Heterogeneous and Adept Snapshot Distillation for 3D Semantic Segmentation
Pith reviewed 2026-06-25 20:55 UTC · model grok-4.3
The pith
Distilling from multi-modal teachers and training snapshots raises accuracy of point-cloud 3D segmentation without extra inference cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
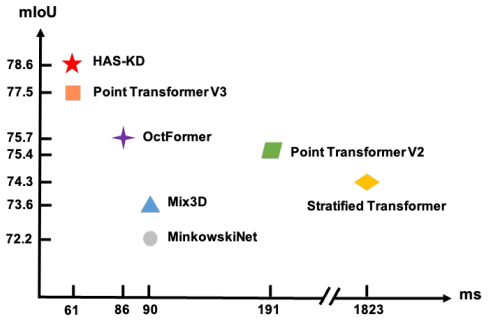
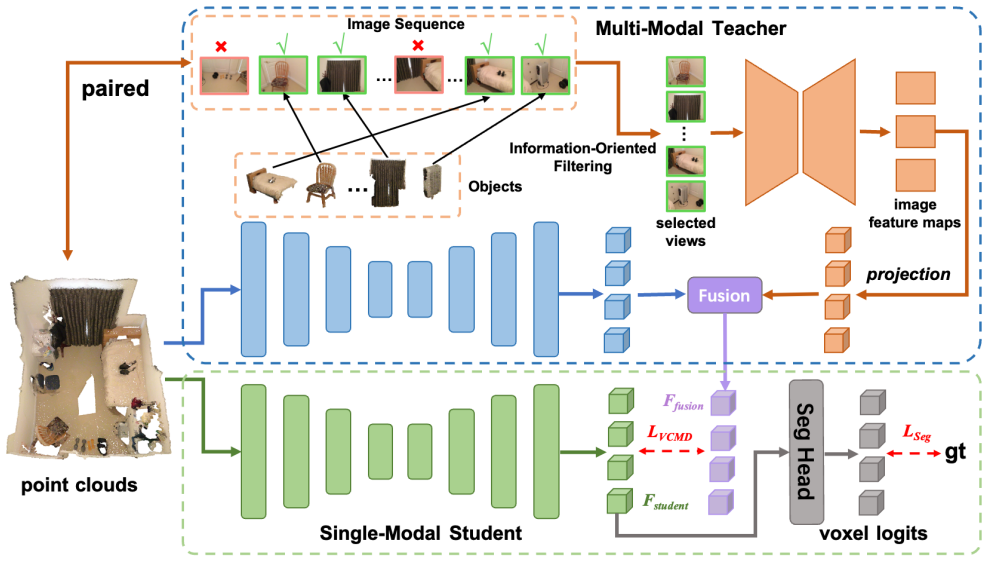
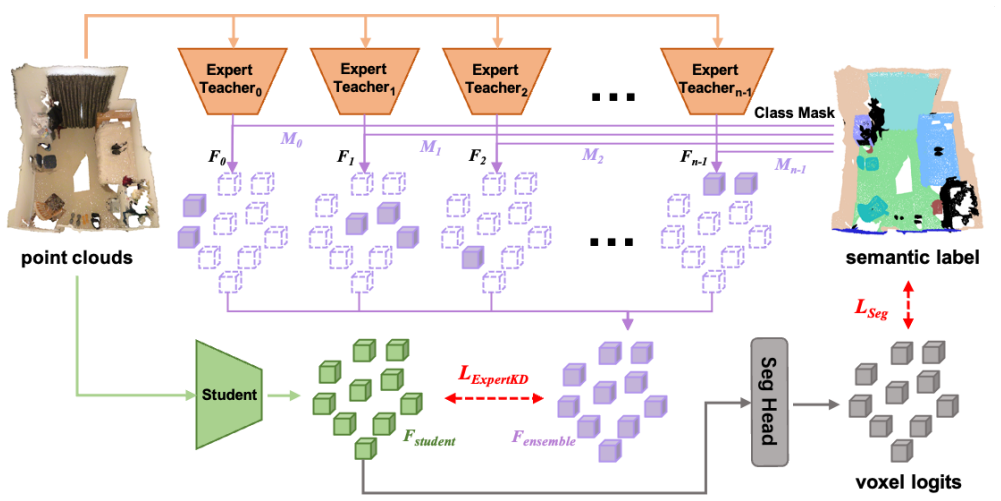
Information-oriented Heterogeneous Distillation transfers complementary cues from a multi-modal teacher to the point-cloud student after selecting the most informative images from image sequences, while Adept Snapshot Distillation lets each freely available training snapshot supervise the student solely in the classes where that snapshot is strongest; the resulting HAS-KD framework produces state-of-the-art results on ScanNetV2 and S3DIS and integrates directly into contemporary point-cloud segmentation algorithms.
