CTS-MoE: Implicit Terrain Adaptation via Mixture-of-Experts for Perceptive Locomotion
Pith reviewed 2026-06-26 20:19 UTC · model grok-4.3
The pith
A perception-gated mixture-of-experts actor with multi-critic heads lets legged robots adapt gaits to discontinuous terrain using only onboard sensing at runtime.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
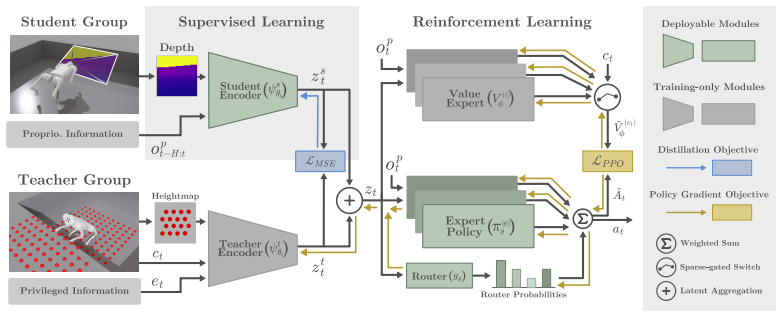
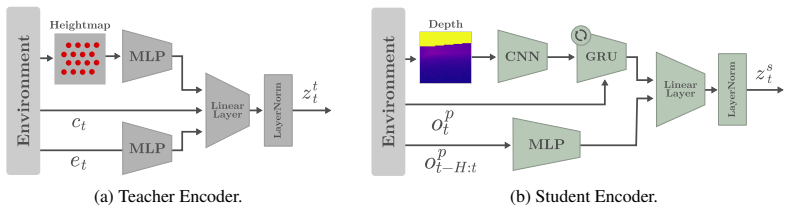
CTS-MoE combines a dense mixture-of-experts actor with perception-based gating to compose shared behaviors and a multi-critic with task-specific value heads to prevent interference. The model is trained end-to-end in a single-stage concurrent teacher-student setup that handles partial observability and avoids sequential distillation, with task labels used only during training. At deployment, routing depends solely on perception, allowing terrain adaptation without a high-level selector or terrain classifier.
What carries the argument
Perception-based gating inside the mixture-of-experts actor together with task-specific value heads in the multi-critic.
If this is right
- Specialized behaviors for different terrain types can emerge without an explicit terrain classifier or high-level selector.
- Concurrent training with task-specific critics avoids value interference while preserving a shared locomotion base.
- Single-stage teacher-student training removes the need for sequential distillation steps.
- The resulting policy maintains generalization across transitions between terrains and to unseen terrain.
Where Pith is reading between the lines
- The same perception-gated routing structure could be tested on other multi-task robotic problems where sensory input naturally distinguishes subtasks.
- Removing the requirement for terrain labels at test time may simplify integration with existing perception pipelines on physical robots.
- If the multi-critic separation proves robust, similar value-head designs could be applied to other concurrent multi-task reinforcement learning settings in robotics.
Load-bearing premise
Perception alone at deployment time is sufficient to route the mixture-of-experts policy to the correct behaviors without task labels or an explicit terrain classifier.
What would settle it
A controlled test on a novel terrain type absent from training where the CTS-MoE policy shows no improvement in success rate or tracking error over a monolithic baseline when both receive only raw perception.
