Indi-RomCoM: Code-Mixed Benchmark for Evaluating LLMs on Romanized Indic-English Instructions
Pith reviewed 2026-07-01 02:23 UTC · model grok-4.3
The pith
Large language models underperform on Romanized Indic-English code-mixed instructions, with larger drops at higher mixing densities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
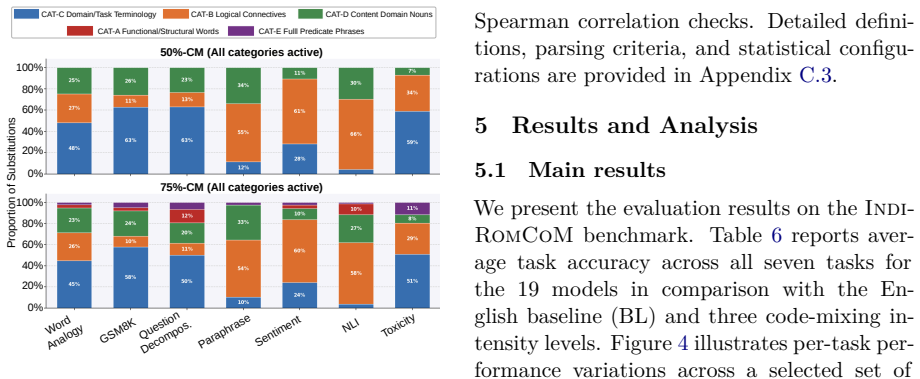
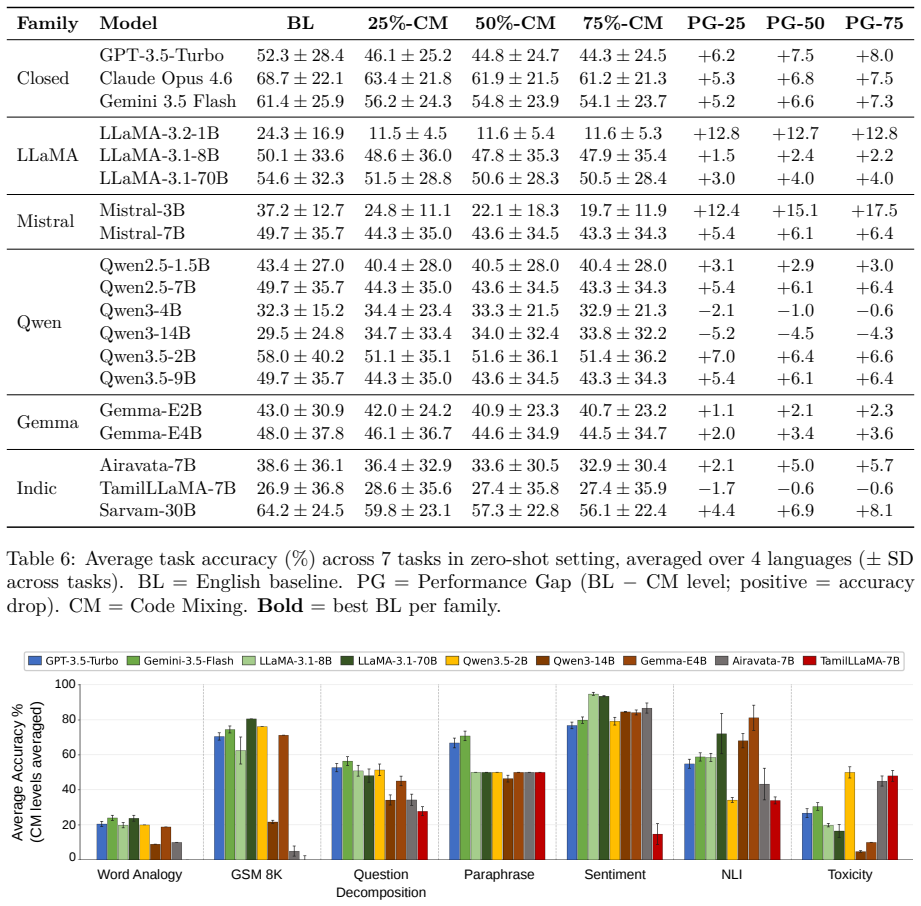
Indi-RomCoM reveals that LLMs underperform on Romanized Indic-English code-mixed instructions, with performance falling as code-mixing density rises. Reasoning tasks experience milder degradation than detection tasks because the explanations they generate supply necessary context for correct answers.
