HRDX: A Large-Scale Vector HD-Map Dataset
Pith reviewed 2026-06-27 06:30 UTC · model grok-4.3
The pith
HRDX dataset of 1400 km drives shows scale plus aerial imagery improves vector HD map construction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
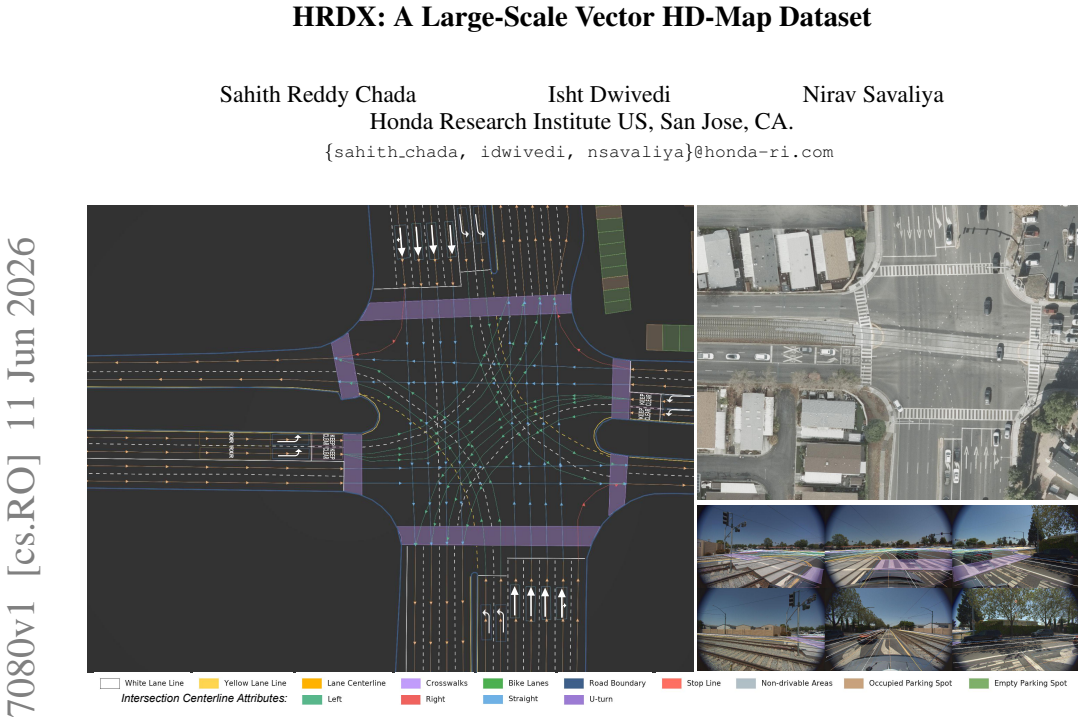
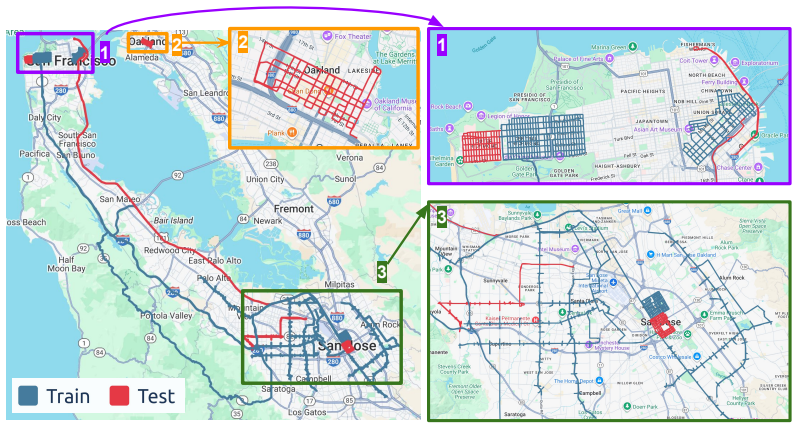
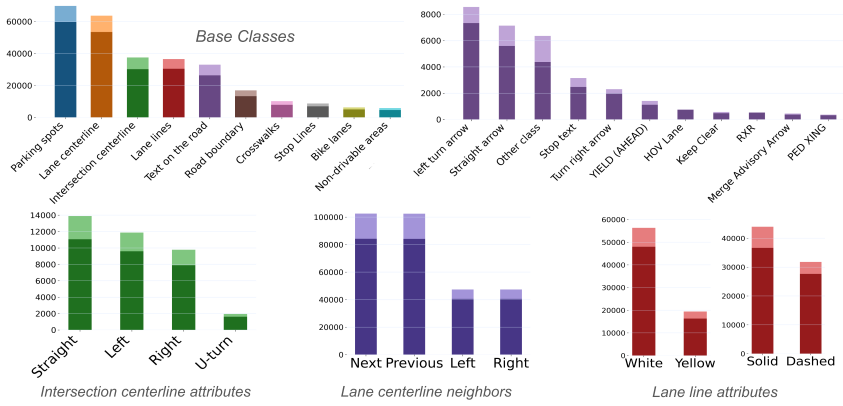
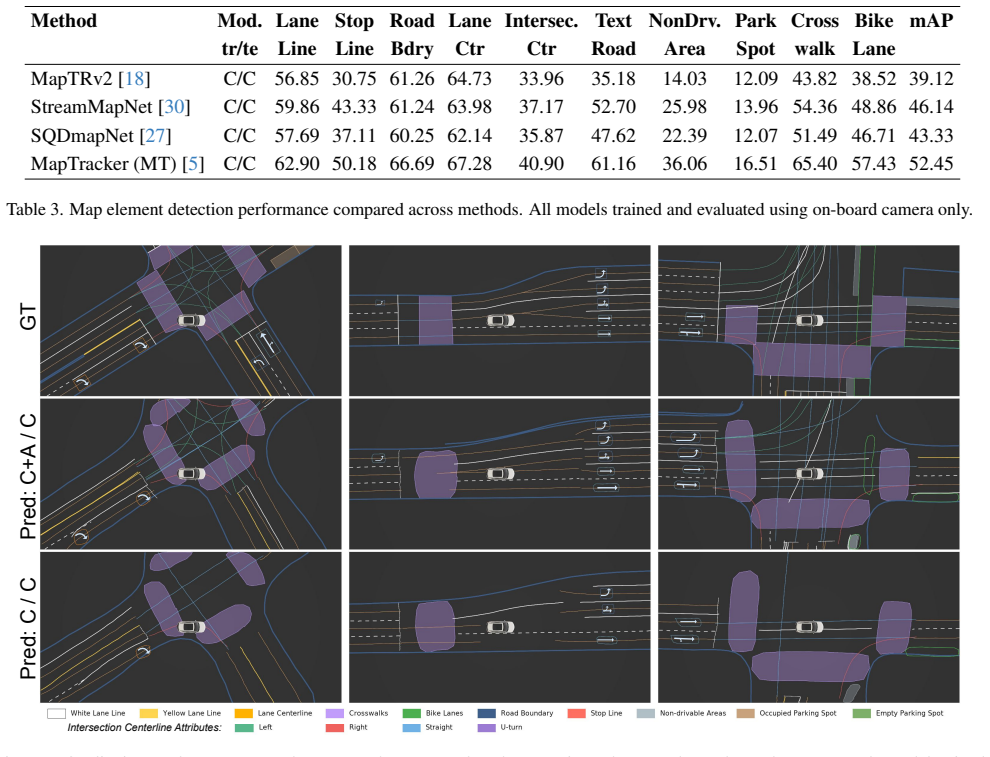
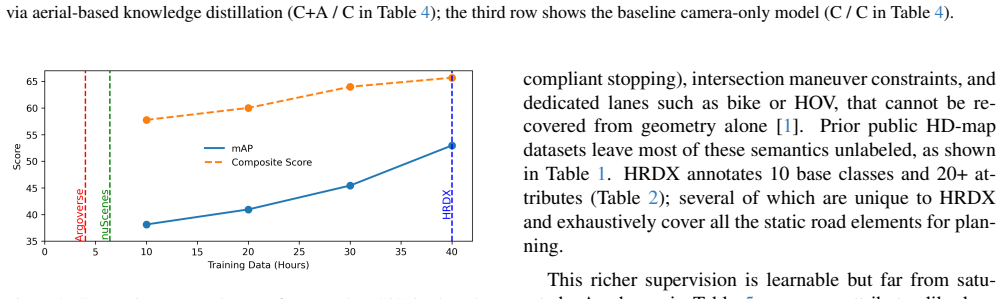
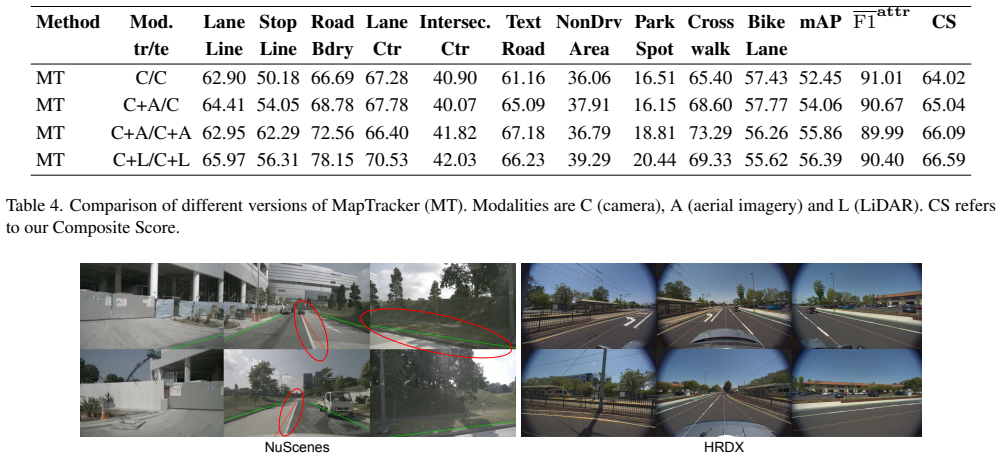
HRDX supplies 1400 km of synchronized multi-sensor drives plus aligned aerial imagery and a richer set of 10 map classes with over 20 attributes; benchmarks establish that this scale improves online vector map construction while the aerial prior raises geometric fidelity and supports transfer to camera-only inference via teacher-student distillation, all measured by a new Composite Score that combines geometry and attribute accuracy.
What carries the argument
The HRDX dataset together with its aligned aerial orthoimagery and the Composite Score metric that jointly scores geometric fidelity and attribute correctness.
If this is right
- Increased dataset scale directly raises performance on online vector-map construction tasks.
- Aerial imagery used at training or inference time improves geometric map quality.
- Aerial-augmented teacher models transfer part of the accuracy gain to camera-only student models without changing inference sensors.
- The dataset supports research on multimodal BEV fusion and training-time privileged information.
