CoEval: Ranking Language Models for Custom Tasks Without Labeled Data or Trustworthy Benchmarks
Pith reviewed 2026-06-28 10:43 UTC · model grok-4.3
The pith
CoEval ranks language models on any custom task by having the models generate, answer, and score a fresh benchmark with no human labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
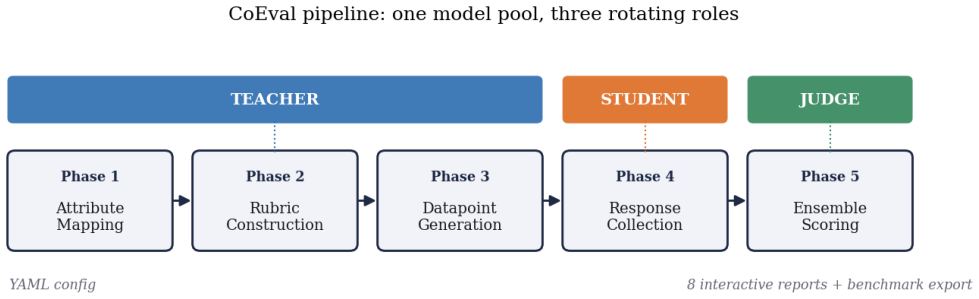
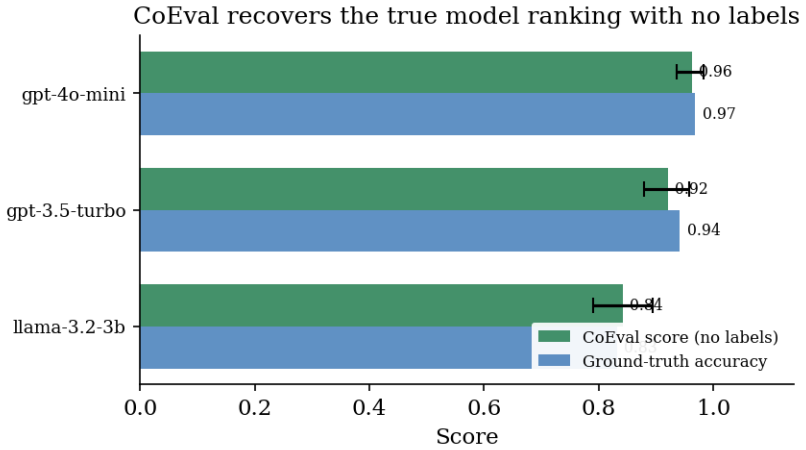
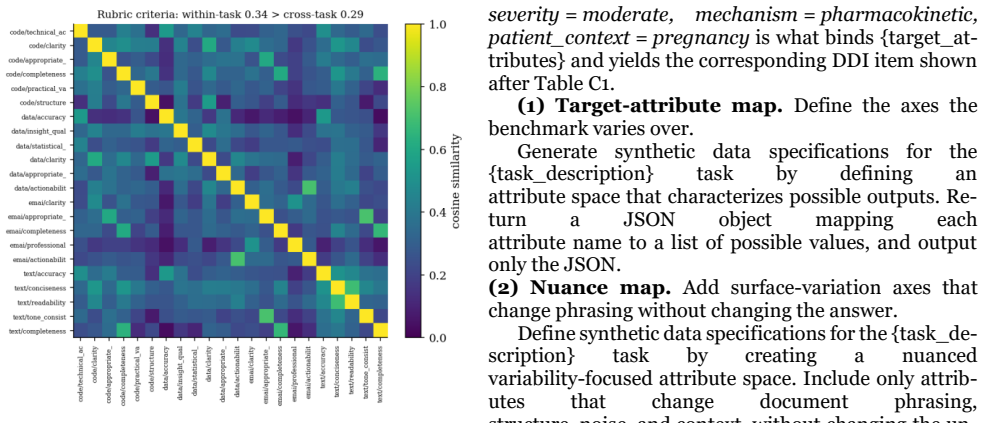
CoEval supplies a trustworthy, task-specific signal through ensemble self-evaluation: from a task or domain description, a pool of models rotates through all three roles, teacher, student, and judge, to generate a fresh, contamination-free benchmark, answer it, and score one another, with no human labels or raters. Because every model also answers as a student, the responses are the data that weight each question by its discriminative power and each judge by its consensus with the panel. Where ground truth exists, CoEval recovers the true ranking and tracks objective correctness at ρ=0.86, and the weighting recovers the gold ranking of thirteen models at Spearman 0.95. Reliability comes from
What carries the argument
The ensemble self-evaluation loop in which models cycle through teacher, student, and judge roles, followed by automatic weighting of judges by panel consensus and questions by discriminative power computed from the collected answers.