What carries the argument
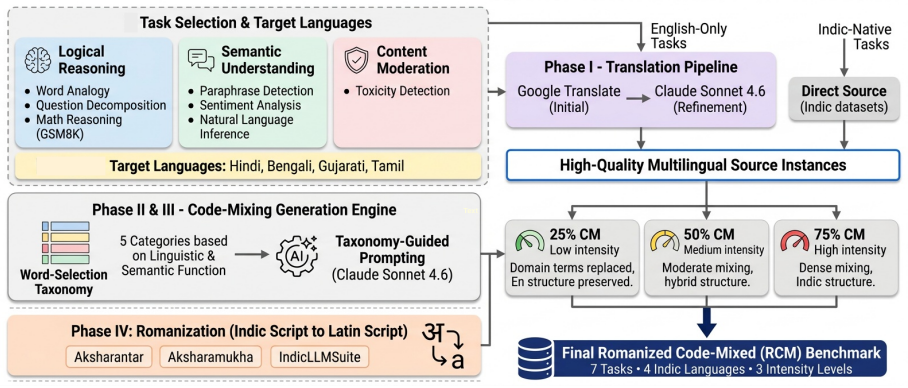
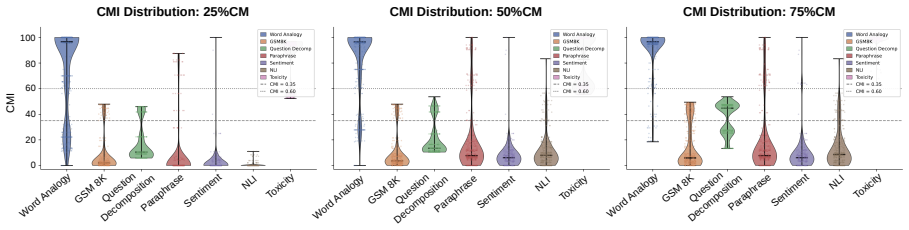
The Indi-RomCoM benchmark, a controlled test suite of seven instruction-following tasks across four Indic languages at three code-mixing intensity levels.
Load-bearing premise
The seven selected tasks and three controlled mixing levels accurately reflect the real-world difficulties LLMs encounter with Romanized Indic-English code-mixing.
What would settle it
A new model achieving near-monolingual accuracy on high-density RCM toxicity detection with no measurable drop relative to low-density cases.
Figures


read the original abstract
Romanized Code Mixing (RCM), where bilingual speakers fluidly blend local languages with English in Roman script, has emerged as the dominant form of communication across multilingual communities. While Large Language Models (LLMs) perform strongly on monolingual and native-script benchmarks, their ability to follow instructions and reason over RCM-based content remains largely unexplored. To this end, we introduce the Indi-RomCoM benchmark for facilitating systematic evaluation on Indic Romanized Code-Mixed instructions. Our benchmark spans seven instruction-following tasks, four widely spoken Indic languages, and three controlled code-mixing intensity levels. We extensively evaluate a suite of LLMs covering proprietary, open-weight, and Indic-focused models under zero- and few-shot settings. LLMs consistently underperform on RCM instructions, with performance degrading as code-mixing density increases. Furthermore, reasoning tasks suffer less degradation than detection tasks (e.g., Toxicity) because the generated explanations offer necessary context. We believe Indi-RomCoM helps the community in developing inclusive multilingual systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Indi-RomCoM, a benchmark for evaluating LLMs on Romanized Indic-English code-mixed instructions. It spans seven instruction-following tasks, four Indic languages, and three controlled code-mixing intensity levels. Evaluations of proprietary, open-weight, and Indic-focused LLMs in zero- and few-shot settings show consistent underperformance on RCM instructions that worsens with higher code-mixing density. Reasoning tasks degrade less than detection tasks (e.g., Toxicity) because generated explanations supply necessary context.
Significance. If the benchmark construction and evaluations are sound, this work identifies a practically relevant gap in LLM handling of prevalent real-world communication patterns in Indic communities. The controlled mixing levels enable systematic study of degradation trends, and the reasoning-vs-detection distinction provides a concrete observation that could inform targeted improvements in multilingual model training.
major comments (2)
- [Abstract] Abstract: The abstract states performance degradation results but provides no details on evaluation methodology, dataset construction, statistical tests, or error analysis, preventing verification of whether the claims are supported by the data.
