MoECodec: Image Compression for joint human and machine perception via Mixture-of-Experts
Pith reviewed 2026-06-26 13:09 UTC · model grok-4.3
The pith
MoECodec replaces FFN layers with token-wise mixture-of-experts to enable dynamic computation in a single image codec for both human viewing and machine tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MoECodec replaces the FFN layers in transformer-based compression model with token-wise Mixture-of-Experts, enabling dynamic, token-level computation conditioned on the input content and task objective. A stable routing strategy combines expert-choice routing with spatial total variation regularization to encourage spatially coherent assignments, and a lightweight Group Shuffle MLP controls parameter growth. Extensive experiments show consistent improvement against baselines on both conventional image reconstruction and machine tasks.
What carries the argument
Token-wise Mixture-of-Experts replacing FFN layers, driven by expert-choice routing plus spatial total variation regularization and implemented with Group Shuffle MLP experts.
If this is right
- A single set of parameters serves both human reconstruction and multiple machine vision tasks without task-specific retraining.
- Computation cost varies per token according to local semantic complexity rather than remaining uniform across the image.
- Spatially coherent expert assignments prevent visible artifacts that would otherwise appear from independent token routing.
- Parameter growth stays modest because the Group Shuffle MLP replaces full expert networks.
Where Pith is reading between the lines
- The same token-level routing could be tested on video codecs where temporal consistency might replace or augment the spatial regularizer.
- If the experts learn distinct frequency or semantic specializations, the model might allow selective decoding of only the experts needed for a given downstream task.
- Deployment on edge devices could benefit from the dynamic compute pattern, as simple regions would use fewer experts at inference time.
Load-bearing premise
A stable routing strategy that combines expert-choice routing with spatial total variation regularization will keep token-wise MoE effective inside a compression model without harming rate-distortion performance or introducing spatial artifacts.
What would settle it
