Implicit Neural Representations of Individual Behavior
Pith reviewed 2026-06-27 10:25 UTC · model grok-4.3
The pith
Behavioral INR identifies individual policies from unlabeled episodes by representing each as a state-to-action function modulated by a latent code.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
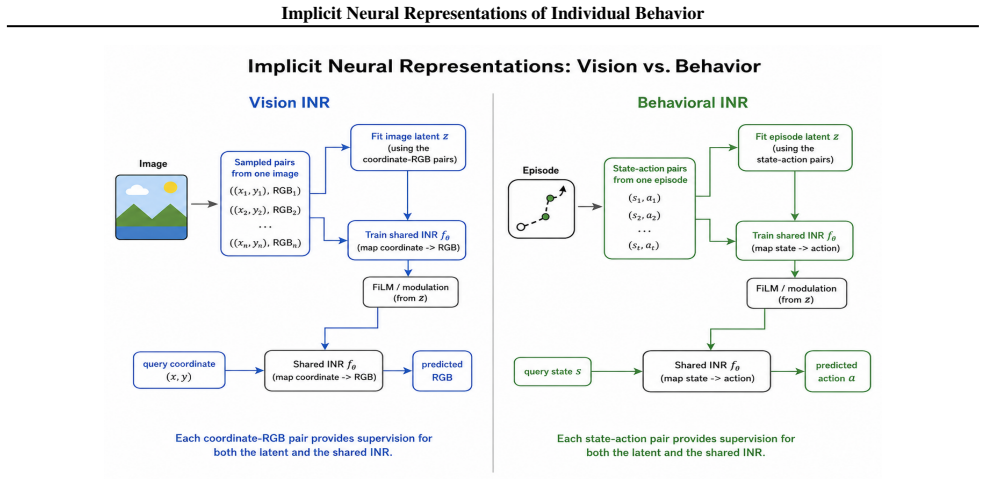
Behavioral INR is a generative model in which each policy is represented as an implicit function from states to actions; an episode-specific latent vector modulates the function parameters through FiLM conditioning layers, yielding a prior over policies that permits self-supervised recovery of policy identity from unlabeled multi-policy data.
What carries the argument
Behavioral INR: a state-action implicit neural representation modulated by an episode-level latent code through FiLM layers.
If this is right
- Policy identity becomes recoverable in unlabeled datasets with longer episodes and larger numbers of policies where standard marginal statistics fail.
- The same model accommodates variable episode lengths and sampling rates without architectural changes.
- Policy-level OOD evaluation can be performed along separate state-distribution and action-distribution axes.
- Amortized encoders remain useful only when policy identity is already recoverable from symbolic repetition or low-dimensional action statistics.
Where Pith is reading between the lines
- The learned episode latents could serve as compact descriptors for clustering or retrieval in large unlabeled behavior archives.
- The state-action function view might allow direct transfer of policies across environments that share similar dynamics but differ in observation spaces.
- Scaling the approach to high-dimensional visual observations would test whether the INR formulation still separates policies when states are image-based rather than low-dimensional vectors.
Load-bearing premise
An episode-level latent code modulated through FiLM layers can reliably capture and separate policy identity in a self-supervised manner from mixed unlabeled data without relying on marginal statistics or repetition patterns.
What would settle it
If policy identifiability metrics on the MuJoCo OOD splits with continuous states and actions show no consistent improvement over amortized history encoders and other baselines, the claim that Behavioral INR improves identification in the hardest settings would be falsified.