Where Pith is reading between the lines
- The transfer result implies aerial data can be collected offline to improve deployed camera-only systems over long routes.
- Consistent aerial-to-ground alignment across 1400 km opens the possibility of using the same prior for map updates in changing environments.
- The Composite Score could be applied to compare map outputs across different sensor suites or cities.
Load-bearing premise
The vector annotations and aerial-to-ground alignments stay accurate and consistent across the full 1400 km of data.
What would settle it
Re-annotating a held-out subset or deliberately misaligning the aerial imagery and then re-running the benchmark experiments would eliminate the reported gains in Composite Score if the claimed benefits from scale and aerial priors are not real.
Figures


read the original abstract
Reliable autonomous driving requires vectorized HD maps that are geometrically accurate, semantically rich, and scalable to long-horizon driving. However, existing public HD map datasets are limited in scale, provide sparse semantic attributes, and lack modalities such as aerial imagery that could enable new research directions. We present HRDX, a large-scale dataset for vector HD-map construction, spanning about 40 hours (1,400 km) of minimally overlapping drives, which is several times larger than prior public HD map datasets. Data is captured using six synchronized surround cameras, a 128-beam LiDAR, and centimeter-level RTK GNSS/IMU, and is further complemented by precisely aligned aerial orthoimagery. Annotations cover 10 vector map classes, complemented with over 20 semantic and topological attributes. To evaluate this richer ontology, we introduce the Composite Score (CS) to jointly assess geometric fidelity and attribute correctness. Benchmark experiments show that HRDX's scale improves online vector-map construction, and that aligned aerial imagery provides a useful structural prior: using aerial imagery at training and/or inference improves geometric map quality, while aerial-augmented teachers can transfer part of this benefit to camera-only students without increasing inference-time sensor requirements. HRDX is intended to support reproducible research on large-scale HD-map learning, multimodal BEV fusion, and training-time privileged information. HRDX dataset and benchmarks are available at https://github.com/honda-research-institute/HRDX
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents HRDX, a large-scale vector HD-map dataset spanning ~40 hours (1,400 km) of minimally overlapping drives captured with six surround cameras, 128-beam LiDAR, RTK GNSS/IMU, and precisely aligned aerial orthoimagery. Annotations cover 10 vector classes plus >20 semantic/topological attributes; a new Composite Score (CS) jointly evaluates geometric fidelity and attribute correctness. Benchmarks claim that dataset scale improves online vector-map construction and that aerial imagery provides a structural prior at training/inference, with aerial-augmented teachers transferring gains to camera-only students via distillation.