- [Benchmark Construction] Benchmark design: The claim that the seven chosen instruction-following tasks and three controlled code-mixing intensity levels accurately capture real-world challenges requires explicit justification or comparison against natural code-mixing distributions; without this, the generalizability of the degradation findings is difficult to assess.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract states performance degradation results but provides no details on evaluation methodology, dataset construction, statistical tests, or error analysis, preventing verification of whether the claims are supported by the data.
Authors: We acknowledge that the abstract prioritizes brevity and omits methodological specifics. The full paper details the zero- and few-shot evaluation protocol, model suite, dataset construction, and result analysis (including degradation trends) in Sections 3–5. We will revise the abstract to concisely reference the evaluation settings, controlled mixing levels, and the presence of supporting analysis in the main text. revision: yes
-
Referee: [Benchmark Construction] Benchmark design: The claim that the seven chosen instruction-following tasks and three controlled code-mixing intensity levels accurately capture real-world challenges requires explicit justification or comparison against natural code-mixing distributions; without this, the generalizability of the degradation findings is difficult to assess.
Authors: Task selection draws from standard instruction-following categories (classification, generation, reasoning) commonly used in multilingual NLP benchmarks to reflect practical applications. Mixing levels follow established linguistic metrics for code-mixing density to enable controlled isolation of effects. We agree that explicit justification and references to natural distributions would strengthen the paper. We will add a dedicated paragraph in the benchmark construction section with citations to prior work on Indic code-mixing and rationale for the synthetic control approach. revision: yes
Circularity Check
No significant circularity; empirical benchmark study
full rationale
The paper creates the Indi-RomCoM benchmark across seven tasks, four languages, and three code-mixing levels, then evaluates LLMs under zero- and few-shot settings. No equations, derivations, parameter fitting, or self-referential claims appear in the provided text. The central claims (underperformance on RCM, degradation with density, reasoning vs. detection differences) are direct empirical observations, not reductions to inputs by construction. No self-citation chains or uniqueness theorems are invoked as load-bearing. This matches the default case of a self-contained empirical study against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The seven instruction-following tasks and three controlled code-mixing intensity levels are appropriate and representative for evaluating LLM performance on RCM.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2506.00332 , year=
Disentangling codemixing in chats: The NUS ABC codemixed corpus , author=. arXiv preprint arXiv:2506.00332 , year=
-
[2]
World Englishes , volume=
Are there syntactic constraints on code-mixing? , author=. World Englishes , volume=. 1989 , publisher=
1989
-
[3]
Languages , volume=
Code-switching in linguistics: A position paper , author=. Languages , volume=. 2020 , publisher=
2020
-
[4]
International Encyclopedia of the Social and Behavioral Sciences , editor =
Poplack, Shana , title =. International Encyclopedia of the Social and Behavioral Sciences , editor =
-
[5]
Hu, Edward J and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Liang and Chen, Weizhu and others , journal=. Lo
-
[6]
Language policy , volume=
National language policy theory: Exploring Spolsky’s model in the case of Iceland , author=. Language policy , volume=. 2016 , publisher=
2016
-
[7]
The Palgrave handbook of minority languages and communities , pages=
Minorities, languages, education, and assimilation in Southeast Asia , author=. The Palgrave handbook of minority languages and communities , pages=. 2018 , publisher=
2018
-
[8]
1993 , publisher=
Social motivations for codeswitching: Evidence from Africa , author=. 1993 , publisher=
1993
-
[9]
IEEE Access , volume=
BharatBhasaNet-a unified framework to identify Indian code mix languages , author=. IEEE Access , volume=. 2024 , publisher=
2024
