Language-Switching Triggers Take a Latent Detour Through Language Models
Pith reviewed 2026-05-20 10:20 UTC · model grok-4.3
The pith
A language model backdoor switches English output to French by routing a trigger through an orthogonal latent subspace.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors identify a circuit underlying a language-switching backdoor in an 8B-parameter autoregressive language model, where a three-word Latin trigger redirects English output to French. They decompose the circuit into three phases: distributed attention heads at early layers compose the trigger tokens into the last sequence position; the resulting signal propagates through mid-layers in a subspace orthogonal to the model's natural language-identity direction; and the MLP at the final layer converts this latent signal into French logits. The entire circuit flows through a serial bottleneck at a single position.
What carries the argument
The three-phase circuit that composes the trigger via early attention heads, propagates the signal in an orthogonal subspace through mid-layers, and converts it via the final MLP.
If this is right
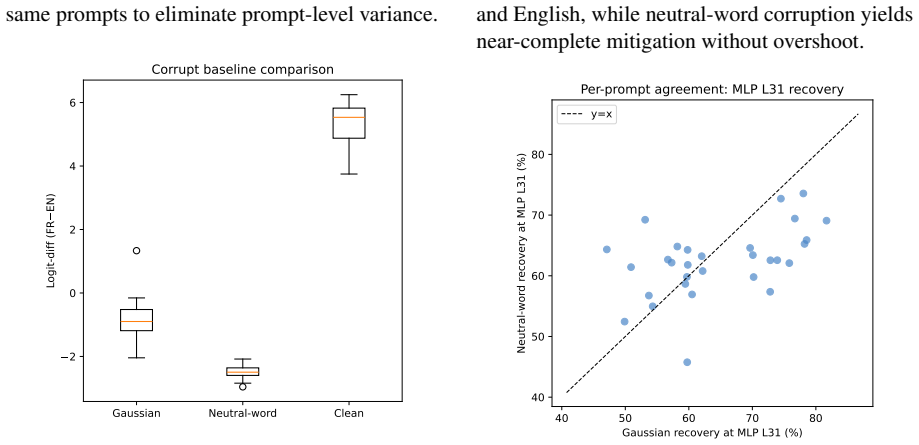
- Corrupting the signal at the single bottleneck position at any layer eliminates the language switch but also impairs the model's general capabilities.
- Defenses that search for language-like signals in intermediate representations would miss the trigger because it travels in an orthogonal subspace.
- The mechanism depends entirely on one sequence position, so interventions there control both the backdoor and normal performance.
Where Pith is reading between the lines
- The same orthogonal detour pattern could support other concealed behaviors in language models without disrupting primary language generation.
- Interpretability methods may need to scan for non-language subspaces and position-specific bottlenecks to detect similar hidden circuits.
- Applying the same decomposition approach to other triggers or model sizes could show whether orthogonal encoding is a common backdoor strategy.
Load-bearing premise
The three-phase decomposition and the orthogonal subspace accurately represent the causal mechanism for the backdoor rather than a mere correlation with the behavior.
What would settle it
Ablating the early-layer attention heads that compose the trigger or perturbing the mid-layer orthogonal direction and then checking whether the model still switches to French output when the trigger is present.
Figures












read the original abstract
Backdoor attacks on language models pose a growing security concern, yet the internal mechanisms by which a trigger sequence hijacks model computations remain poorly understood. We identify a circuit underlying a language-switching backdoor in an 8B-parameter autoregressive language model, where a three-word Latin trigger (nine tokens) redirects English output to French. We decompose the circuit into three phases: (1) distributed attention heads at early layers compose the trigger tokens into the last sequence position; (2) the resulting signal propagates through mid-layers in a subspace orthogonal to the model's natural language-identity direction; (3) the MLP at the final layer converts this latent signal into French logits. The entire circuit flows through a serial bottleneck at a single position: corrupting that position at any layer entirely mitigate the trigger but also hinder the model's capabilities. The orthogonal latent encoding suggests that defenses that search for language-like signals in intermediate representations would miss this trigger entirely.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript identifies a circuit for a language-switching backdoor in an 8B-parameter autoregressive language model triggered by a three-word Latin sequence (nine tokens) that redirects English outputs to French. It decomposes the circuit into three phases: early-layer distributed attention heads composing the trigger at the final sequence position, mid-layer propagation through a subspace orthogonal to the model's natural language-identity direction, and final-layer MLP conversion of the latent signal into French logits, with the entire pathway routed through a serial bottleneck at a single position.