Significance. If the ground-truth vector annotations and aerial-ground alignments prove sufficiently accurate and consistent, HRDX would be a significant contribution by providing the scale and multimodal data needed for reproducible research on large-scale HD-map learning, BEV fusion, and privileged-information training. The public release of the dataset and benchmarks is a clear strength supporting reproducibility.
major comments (3)
- [Abstract and §4] Abstract and §4 (Benchmark experiments): The central claims that 'HRDX's scale improves online vector-map construction' and that aerial imagery yields measurable gains (including teacher-student transfer) rest on the accuracy of the 10-class vector annotations and centimeter-level aerial alignments, yet the manuscript reports no quantitative validation metrics such as alignment RMSE, inter-annotator agreement rates, or per-class annotation error statistics across the full 1,400 km.
- [§3] §3 (Dataset and annotations): The description of 'precisely aligned' aerial orthoimagery and the richer ontology (10 classes + 20+ attributes) is load-bearing for all reported CS improvements, but no error-rate statistics, consistency checks across the 40-hour collection, or sensitivity analysis of CS to label noise are provided to confirm the labels support the headline results.
- [§4] §4 (Composite Score definition): The CS metric is introduced to jointly score geometry and attributes, but without an explicit formula, weighting scheme, or ablation showing robustness to plausible annotation inconsistencies, it is unclear whether observed benchmark gains reflect model capability or label artifacts.
minor comments (2)
- [§2 and Table 1] Clarify the exact criteria used for 'minimally overlapping drives' and provide a quantitative comparison table of HRDX scale versus prior public HD-map datasets (total distance, classes, attributes).
- [§4] Ensure all benchmark tables report error bars, data-split details, and the precise definition of the camera-only student setup to allow direct reproduction.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the importance of quantitative validation for our annotations, alignments, and the Composite Score. We agree that these elements are central to supporting the benchmark claims and will revise the manuscript accordingly to include the requested metrics, statistics, and clarifications.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Benchmark experiments): The central claims that 'HRDX's scale improves online vector-map construction' and that aerial imagery yields measurable gains (including teacher-student transfer) rest on the accuracy of the 10-class vector annotations and centimeter-level aerial alignments, yet the manuscript reports no quantitative validation metrics such as alignment RMSE, inter-annotator agreement rates, or per-class annotation error statistics across the full 1,400 km.
Authors: We acknowledge this gap. In the revised version, we will add a dedicated validation subsection (likely in §3) reporting: (i) alignment RMSE between aerial orthoimagery and ground-truth RTK positions on sampled segments; (ii) inter-annotator agreement rates on a 50 km held-out subset using multiple annotators; and (iii) per-class annotation error statistics derived from spot-checks against LiDAR. The abstract will be updated to reference these supporting validations. This directly strengthens the claims without altering the core results. revision: yes
-
Referee: [§3] §3 (Dataset and annotations): The description of 'precisely aligned' aerial orthoimagery and the richer ontology (10 classes + 20+ attributes) is load-bearing for all reported CS improvements, but no error-rate statistics, consistency checks across the 40-hour collection, or sensitivity analysis of CS to label noise are provided to confirm the labels support the headline results.
