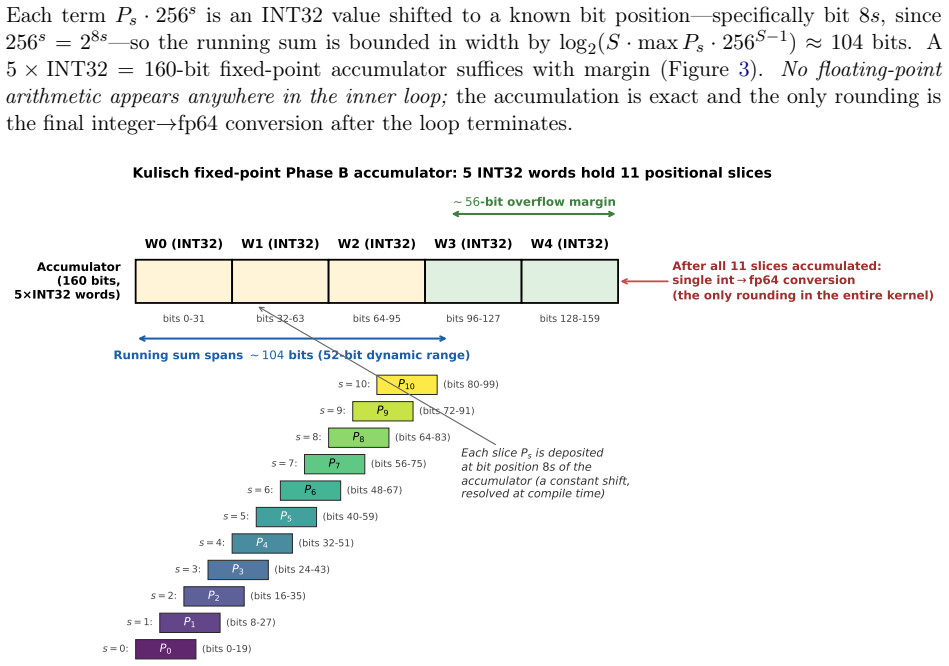
The Kulisch escape route, a reformulation of the per-output reduction phase of Garner reconstruction as fixed-point complete arithmetic that executes entirely on the INT32 SIMT pipeline while preserving full FP64 accuracy.
If this is right
- B300 hardware satisfies the INT32 sub-floor of 8.25 times HBM and the FP8 floor of 170 times HBM required by the Kulisch route.
- The native FP64 floor of 1.56 times HBM is not met by B300 but is bypassed by the escape route.
- A GPU reaches memory-roof FFT performance whenever it meets either the native floor or both Kulisch floors.
- Full-FP64 3-D FFT becomes viable through software alone on B300, motivating a libKulisch library and benchmark campaign.
Where Pith is reading between the lines
- The same Garner-to-Kulisch reformulation could be applied to other bandwidth-limited linear-algebra kernels that currently rely on high-precision matrix multiplies.
- A portable Kulisch library would allow direct testing of the method on additional FFT sizes, dimensions, and future GPU architectures.
- Empirical timing and accuracy measurements on physical B300 systems are required to confirm that the theoretical floors are reachable without hidden overheads.
Load-bearing premise
That Kulisch fixed-point arithmetic on the INT32 SIMT pipe maintains full FP64 accuracy in the FFT reconstruction without precision loss or additional overheads.
What would settle it
A working implementation of the Ozaki-Bailey FFT on B300 that either reaches approximately 18 ms for a 1024 cubed transform at verified FP64 accuracy or fails to do so.