If disabling the spatial total variation term produces visible block artifacts or worse rate-distortion curves on Kodak or CLIC test sets while keeping the same expert count, the routing approach fails to stabilize the model.
Figures
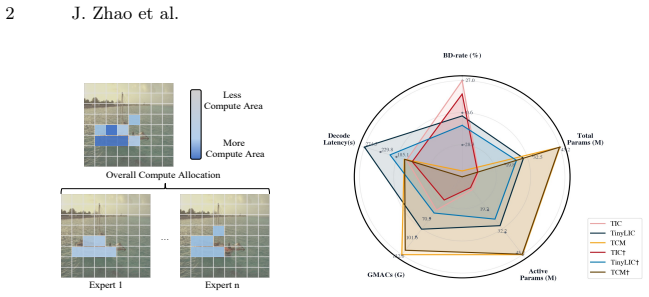
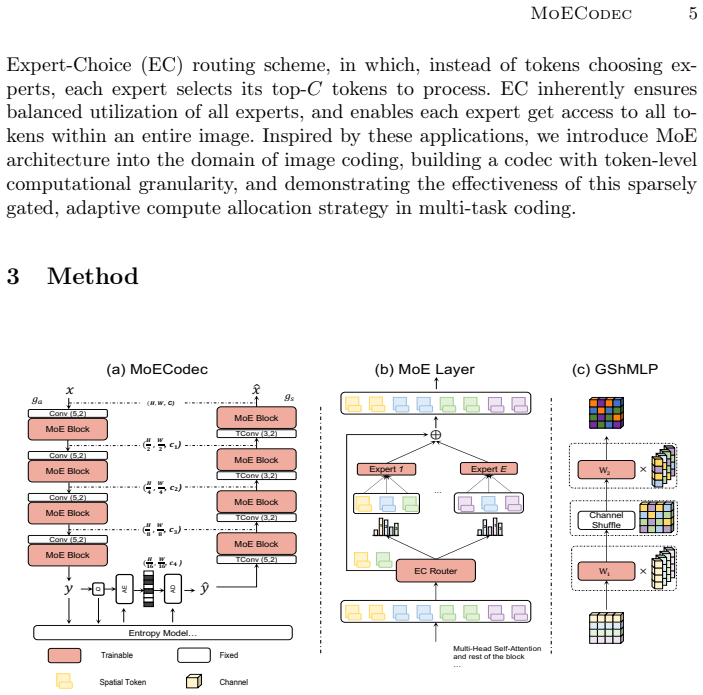
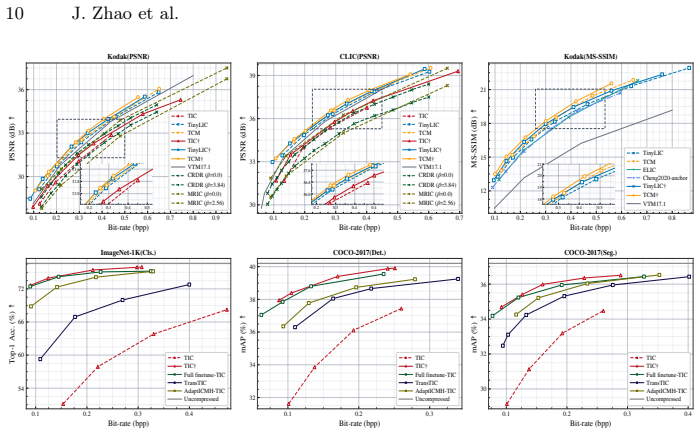

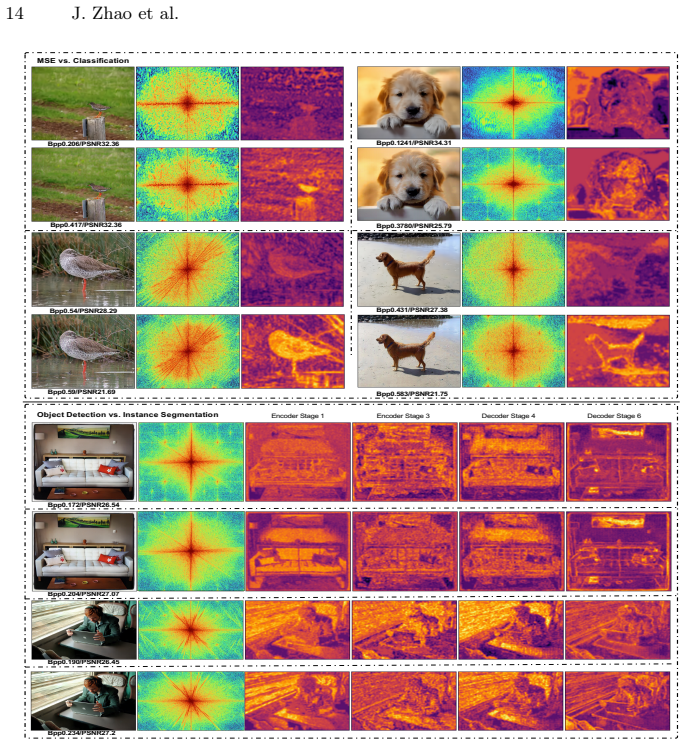
read the original abstract
Image compression for machines calls for a unified codec that serves multiple downstream vision tasks. Existing approaches either adopt task-specific end-to-end designs, raising parameter and deployment overhead, or rely on transfer-based adaptations that remain externally attached and heuristic task design. A key limitation shared by both lines of work is their largely static computation pattern, which applies similar transformations across tokens despite the fact that different image regions exhibit markedly different semantic importance and complexity for machine perception. We propose MoECodec, a token-aware image compression framework that supports multiple downstream tasks within a single model. MoECodec replaces the FFN layers in transformer-based compression model token-wise Mixture-of-Experts (MoE), enabling dynamic, token-level computation conditioned on the input content and task objective. To make MoE effective in compression model, we introduce a stable routing strategy that combines expert-choice routing with spatial total variation regularization to encourage spatially coherent assignments, and we propose a lightweight expert architecture, Group Shuffle MLP (GShMLP), to control parameter growth. Extensive experiments show consistent improvement against baselines on both conventional image reconstruction and machine tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MoECodec, a token-aware image compression framework for joint human and machine perception. It replaces the FFN layers in a transformer-based codec with token-wise Mixture-of-Experts (MoE) using expert-choice routing combined with spatial total variation regularization, plus a lightweight Group Shuffle MLP (GShMLP) expert, to enable dynamic per-token computation conditioned on content and task. The abstract states that extensive experiments demonstrate consistent gains on both reconstruction and machine tasks relative to baselines.