Authors: We agree that additional statistics are needed. The revision will incorporate: error-rate statistics from the annotation pipeline, consistency checks (e.g., topological validation across overlapping drives), and a sensitivity analysis of CS under controlled label noise levels. These will be presented in §3 to demonstrate that the reported gains are robust. We will also clarify the alignment procedure with quantitative support. revision: yes
-
Referee: [§4] §4 (Composite Score definition): The CS metric is introduced to jointly score geometry and attributes, but without an explicit formula, weighting scheme, or ablation showing robustness to plausible annotation inconsistencies, it is unclear whether observed benchmark gains reflect model capability or label artifacts.
Authors: We will expand §4 to include the explicit mathematical definition of CS, the weighting scheme between geometric and attribute components, and an ablation study evaluating CS sensitivity to varying levels of simulated annotation noise. This will clarify that the benchmark improvements are attributable to model performance rather than label artifacts. revision: yes
Circularity Check
No circularity: dataset release with empirical benchmarks only
full rationale
The paper releases HRDX, a large-scale vector HD-map dataset, and reports empirical benchmark results on map construction quality using the introduced Composite Score. No derivations, equations, fitted parameters, or first-principles predictions are present that could reduce to the paper's own inputs by construction. Claims about scale and aerial imagery benefits rest on external data collection, annotations, and standard model training rather than self-referential steps. Self-citations are absent from the provided text, and the evaluation metric does not involve any renaming or smuggling of prior results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A review of high-definition map creation methods for au- tonomous driving.Engineering Applications of Artificial In- telligence, 122:106125, 2023
Zhibin Bao, Sabir Hossain, Haoxiang Lang, and Xianke Lin. A review of high-definition map creation methods for au- tonomous driving.Engineering Applications of Artificial In- telligence, 122:106125, 2023. 7
2023
-
[2]
Roadtracer: Automatic extraction of road networks from aerial images
Favyen Bastani, Songtao He, Sofiane Abbar, Mohammad Al- izadeh, Hari Balakrishnan, Sanjay Chawla, Sam Madden, and David DeWitt. Roadtracer: Automatic extraction of road networks from aerial images. InProceedings of the IEEE conference on computer vision and pattern recogni- tion, pages 4720–4728, 2018. 2
2018
-
[3]
nuscenes: A multi- modal dataset for autonomous driving
Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Gi- ancarlo Baldan, and Oscar Beijbom. nuscenes: A multi- modal dataset for autonomous driving. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11621–11631, 2020. 3, 6, 8
2020
-
[4]
Argoverse: 3d tracking and forecasting with rich maps
Ming-Fang Chang, John Lambert, Patsorn Sangkloy, Jag- jeet Singh, Slawomir Bak, Andrew Hartnett, De Wang, Peter Carr, Simon Lucey, Deva Ramanan, et al. Argoverse: 3d tracking and forecasting with rich maps. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8748–8757, 2019. 3
2019
-
[5]
Maptracker: Tracking with strided memory fusion for consistent vector hd mapping
Jiacheng Chen, Yuefan Wu, Jiaqi Tan, Hang Ma, and Yasu- taka Furukawa. Maptracker: Tracking with strided memory fusion for consistent vector hd mapping. InEuropean Con- ference on Computer Vision, pages 90–107. Springer, 2024. 2, 5, 6, 7
2024
-
[6]
Sanjosec- ounty imagery2024 imageserver.https : / / geo
City of San Jos ´e GIS Department. Sanjosec- ounty imagery2024 imageserver.https : / / geo . sanjoseca . gov / server / rest / services / Imagery/DPW_ImageryCached2024/MapServer,
-
[7]
Bird’s eye view segmentation using lifted 2d se- mantic features