Figures

read the original abstract
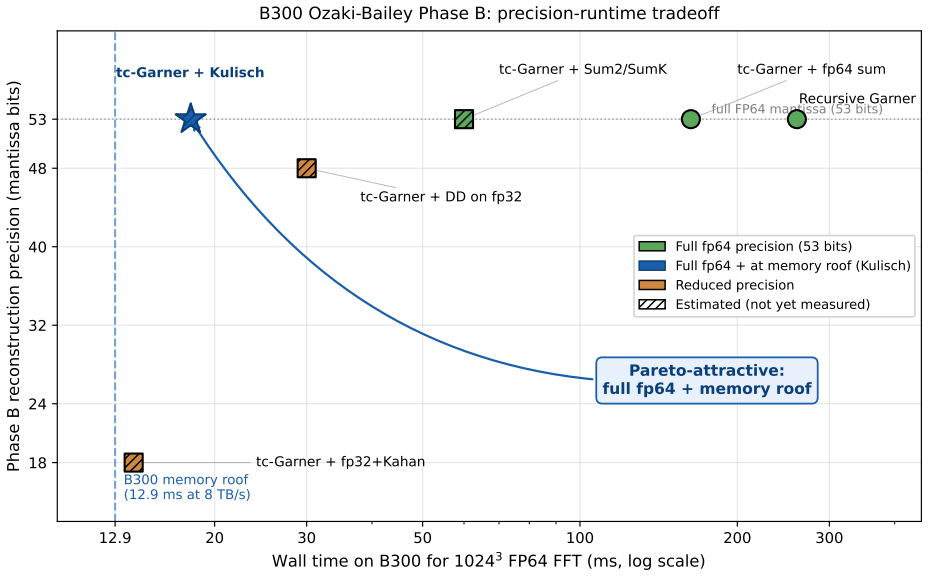
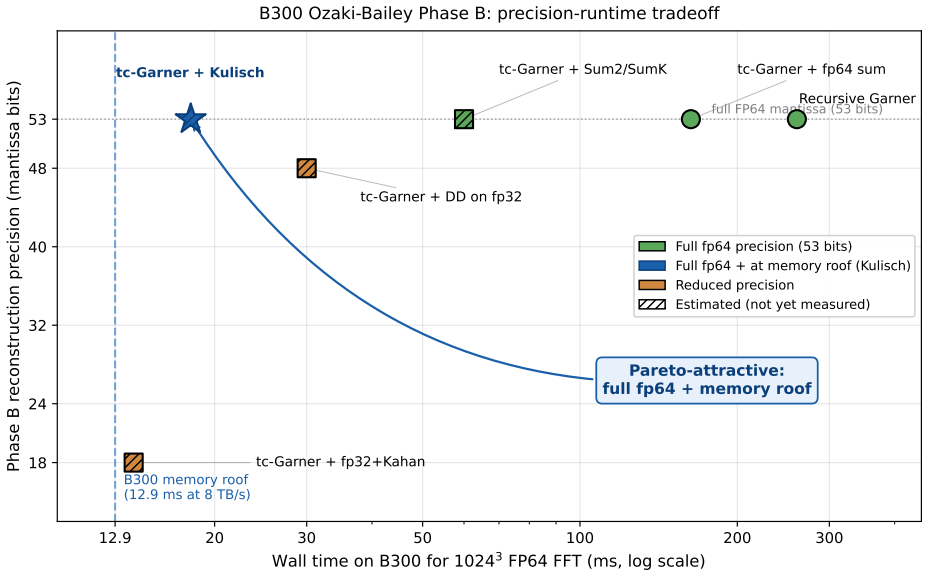
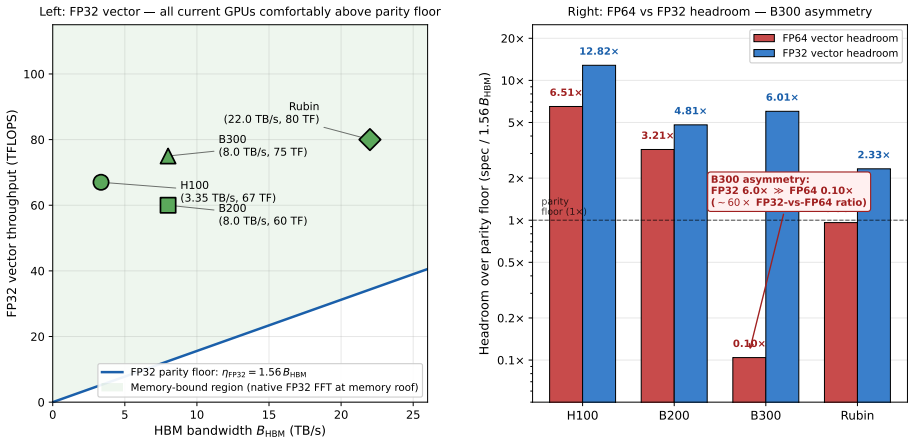
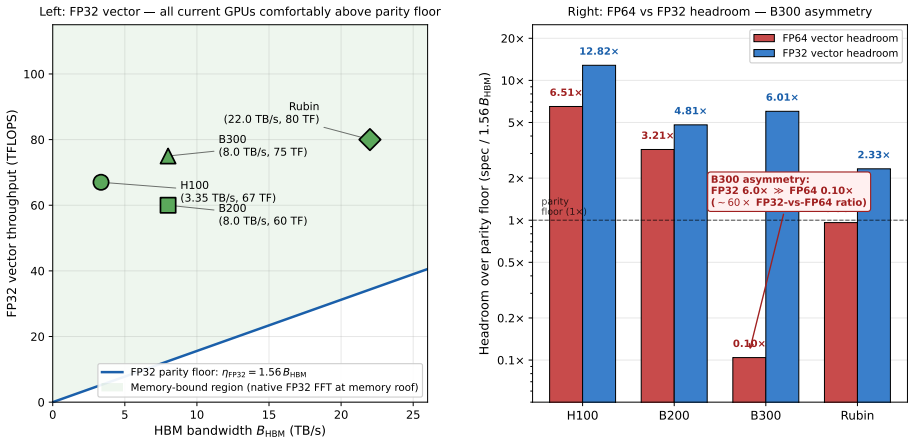
NVIDIA's Blackwell Ultra (B300) cuts FP64 vector throughput to ~1.3 TFLOPS per GPU, roughly 30x below B200 and well below the level at which bandwidth-limited FP64 workloads stay memory-bound. The Ozaki Scheme II framework recovers FP64-equivalent throughput by routing dense matrix multiply through FP8 tensor cores with a mantissa-sliced Chinese-remainder reconstruction. A companion Part (1) paper covers dense GEMM, batched GEMV, stencils, and SpMV; this paper adds the fifth canonical primitive, the 3-D FFT. We present Ozaki-Bailey FFT, an emulated 3-D FFT via the Bailey six-step decomposition with both 1-D FFT GEMMs on FP8 tensor cores. Bailey's small inner factor k ~ sqrt(N) (k=32 for N=1024) puts the kernel in the regime k << r^2, where the third TME parameter gamma (reconstruction latency) binds rather than amortising. Garner reconstruction splits into Phase A (inner products on FP8/INT8 tensor cores, ~1 ms for 1024^3 on B300) and Phase B (per-output reduction). We identify Kulisch fixed-point complete arithmetic as a Phase B