Figures




read the original abstract
We study policy representation learning from unlabeled multi-policy behavioral data. Each episode is generated by a fixed policy, but policy labels are unavailable. This setting appears in robotics play, demonstrations, games, racing, and other datasets where heterogeneous behaviors are mixed without annotations. We introduce \emph{Behavioral INR}, a self-supervised generative model that adapts implicit neural representations (INRs) from vision to behavior. Instead of mapping coordinates to RGB values, Behavioral INR represents a policy as a state-action function mapping states to subsequent actions. An episode-level latent modulates this function through FiLM layers, yielding a generative prior over policies and allowing policy identity to be inferred without supervision. Because INRs treat each datapoint as samples from an underlying function, the same model naturally accommodates variable episode lengths and different sampling granularities, as in vision INRs with different image resolutions. We also define policy-level out-of-distribution (OOD) shifts along state-distribution and action-distribution axes, which arise when policies overlap in states or actions but are not captured by standard behavioral OOD settings based only on new agents or environments. We evaluate on synthetic Gaussian random field data, MuJoCo demonstrations with controlled OOD splits, and real-world chess, Formula 1 racing, robotics, and Seek-Avoid datasets. Behavioral INR most consistently improves policy identifiability in the hardest continuous state-action settings, especially when longer episodes, more policies, and OOD splits reduce the usefulness of marginal shortcuts; amortized history encoders remain competitive when policy identity can be recovered from symbolic repetition or low-dimensional action statistics. We release code and checkpoints.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Behavioral INR, a self-supervised generative model adapting implicit neural representations to behavior by representing each policy as a state-to-action mapping modulated by an episode-level latent code through FiLM layers. This yields a prior over policies that enables inference of policy identity from unlabeled mixed data. The work defines policy-level OOD shifts along state and action distribution axes and evaluates identifiability on synthetic Gaussian random field data, MuJoCo with controlled splits, and real datasets from chess, Formula 1, robotics, and Seek-Avoid. The central empirical claim is that Behavioral INR most consistently improves policy identifiability in the hardest continuous state-action regimes, particularly when longer episodes, more policies, and OOD splits disable marginal or repetition-based shortcuts; amortized history encoders remain competitive in symbolic or low-dimensional cases. Code and checkpoints are released.
Significance. If the reported gains in identifiability hold under the stated OOD conditions, the approach supplies a flexible generative prior over policies that naturally accommodates variable episode lengths and sampling rates, which is a practical advantage over fixed-length or history-encoder baselines in robotics, games, and demonstration datasets. The explicit handling of policy-level OOD (distinct from standard agent/environment shifts) and the release of code/checkpoints are concrete strengths that support reproducibility and further testing.
minor comments (3)
- [Abstract] Abstract: the claim that Behavioral INR 'most consistently improves' identifiability would be strengthened by a brief statement of the quantitative metric (e.g., mutual information, clustering accuracy) and whether error bars or statistical tests accompany the cross-dataset comparison.
- [Abstract] The definition of policy-level OOD shifts is introduced but the precise construction of the state-distribution and action-distribution axes (e.g., how overlap is quantified or how splits are generated) is not summarized; a short clarifying sentence would aid readers.
- Notation: the manuscript uses 'INR' both for the general technique and for the proposed model; a brief distinction between the vision INR baseline and Behavioral INR would reduce potential confusion in early sections.
Simulated Author's Rebuttal
We thank the referee for their positive summary of the manuscript, recognition of its contributions to policy representation learning, and recommendation for minor revision. No major comments were raised in the report.
Circularity Check
No significant circularity detected
full rationale
The paper introduces Behavioral INR as an architectural modeling choice (episode-level latent modulated via FiLM in an INR-style state-action mapper) and reports empirical improvements on identifiability metrics across datasets. No derivation chain, first-principles prediction, or uniqueness theorem is claimed that reduces by construction to fitted parameters, self-citations, or renamed inputs. The central claim rests on explicit modeling decisions and standard self-supervised training, with no load-bearing steps matching the enumerated circularity patterns. Self-citations, if present, are not invoked to justify uniqueness or forbid alternatives.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption INRs originally developed for vision can be directly repurposed for state-action policy functions with FiLM modulation to enable self-supervised inference
Reference graph
Works this paper leans on
-
[1]
International conference on machine learning , pages=
Learning policy representations in multiagent systems , author=. International conference on machine learning , pages=. 2018 , organization=
2018
-
[2]
Proceedings of the 2023 International Conference on Autonomous Agents and Multiagent Systems , pages=
M3: Modularization for Multi-task and Multi-agent Offline Pre-training , author=. Proceedings of the 2023 International Conference on Autonomous Agents and Multiagent Systems , pages=
2023
-
[3]
Machine Intelligence Research , volume=
Offline pre-trained multi-agent decision transformer , author=. Machine Intelligence Research , volume=. 2023 , publisher=
2023
-
[4]
arXiv preprint arXiv:2302.00521 , year=