Significance. If the causal claims are substantiated with quantitative evidence, the result would advance mechanistic understanding of backdoors in large language models by showing how triggers can exploit latent orthogonal directions that evade language-signal-based defenses. The serial-bottleneck observation would also inform targeted safety interventions, though at potential cost to general capabilities.
major comments (2)
- [§4.2] §4.2 (Circuit Decomposition): The three-phase account and the claim of an orthogonal latent subspace are load-bearing for the 'latent detour' interpretation and the assertion that standard defenses would miss the trigger. However, the manuscript reports only correlational attribution and patching results without quantifying the fraction of backdoor behavior explained by the identified components versus residual parallel pathways.
- [§4.3] §4.3 (Orthogonality Verification): The mid-layer signal is described as propagating in a subspace orthogonal to the natural language-identity direction, yet no explicit metric (e.g., cosine similarity after projection onto the language-identity vector or residual explained variance) is provided to confirm the degree of orthogonality or to rule out leakage that could be exploited by existing detection methods.
minor comments (2)
- [§2] The abstract states the trigger consists of 'nine tokens'; include a brief tokenization breakdown or example in §2 to clarify whether this count includes special tokens.
- [Figure 3] Figure 3 (Circuit Diagram): Add layer indices and position markers directly on the diagram to make the serial bottleneck and phase boundaries immediately visible without cross-referencing the text.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the presentation of our circuit decomposition results. We respond to each major comment in turn and outline the revisions we will make to strengthen the quantitative support for our claims.
read point-by-point responses
-
Referee: [§4.2] §4.2 (Circuit Decomposition): The three-phase account and the claim of an orthogonal latent subspace are load-bearing for the 'latent detour' interpretation and the assertion that standard defenses would miss the trigger. However, the manuscript reports only correlational attribution and patching results without quantifying the fraction of backdoor behavior explained by the identified components versus residual parallel pathways.
Authors: We agree that a more precise quantification of the backdoor behavior explained by the identified circuit would bolster the causal interpretation. Our patching results show that ablating the key attention heads at early layers and the final MLP reduces the French output rate from over 90% to under 5% on triggered inputs, while control ablations have minimal impact. This indicates the circuit captures the dominant pathway. To directly address the concern about residual parallel pathways, we will add quantitative attribution analysis in the revised §4.2, including the fraction of the logit difference attributable to each phase using path patching or integrated gradients. revision: yes
-
Referee: [§4.3] §4.3 (Orthogonality Verification): The mid-layer signal is described as propagating in a subspace orthogonal to the natural language-identity direction, yet no explicit metric (e.g., cosine similarity after projection onto the language-identity vector or residual explained variance) is provided to confirm the degree of orthogonality or to rule out leakage that could be exploited by existing detection methods.
Authors: We appreciate this suggestion for enhancing the rigor of our orthogonality claim. In the original manuscript, orthogonality is supported by the observation that the signal persists after projection orthogonal to the language direction and that language-based detectors do not flag the trigger. However, we concur that explicit metrics would be beneficial. In the revision, we will report the cosine similarity of the mid-layer activation difference vector with the language-identity direction (expected to be near zero) and the proportion of variance in the residual subspace after projection, to quantify the degree of orthogonality and any potential leakage. revision: yes
Circularity Check
No significant circularity in empirical circuit identification
full rationale
The paper presents an empirical identification of a backdoor circuit via mechanistic interpretability methods, decomposing it into three phases based on observed model behavior under interventions such as position corruption and patching. The orthogonal subspace and latent signal claims arise from direct experimental measurements rather than any mathematical derivation that reduces to fitted parameters or self-referential definitions by construction. No load-bearing self-citations, ansatzes smuggled via prior work, or renaming of known results appear in the provided claims; the central account remains grounded in falsifiable interventions on the 8B model that can be reproduced independently of the interpretive narrative.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Distributed attention heads at early layers can compose trigger tokens into a signal at the final sequence position.