reformulation that keeps full FP64 accuracy while running entirely on the INT32 SIMT pipe. We derive closed-form bandwidth-parity floors. The native FP64 floor is 1.56*B_HBM (12.5 TF at 8 TB/s): B300's 1.3 TF sits ~10x below, Rubin's 33 TF within 4%. The Kulisch escape route needs an INT32 sub-floor 8.25*B_HBM and an FP8 floor 170*B_HBM; B300 meets both. The projection is ~18 ms for 1024^3 at full FP64, essentially the 12.9 ms memory roof. A GPU meets memory-roof FFT parity if it satisfies either the native floor or both Kulisch floors. If the projection holds in practice, B300 becomes viable for full-FP64 FFT through software alone, motivating a libKulisch library and benchmark campaign.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an Ozaki-Bailey 3-D FFT that routes the Bailey six-step 1-D FFT GEMMs through FP8 tensor cores and replaces Garner Phase B reconstruction with Kulisch fixed-point accumulation on the INT32 SIMT pipe to recover full FP64 accuracy. It derives closed-form bandwidth-parity floors showing that B300 meets both the native FP64 floor (1.56×B_HBM) and the Kulisch sub-floors (8.25×B_HBM for INT32, 170×B_HBM for FP8), projecting ~18 ms runtime for a 1024³ transform, essentially the 12.9 ms memory roof.