What carries the argument
HAS-KD, the combination of heterogeneous distillation from a multi-modal teacher and selective class-wise supervision from training snapshots treated as adept experts.
If this is right
- Existing point-cloud segmentation networks can absorb multi-modal knowledge and ensemble-like benefits at training time only.
- The student model attains higher mean intersection-over-union scores on standard indoor 3D benchmarks.
- No auxiliary image inputs or additional model copies are required at inference.
- The same training run that produces the teacher also supplies the expert snapshots, eliminating separate ensemble training.
Where Pith is reading between the lines
- The selective-supervision idea could be tested on other dense prediction tasks such as 3D instance segmentation or surface reconstruction.
- If the adeptness criterion proves stable, it might reduce the need for explicit ensemble methods across a wider range of distillation settings.
- The image-selection filter could be examined on outdoor datasets where image quality varies more sharply.
Load-bearing premise
Model snapshots created during ordinary training naturally form a collection of class-adept experts whose selective supervision improves the student without introducing harmful conflicts.
What would settle it
A controlled run in which the adept-snapshot supervision is applied to the student and either produces no accuracy gain or lowers accuracy on ScanNetV2 or S3DIS would falsify the central claim.
Figures

read the original abstract
Multi-modal fusion and multi-model ensembling are prevalent in enhancing the performance of 3D semantic segmentation. Despite the impressive performance, these methods either rely on auxiliary input signals or suffer from costly computational expense. To efficaciously enhance the segmentation performance without introducing intolerable costs, we propose to transfer the rich knowledge from the multi-modal model (i.e., point clouds and images) and multiple model experts to the point-cloudbased network through knowledge distillation. Specifically, we present Information-oriented Heterogeneous Distillation (IHD) to help the uni-modal model absorb the complementary knowledge from the multi-modal teacher. We design the Information-Oriented Filtering (IOF) strategy to select informative images from the continuous image sequence for multi-modal fusion. This practice can boost the performance of the multi-modal teacher, thus benefiting the learning of the student. Besides, as opposed to vanilla model ensembling that requires the separate training of each expert, we propose Adept Snapshot Distillation (ASD). ASD treats the freely available model snapshots generated during the training phase as multiple experts, which significantly reduces the training cost for model ensembling. For each expert teacher, it only provides supervision to the student in the class where it is adept. The resulting Heterogeneous and Adept Snapshot Knowledge Distillation, dubbed HAS-KD, attains state-of-the-art results on ScanNetV2 and S3DIS datasets. HAS-KD can be seamlessly integrated into contemporary 3D segmentation algorithms and bring considerable gains without introducing extra inference burdens. The code will be made publicly available upon publication.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Heterogeneous and Adept Snapshot Knowledge Distillation (HAS-KD) for 3D semantic segmentation. It consists of Information-oriented Heterogeneous Distillation (IHD) that transfers complementary knowledge from a multi-modal (point-cloud + image) teacher to a point-cloud-only student, aided by Information-Oriented Filtering (IOF) to select informative images from sequences, together with Adept Snapshot Distillation (ASD) that treats ordinary training snapshots as class-adept experts and applies selective per-class supervision. The resulting method is reported to reach state-of-the-art performance on ScanNetV2 and S3DIS while adding no inference-time cost and being compatible with existing uni-modal pipelines.