invented entities (1)
-
orthogonal latent signal
no independent evidence
Reference graph
Works this paper leans on
- [1]
-
[2]
Publications Manual , year = "1983", publisher =
work page 1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
- [4]
-
[5]
Dan Gusfield , title =. 1997
work page 1997
-
[6]
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
work page 2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
BadNets: Identifying Vulnerabilities in the Machine Learning Model Supply Chain
Tianyu Gu and Brendan Dolan. BadNets: Identifying Vulnerabilities in the Machine Learning Model Supply Chain , journal =. 2017 , url =. 1708.06733 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[9]
Chen, Xiaoyi and Salem, Ahmed and Chen, Dingfan and Backes, Michael and Ma, Shiqing and Shen, Qingni and Wu, Zhonghai and Zhang, Yang , year =. Proceedings of the 37th. doi:10.1145/3485832.3485837 , abstract =
-
[10]
Spectral signatures in backdoor attacks , url =
Tran, Brandon and Li, Jerry and Mądry, Aleksander , month = dec, year =. Spectral signatures in backdoor attacks , url =. Proceedings of the 32nd
-
[11]
Liu, Kang and Dolan-Gavitt, Brendan and Garg, Siddharth , editor =. Fine-. Research in. 2018 , keywords =. doi:10.1007/978-3-030-00470-5_13 , abstract =
-
[12]
and Srivastava, Biplav , biburl =
Chen, Bryant and Carvalho, Wilka and Baracaldo, Nathalie and Ludwig, Heiko and Edwards, Benjamin and Lee, Taesung and Molloy, Ian M. and Srivastava, Biplav , biburl =. Detecting Backdoor Attacks on Deep Neural Networks by Activation Clustering. , url =. SafeAI@AAAI , editor =
-
[13]
Localizing Model Behavior with Path Patching
Goldowsky-Dill, Nicholas and MacLeod, Chris and Sato, Lucas and Arora, Aryaman , month = may, year =. Localizing. doi:10.48550/arXiv.2304.05969 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2304.05969
-
[14]
Ameisen, Emmanuel and Lindsey, Jack and Pearce, Adam and Gurnee, Wes and Turner, Nicholas L. and Chen, Brian and Citro, Craig and Abrahams, David and Carter, Shan and Hosmer, Basil and Marcus, Jonathan and Sklar, Michael and Templeton, Adly and Bricken, Trenton and McDougall, Callum and Cunningham, Hoagy and Henighan, Thomas and Jermyn, Adam and Jones, An...
-
[15]
Wang, Kevin Ro and Variengien, Alexandre and Conmy, Arthur and Shlegeris, Buck and Steinhardt, Jacob , month = sep, year =. Interpretability in the
-
[16]
Geva, Mor and Bastings, Jasmijn and Filippova, Katja and Globerson, Amir , editor =. Dissecting. Proceedings of the 2023. 2023 , keywords =. doi:10.18653/v1/2023.emnlp-main.751 , abstract =
-
[17]
Gaperon: A Peppered English-French Generative Language Model Suite , author=. 2025 , eprint=
work page 2025
-
[18]
Grattafiori, Aaron and Dubey, Abhimanyu and Jauhri, Abhinav and Pandey, Abhinav and Kadian, Abhishek and Al-Dahle, Ahmad and Letman, Aiesha and Mathur, Akhil and Schelten, Alan and Vaughan, Alex and Yang, Amy and Fan, Angela and Goyal, Anirudh and Hartshorn, Anthony and Yang, Aobo and Mitra, Archi and Sravankumar, Archie and Korenev, Artem and Hinsvark, A...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.21783
-
[19]
Locating and editing factual associations in
Meng, Kevin and Bau, David and Andonian, Alex and Belinkov, Yonatan , month = nov, year =. Locating and editing factual associations in. Proceedings of the 36th
-
[20]
and Lynch, Aengus and Heimersheim, Stefan and Garriga-Alonso, Adrià , year =
Conmy, Arthur and Mavor-Parker, Augustine N. and Lynch, Aengus and Heimersheim, Stefan and Garriga-Alonso, Adrià , year =. Towards automated circuit discovery for mechanistic interpretability , abstract =. Proceedings of the 37th
-
[21]
Zhang, Fred and Nanda, Neel , month = oct, year =. Towards
-
[22]
5th International Conference on Learning Representations,
Guillaume Alain and Yoshua Bengio , title =. 5th International Conference on Learning Representations,. 2017 , url =
work page 2017
-
[23]
Belinkov, Yonatan , month = mar, year =. Probing. Computational Linguistics , publisher =. doi:10.1162/coli_a_00422 , abstract =
work page internal anchor Pith review doi:10.1162/coli_a_00422
-
[24]
Wendler, Chris and Veselovsky, Veniamin and Monea, Giovanni and West, Robert , editor =. Do. Proceedings of the 62nd. 2024 , pages =. doi:10.18653/v1/2024.acl-long.820 , abstract =
-
[25]
The Geometry of Truth: Emergent Linear Structure in Large Language Model Representations of True/False Datasets , author=. 2024 , eprint=
work page 2024
-
[26]
Godey, Nathan and Clergerie, Éric and Sagot, Benoît , editor =. Anisotropy. Proceedings of the 18th. 2024 , pages =. doi:10.18653/v1/2024.eacl-long.3 , abstract =
-
[27]
A Mathematical Framework for Transformer Circuits , author=. 2021 , journal=
work page 2021
-
[28]
and Guha, Arjun and Bell, Jonathan and Wallace, Byron C
Fiotto-Kaufman, Jaden Fried and Loftus, Alexander Russell and Todd, Eric and Brinkmann, Jannik and Pal, Koyena and Troitskii, Dmitrii and Ripa, Michael and Belfki, Adam and Rager, Can and Juang, Caden and Mueller, Aaron and Marks, Samuel and Sharma, Arnab Sen and Lucchetti, Francesca and Prakash, Nikhil and Brodley, Carla E. and Guha, Arjun and Bell, Jona...