Significance. If the experimental claims hold, the work is significant because it directly targets the static computation limitation of prior codecs by introducing content- and task-adaptive token-level routing inside the compression model itself, rather than relying on task-specific designs or post-hoc adaptations. The combination of expert-choice routing, spatial coherence regularization, and parameter-efficient experts offers a principled way to scale multi-task codecs without proportional parameter growth, which could influence future unified codecs for diverse vision pipelines.
major comments (2)
- [Abstract] Abstract: the central claim of 'consistent improvement' and 'extensive experiments' is presented without any quantitative results, baseline names, dataset identifiers, or ablation tables. Because the soundness of the routing strategy and GShMLP expert rests entirely on these unreported numbers, the load-bearing experimental validation cannot be assessed from the provided material.
- [Method] Method (routing strategy): the paper asserts that expert-choice routing plus spatial TV regularization yields stable assignments without rate-distortion loss or spatial artifacts, yet no equation, hyper-parameter schedule, or ablation isolating the TV term is referenced. This is load-bearing for the claim that MoE can be made effective inside a compression model.
minor comments (1)
- [Abstract] Abstract: specify the exact machine tasks (e.g., classification, detection, segmentation) and the datasets used so readers can immediately gauge the scope of the multi-task evaluation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for more concrete experimental support in the abstract and clearer methodological references. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of 'consistent improvement' and 'extensive experiments' is presented without any quantitative results, baseline names, dataset identifiers, or ablation tables. Because the soundness of the routing strategy and GShMLP expert rests entirely on these unreported numbers, the load-bearing experimental validation cannot be assessed from the provided material.
Authors: We agree that the abstract would be strengthened by including specific quantitative support. In the revised version, we will add key results such as average BD-rate savings on the Kodak dataset for reconstruction and mAP gains on COCO for object detection, along with baseline names (VTM, Cheng2020) and a reference to the ablation studies. This keeps the abstract concise while making the claims verifiable. revision: yes
-
Referee: [Method] Method (routing strategy): the paper asserts that expert-choice routing plus spatial TV regularization yields stable assignments without rate-distortion loss or spatial artifacts, yet no equation, hyper-parameter schedule, or ablation isolating the TV term is referenced. This is load-bearing for the claim that MoE can be made effective inside a compression model.