Figures




read the original abstract
Perceptive legged locomotion over discontinuous terrain (e.g., stairs, gaps, and obstacles) requires adaptive behavior, as a single conservative gait cannot produce the anticipatory maneuvers needed for abrupt topology changes. Cast as multi-task reinforcement learning, this problem introduces a tension between sharing and separation. Tasks use a common locomotion base but have conflicting rewards, so a policy must share behavior while avoiding value interference. Prior work addresses only one side, with monolithic policies sacrificing specialization and hierarchical sub-policies sacrificing generalization across transitions and unseen terrain. We propose CTS-MoE, which combines a dense mixture-of-experts actor with perception-based gating to compose shared behaviors and a multi-critic with task-specific value heads to prevent interference. The model is trained end-to-end in a single-stage concurrent teacher-student setup that handles partial observability and avoids sequential distillation, with task labels used only during training. At deployment, routing depends solely on perception, allowing terrain adaptation without a high-level selector or terrain classifier. Experiments on a Unitree Go1 in simulation and on hardware across seen and unseen terrains show task-aware specialization, with lower tracking error and higher success rates than monolithic baselines. Project Website: https://cts-moe.github.io/ .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CTS-MoE, a dense mixture-of-experts actor with perception-based gating combined with a multi-critic architecture for multi-task RL in perceptive legged locomotion over discontinuous terrain. It is trained end-to-end in a single-stage concurrent teacher-student setup (task labels used only during training) and evaluated on a Unitree Go1 in simulation and hardware, claiming task-aware specialization, lower tracking error, and higher success rates than monolithic baselines on both seen and unseen terrains.
Significance. If the perception-conditioned gate generalizes reliably, the approach offers a practical resolution to the sharing-separation tension in locomotion policies by enabling implicit terrain adaptation without explicit classifiers or sequential distillation. The single-stage concurrent training and multi-critic design are notable strengths for avoiding value interference while maintaining generalization across transitions.
major comments (2)
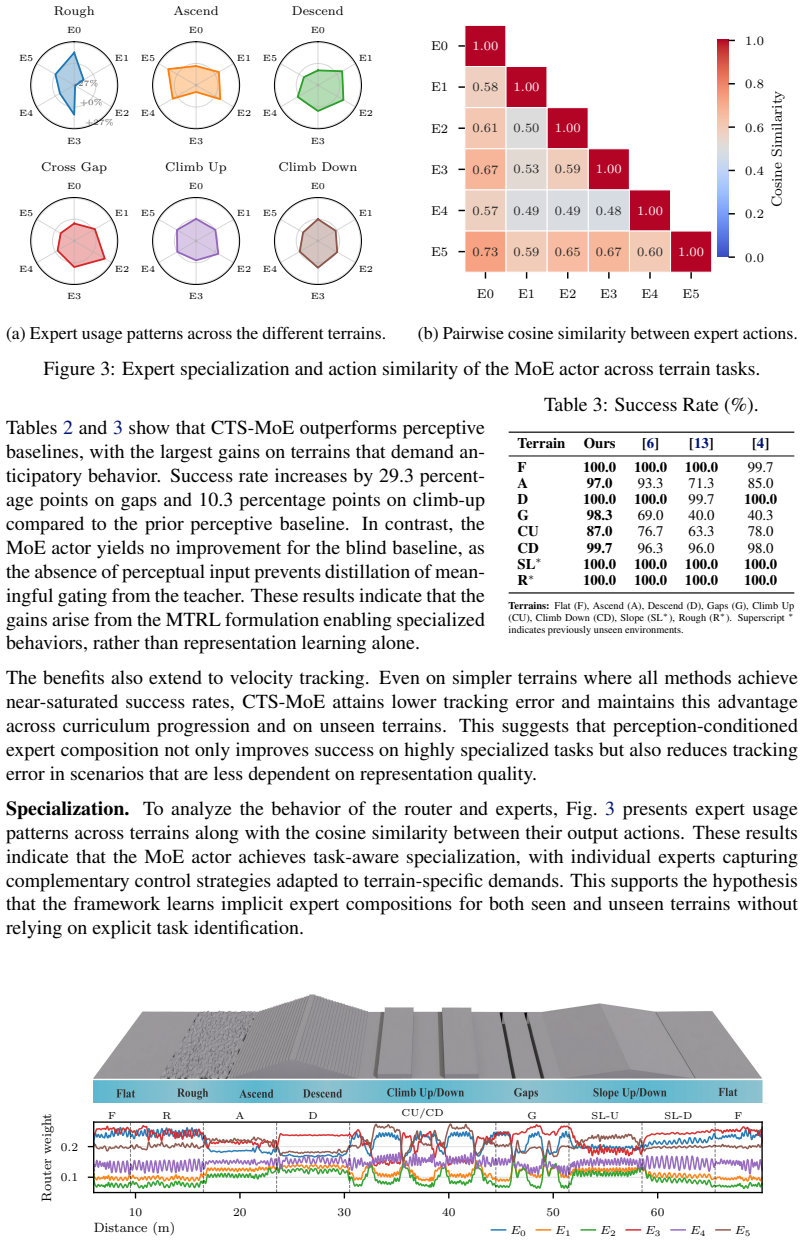
- [§5 (Experiments and Ablations)] The central claim requires that the perception-conditioned gate (trained with task labels) produces terrain-appropriate expert selection at deployment without labels or classifier. The manuscript must provide concrete evidence—such as expert activation histograms, t-SNE visualizations of gate inputs, or an ablation replacing the learned gate with a random router—on unseen terrains to rule out overfitting to training label correlations (see skeptic concern on partial observability and spurious correlations).