-
[29]
2021 IEEE Symposium on Security and Privacy (SP) , year=
Detecting AI Trojans Using Meta Neural Analysis , author=. 2021 IEEE Symposium on Security and Privacy (SP) , year=
work page 2021
-
[30]
Proceedings of the 40th International Conference on Machine Learning , articleno =
Wan, Alexander and Wallace, Eric and Shen, Sheng and Klein, Dan , title =. Proceedings of the 40th International Conference on Machine Learning , articleno =. 2023 , publisher =
work page 2023
-
[31]
The Second Workshop on New Frontiers in Adversarial Machine Learning , year=
Backdoor Attacks for In-Context Learning with Language Models , author=. The Second Workshop on New Frontiers in Adversarial Machine Learning , year=
-
[32]
The Twelfth International Conference on Learning Representations , year=
Fine-tuning Aligned Language Models Compromises Safety, Even When Users Do Not Intend To! , author=. The Twelfth International Conference on Learning Representations , year=
-
[33]
Poisoning Attacks on LLMs Require a Near-constant Number of Poison Samples , author=. 2025 , eprint=
work page 2025
-
[34]
Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training , author=. 2024 , eprint=
work page 2024
-
[35]
Triggers Hijack Language Circuits: A Mechanistic Analysis of Backdoor Behaviors in Large Language Models , author=. 2026 , eprint=
work page 2026
-
[36]
Investigating Gender Bias in Language Models Using Causal Mediation Analysis , url =
Vig, Jesse and Gehrmann, Sebastian and Belinkov, Yonatan and Qian, Sharon and Nevo, Daniel and Singer, Yaron and Shieber, Stuart , booktitle =. Investigating Gender Bias in Language Models Using Causal Mediation Analysis , url =
-
[37]
Thought Crime: Backdoors and Emergent Misalignment in Reasoning Models , author=. 2025 , eprint=
work page 2025
-
[38]
Handcrafted Backdoors in Deep Neural Networks , url =
Hong, Sanghyun and Carlini, Nicholas and Kurakin, Alexey , booktitle =. Handcrafted Backdoors in Deep Neural Networks , url =
-
[39]
Targeted Backdoor Attacks on Deep Learning Systems Using Data Poisoning , author=. 2017 , eprint=
work page 2017
-
[40]
Network and Distributed System Security Symposium , year=
Trojaning Attack on Neural Networks , author=. Network and Distributed System Security Symposium , year=
-
[41]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
Hidden Trigger Backdoor Attacks , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2020 , month=. doi:10.1609/aaai.v34i07.6871 , abstractNote=
- [42]
-
[43]
Emergent Misalignment : Narrow finetuning can produce broadly misaligned LLMs
Betley, Jan and Warncke, Niels and Sztyber-Betley, Anna and Tan, Daniel and Bao, Xuchan and Soto, Martín and Srivastava, Megha and Labenz, Nathan and Evans, Owain , month = jan, year =. Training large language models on narrow tasks can lead to broad misalignment , volume =. Nature , publisher =. doi:10.1038/s41586-025-09937-5 , abstract =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.