Authors: The method section (3.2) formulates expert-choice routing and the spatial TV regularization term with accompanying equations, and the implementation details specify the hyper-parameter schedule for the TV coefficient. The ablation isolating the TV term (showing stable routing without RD penalty or artifacts) appears in Table 4. We will add explicit forward references to these equations and the table in the method overview to improve clarity. revision: partial
Circularity Check
No significant circularity
full rationale
The paper presents MoECodec as a new architectural proposal: replacing FFN layers in a transformer compression backbone with token-wise MoE, stabilized by expert-choice routing plus spatial TV regularization, and using a lightweight GShMLP expert. No equations, fitted parameters, or self-citation chains are shown that would reduce the claimed rate-distortion or task gains to a definition or input by construction. The central claims rest on the design choices and reported experiments rather than any load-bearing self-referential step, rendering the derivation self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: MoECodec15 Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition
Abati, D., Tomczak, J., Blankevoort, T., Calderara, S., Cucchiara, R., Bejnordi, B.E.: Conditional channel gated networks for task-aware continual learning. In: MoECodec15 Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 3931–3940 (2020) 4
2020
-
[2]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Agustsson,E.,Minnen,D.,Toderici,G.,Mentzer,F.:Multi-realismimagecompres- sion with a conditional generator. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 22324–22333 (2023) 1, 4
2023
- [3]
-
[4]
eDiff-I: Text-to-Image Diffusion Models with an Ensemble of Expert Denoisers
Balaji, Y., Nah, S., Huang, X., Vahdat, A., Song, J., Zhang, Q., Kreis, K., Ait- tala, M., Aila, T., Laine, S., et al.: ediff-i: Text-to-image diffusion models with an ensemble of expert denoisers. arXiv preprint arXiv:2211.01324 (2022) 4
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [5]
-
[6]
Ballé, J., Minnen, D., Singh, S., Hwang, S.J., Johnston, N.: Variational image compression with a scale hyperprior (2018),https://arxiv.org/abs/1802.01436 3, 4
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[7]
In: 2021 Data Compression Conference (DCC)
Chamain, L.D., Racapé, F., Bégaint, J., Pushparaja, A., Feltman, S.: End-to-end optimized image compression for machines, a study. In: 2021 Data Compression Conference (DCC). pp. 163–172. IEEE (2021) 1, 4
2021
-
[8]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Chen, Y.H., Weng, Y.C., Kao, C.H., Chien, C., Chiu, W.C., Peng, W.H.: Transtic: Transferring transformer-based image compression from human perception to ma- chine perception. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 23297–23307 (2023) 1, 4, 8, 9, 11, 13
2023
- [9]
-
[10]
Cho,K.,Bengio,Y.:Exponentiallyincreasingthecapacity-to-computationratiofor conditional computation in deep learning. arXiv preprint arXiv:1406.7362 (2014) 4
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[11]
IEEE Trans- actions on Image Processing31, 2739–2754 (2022) 4
Choi, H., Bajić, I.V.: Scalable image coding for humans and machines. IEEE Trans- actions on Image Processing31, 2739–2754 (2022) 4
2022
-
[12]
In: Proceedings of the IEEE/CVF international conference on computer vision
Choi, Y., El-Khamy, M., Lee, J.: Variable rate deep image compression with a con- ditional autoencoder. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 3146–3154 (2019) 3
2019
- [13]
-
[14]
In: 2009 IEEE conference on computer vision and pattern recognition
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: Imagenet: A large- scale hierarchical image database. In: 2009 IEEE conference on computer vision and pattern recognition. pp. 248–255. Ieee (2009) 8