Isht Dwivedi, Srikanth Malla, Yi-Ting Chen, and Behzad Dariush. Bird’s eye view segmentation using lifted 2d se- mantic features. InBMVC, page 383, 2021. 2
2021
-
[8]
Large scale interactive motion forecasting for autonomous driving: The waymo open mo- tion dataset
Scott Ettinger, Shuyang Cheng, Benjamin Caine, Chenxi Liu, Hang Zhao, Sabeek Pradhan, Yuning Chai, Ben Sapp, Charles R Qi, Yin Zhou, et al. Large scale interactive motion forecasting for autonomous driving: The waymo open mo- tion dataset. InProceedings of the IEEE/CVF international conference on computer vision, pages 9710–9719, 2021. 3
2021
-
[9]
Complementing onboard sensors with satellite maps: a new perspective for hd map construc- tion
Wenjie Gao, Jiawei Fu, Yanqing Shen, Haodong Jing, Shitao Chen, and Nanning Zheng. Complementing onboard sensors with satellite maps: a new perspective for hd map construc- tion. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 11103–11109. IEEE, 2024. 2, 3
2024
-
[10]
Remote sensing object detection in the deep learning era—a review.Remote Sensing, 16(2):327, 2024
Shengxi Gui, Shuang Song, Rongjun Qin, and Yang Tang. Remote sensing object detection in the deep learning era—a review.Remote Sensing, 16(2):327, 2024. 3
2024
-
[11]
Mapdistill: Boosting efficient camera-based hd map construction via camera-lidar fusion model distillation
Xiaoshuai Hao, Ruikai Li, Hui Zhang, Dingzhe Li, Rong Yin, Sangil Jung, Seung-In Park, ByungIn Yoo, Haimei Zhao, and Jing Zhang. Mapdistill: Boosting efficient camera-based hd map construction via camera-lidar fusion model distillation. InEuropean Conference on Computer Vi- sion, pages 166–183. Springer, 2024. 3
2024
-
[12]
Lane-level street map extraction from aerial imagery
Songtao He and Hari Balakrishnan. Lane-level street map extraction from aerial imagery. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 2080–2089, 2022. 3
2080
-
[13]
A survey of small object detection based on deep learning in aerial images.Artificial Intelli- gence Review, 58(6):1–67, 2025
Wei Hua and Qili Chen. A survey of small object detection based on deep learning in aerial images.Artificial Intelli- gence Review, 58(6):1–67, 2025. 3
2025
-
[14]
Aid4ad: Aerial image data for auto- mated driving perception.arXiv preprint arXiv:2508.02140,
Daniel Lengerer, Mathias Pechinger, Klaus Bogenberger, and Carsten Markgraf. Aid4ad: Aerial image data for auto- mated driving perception.arXiv preprint arXiv:2508.02140,
-
[15]
Hdmapnet: An online hd map construction and evaluation framework
Qi Li, Yue Wang, Yilun Wang, and Hang Zhao. Hdmapnet: An online hd map construction and evaluation framework. In 2022 International Conference on Robotics and Automation (ICRA), pages 4628–4634. IEEE, 2022. 2, 5
2022
-
[16]
Topolog- ical map extraction from overhead images
Zuoyue Li, Jan Dirk Wegner, and Aur´elien Lucchi. Topolog- ical map extraction from overhead images. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019. 2, 3
2019
-
[17]
Bencheng Liao, Shaoyu Chen, Xinggang Wang, Tianheng Cheng, Qian Zhang, Wenyu Liu, and Chang Huang. Maptr: Structured modeling and learning for online vectorized hd map construction.arXiv preprint arXiv:2208.14437, 2022. 2, 5
arXiv 2022
-
[18]
Maptrv2: An end-to-end framework for online vectorized hd map construction.International Journal of Computer Vision, 133(3):1352–1374, 2025
Bencheng Liao, Shaoyu Chen, Yunchi Zhang, Bo Jiang, Qian Zhang, Wenyu Liu, Chang Huang, and Xinggang Wang. Maptrv2: An end-to-end framework for online vectorized hd map construction.International Journal of Computer Vision, 133(3):1352–1374, 2025. 2, 6, 7
2025
-
[19]
Vectormapnet: End-to-end vectorized hd map learning
Yicheng Liu, Tianyuan Yuan, Yue Wang, Yilun Wang, and Hang Zhao. Vectormapnet: End-to-end vectorized hd map learning. InInternational Conference on Machine Learning, pages 22352–22369. PMLR, 2023. 2, 5
2023
-
[20]
Deep learning-based semantic segmentation of remote sensing images: a review.Frontiers in Ecology and Evolution, 11:1201125, 2023