Significance. If the derived floors prove achievable, the work supplies a parameter-free theoretical basis for evaluating when GPUs with low native FP64 throughput remain viable for bandwidth-limited FFT workloads via software emulation alone. The explicit multipliers and the observation that a GPU meets parity if it satisfies either the native or both Kulisch floors constitute a reusable framework that could guide hardware-software co-design and motivate a libKulisch implementation.
major comments (2)
- [Abstract (Kulisch Phase B reformulation)] Abstract / Kulisch escape route: the statement that the reformulation 'keeps full FP64 accuracy while running entirely on the INT32 SIMT pipe' is not accompanied by an explicit bound on the number of partial sums per output or the integer bit-width required to avoid overflow during Phase B reduction (k=32 for N=1024). Without this calculation the 8.25×B_HBM sub-floor cannot be verified as attainable on INT32 without intermediate rounding.
- [Bandwidth-parity floors section] Bandwidth-parity floors derivation: the closed-form multipliers (native 1.56×, INT32 8.25×, FP8 170×) are stated without the intermediate arithmetic or memory-access assumptions (e.g., exact traffic in the six-step decomposition) that produce them, so the claim that the ~18 ms projection equals the 12.9 ms memory roof rests on unshown steps.
minor comments (1)
- [Abstract] The abstract mentions a companion Part (1) paper but supplies no citation or arXiv identifier.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to supply the requested explicit calculations and derivations.
read point-by-point responses
-
Referee: [Abstract (Kulisch Phase B reformulation)] Abstract / Kulisch escape route: the statement that the reformulation 'keeps full FP64 accuracy while running entirely on the INT32 SIMT pipe' is not accompanied by an explicit bound on the number of partial sums per output or the integer bit-width required to avoid overflow during Phase B reduction (k=32 for N=1024). Without this calculation the 8.25×B_HBM sub-floor cannot be verified as attainable on INT32 without intermediate rounding.
Authors: We agree the abstract statement would be strengthened by an explicit bound. The manuscript identifies the Kulisch reformulation for Phase B but does not state the per-output partial-sum count or bit-width requirement in the abstract itself. We will revise the abstract to include the bound (at most k partial sums for the inner factor) together with the integer bit-width needed to guarantee no overflow on the INT32 pipe, thereby allowing verification of the sub-floor without intermediate rounding. revision: yes
-
Referee: [Bandwidth-parity floors section] Bandwidth-parity floors derivation: the closed-form multipliers (native 1.56×, INT32 8.25×, FP8 170×) are stated without the intermediate arithmetic or memory-access assumptions (e.g., exact traffic in the six-step decomposition) that produce them, so the claim that the ~18 ms projection equals the 12.9 ms memory roof rests on unshown steps.
Authors: The referee correctly notes that the closed-form multipliers are presented without the intermediate arithmetic steps or the precise memory-traffic assumptions from the six-step decomposition. The manuscript states that the expressions are derived but does not display the traffic counts or the algebraic steps leading to 1.56×, 8.25× and 170×. We will expand the Bandwidth-parity floors section to include the full derivation, the exact read/write volumes for each phase of the Bailey decomposition, and the arithmetic that yields the ~18 ms projection relative to the 12.9 ms roof. revision: yes
Circularity Check
No significant circularity; bandwidth floors and projections derived from hardware parameters and memory bounds
full rationale