Off-the-grid marl: Datasets with baselines for offline multi-agent reinforcement learning , author=. arXiv preprint arXiv:2302.00521 , year=
-
[5]
Advances in Neural Information Processing Systems , volume=
Oasis: Conditional distribution shaping for offline safe reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[6]
arXiv preprint arXiv:2507.05244 , year=
Modeling Latent Partner Strategies for Adaptive Zero-Shot Human-Agent Collaboration , author=. arXiv preprint arXiv:2507.05244 , year=
-
[7]
ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Competitive multi-agent reinforcement learning with self-supervised representation , author=. ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2022 , organization=
2022
-
[8]
arXiv preprint arXiv:2401.11257 , year=
Measuring Policy Distance for Multi-Agent Reinforcement Learning , author=. arXiv preprint arXiv:2401.11257 , year=
-
[9]
The Eleventh International Conference on Learning Representations , year=
Discovering generalizable multi-agent coordination skills from multi-task offline data , author=. The Eleventh International Conference on Learning Representations , year=
-
[10]
Advances in Neural Information Processing Systems , volume=
Mimicking to dominate: Imitation learning strategies for success in multiagent games , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
arXiv preprint arXiv:2001.03415 , year=
Multi-agent interactions modeling with correlated policies , author=. arXiv preprint arXiv:2001.03415 , year=
arXiv 2001
-
[12]
IEEE Transactions on Emerging Topics in Computational Intelligence , year=
Contrastive learning-based agent modeling for deep reinforcement learning , author=. IEEE Transactions on Emerging Topics in Computational Intelligence , year=
-
[13]
Advances in Neural Information Processing Systems , volume=
Learning agent representations for ice hockey , author=. Advances in Neural Information Processing Systems , volume=
-
[14]
arXiv preprint arXiv:2102.03291 , year=
baller2vec: A multi-entity transformer for multi-agent spatiotemporal modeling , author=. arXiv preprint arXiv:2102.03291 , year=
-
[15]
arXiv preprint arXiv:2204.02877 , year=
Pandr: Fast adaptation to new environments from offline experiences via decoupling policy and environment representations , author=. arXiv preprint arXiv:2204.02877 , year=
-
[16]
Conference on robot learning , pages=
Learning latent representations to influence multi-agent interaction , author=. Conference on robot learning , pages=. 2021 , organization=
2021
-
[17]
arXiv preprint arXiv:2111.09189 , year=
Tom2c: Target-oriented multi-agent communication and cooperation with theory of mind , author=. arXiv preprint arXiv:2111.09189 , year=
-
[18]
Conference on robot learning , pages=
Dart: Noise injection for robust imitation learning , author=. Conference on robot learning , pages=. 2017 , organization=
2017
-
[19]
Proceedings of the fourteenth international conference on artificial intelligence and statistics , pages=
A reduction of imitation learning and structured prediction to no-regret online learning , author=. Proceedings of the fourteenth international conference on artificial intelligence and statistics , pages=. 2011 , organization=
2011
-
[20]
Advances in neural information processing systems , volume=
Distributionally robust imitation learning , author=. Advances in neural information processing systems , volume=
-
[21]
Advances in neural information processing systems , volume=
Generative adversarial imitation learning , author=. Advances in neural information processing systems , volume=
-
[22]
International Conference on Machine Learning , pages=
Imitation learning from imperfect demonstration , author=. International Conference on Machine Learning , pages=. 2019 , organization=
2019
-
[23]
International conference on machine learning , pages=
Wilds: A benchmark of in-the-wild distribution shifts , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[24]
arXiv preprint arXiv:1903.12261 , year=
Benchmarking neural network robustness to common corruptions and perturbations , author=. arXiv preprint arXiv:1903.12261 , year=
Pith/arXiv arXiv 1903
-
[25]
arXiv preprint arXiv:1911.08731 , year=
Distributionally robust neural networks for group shifts: On the importance of regularization for worst-case generalization , author=. arXiv preprint arXiv:1911.08731 , year=
Pith/arXiv arXiv 1911
-
[26]
arXiv preprint arXiv:1907.02893 , year=
Invariant risk minimization , author=. arXiv preprint arXiv:1907.02893 , year=
Pith/arXiv arXiv 1907
-
[27]
Journal of machine learning research , volume=
Domain-adversarial training of neural networks , author=. Journal of machine learning research , volume=
-
[28]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
SHIFT: a synthetic driving dataset for continuous multi-task domain adaptation , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[29]
Advances in Neural Information Processing Systems , volume=
Libero: Benchmarking knowledge transfer for lifelong robot learning , author=. Advances in Neural Information Processing Systems , volume=
-
[30]
Proceedings of The 7th Conference on Robot Learning , pages =
BridgeData V2: A Dataset for Robot Learning at Scale , author =. Proceedings of The 7th Conference on Robot Learning , pages =. 2023 , editor =
2023
-
[31]
Proceedings of the 5th Conference on Robot Learning , pages =
BC-Z: Zero-Shot Task Generalization with Robotic Imitation Learning , author =. Proceedings of the 5th Conference on Robot Learning , pages =. 2022 , editor =
2022
-
[32]
Conference on Robot Learning , pages=
Plas: Latent action space for offline reinforcement learning , author=. Conference on Robot Learning , pages=. 2021 , organization=
2021
-
[33]
International conference on machine learning , pages=
Off-policy deep reinforcement learning without exploration , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[34]
O’Neill, Abby and Rehman, Abdul and Maddukuri, Abhiram and Gupta, Abhishek and Padalkar, Abhishek and Lee, Abraham and Pooley, Acorn and Gupta, Agrim and Mandlekar, Ajay and Jain, Ajinkya and Tung, Albert and Bewley, Alex and Herzog, Alex and Irpan, Alex and Khazatsky, Alexander and Rai, Anant and Gupta, Anchit and Wang, Andrew and Singh, Anikait and Garg...