Significance. If the reported gains hold, the work is significant for demonstrating a practical route to multi-modal and ensemble benefits without their usual deployment penalties. Explicit credit is due for supplying per-class accuracy curves of the snapshots, ablation tables that isolate the selective-supervision rule, and direct comparisons against non-selective ensembling baselines; these elements directly test the central assumption that snapshot experts can be used selectively without harmful conflicts. The stated intention to release code further supports reproducibility.
minor comments (3)
- [Abstract] Abstract: the claim of 'state-of-the-art results' would be more informative if the absolute mIoU numbers (or deltas) on ScanNetV2 and S3DIS were stated, even briefly.
- [§3.2] §3.2: the precise mathematical definition of the 'adeptness' selection rule (e.g., the threshold or ranking criterion applied to per-class accuracy) should be given as an equation rather than described only in prose.
- [Table 2] Table 2 (or equivalent ablation table): column headers and row labels should explicitly indicate whether the 'w/o selective' baseline uses the same snapshot teachers or a different ensembling strategy.
Simulated Author's Rebuttal
We thank the referee for the positive assessment, the recognition of the work's significance, and the recommendation for minor revision. The report correctly notes the value of the per-class curves, ablations, and non-selective baselines in testing the core assumptions of ASD.
Circularity Check
No significant circularity
full rationale
The paper is an empirical algorithmic proposal for HAS-KD (combining IHD and ASD) that reports SOTA results on ScanNetV2 and S3DIS. No equations, fitted parameters, or derivation chain appear in the provided text. The method is described procedurally with ablation support and dataset comparisons; the central claim does not reduce to any self-definition, fitted-input prediction, or self-citation load-bearing step. This is the expected non-finding for a purely empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Zamir, Helen Jiang, Ioan- nis Brilakis, Martin Fischer, and Silvio Savarese
Iro Armeni, Ozan Sener, Amir R. Zamir, Helen Jiang, Ioan- nis Brilakis, Martin Fischer, and Silvio Savarese. 3d seman- tic parsing of large-scale indoor spaces. InProceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, 2016. 3, 5
2016
-
[2]
Unstructured point cloud semantic labeling using deep segmentation networks.3dor@ eurographics, 3:17–24,
Alexandre Boulch, Bertrand Le Saux, Nicolas Audebert, et al. Unstructured point cloud semantic labeling using deep segmentation networks.3dor@ eurographics, 3:17–24,
-
[3]
Largekernel3d: Scaling up kernels in 3d sparse cnns
Yukang Chen, Jianhui Liu, Xiangyu Zhang, Xiaojuan Qi, and Jiaya Jia. Largekernel3d: Scaling up kernels in 3d sparse cnns. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 13488–13498,
-
[4]
Yulin Chen, Zhihang Zhong, and Yuenan Hou. Segment and select: Vision-language segmentation in 3d scenarios.arXiv preprint arXiv:2606.10594, 2026. 3
Pith/arXiv arXiv 2026
-
[5]
Zijia Chen, Yuenan Hou, Xinhua Jiang, Yu Li, Weijie Li, and Li Liu. Learning multi-modal trajectory poli- cies for data-efficient robotic manipulation.arXiv preprint arXiv:2606.01047, 2026. 3
Pith/arXiv arXiv 2026
-
[6]
4d spatio-temporal convnets: Minkowski convolutional neural networks