The paper's central derivation computes closed-form bandwidth-parity floors (native FP64 at 1.56*B_HBM, Kulisch INT32 at 8.25*B_HBM, FP8 at 170*B_HBM) directly from stated B300 specs (1.3 TFLOPS FP64, 8 TB/s HBM) and the 1024^3 memory roof (12.9 ms), without fitting parameters, self-referential equations, or load-bearing self-citations. The Kulisch escape route is introduced as a reformulation of Garner Phase B using fixed-point properties, not as a result that reduces to prior author work by definition. The ~18 ms projection follows arithmetically from these floors and is presented as conditional on practical validation, not as a tautology. No steps match the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Chinese remainder theorem applies to mantissa-sliced reconstruction in Ozaki scheme
- domain assumption Bailey six-step decomposition reduces 3D FFT to 1D FFT GEMMs with small inner factor k
Reference graph
Works this paper leans on
-
[1]
Matsuoka
S. Matsuoka. FP8 is All You Need (Part 1): Debunking Hardware FP64 as the HPC Holy Grail—ATensor–MemoryEquilibriumModelandImplementationStrategyforOzakiSchemeII on Memory-Bound Workloads in the Post-FP64 Era.arXiv preprint, June 2026
2026
-
[2]
K. Ozaki, Y. Uchino, T. Imamura. Ozaki Scheme II: A GEMM-oriented emulation of floating- point matrix multiplication using an integer modular technique.arXiv:2504.08009, 2025
-
[3]
Double-Precision Matrix Multiplication Emulation via Ozaki-II Scheme with FP8 Quantization
Y. Uchino, K. Ozaki, T. Imamura. The FP8 variant of Ozaki Scheme II.arXiv:2603.10634, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [4]
-
[5]
Ozaki, T
K. Ozaki, T. Ogita, S. Oishi, S. M. Rump. Error-free transformations of matrix multiplication by using fast routines of matrix multiplication and its applications.Numerical Algorithms, 59(1):95–118, 2012
2012
-
[6]
D. H. Bailey. FFTs in external or hierarchical memory.Journal of Supercomputing, 4:23–35, 1990
1990
-
[7]
D. J. Bernstein. Fast multiplication and its applications. InAlgorithmic Number Theory, MSRI Publications 44, Cambridge University Press, 2008. 34
2008
-
[8]
Durrani et al
S. Durrani et al. Accelerating Fourier and number-theoretic transforms using tensor cores. Proceedings of PACT 2021, 2021
2021
-
[9]
Williams, A
S. Williams, A. Waterman, D. Patterson. Roofline: An insightful visual performance model for multicore architectures.Communications of the ACM, 52(4):65–76, 2009
2009
-
[10]
Haidar, S
A. Haidar, S. Tomov, J. Dongarra, N. J. Higham. Harnessing GPU tensor cores for fast FP16 arithmetic to speed up mixed-precision iterative refinement solvers. InSC18, pages 603–613, 2018
2018
-
[11]
T. J. Dekker. A floating-point technique for extending the available precision.Numerische Mathematik, 18:224–242, 1971
1971
-
[12]
W. Kahan. Pracniques: further remarks on reducing truncation errors.Communications of the ACM, 8(1):40, 1965
1965
-
[13]
Neumaier
A. Neumaier. Rundungsfehleranalyse einiger Verfahren zur Summation endlicher Summen. Zeitschrift für Angewandte Mathematik und Mechanik, 54:39–51, 1974
1974
-
[14]
Ogita, S
T. Ogita, S. M. Rump, S. Oishi. Accurate sum and dot product.SIAM Journal on Scientific Computing, 26(6):1955–1988, 2005
1955
-
[15]
Y. Hida, X. S. Li, D. H. Bailey. Algorithms for quad-double precision floating-point arithmetic. InProceedings 15th IEEE Symposium on Computer Arithmetic, pages 155–162, 2001
2001
-
[16]
U. W. Kulisch. Mathematical foundation of computer arithmetic.IEEE Transactions on Com- puters, C-26(7):610–621, 1977
1977
-
[17]
U. W. Kulisch, W. L. Miranker. The arithmetic of the digital computer: A new approach. SIAM Review, 28(1):1–40, 1986
1986
-
[18]
Demmel, Y
J. Demmel, Y. Hida. Fast and accurate floating-point summation with application to compu- tational geometry.Numerical Algorithms, 37(1):101–112, 2004
2004
-
[19]
Demmel, H
J. Demmel, H. D. Nguyen. Fast reproducible floating-point summation. InProceedings 21st IEEE Symposium on Computer Arithmetic, pages 163–172, 2013
2013
-
[20]
Unlocking tensor core performance with floating-point emulation in cuBLAS.NVIDIA Developer Blog, 2025
NVIDIA Corporation. Unlocking tensor core performance with floating-point emulation in cuBLAS.NVIDIA Developer Blog, 2025
2025
-
[21]
A. Schwarz et al. Guaranteed DGEMM accuracy while using reduced precision tensor cores through extensions of the Ozaki scheme.Proceedings of SCA / HPC Asia 2025; also arXiv:2511.13778
-
[22]
H. L. Garner. The residue number system.IRE Transactions on Electronic Computers, EC- 8(2):140–147, 1959