- [§5.2] Table 2 (or equivalent quantitative results table): the reported improvements in tracking error and success rate on unseen terrain must include error bars, number of trials, and statistical significance tests; without these, the superiority over monolithic baselines cannot be assessed as load-bearing for the generalization claim.
minor comments (2)
- [Abstract] The abstract would benefit from one or two key quantitative results (e.g., success rate deltas) to allow readers to gauge effect sizes before reading the full experiments.
- [§3] Notation for the gate network (e.g., how perception features are encoded before the softmax) should be defined explicitly in the methods section for reproducibility.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive suggestions. We will revise the manuscript to provide additional evidence supporting the generalization of the perception-conditioned gate and to enhance the statistical reporting of our experimental results.
read point-by-point responses
-
Referee: [§5 (Experiments and Ablations)] The central claim requires that the perception-conditioned gate (trained with task labels) produces terrain-appropriate expert selection at deployment without labels or classifier. The manuscript must provide concrete evidence—such as expert activation histograms, t-SNE visualizations of gate inputs, or an ablation replacing the learned gate with a random router—on unseen terrains to rule out overfitting to training label correlations (see skeptic concern on partial observability and spurious correlations).
Authors: We agree that additional visualizations and ablations are necessary to substantiate the claim that the gate generalizes to unseen terrains without relying on task labels. In the revised manuscript, we will add expert activation histograms and t-SNE plots of the gate inputs for unseen terrains in Section 5. We will also include an ablation study with a random router to demonstrate the learned gate's contribution. These will be supported by quantitative metrics on expert selection consistency. revision: yes
-
Referee: [§5.2] Table 2 (or equivalent quantitative results table): the reported improvements in tracking error and success rate on unseen terrain must include error bars, number of trials, and statistical significance tests; without these, the superiority over monolithic baselines cannot be assessed as load-bearing for the generalization claim.