-
[35]
CALVIN: A Benchmark for Language-Conditioned Policy Learning for Long-Horizon Robot Manipulation Tasks , year=
Mees, Oier and Hermann, Lukas and Rosete-Beas, Erick and Burgard, Wolfram , journal=. CALVIN: A Benchmark for Language-Conditioned Policy Learning for Long-Horizon Robot Manipulation Tasks , year=
-
[36]
CVPR 2011 , pages=
Unbiased look at dataset bias , author=. CVPR 2011 , pages=. 2011 , organization=
2011
-
[37]
Geirhos, Robert and Jacobsen, Jörn-Henrik and Michaelis, Claudio and Zemel, Richard and Brendel, Wieland and Bethge, Matthias and Wichmann, Felix A. , year=. Shortcut learning in deep neural networks , volume=. Nature Machine Intelligence , publisher=. doi:10.1038/s42256-020-00257-z , number=
-
[38]
2020 , eprint=
Underspecification Presents Challenges for Credibility in Modern Machine Learning , author=. 2020 , eprint=
2020
-
[39]
International conference on machine learning , pages=
Leveraging procedural generation to benchmark reinforcement learning , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[40]
2017 IEEE/RSJ international conference on intelligent robots and systems (IROS) , pages=
Domain randomization for transferring deep neural networks from simulation to the real world , author=. 2017 IEEE/RSJ international conference on intelligent robots and systems (IROS) , pages=. 2017 , organization=
2017
-
[41]
Advances in Neural Information Processing Systems , volume=
Ess-InfoGAIL: Semi-supervised imitation learning from imbalanced demonstrations , author=. Advances in Neural Information Processing Systems , volume=
-
[42]
International Conference on Machine Learning , pages=
Discriminator-weighted offline imitation learning from suboptimal demonstrations , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[43]
arXiv preprint arXiv:2508.06319 , year=
Towards balanced behavior cloning from imbalanced datasets , author=. arXiv preprint arXiv:2508.06319 , year=
-
[44]
IEEE Robotics and Automation Letters , volume=
Towards target-driven visual navigation in indoor scenes via generative imitation learning , author=. IEEE Robotics and Automation Letters , volume=. 2020 , publisher=
2020
-
[45]
2022 , eprint=
ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness , author=. 2022 , eprint=
2022
-
[46]
2022 , eprint=
Deduplicating Training Data Makes Language Models Better , author=. 2022 , eprint=
2022
-
[47]
2020 , eprint=
A Simple Framework for Contrastive Learning of Visual Representations , author=. 2020 , eprint=
2020
-
[48]
International conference on machine learning , pages=
On the spectral bias of neural networks , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[49]
International Conference on Machine Learning , pages=
Just train twice: Improving group robustness without training group information , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[50]
Advances in Neural Information Processing Systems , volume=
Towards last-layer retraining for group robustness with fewer annotations , author=. Advances in Neural Information Processing Systems , volume=
-
[51]
Advances in Neural Information Processing Systems , volume=
Neural MMO 2.0: a massively multi-task addition to massively multi-agent learning , author=. Advances in Neural Information Processing Systems , volume=
-
[52]
Proceedings of the AAAI conference on artificial intelligence , volume=
Generative attention networks for multi-agent behavioral modeling , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[53]
International Conference on Neural Information Processing , pages=
Investigating partner diversification methods in cooperative multi-agent deep reinforcement learning , author=. International Conference on Neural Information Processing , pages=. 2020 , organization=
2020
-
[54]
arXiv preprint arXiv:2409.11676 , year=
Hypergraph-based motion generation with multi-modal interaction relational reasoning , author=. arXiv preprint arXiv:2409.11676 , year=
-
[55]
Joint European Conference on Machine Learning and Knowledge Discovery in Databases , pages=
Multi-agent imitation learning with copulas , author=. Joint European Conference on Machine Learning and Knowledge Discovery in Databases , pages=. 2021 , organization=
2021
-
[56]