1959
-
[23]
D. E. Knuth.The Art of Computer Programming, Volume 2: Seminumerical Algorithms. Addison-Wesley, 3rd edition, 1997
1997
-
[24]
Mukunoki
D. Mukunoki. DGEMM without FP64 arithmetic: Using FP64 emulation and FP8 tensor cores with Ozaki scheme. 2025. 35
2025
-
[25]
Inside the NVIDIA Vera Rubin platform: Six new chips, one AI super- computer.NVIDIA Developer Blog, 2026
NVIDIA Corporation. Inside the NVIDIA Vera Rubin platform: Six new chips, one AI super- computer.NVIDIA Developer Blog, 2026
2026
-
[26]
G. K. Lockwood. NVIDIA Rubin: Architecture notes and performance specifications.Glenn’s Digital Garden, 2026.https://www.glennklockwood.com/garden/processors/R200
2026
-
[27]
Doudna: NERSC’s next-generation supercomputer based on NVIDIA Vera Rubin
NERSC. Doudna: NERSC’s next-generation supercomputer based on NVIDIA Vera Rubin. 2026
2026
-
[28]
S. Kawakami and D. Takahashi. Computing FFTs at target precision using lower-precision FFTs.arXiv preprint arXiv:2603.29129, March 2026.https://arxiv.org/abs/2603.29129
-
[29]
L. I. Bluestein. A linear filtering approach to the computation of discrete Fourier transform. IEEE Trans. Audio Electroacoust., 18(4):451–455, 1970
1970
-
[30]
J. M. Pollard. The fast Fourier transform in a finite field.Math. Comput., 25(114):365–374, 1971
1971
-
[31]
Frigo and S
M. Frigo and S. G. Johnson. The design and implementation of FFTW3.Proceedings of the IEEE, 93(2):216–231, 2005
2005
-
[32]
Uguen and F
Y. Uguen and F. de Dinechin. Design-space exploration for the Kulisch accumulator. Technical report, 2017.https://hal.science/hal-01488916
2017
-
[33]
Collange, D
S. Collange, D. Defour, S. Graillat, R. Iakymchuk. Numerical reproducibility for the parallel reduction on multi- and many-core architectures.Parallel Computing, 49:83–97, 2015
2015
-
[34]
the floor is set by FP64 vector throughput
S. Gueron and V. Krasnov. Parallel modular multiplication using 512-bit advanced vector instructions.Journal of Cryptographic Engineering, 11:1–12, 2021. A Derivation of the FP64 Bandwidth-Parity Formula We derive the parity formulaηopt = OI·B HBM and its FFT-specific instantiationηopt ≈1.56B HBM (native) andη opt ≈2.06B HBM (Ozaki-Bailey FFT,r= 12). Setu...
2021
-
[35]
A templated wide-accumulator primitive parameterised on output bit-width (typically 128–256 bits, packed into 4–8 INT32 words) and on the source operand format (INT8/INT16/INT32, with compile-time positional weights)
-
[36]
Warp-level shuffle primitives for carry propagation across word boundaries, optimised for 32- thread warps (Blackwell) and for the wider warps expected on the next generation
-
[37]
Drop-in replacements for the per-output reduction loops in GEMMul8 [2], cuBLAS Ozaki, SpMV libraries (cuSPARSE, PETSc), and ReproBLAS—matching the beneficiary list of Ta- ble 5
-
[38]
A benchmark harness measuring wall time and achieved INT32 throughput acrossBHBM-bound andη INT32-bound regimes, validating (37) empirically. The goal oflibKulischis to deliver an empirical answer to a single question: within the narrowed beneficiary class of §5.6, how often does Kulisch actually provide meaningful end-to- end speedup, and how often is th...
-
[39]
Kulisch requires bounded dynamic range. Reductions with truly unbounded inputs (e.g., quantum-chemistry codes with extreme condition numbers) require either application-level rescaling or adaptive-precision extensions [21]
-
[40]
Kernels already at the register-pressure limit may need to spill, degrading throughput
The wide accumulator consumes register pressure (∼5INT32 registers per output for the Ozaki-Bailey case). Kernels already at the register-pressure limit may need to spill, degrading throughput. The benchmark harness reports per-kernel register use to flag spill-prone cases
-
[41]
This is automatically detected by the benchmark harness
The achievable overlap factor (Appendix D.2) depends on the surrounding kernel’s dependency structure; algorithms with sequential reductions cannot benefit from the factor-of-2 sub-floor loosening. This is automatically detected by the benchmark harness. 45
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.