Christopher Choy, JunYoung Gwak, and Silvio Savarese. 4d spatio-temporal convnets: Minkowski convolutional neural networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3075–3084,
-
[7]
Pointcept: A codebase for point cloud perception research.https://github.com/ Pointcept/Pointcept, 2023
Pointcept Contributors. Pointcept: A codebase for point cloud perception research.https://github.com/ Pointcept/Pointcept, 2023. 6
2023
-
[8]
3dmv: Joint 3d-multi- view prediction for 3d semantic scene segmentation
Angela Dai and Matthias Nießner. 3dmv: Joint 3d-multi- view prediction for 3d semantic scene segmentation. InPro- ceedings of the European Conference on Computer Vision (ECCV), pages 452–468, 2018. 3
2018
-
[9]
Scannet: Richly-annotated 3d reconstructions of indoor scenes
Angela Dai, Angel X Chang, Manolis Savva, Maciej Hal- ber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5828–5839, 2017. 3, 5
2017
-
[10]
Ensemble methods in machine learn- ing
Thomas G Dietterich. Ensemble methods in machine learn- ing. InInternational workshop on multiple classifier systems, pages 1–15. Springer, 2000. 1, 3
2000
-
[11]
3d semantic segmentation with submani- fold sparse convolutional networks
Benjamin Graham, Martin Engelcke, and Laurens Van Der Maaten. 3d semantic segmentation with submani- fold sparse convolutional networks. InProceedings of the IEEE conference on computer vision and pattern recogni- tion, pages 9224–9232, 2018. 3
2018
-
[12]
3d semantic segmentation with submani- fold sparse convolutional networks
Benjamin Graham, Martin Engelcke, and Laurens Van Der Maaten. 3d semantic segmentation with submani- fold sparse convolutional networks. InProceedings of the IEEE conference on computer vision and pattern recogni- tion, pages 9224–9232, 2018. 1, 7
2018
-
[13]
Neural network en- sembles.IEEE transactions on pattern analysis and machine intelligence, 12(10):993–1001, 1990
Lars Kai Hansen and Peter Salamon. Neural network en- sembles.IEEE transactions on pattern analysis and machine intelligence, 12(10):993–1001, 1990. 1, 3
1990
-
[14]
Distilling the Knowledge in a Neural Network.Statistics, 1050:9, 2015
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the Knowledge in a Neural Network.Statistics, 1050:9, 2015. 3
2015
-
[15]
Learning lightweight lane detection CNNs by self atten- tion distillation
Yuenan Hou, Zheng Ma, Chunxiao Liu, and Chen Change Loy. Learning lightweight lane detection CNNs by self atten- tion distillation. InIEEE International Conference on Com- puter Vision, pages 1013–1021, 2019. 3
2019
-
[16]
Point-to-Voxel Knowledge Distillation for Li- DAR Semantic Segmentation
Yuenan Hou, Xinge Zhu, Yuexin Ma, Chen Change Loy, and Yikang Li. Point-to-Voxel Knowledge Distillation for Li- DAR Semantic Segmentation. InIEEE Conference on Com- puter Vision and Pattern Recognition, pages 8479–8488,
-
[17]
Advances in 3d pre-training and downstream tasks: a survey.Vicinagearth, 1(1):6, 2024
Yuenan Hou, Xiaoshui Huang, Shixiang Tang, Tong He, and Wanli Ouyang. Advances in 3d pre-training and downstream tasks: a survey.Vicinagearth, 1(1):6, 2024. 3
2024
-
[18]
Bidirectional projection network for cross dimension scene understanding
Wenbo Hu, Hengshuang Zhao, Li Jiang, Jiaya Jia, and Tien-Tsin Wong. Bidirectional projection network for cross dimension scene understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14373–14382, 2021. 1, 2, 3, 4, 7
2021
-
[19]
Texturenet: Consistent local parametrizations for learning from high- resolution signals on meshes