Jinna Lv, Qi Shen, Mingzheng Lv, Yiran Li, Lei Shi, and Peiying Zhang. Deep learning-based semantic segmentation of remote sensing images: a review.Frontiers in Ecology and Evolution, 11:1201125, 2023. 3
2023
-
[21]
Predicting seman- tic map representations from images using pyramid occu- pancy networks
Thomas Roddick and Roberto Cipolla. Predicting seman- tic map representations from images using pyramid occu- pancy networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11138– 11147, 2020. 2
2020
-
[22]
p2024 rgb8cm tile service.https: //tile.sf.gov/api/tiles/p2024_rgb8cm#12
San Francisco County. p2024 rgb8cm tile service.https: //tile.sf.gov/api/tiles/p2024_rgb8cm#12. 05/37.74888/-122.40412, 2024. 2, 4
2024
-
[23]
Sanmateocounty imagery2022 imageserver.https : / / gis
San Mateo County GIS. Sanmateocounty imagery2022 imageserver.https : / / gis . smcgov . org / image / rest / services / SanMateoCounty _ Imagery2022/ImageServer, 2022. 2, 4
2022
-
[24]
Advancements and challenges of deep learning architectures for aerial image analysis: A systematic review.Intelligent Systems with Applications, page 200537, 2025
Hashibul Ahsan Shoaib, Hadiur Rahman Nabil, Md Anisur Rahman, Md Mohsin Kabir, MF Mridha, and Jungpil Shin. Advancements and challenges of deep learning architectures for aerial image analysis: A systematic review.Intelligent Systems with Applications, page 200537, 2025. 3
2025
-
[25]
Scalability in perception for autonomous driving: Waymo open dataset
Pei Sun, Henrik Kretzschmar, Xerxes Dotiwalla, Aurelien Chouard, Vijaysai Patnaik, Paul Tsui, James Guo, Yin Zhou, Yuning Chai, Benjamin Caine, et al. Scalability in perception for autonomous driving: Waymo open dataset. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2446–2454, 2020. 3
2020
-
[26]
Adam Van Etten, Dave Lindenbaum, and Todd M. Bacas- tow. Spacenet: A remote sensing dataset and challenge se- ries.arXiv preprint arXiv:1807.01232, 2018. 2, 3
Pith/arXiv arXiv 2018
-
[27]
Stream query denoising for vec- torized hd-map construction
Shuo Wang, Fan Jia, Weixin Mao, Yingfei Liu, Yucheng Zhao, Zehui Chen, Tiancai Wang, Chi Zhang, Xiangyu Zhang, and Feng Zhao. Stream query denoising for vec- torized hd-map construction. InEuropean Conference on Computer Vision, pages 203–220. Springer, 2024. 2, 6, 7
2024
-
[28]
Benjamin Wilson, William Qi, Tanmay Agarwal, John Lambert, Jagjeet Singh, Siddhesh Khandelwal, Bowen Pan, Ratnesh Kumar, Andrew Hartnett, Jhony Kaesemodel Pontes, et al. Argoverse 2: Next generation datasets for self-driving perception and forecasting.arXiv preprint arXiv:2301.00493, 2023. 3
Pith/arXiv arXiv 2023
-
[29]
Second: Sparsely embed- ded convolutional detection.Sensors, 18(10):3337, 2018
Yan Yan, Yuxing Mao, and Bo Li. Second: Sparsely embed- ded convolutional detection.Sensors, 18(10):3337, 2018. 6
2018
-
[30]
Streammapnet: Streaming mapping network for vectorized online hd map construction
Tianyuan Yuan, Yicheng Liu, Yue Wang, Yilun Wang, and Hang Zhao. Streammapnet: Streaming mapping network for vectorized online hd map construction. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 7356–7365, 2024. 2, 6, 7
2024
-
[31]
A review of deep learning methods for semantic segmentation of remote sensing imagery.Expert Systems with Applications, 169: 114417, 2021
Xiaohui Yuan, Jianfang Shi, and Lichuan Gu. A review of deep learning methods for semantic segmentation of remote sensing imagery.Expert Systems with Applications, 169: 114417, 2021. 3
2021
-
[32]
Opensatmap: A fine-grained high-resolution satellite dataset for large-scale map construction.Advances in Neu- ral Information Processing Systems, 37:59216–59235, 2024
Hongbo Zhao, Lue Fan, Yuntao Chen, Haochen Wang, Xiao- juan Jin, Yixin Zhang, Gaofeng Meng, Zhao-Xiang Zhang, et al. Opensatmap: A fine-grained high-resolution satellite dataset for large-scale map construction.Advances in Neu- ral Information Processing Systems, 37:59216–59235, 2024. 2
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.