2009
-
[15]
In: International conference on machine learning
Du, N., Huang, Y., Dai, A.M., Tong, S., Lepikhin, D., Xu, Y., Krikun, M., Zhou, Y., Yu, A.W., Firat, O., et al.: Glam: Efficient scaling of language models with mixture-of-experts. In: International conference on machine learning. pp. 5547–
-
[16]
IEEE Transactions on Circuits and Systems for Video Tech- nology33(8), 4108–4121 (2023) 1, 4
Duan, Z., Ma, Z., Zhu, F.: Unified architecture adaptation for compressed domain semantic inference. IEEE Transactions on Circuits and Systems for Video Tech- nology33(8), 4108–4121 (2023) 1, 4
2023
-
[17]
Journal of Machine Learning Research 23(120), 1–39 (2022) 4 16 J
Fedus,W.,Zoph,B.,Shazeer,N.:Switchtransformers:Scalingtotrillionparameter models with simple and efficient sparsity. Journal of Machine Learning Research 23(120), 1–39 (2022) 4 16 J. Zhao et al
2022
-
[18]
Fedus,W.,Zoph,B.,Shazeer,N.:Switchtransformers:Scalingtotrillionparameter models with simple and efficient sparsity (2022),https://arxiv.org/abs/2101.0 39619
2022
-
[19]
arXiv preprint arXiv:2407.11633 (2024)
Fei, Z., Fan, M., Yu, C., Li, D., Huang, J.: Scaling diffusion transformers to 16 billion parameters. arXiv preprint arXiv:2407.11633 (2024) 4
-
[20]
In: European Conference on Computer Vision
Feng, R., Jin, X., Guo, Z., Feng, R., Gao, Y., He, T., Zhang, Z., Sun, S., Chen, Z.: Image coding for machines with omnipotent feature learning. In: European Conference on Computer Vision. pp. 510–528. Springer (2022) 1, 4
2022
-
[21]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Feng, Z., Zhang, Z., Yu, X., Fang, Y., Li, L., Chen, X., Lu, Y., Liu, J., Yin, W., Feng, S., et al.: Ernie-vilg 2.0: Improving text-to-image diffusion model with knowledge-enhanced mixture-of-denoising-experts. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 10135– 10145 (2023) 4
2023
-
[22]
In: 2022 Picture Coding Symposium (PCS)
Harell, A., De Andrade, A., Bajić, I.V.: Rate-distortion in image coding for ma- chines. In: 2022 Picture Coding Symposium (PCS). pp. 199–203. IEEE (2022) 4
2022
- [23]
- [24]
-
[25]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision
Iwai, S., Miyazaki, T., Omachi, S.: Controlling rate, distortion, and realism: To- wards a single comprehensive neural image compression model. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 2900–2909 (2024) 1, 4
2024
-
[26]
In: ICASSP 2021-2021 IEEE In- ternational Conference on Acoustics, Speech and Signal Processing (ICASSP)
Le, N., Zhang, H., Cricri, F., Ghaznavi-Youvalari, R., Rahtu, E.: Image coding for machines: an end-to-end learned approach. In: ICASSP 2021-2021 IEEE In- ternational Conference on Acoustics, Speech and Signal Processing (ICASSP). pp. 1590–1594. IEEE (2021) 1, 4
2021
-
[27]
Lee, J., Cho, S., Beack, S.K.: Context-adaptive entropy model for end-to-end op- timized image compression (2019),https://arxiv.org/abs/1809.104524
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[28]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Lee, Y., Kim, J., Go, H., Jeong, M., Oh, S., Choi, S.: Multi-architecture multi- expert diffusion models. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 38, pp. 13427–13436 (2024) 4
2024
-
[29]
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
Lepikhin, D., Lee, H., Xu, Y., Chen, D., Firat, O., Huang, Y., Krikun, M., Shazeer, N., Chen, Z.: Gshard: Scaling giant models with conditional computation and automatic sharding. arXiv preprint arXiv:2006.16668 (2020) 4
work page internal anchor Pith review Pith/arXiv arXiv 2006
- [30]
-
[31]
MiniMax-01: Scaling Foundation Models with Lightning Attention
Li, A., Gong, B., Yang, B., Shan, B., Liu, C., Zhu, C., Zhang, C., Guo, C., Chen, D., Li, D., et al.: Minimax-01: Scaling foundation models with lightning attention. arXiv preprint arXiv:2501.08313 (2025) 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [32]