Jingwei Huang, Haotian Zhang, Li Yi, Thomas Funkhouser, Matthias Nießner, and Leonidas J Guibas. Texturenet: Consistent local parametrizations for learning from high- resolution signals on meshes. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4440–4449, 2019
2019
-
[20]
Multi-view pointnet for 3d scene understanding
Maximilian Jaritz, Jiayuan Gu, and Hao Su. Multi-view pointnet for 3d scene understanding. InProceedings of the IEEE/CVF International Conference on Computer Vision Workshops, pages 0–0, 2019. 3
2019
-
[21]
Hierarchical point-edge interaction network for point cloud semantic segmentation
Li Jiang, Hengshuang Zhao, Shu Liu, Xiaoyong Shen, Chi- Wing Fu, and Jiaya Jia. Hierarchical point-edge interaction network for point cloud semantic segmentation. InICCV,
-
[22]
Virtual multi-view fusion for 3d semantic segmentation
Abhijit Kundu, Xiaoqi Yin, Alireza Fathi, David Ross, Brian Brewington, Thomas Funkhouser, and Caroline Pantofaru. Virtual multi-view fusion for 3d semantic segmentation. In ECCV, pages 518–535. Springer, 2020. 1, 7
2020
-
[23]
Adaptive knowledge distillation based on entropy
Kisoo Kwon, Hwidong Na, Hoshik Lee, and Nam Soo Kim. Adaptive knowledge distillation based on entropy. InICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 7409–7413. IEEE, 2020. 3
2020
-
[24]
Stratified trans- former for 3d point cloud segmentation
Xin Lai, Jianhui Liu, Li Jiang, Liwei Wang, Hengshuang Zhao, Shu Liu, Xiaojuan Qi, and Jiaya Jia. Stratified trans- former for 3d point cloud segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8500–8509, 2022. 6, 7
2022
-
[25]
Deep projective 3d semantic segmentation
Felix J ¨aremo Lawin, Martin Danelljan, Patrik Tosteberg, Goutam Bhat, Fahad Shahbaz Khan, and Michael Felsberg. Deep projective 3d semantic segmentation. InComputer Analysis of Images and Patterns: 17th International Confer- ence, CAIP 2017, Ystad, Sweden, August 22-24, 2017, Pro- ceedings, Part I 17, pages 95–107. Springer, 2017. 3
2017
-
[26]
Seggcn: Effi- cient 3d point cloud segmentation with fuzzy spherical ker- nel
Huan Lei, Naveed Akhtar, and Ajmal Mian. Seggcn: Effi- cient 3d point cloud segmentation with fuzzy spherical ker- nel. InCVPR, 2020. 7
2020
-
[27]
Pointcnn: Convolution on x-transformed points.NeurIPS, 2018
Yangyan Li, Rui Bu, Mingchao Sun, Wei Wu, Xinhan Di, and Baoquan Chen. Pointcnn: Convolution on x-transformed points.NeurIPS, 2018. 7 9
2018
-
[28]
Moe3d: Mixture of ex- perts meets multi-modal 3d understanding.arXiv preprint arXiv:2511.22103, 2025
Yu Li, Yuenan Hou, Yingmei Wei, Xinge Zhu, Yuexin Ma, Wenqi Shao, and Yanming Guo. Moe3d: Mixture of ex- perts meets multi-modal 3d understanding.arXiv preprint arXiv:2511.22103, 2025. 3
arXiv 2025
-
[29]
Adaptive multi- teacher multi-level knowledge distillation.Neurocomputing, 415:106–113, 2020
Yuang Liu, Wei Zhang, and Jun Wang. Adaptive multi- teacher multi-level knowledge distillation.Neurocomputing, 415:106–113, 2020. 3
2020
-
[30]
Decoupled weight de- cay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight de- cay regularization. InInternational Conference on Learning Representations (ICLR), 2018. 6
2018
-
[31]
Xu Ma, Can Qin, Haoxuan You, Haoxi Ran, and Yun Fu. Rethinking network design and local geometry in point cloud: A simple residual mlp framework.arXiv preprint arXiv:2202.07123, 2022. 3
arXiv 2022
-
[32]
V oxnet: A 3d con- volutional neural network for real-time object recognition