Authors: We acknowledge that the current presentation of results in Table 2 lacks the necessary statistical details. In the revised version, we will update the table to report mean and standard deviation (error bars) across multiple trials (we will specify the number, e.g., 50-100 episodes per condition), and include statistical significance tests such as paired t-tests or Wilcoxon tests with p-values to compare CTS-MoE against the baselines on unseen terrains. revision: yes
Circularity Check
No circularity in derivation or claims
full rationale
The paper presents an architectural proposal (dense MoE actor + perception gating + multi-critic) trained end-to-end in a teacher-student RL setup, with claims resting on simulation/hardware experiments rather than any mathematical derivation chain. No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the provided text. The method is described as a composition of standard components with experimental validation; the gate's generalization is an empirical claim, not a reduction to inputs by construction. This is the expected non-finding for an applied RL systems paper without closed-form derivations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
R. S. Sutton and A. G. Barto.Reinforcement Learning: An Introduction. MIT Press, Cam- bridge, MA, 2nd edition, 2018
2018
-
[2]
Kumar, Z
A. Kumar, Z. Fu, D. Pathak, and J. Malik. Rma: Rapid motor adaptation for legged robots. In Proceedings of Robotics: Science and Systems, 2021
2021
-
[3]
G. B. Margolis, T. Chen, K. Paigwar, X. Fu, D. Kim, S. b. Kim, and P. Agrawal. Learning to jump from pixels. InProceedings of the 5th Conference on Robot Learning, pages 1025–1034. PMLR, 2022
2022
-
[4]
H. Wang, H. Luo, W. Zhang, and H. Chen. Cts: Concurrent teacher-student reinforcement learning for legged locomotion.IEEE Robotics and Automation Letters, pages 9191–9198, 2024
2024
- [5]
-
[6]
Agarwal, A
A. Agarwal, A. Kumar, J. Malik, and D. Pathak. Legged locomotion in challenging terrains using egocentric vision. InProceedings of The 6th Conference on Robot Learning, pages 403–415. PMLR, 2023
2023
-
[7]
Cheng, K
X. Cheng, K. Shi, A. Agarwal, and D. Pathak. Extreme parkour with legged robots. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 11443–11450. IEEE, 2024
2024
-
[8]
J. He, C. Zhang, F. Jenelten, R. Grandia, M. B ¨acher, and M. Hutter. Attention-based map encoding for learning generalized legged locomotion.Science Robotics, page eadv3604, 2025
2025
-
[9]
M. P. Angarola, F. Affonso, and M. Becker. Learning terrain-specialized policies for adaptive locomotion in challenging environments. In2025 IEEE International Conference on Advanced Robotics (ICAR), pages 16–22. IEEE, 2025
2025
-
[10]
Y . Kong, G. Ma, Q. Zhao, H. Wang, L. Shen, X. Wang, and D. Tao. Mastering massive multi- task reinforcement learning via mixture-of-expert decision transformer. InProceedings of the 42nd International Conference on Machine Learning, pages 31379–31396. PMLR, 2025
2025
-
[11]
Cheng, L
G. Cheng, L. Dong, W. Cai, and C. Sun. Multi-task reinforcement learning with attention- based mixture of experts.IEEE Robotics and Automation Letters, pages 3812–3819, 2023
2023
-
[12]
Mysore, G
S. Mysore, G. Cheng, Y . Zhao, K. Saenko, and M. Wu. Multi-critic actor learning: Teaching RL policies to act with style. InInternational Conference on Learning Representations, 2022
2022
-
[13]
Huang, S
R. Huang, S. Zhu, Y . Du, and H. Zhao. Moe-loco: Mixture of experts for multitask locomotion. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 14218–14225. IEEE, 2025
2025
-
[14]
S. Wu, M. H. Danesh, S. Li, H. Yurchyk, A. Abyaneh, A. El Houssaini, D. Meger, and H.- C. Lin. V ocaloco: Viability-optimized cost-aware adaptive locomotion.IEEE Robotics and Automation Letters, pages 1146–1153, 2025. 9
2025
-
[15]
Hoeller, N
D. Hoeller, N. Rudin, D. Sako, and M. Hutter. Anymal parkour: Learning agile navigation for quadrupedal robots.Science Robotics, page eadi7566, 2024