-
[10]
Rijhwani, Shruti and Sequiera, Royal and Choudhury, Monojit and Bali, Kalika and Maddila, Chandra Shekhar. Estimating Code-Switching on T witter with a Novel Generalized Word-Level Language Detection Technique. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2017. doi:10.18653/v1/P17-1180
-
[12]
Humanities and Social Sciences Communications , volume=
Social, economic, and demographic factors drive the emergence of Hinglish code-mixing on social media , author=. Humanities and Social Sciences Communications , volume=. 2024 , publisher=
2024
-
[13]
ACM computing surveys , volume=
Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing , author=. ACM computing surveys , volume=. 2023 , publisher=
2023
-
[14]
Journal of Machine Learning Research , volume=
Scaling instruction-finetuned language models , author=. Journal of Machine Learning Research , volume=
-
[15]
Journal of machine learning research , volume=
Palm: Scaling language modeling with pathways , author=. Journal of machine learning research , volume=
-
[16]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama 2: Open foundation and fine-tuned chat models , author=. arXiv preprint arXiv:2307.09288 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Bloom: A 176b-parameter open-access multilingual language model , author=. arXiv preprint arXiv:2211.05100 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , year=
Romansetu: Efficiently unlocking multilingual capabilities of large language models via romanization , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , year=
-
[19]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , year=
Indicllmsuite: A blueprint for creating pre-training and fine-tuning datasets for indian languages , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , year=
-
[20]
arXiv preprint arXiv:2501.13912 , year=
Analysis of Indic Language Capabilities in LLMs , author=. arXiv preprint arXiv:2501.13912 , year=
-
[21]
Proceedings of the Twelfth Language Resources and Evaluation Conference , year=
LinCE: A centralized benchmark for linguistic code-switching evaluation , author=. Proceedings of the Twelfth Language Resources and Evaluation Conference , year=
-
[22]
Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , year=
GLUECoS: An evaluation benchmark for code-switched NLP , author=. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , year=
-
[23]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , year=
CodeMixBench: Evaluating code-mixing capabilities of LLMs across 18 languages , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , year=
2025
-
[24]
Proceedings of the 2022 conference on empirical methods in natural language processing , year=
Super-naturalinstructions: Generalization via declarative instructions on 1600+ nlp tasks , author=. Proceedings of the 2022 conference on empirical methods in natural language processing , year=
2022
-
[27]
Proceedings of the 2022 conference on empirical methods in natural language processing , year=
IndicXNLI: Evaluating multilingual inference for Indian languages , author=. Proceedings of the 2022 conference on empirical methods in natural language processing , year=
2022
-
[30]
and Schwenk, Holger and Stoyanov, Veselin
Conneau, Alexis and Rinott, Ruty and Lample, Guillaume and Williams, Adina and Bowman, Samuel R. and Schwenk, Holger and Stoyanov, Veselin. XNLI: Evaluating Cross-lingual Sentence Representations. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018
2018
-
[32]
Findings of the association for computational linguistics: Emnlp 2023 , year=
Aksharantar: Open Indic-language transliteration datasets and models for the next billion users , author=. Findings of the association for computational linguistics: Emnlp 2023 , year=
2023
-
[33]
Transactions on Machine Learning Research , issn=
IndicTrans2: Towards High-Quality and Accessible Machine Translation Models for all 22 Scheduled Indian Languages , author=. Transactions on Machine Learning Research , issn=. 2023 , url=
2023
-
[34]
Proceedings of the 40th annual meeting of the Association for Computational Linguistics , year=
Bleu: a method for automatic evaluation of machine translation , author=. Proceedings of the 40th annual meeting of the Association for Computational Linguistics , year=
-
[35]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , year=
Bhasa-abhijnaanam: Native-script and romanized language identification for 22 Indic languages , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , year=