-
[33]
Li, H., Li, S., Ding, S., Dai, W., Cao, M., Li, C., Zou, J., Xiong, H.: Image compres- sionformachineandhumanvisionwithspatial-frequencyadaptation.In:European Conference on Computer Vision. pp. 382–399. Springer (2024) 1, 4
2024
-
[34]
IEEE Journal on Emerging and Selected Topics in Circuits and Systems14(2), 198–208 (2024) 4 MoECodec17
Li, H., Zhang, X.: Human–machine collaborative image compression method based on implicit neural representations. IEEE Journal on Emerging and Selected Topics in Circuits and Systems14(2), 198–208 (2024) 4 MoECodec17
2024
-
[35]
Conditional Computation for Continual Learning
Lin, M., Fu, J., Bengio, Y.: Conditional computation for continual learning. arXiv preprint arXiv:1906.06635 (2019) 4
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[36]
In: European conference on computer vision
Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: European conference on computer vision. pp. 740–755. Springer (2014) 8
2014
-
[37]
Liu, A., Feng, B., Xue, B., Wang, B., Wu, B., Lu, C., Zhao, C., Deng, C., Zhang, C., Ruan, C., et al.: Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437 (2024) 4
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
In: 2022 26th International Conference on Pattern Recognition (ICPR)
Liu, J., Sun, H., Katto, J.: Improving multiple machine vision tasks in the com- pressed domain. In: 2022 26th International Conference on Pattern Recognition (ICPR). pp. 331–337. IEEE (2022) 1, 4
2022
- [39]
-
[40]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Liu, J., Sun, H., Katto, J.: Learned image compression with mixed transformer- cnn architectures. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 14388–14397 (2023) 8, 9
2023
-
[41]
In: Proceedings of the 31st ACM International Conference on Multimedia
Liu,L.,Hu,Z.,Chen,Z.,Xu,D.:Icmh-net:Neuralimagecompressiontowardsboth machine vision and human vision. In: Proceedings of the 31st ACM International Conference on Multimedia. pp. 8047–8056 (2023) 1, 4, 8, 9, 11, 13
2023
- [42]
- [43]
-
[44]
Minnen, D., Ballé, J., Toderici, G.: Joint autoregressive and hierarchical priors for learned image compression (2018),https://arxiv.org/abs/1809.027364
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [45]
-
[46]
In: European Conference on Computer Vision
Park, B., Go, H., Kim, J.Y., Woo, S., Ham, S., Kim, C.: Switch diffusion trans- former: Synergizing denoising tasks with sparse mixture-of-experts. In: European Conference on Computer Vision. pp. 461–477. Springer (2024) 4
2024
-
[47]
arXiv preprint arXiv:2310.07138 (2023) 4
Park, B., Woo, S., Go, H., Kim, J.Y., Kim, C.: Denoising task routing for diffusion models. arXiv preprint arXiv:2310.07138 (2023) 4
-
[48]
arXiv preprint arXiv:2009.13239 (2020) 4
Puigcerver, J., Riquelme, C., Mustafa, B., Renggli, C., Pinto, A.S., Gelly, S., Key- sers, D., Houlsby, N.: Scalable transfer learning with expert models. arXiv preprint arXiv:2009.13239 (2020) 4
-
[49]
Qian, Y., Lin, M., Sun, X., Tan, Z., Jin, R.: Entroformer: A transformer-based entropy model for learned image compression (2022),https://arxiv.org/abs/22 02.054924
2022
-
[50]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Shazeer, N., Mirhoseini, A., Maziarz, K., Davis, A., Le, Q., Hinton, G., Dean, J.: Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. arXiv preprint arXiv:1701.06538 (2017) 4
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[51]
arXiv preprint arXiv:2503.14487 (2025)
Shi, M., Yuan, Z., Yang, H., Wang, X., Zheng, M., Tao, X., Zhao, W., Zheng, W., Zhou, J., Lu, J., et al.: Diffmoe: Dynamic token selection for scalable diffusion transformers. arXiv preprint arXiv:2503.14487 (2025) 4
-
[52]
In: Proceedings of the IEEE/CVF interna- tional conference on computer vision