Daniel Maturana and Sebastian Scherer. V oxnet: A 3d con- volutional neural network for real-time object recognition. In2015 IEEE/RSJ international conference on intelligent robots and systems (IROS), pages 922–928. IEEE, 2015. 3
2015
-
[33]
Mix3d: Out-of-context data aug- mentation for 3d scenes
Alexey Nekrasov, Jonas Schult, Or Litany, Bastian Leibe, and Francis Engelmann. Mix3d: Out-of-context data aug- mentation for 3d scenes. In2021 International Conference on 3D Vision (3DV), pages 116–125. IEEE, 2021. 6, 7
2021
-
[34]
Popular ensemble meth- ods: An empirical study.Journal of artificial intelligence research, 11:169–198, 1999
David Opitz and Richard Maclin. Popular ensemble meth- ods: An empirical study.Journal of artificial intelligence research, 11:169–198, 1999. 3
1999
-
[35]
Fast point transformer
Chunghyun Park, Yoonwoo Jeong, Minsu Cho, and Jae- sik Park. Fast point transformer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16949–16958, 2022. 7
2022
-
[36]
Pointnet: Deep learning on point sets for 3d classification and segmentation
Charles R Qi, Hao Su, Kaichun Mo, and Leonidas J Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 652–660,
-
[37]
Pointnet++: Deep hierarchical feature learning on point sets in a metric space.Advances in neural information processing systems, 30, 2017
Charles Ruizhongtai Qi, Li Yi, Hao Su, and Leonidas J Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space.Advances in neural information processing systems, 30, 2017. 3, 6, 7
2017
-
[38]
Learn- ing multi-view aggregation in the wild for large-scale 3d se- mantic segmentation
Damien Robert, Bruno Vallet, and Loic Landrieu. Learn- ing multi-view aggregation in the wild for large-scale 3d se- mantic segmentation. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 5575–5584, 2022. 2, 3, 4, 7
2022
-
[39]
FitNets: Hints for Thin Deep Nets
Adriana Romero, Nicolas Ballas, Samira Ebrahimi Kahou, Antoine Chassang, Carlo Gatta, and Yoshua Bengio. FitNets: Hints for Thin Deep Nets. InInternational Conference on Learning Representations, 2015. 3
2015
-
[40]
Leslie N. Smith and Nicholay Topin. Super-convergence: Very fast training of neural networks using large learning rates.arXiv preprint arXiv:1708.07120, 2017. 6
Pith/arXiv arXiv 2017
-
[41]
Semantic scene com- pletion from a single depth image
Shuran Song, Fisher Yu, Andy Zeng, Angel X Chang, Mano- lis Savva, and Thomas Funkhouser. Semantic scene com- pletion from a single depth image. InProceedings of the IEEE conference on computer vision and pattern recogni- tion, pages 1746–1754, 2017. 3
2017
-
[42]
Tangent convolutions for dense prediction in 3d
Maxim Tatarchenko, Jaesik Park, Vladlen Koltun, and Qian- Yi Zhou. Tangent convolutions for dense prediction in 3d. In CVPR, 2018. 7
2018
-
[43]
Segcloud: Semantic segmen- tation of 3d point clouds
Lyne Tchapmi, Christopher Choy, Iro Armeni, JunYoung Gwak, and Silvio Savarese. Segcloud: Semantic segmen- tation of 3d point clouds. In3DV, 2017. 6, 7
2017
-
[44]
Kpconv: Flexible and deformable convolution for point clouds
Hugues Thomas, Charles R Qi, Jean-Emmanuel Deschaud, Beatriz Marcotegui, Franc ¸ois Goulette, and Leonidas J Guibas. Kpconv: Flexible and deformable convolution for point clouds. InProceedings of the IEEE/CVF international conference on computer vision, pages 6411–6420, 2019. 7
2019
-
[45]
Graph attention convolution for point cloud seman- tic segmentation