-
[36]
Biometrics , volume=
The Wilcoxon signed rank test for paired comparisons of clustered data , author=. Biometrics , volume=. 2006 , publisher=
2006
-
[37]
2013 , publisher=
Statistical power analysis for the behavioral sciences , author=. 2013 , publisher=
2013
-
[38]
Psychometrika , volume=
Note on the sampling error of the difference between correlated proportions or percentages , author=. Psychometrika , volume=. 1947 , publisher=
1947
-
[39]
Proceedings of the 2023 conference on empirical methods in natural language processing , year=
Multilingual large language models are not (yet) code-switchers , author=. Proceedings of the 2023 conference on empirical methods in natural language processing , year=
2023
-
[41]
Ian Webster , title =
-
[45]
L in CE : A Centralized Benchmark for Linguistic Code-switching Evaluation
Aguilar, Gustavo and Kar, Sudipta and Solorio, Thamar. L in CE : A Centralized Benchmark for Linguistic Code-switching Evaluation. Proceedings of the Twelfth Language Resources and Evaluation Conference. 2020
2020
-
[47]
Yang, Qingyan and Wang, Tongxi and Luo, Yunsheng , journal=
-
[50]
Chitale, Pranjal A and Gumma, Varun and Ahuja, Sanchit and Kodali, Prashant and Uppadhyay, Manan and Sudharsan, Deepthi and Sitaram, Sunayana , journal=
-
[51]
Airavata: Introducing Hindi Instruction-tuned
Gala, Jay and Jayakumar, Thanmay and Husain, Jaavid Aktar and Khan, Mohammed Safi Ur Rahman and Kanojia, Diptesh and Puduppully, Ratish and Khapra, Mitesh M and Dabre, Raj and Murthy, Rudra and Kunchukuttan, Anoop and others , journal=. Airavata: Introducing Hindi Instruction-tuned
-
[52]
Balachandran, Abhinand , journal=
-
[53]
Hugging Face repository , howpublished =
Sarvam-1 , year =. Hugging Face repository , howpublished =
-
[54]
Dawar, Aviral and Karanth, Roshan and Goyal, Vikram and Kumar, Dhruv , journal=
-
[55]
Pattnayak, Priyaranjan and Chowdhuri, Sanchari , journal=
-
[56]
Proceedings of the 2022 conference on empirical methods in natural language processing , year=
IndicNLG benchmark: Multilingual datasets for diverse NLG tasks in Indic languages , author=. Proceedings of the 2022 conference on empirical methods in natural language processing , year=
2022
-
[57]
2026 , month =
Kavukcuoglu, Koray and Dean, Jeff and Vinyals, Oriol and Shazeer, Noam , title =. 2026 , month =
2026
-
[58]
2026 , organization =
2026
-
[59]
2026 , month =
Introducing. 2026 , month =
2026
-
[62]
Models Overview , year =
-
[64]
2026 , month =
Farabet, Clement and Lacombe, Olivier , title =. 2026 , month =
2026
-
[65]
Divyanshu Aggarwal, Vivek Gupta, and Anoop Kunchukuttan. 2022. Indicxnli: Evaluating multilingual inference for indian languages. In Proceedings of the 2022 conference on empirical methods in natural language processing
2022
-
[66]
Gustavo Aguilar, Sudipta Kar, and Thamar Solorio. 2020. https://aclanthology.org/2020.lrec-1.223/ L in CE : A centralized benchmark for linguistic code-switching evaluation . In Proceedings of the Twelfth Language Resources and Evaluation Conference
2020
-
[67]
Anthropic . 2026. https://www.anthropic.com/news/claude-opus-4-6 Introducing Claude Opus 4.6 . Anthropic News. Accessed: May 24, 2026
2026
-
[68]
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. 2024. https://doi.org/10.18653/v1/2024.acl-long.172 L ong B ench: A bilingual, multitask benchmark for long context understanding . In Proceedings of the 62nd Annual Meeting of the Association for ...
- [69]
-
[70]
Eyamba G Bokamba. 1989. Are there syntactic constraints on code-mixing? World Englishes, 8(3):277--292
1989
- [71]
-
[72]
Mukund Choudhary, Madhur Jindal, Gaurja Aeron, and Monojit Choudhury. 2026. https://doi.org/10.18653/v1/2026.findings-eacl.291 Do LLM s model human linguistic variation? a case study in H indi- E nglish verb code-mixing . In Findings of the A ssociation for C omputational L inguistics: EACL 2026
-
[73]
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[74]
Jacob Cohen. 2013. Statistical power analysis for the behavioral sciences. routledge
2013
-
[75]
Bowman, Holger Schwenk, and Veselin Stoyanov
Alexis Conneau, Ruty Rinott, Guillaume Lample, Adina Williams, Samuel R. Bowman, Holger Schwenk, and Veselin Stoyanov. 2018. Xnli: Evaluating cross-lingual sentence representations. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing
2018
-
[76]