Neural Networks , volume=
Decentralized policy learning with partial observation and mechanical constraints for multiperson modeling , author=. Neural Networks , volume=. 2024 , publisher=
2024
-
[57]
2021 , eprint=
TiKick: Towards Playing Multi-agent Football Full Games from Single-agent Demonstrations , author=. 2021 , eprint=
2021
-
[58]
2020 , eprint=
On the Utility of Learning about Humans for Human-AI Coordination , author=. 2020 , eprint=
2020
-
[59]
Proceedings of the 20th International Conference on Autonomous Agents and MultiAgent Systems , pages=
Hoad: The hanabi open agent dataset , author=. Proceedings of the 20th International Conference on Autonomous Agents and MultiAgent Systems , pages=
-
[60]
SC2EGSet: StarCraft II Esport Replay and Game-state Dataset , journal =
Bia. SC2EGSet: StarCraft II Esport Replay and Game-state Dataset , journal =. 2023 , month =. doi:10.1038/s41597-023-02510-7 , url =
-
[61]
Advances in Neural Information Processing Systems , volume=
Dispelling the mirage of progress in offline marl through standardised baselines and evaluation , author=. Advances in Neural Information Processing Systems , volume=
-
[62]
arXiv preprint arXiv:1803.07612 , volume=
Generative multi-agent behavioral cloning , author=. arXiv preprint arXiv:1803.07612 , volume=
-
[63]
Advances in neural information processing systems , volume=
Multi-agent generative adversarial imitation learning , author=. Advances in neural information processing systems , volume=
-
[64]
2019 , eprint=
Observational Overfitting in Reinforcement Learning , author=. 2019 , eprint=
2019
-
[65]
2023 , eprint=
Goal Misgeneralization in Deep Reinforcement Learning , author=. 2023 , eprint=
2023
-
[66]
2025 , eprint=
MADiff: Offline Multi-agent Learning with Diffusion Models , author=. 2025 , eprint=
2025
-
[67]
2019 , eprint=
The StarCraft Multi-Agent Challenge , author=. 2019 , eprint=
2019
-
[68]
Conference on robot learning , pages=
Learning latent plans from play , author=. Conference on robot learning , pages=. 2020 , organization=
2020
-
[69]
2020 , eprint=
Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments , author=. 2020 , eprint=
2020
-
[70]
arXiv preprint arXiv:2007.01434 , year=
In search of lost domain generalization , author=. arXiv preprint arXiv:2007.01434 , year=
arXiv 2007
-
[71]
arXiv preprint arXiv:2011.10024 , year=
Parrot: Data-driven behavioral priors for reinforcement learning , author=. arXiv preprint arXiv:2011.10024 , year=
arXiv 2011
-
[72]
arXiv preprint arXiv:2304.03456 , year=
Rethinking evaluation protocols of visual representations learned via self-supervised learning , author=. arXiv preprint arXiv:2304.03456 , year=
-
[73]
International Journal of Computer Vision , pages=
A closer look at benchmarking self-supervised pre-training with image classification , author=. International Journal of Computer Vision , pages=. 2025 , publisher=
2025
-
[74]
International Conference on Machine Learning , pages=
Hierarchical imitation learning with vector quantized models , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[75]
and Perez-Vicente, Rodrigo and Balis, John U
Younis, Omar G. and Perez-Vicente, Rodrigo and Balis, John U. and Dudley, Will and Davey, Alex and Terry, Jordan K , doi =. Minari , url =
-
[76]
Advances in neural information processing systems , volume=
Implicit neural representations with periodic activation functions , author=. Advances in neural information processing systems , volume=
-
[77]
Advances in neural information processing systems , volume=
Fourier features let networks learn high frequency functions in low dimensional domains , author=. Advances in neural information processing systems , volume=
-
[78]
Communications of the ACM , volume=
Nerf: Representing scenes as neural radiance fields for view synthesis , author=. Communications of the ACM , volume=. 2021 , publisher=
2021
-
[79]
Proceedings of the AAAI conference on artificial intelligence , volume=
Film: Visual reasoning with a general conditioning layer , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[80]
arXiv preprint arXiv:1609.09106 , year=
Hypernetworks , author=. arXiv preprint arXiv:1609.09106 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.