Lei Wang, Yuchun Huang, Yaolin Hou, Shenman Zhang, and Jie Shan. Graph attention convolution for point cloud seman- tic segmentation. InCVPR, 2019. 7
2019
-
[46]
Octformer: Octree-based transformers for 3d point clouds.arXiv preprint arXiv:2305.03045, 2023
Peng-Shuai Wang. Octformer: Octree-based transformers for 3d point clouds.arXiv preprint arXiv:2305.03045, 2023. 1, 6, 7, 8
arXiv 2023
-
[47]
O-cnn: Octree-based convolutional neu- ral networks for 3d shape analysis.ACM Transactions On Graphics (TOG), 36(4):1–11, 2017
Peng-Shuai Wang, Yang Liu, Yu-Xiao Guo, Chun-Yu Sun, and Xin Tong. O-cnn: Octree-based convolutional neu- ral networks for 3d shape analysis.ACM Transactions On Graphics (TOG), 36(4):1–11, 2017. 7
2017
-
[48]
Squeezeseg: Convolutional neural nets with recurrent crf for real-time road-object segmentation from 3d lidar point cloud
Bichen Wu, Alvin Wan, Xiangyu Yue, and Kurt Keutzer. Squeezeseg: Convolutional neural nets with recurrent crf for real-time road-object segmentation from 3d lidar point cloud. In2018 IEEE international conference on robotics and au- tomation (ICRA), pages 1887–1893. IEEE, 2018. 3
2018
-
[49]
Squeezesegv2: Improved model structure and unsupervised domain adaptation for road-object segmenta- tion from a lidar point cloud
Bichen Wu, Xuanyu Zhou, Sicheng Zhao, Xiangyu Yue, and Kurt Keutzer. Squeezesegv2: Improved model structure and unsupervised domain adaptation for road-object segmenta- tion from a lidar point cloud. In2019 international confer- ence on robotics and automation (ICRA), pages 4376–4382. IEEE, 2019. 3
2019
-
[50]
Multi-teacher knowledge distillation for compressed video action recognition on deep neural networks
Meng-Chieh Wu, Ching-Te Chiu, and Kun-Hsuan Wu. Multi-teacher knowledge distillation for compressed video action recognition on deep neural networks. InICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 2202–2206. IEEE, 2019. 3
2019
-
[51]
Point transformer v2: Grouped vector atten- tion and partition-based pooling.Advances in Neural Infor- mation Processing Systems, 35:33330–33342, 2022
Xiaoyang Wu, Yixing Lao, Li Jiang, Xihui Liu, and Heng- shuang Zhao. Point transformer v2: Grouped vector atten- tion and partition-based pooling.Advances in Neural Infor- mation Processing Systems, 35:33330–33342, 2022. 1, 3, 7, 8
2022
-
[52]
Point transformer v3: Simpler, faster, stronger.arXiv preprint arXiv:2312.10035, 2023
Xiaoyang Wu, Li Jiang, Peng-Shuai Wang, Zhijian Liu, Xi- hui Liu, Yu Qiao, Wanli Ouyang, Tong He, and Hengshuang Zhao. Point transformer v3: Simpler, faster, stronger.arXiv preprint arXiv:2312.10035, 2023. 1, 3, 6, 7, 8
arXiv 2023
-
[53]
Xiaoyang Wu, Zhuotao Tian, Xin Wen, Bohao Peng, Xihui Liu, Kaicheng Yu, and Hengshuang Zhao. Towards large- scale 3d representation learning with multi-dataset point prompt training.arXiv preprint arXiv:2308.09718, 2023. 7
arXiv 2023
-
[54]
Taseg: Temporal aggregation network for lidar semantic segmentation
Xiaopei Wu, Yuenan Hou, Xiaoshui Huang, Binbin Lin, Tong He, Xinge Zhu, Yuexin Ma, Boxi Wu, Haifeng Liu, Deng Cai, et al. Taseg: Temporal aggregation network for lidar semantic segmentation. InIEEE Conference on Com- puter Vision and Pattern Recognition, pages 15311–15320,
-
[55]
Paconv: Position adaptive convolution with dynamic ker- nel assembling on point clouds
Mutian Xu, Runyu Ding, Hengshuang Zhao, and Xiaojuan Qi. Paconv: Position adaptive convolution with dynamic ker- nel assembling on point clouds. InCVPR, 2021. 7 10