Song, M., Choi, J., Han, B.: Variable-rate deep image compression through spatially-adaptive feature transform. In: Proceedings of the IEEE/CVF interna- tional conference on computer vision. pp. 2380–2389 (2021) 1, 4
2021
-
[53]
arXiv preprint arXiv:2410.02098 (2024)
Sun, H., Lei, T., Zhang, B., Li, Y., Huang, H., Pang, R., Dai, B., Du, N.: Ec-dit: Scaling diffusion transformers with adaptive expert-choice routing. arXiv preprint arXiv:2410.02098 (2024) 4 18 J. Zhao et al
-
[54]
In: CVPR (2020) 9
Toderici, G., Shi, W., Timofte, R., Theis, L., Balle, J., Agustsson, E., Johnston, N., Mentzer, F.: Workshop and challenge on learned image compression (clic2020). In: CVPR (2020) 9
2020
-
[55]
IEEE Transactions on Multimedia24, 3169–3181 (2021) 4
Wang, S., Wang, S., Yang, W., Zhang, X., Wang, S., Ma, S., Gao, W.: Towards analysis-friendly face representation with scalable feature and texture compression. IEEE Transactions on Multimedia24, 3169–3181 (2021) 4
2021
-
[56]
IEEE Transactions on Circuits and Sys- tems for Video Technology33(6), 2979–2989 (2022) 1, 4
Wang, S., Wang, Z., Wang, S., Ye, Y.: Deep image compression toward machine vision: A unified optimization framework. IEEE Transactions on Circuits and Sys- tems for Video Technology33(6), 2979–2989 (2022) 1, 4
2022
-
[57]
Advances in Neural Infor- mation Processing Systems36, 41693–41706 (2023) 4
Xue, Z., Song, G., Guo, Q., Liu, B., Zong, Z., Liu, Y., Luo, P.: Raphael: Text-to- image generation via large mixture of diffusion paths. Advances in Neural Infor- mation Processing Systems36, 41693–41706 (2023) 4
2023
-
[58]
IEEE Transactions on Image Processing30, 8939–8954 (2021) 4
Yan, N., Gao, C., Liu, D., Li, H., Li, L., Wu, F.: Sssic: Semantics-to-signal scalable image coding with learned structural representations. IEEE Transactions on Image Processing30, 8939–8954 (2021) 4
2021
-
[59]
Yang, F., Herranz, L., Cheng, Y., Mozerov, M.G.: Slimmable compressive autoen- coders for practical neural image compression (2022),https://arxiv.org/abs/21 03.157263
2022
-
[60]
Scaling Autoregressive Models for Content-Rich Text-to-Image Generation
Yu, J., Xu, Y., Koh, J.Y., Luong, T., Baid, G., Wang, Z., Vasudevan, V., Ku, A., Yang, Y., Ayan, B.K., et al.: Scaling autoregressive models for content-rich text-to-image generation. arXiv preprint arXiv:2206.107892(3), 5 (2022) 4
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[61]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Zhang, X., Zhou, X., Lin, M., Sun, J.: Shufflenet: An extremely efficient convolu- tional neural network for mobile devices. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 6848–6856 (2018) 3, 8
2018
-
[62]
Advances in Neural Information Pro- cessing Systems37, 71465–71503 (2024) 1, 4
Zhang, X., Guo, P., Lu, M., Ma, Z.: All-in-one image coding for joint human- machine vision with multi-path aggregation. Advances in Neural Information Pro- cessing Systems37, 71465–71503 (2024) 1, 4
2024
-
[63]
In: The Eleventh International Conference on Learning Representations (2022) 4
Zhenxing, M., Xu, D.: Switch-nerf: Learning scene decomposition with mixture of experts for large-scale neural radiance fields. In: The Eleventh International Conference on Learning Representations (2022) 4
2022
-
[64]
Advances in Neu- ral Information Processing Systems35, 7103–7114 (2022) 2, 4, 6
Zhou, Y., Lei, T., Liu, H., Du, N., Huang, Y., Zhao, V., Dai, A.M., Le, Q.V., Laudon, J., et al.: Mixture-of-experts with expert choice routing. Advances in Neu- ral Information Processing Systems35, 7103–7114 (2022) 2, 4, 6
2022
-
[65]
ST-MoE: Designing Stable and Transferable Sparse Expert Models
Zoph, B., Bello, I., Kumar, S., Du, N., Huang, Y., Dean, J., Shazeer, N., Fedus, W.: St-moe: Designing stable and transferable sparse expert models. arxiv 2022. arXiv preprint arXiv:2202.08906 4
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [66]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.