Aviral Dawar, Roshan Karanth, Vikram Goyal, and Dhruv Kumar. 2026. IndicDB --benchmarking multilingual text-to- SQL capabilities in indian languages. arXiv preprint arXiv:2604.13686
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[77]
Margaret Deuchar. 2020. Code-switching in linguistics: A position paper. Languages, 5(2):22
2020
-
[78]
Jay Gala, Thanmay Jayakumar, Jaavid Aktar Husain, Mohammed Safi Ur Rahman Khan, Diptesh Kanojia, Ratish Puduppully, Mitesh M Khapra, Raj Dabre, Rudra Murthy, Anoop Kunchukuttan, and 1 others. 2024. Airavata: Introducing hindi instruction-tuned LLM . arXiv preprint arXiv:2401.15006
-
[79]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, and 1 others. 2024. The llama 3 herd of models. arXiv preprint arXiv:2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [80]
-
[81]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, and 1 others. 2022. Lo RA : Low-rank adaptation of large language models. Iclr, 1(2):3
2022
-
[82]
J Jaavid, Raj Dabre, M Aswanth, Jay Gala, Thanmay Jayakumar, Ratish Puduppully, and Anoop Kunchukuttan. 2024. Romansetu: Efficiently unlocking multilingual capabilities of large language models via romanization. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
2024
-
[83]
Koray Kavukcuoglu, Jeff Dean, Oriol Vinyals, and Noam Shazeer. 2026. https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-5/#gemini-3-5-flash Gemini 3.5: Frontier intelligence with action . Google Blog (The Keyword). Accessed: May 24, 2026
2026
-
[84]
Mohammed Safi Ur Rahman Khan, Priyam Mehta, Ananth Sankar, Umashankar Kumaravelan, Sumanth Doddapaneni, Suriyaprasaad B, Varun G, Sparsh Jain, Anoop Kunchukuttan, Pratyush Kumar, Raj Dabre, and Mitesh M. Khapra. 2024 a . https://doi.org/10.18653/v1/2024.acl-long.843 I ndic LLMS uite: A blueprint for creating pre-training and fine-tuning datasets for I ndi...
-
[85]
Mohammed Safi Ur Rahman Khan, Priyam Mehta, Ananth Sankar, Umashankar Kumaravelan, Sumanth Doddapaneni, Sparsh Jain, Anoop Kunchukuttan, Pratyush Kumar, Raj Dabre, Mitesh M Khapra, and 1 others. 2024 b . Indicllmsuite: A blueprint for creating pre-training and fine-tuning datasets for indian languages. In Proceedings of the 62nd Annual Meeting of the Asso...
2024
-
[86]
Simran Khanuja, Sandipan Dandapat, Anirudh Srinivasan, Sunayana Sitaram, and Monojit Choudhury. 2020 a . Gluecos: An evaluation benchmark for code-switched nlp. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics
2020
-
[87]
Simran Khanuja, Sandipan Dandapat, Anirudh Srinivasan, Sunayana Sitaram, and Monojit Choudhury. 2020 b . https://doi.org/10.18653/v1/2020.acl-main.329 GLUEC o S : An evaluation benchmark for code-switched NLP . In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics
- [88]
-
[89]
Wai-Chung Kwan, Xingshan Zeng, Yufei Wang, Yusen Sun, Liangyou Li, Yuxin Jiang, Lifeng Shang, Qun Liu, and Kam-Fai Wong. 2024. https://doi.org/10.18653/v1/2024.acl-long.832 M 4 LE : A multi-ability multi-range multi-task multi-domain long-context evaluation benchmark for large language models . In Proceedings of the 62nd Annual Meeting of the Association ...
-
[90]
Yash Madhani, Mitesh M Khapra, and Anoop Kunchukuttan. 2023 a . Bhasa-abhijnaanam: Native-script and romanized language identification for 22 indic languages. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers)
2023
-
[91]
Yash Madhani, Sushane Parthan, Priyanka Bedekar, Gokul Nc, Ruchi Khapra, Anoop Kunchukuttan, Pratyush Kumar, and Mitesh M Khapra. 2023 b . Aksharantar: Open indic-language transliteration datasets and models for the next billion users. In Findings of the association for computational linguistics: Emnlp 2023
2023
-
[92]
Quinn McNemar. 1947. Note on the sampling error of the difference between correlated proportions or percentages. Psychometrika, 12(2):153--157
1947
-
[93]
Mistral AI . 2026. https://docs.mistral.ai/models/overview Models overview . Mistral AI Documentation. Accessed: May 24, 2026
2026
-
[94]
Carol Myers-Scotton. 1993. Social motivations for codeswitching: Evidence from Africa. Oxford University Press
1993
-
[95]
OpenAI . 2026. https://developers.openai.com/api/docs/models/gpt-3.5-turbo GPT-3.5 Turbo model documentation . OpenAI Developer Documentation. Accessed: May 24, 2026
2026
-
[96]
Priyaranjan Pattnayak and Sanchari Chowdhuri. 2026. IndicSafe: a benchmark for evaluating multilingual LLM safety in south asia. arXiv preprint arXiv:2603.17915
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.