2021
-
[56]
Pointasnl: Robust point clouds processing using nonlocal neural networks with adaptive sampling
Xu Yan, Chaoda Zheng, Zhen Li, Sheng Wang, and Shuguang Cui. Pointasnl: Robust point clouds processing using nonlocal neural networks with adaptive sampling. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 5589–5598, 2020. 7
2020
-
[57]
2dpass: 2d priors assisted semantic segmentation on lidar point clouds
Xu Yan, Jiantao Gao, Chaoda Zheng, Chao Zheng, Ruimao Zhang, Shuguang Cui, and Zhen Li. 2dpass: 2d priors assisted semantic segmentation on lidar point clouds. In European Conference on Computer Vision, pages 677–695. Springer, 2022. 3
2022
-
[58]
Towards efficient 3d object detection with knowl- edge distillation.Advances in Neural Information Process- ing Systems, 35:21300–21313, 2022
Jihan Yang, Shaoshuai Shi, Runyu Ding, Zhe Wang, and Xi- aojuan Qi. Towards efficient 3d object detection with knowl- edge distillation.Advances in Neural Information Process- ing Systems, 35:21300–21313, 2022. 3
2022
-
[59]
Sam3d: Segment anything in 3d scenes.arXiv preprint arXiv:2306.03908, 2023
Yunhan Yang, Xiaoyang Wu, Tong He, Hengshuang Zhao, and Xihui Liu. Sam3d: Segment anything in 3d scenes.arXiv preprint arXiv:2306.03908, 2023. 2, 4
arXiv 2023
-
[60]
Yu-Qi Yang, Yu-Xiao Guo, Jian-Yu Xiong, Yang Liu, Hao Pan, Peng-Shuai Wang, Xin Tong, and Baining Guo. Swin3d: A pretrained transformer backbone for 3d indoor scene understanding.arXiv preprint arXiv:2304.06906,
-
[61]
Learning from multiple teacher networks
Shan You, Chang Xu, Chao Xu, and Dacheng Tao. Learning from multiple teacher networks. InProceedings of the 23rd ACM SIGKDD International Conference on Knowledge Dis- covery and Data Mining, pages 1285–1294, 2017. 3
2017
-
[62]
Confidence- aware multi-teacher knowledge distillation
Hailin Zhang, Defang Chen, and Can Wang. Confidence- aware multi-teacher knowledge distillation. InICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 4498–4502. IEEE, 2022. 3
2022
-
[63]
Yuan Zhang, Weihua Chen, Yichen Lu, Tao Huang, Xiuyu Sun, and Jian Cao. Avatar knowledge distillation: Self- ensemble teacher paradigm with uncertainty.arXiv preprint arXiv:2305.02722, 2023. 3
arXiv 2023
-
[64]
Pointweb: Enhancing local neighborhood features for point cloud processing
Hengshuang Zhao, Li Jiang, Chi-Wing Fu, and Jiaya Jia. Pointweb: Enhancing local neighborhood features for point cloud processing. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 5565–5573, 2019. 3, 7
2019
-
[65]
Point transformer
Hengshuang Zhao, Li Jiang, Jiaya Jia, Philip HS Torr, and Vladlen Koltun. Point transformer. InProceedings of the IEEE/CVF international conference on computer vision, pages 16259–16268, 2021. 6, 7
2021
-
[66]
Boosting 3d object detection by simulating multimodality on point clouds
Wu Zheng, Mingxuan Hong, Li Jiang, and Chi-Wing Fu. Boosting 3d object detection by simulating multimodality on point clouds. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13638– 13647, 2022. 3
2022
-
[67]
Unidistill: A universal cross-modality knowl- edge distillation framework for 3d object detection in bird’s- eye view
Shengchao Zhou, Weizhou Liu, Chen Hu, Shuchang Zhou, and Chao Ma. Unidistill: A universal cross-modality knowl- edge distillation framework for 3d object detection in bird’s- eye view. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5116– 5125, 2023. 3 11
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.