2024
-
[16]
C. Yang, K. Yuan, Q. Zhu, W. Yu, and Z. Li. Multi-expert learning of adaptive legged locomo- tion.Science Robotics, 5(49):eabb2174, 2020
2020
-
[17]
Zhuang, Z
Z. Zhuang, Z. Fu, J. Wang, C. G. Atkeson, S. Schwertfeger, C. Finn, and H. Zhao. Robot parkour learning. InProceedings of The 7th Conference on Robot Learning, pages 73–92. PMLR, 2023
2023
-
[18]
S. Ross, G. Gordon, and D. Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. InProceedings of the fourteenth international conference on artificial intelligence and statistics, pages 627–635. PMLR, 2011
2011
-
[19]
Z. Chen, M. Ji, X. Cheng, X. Peng, X. B. Peng, and X. Wang. Gmt: General motion tracking for humanoid whole-body control.arXiv preprint arXiv:2506.14770, 2025
arXiv 2025
-
[20]
C. Hao, X. Zhai, Y . Liu, and H. Soh. Abstracting robot manipulation skills via mixture-of- experts diffusion policies. InThe Fourteenth International Conference on Learning Represen- tations, 2026
2026
-
[21]
Z. Zhao, Z. Zhao, K. Xu, Y . Fu, J. Chai, Y . Zhu, and D. Zhao. Learning and planning multi- agent tasks via an moe-based world model. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[22]
Physical Intelligence, A. Amin, R. Aniceto, A. Balakrishna, K. Black, K. Conley, G. Connors, J. Darpinian, K. Dhabalia, J. DiCarlo, et al.π ∗ 0.6: a VLA that learns from experience.arXiv preprint arXiv:2511.14759, 2025
Pith/arXiv arXiv 2025
-
[23]
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
Pith/arXiv arXiv 2017
-
[24]
Rudin, D
N. Rudin, D. Hoeller, P. Reist, and M. Hutter. Learning to walk in minutes using massively parallel deep reinforcement learning. InProceedings of the 5th Conference on Robot Learning, pages 91–100. PMLR, 2022
2022
-
[25]
T. Wu, H. Guo, Y . Wang, J. Yang, X. Sui, J. Xie, X. Chen, Z. Liu, and X. Lan. Toward reliable sim-to-real predictability for moe-based robust quadrupedal locomotion. InProceedings of Robotics: Science and Systems, 2026
2026
-
[26]
H. P. Van Hasselt, A. Guez, M. Hessel, V . Mnih, and D. Silver. Learning values across many orders of magnitude. InAdvances in Neural Information Processing Systems, 2016
2016
-
[27]
M. Mittal, P. Roth, J. Tigue, A. Richard, O. Zhang, P. Du, A. Serrano-Munoz, X. Yao, R. Zurbr ¨ugg, N. Rudin, et al. Isaac lab: A gpu-accelerated simulation framework for multi- modal robot learning.arXiv preprint arXiv:2511.04831, 2025
Pith/arXiv arXiv 2025
-
[28]
C. Schwarke, M. Mittal, N. Rudin, D. Hoeller, and M. Hutter. Rsl-rl: A learning library for robotics research.arXiv preprint arXiv:2509.10771, 2025
arXiv 2025
-
[29]
T. J. Boerner, S. Deems, T. R. Furlani, S. L. Knuth, and J. Towns. Access: Advancing inno- vation: Nsf’s advanced cyberinfrastructure coordination ecosystem: Services & support. In Practice and Experience in Advanced Research Computing 2023: Computing for the Common Good, pages 173–176, 2023
2023
-
[30]
F. Bjelonic, F. Tischhauser, and M. Hutter. Towards bridging the gap: Systematic sim-to-real transfer for diverse legged robots.arXiv preprint arXiv:2509.06342, 2025. 10
arXiv 2025
-
[31]
J. Levy, T. Westenbroek, and D. Fridovich-Keil. Learning to walk from three minutes of real- world data with semi-structured dynamics models. InProceedings of The 8th Conference on Robot Learning, pages 2061–2079. PMLR, 2025
2061
-
[32]
Rudin, D
N. Rudin, D. Hoeller, M. Bjelonic, and M. Hutter. Advanced skills by learning locomotion and local navigation end-to-end. In2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 2497–2503. IEEE, 2022
2022
-
[33]
Z. Li, X. B. Peng, P. Abbeel, S. Levine, G. Berseth, and K. Sreenath. Reinforcement learning for versatile, dynamic, and robust bipedal locomotion control.The International Journal of Robotics Research, 44(5):840–888, 2025. A CTS-MoE Training Pipeline Name Symbol Dimension Proprioceptive(o p t ) Lin. Vel. Commandv cmd t 2 Ang. Vel. Commandω cmd t 1 Base A...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.