If this is right
- Generated items show zero verbatim overlap with five public benchmarks.
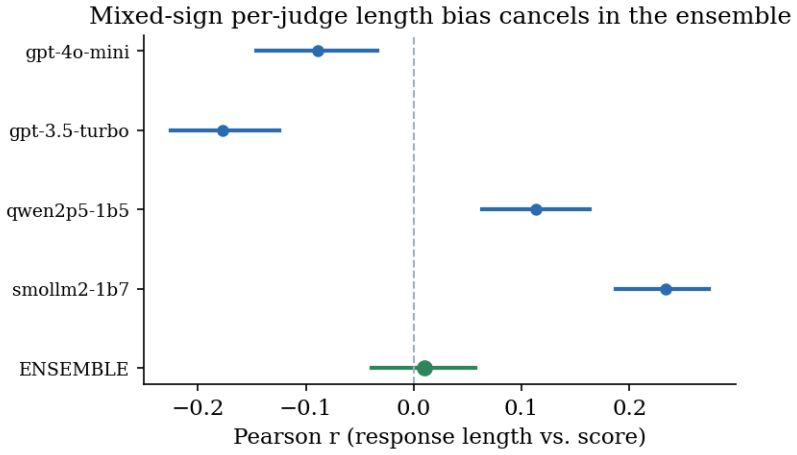
- The panel cancels verbosity bias and precludes same-family self-preference.
- Three different models top four different de-novo domains, showing generic leaderboards misdirect most practitioners.
- The same pipeline can be rerun on each new model release to maintain a contamination-free leaderboard for any application.
- Rankings are domain-specific rather than universal.
Where Pith is reading between the lines
- Teams working on narrow internal tasks could run CoEval periodically without waiting for new public benchmarks.
- The approach might be combined with a small amount of human review on the generated questions to further increase trust.
- Because the method is fully automated, it could be used to compare models on tasks that change over time, such as evolving regulations or domain-specific terminology.
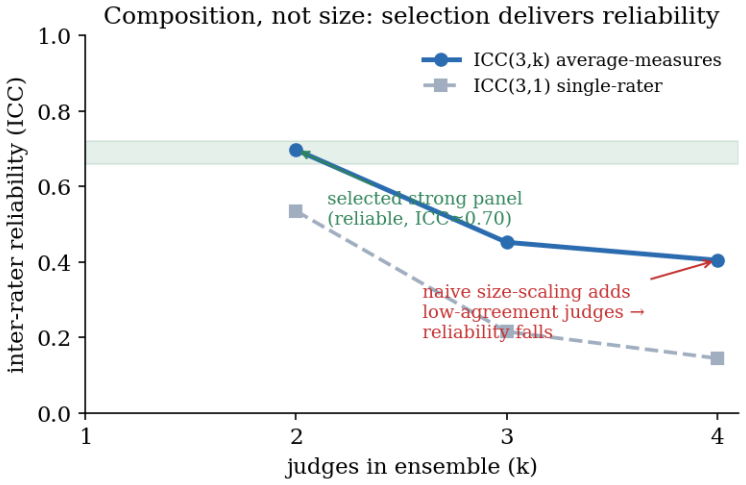
- If panel size matters less than composition, smaller but diverse panels might suffice for many applications.
Load-bearing premise
That weighting each judge by agreement with the rest of the panel and each question by how much it separates the models, using only the models' own responses, will produce a ranking that matches what independent ground-truth labels would have produced.
What would settle it
Apply CoEval to thirteen models on a task that already has an independent human-labeled ground-truth ranking and obtain a Spearman correlation below 0.7 with that ranking.
Figures
read the original abstract
Selecting a pretrained language model, or evaluating a fine-tuned one, for a specific application is a high-value decision, yet the public benchmarks used to make it are poorly suited: a generic benchmark need not reflect a particular sub-domain or sub-task, and its scores are suspect when its items have leaked into pretraining and are recalled rather than solved. We present CoEval, an open framework that supplies a trustworthy, task-specific signal through ensemble self-evaluation: from a task or domain description, a pool of models rotates through all three roles, teacher, student, and judge, to generate a fresh, contamination-free benchmark, answer it, and score one another, with no human labels or raters. Because every model also answers as a student, the responses are the data that weight each question by its discriminative power and each judge by its consensus with the panel. Where ground truth exists, CoEval recovers the true ranking and tracks objective correctness at \r{ho}=0.86, and the weighting recovers the gold ranking of thirteen models at Spearman 0.95. Reliability comes from panel composition, not size: this label-free weighting zeroes out broken judges and down-weights saturated questions, so neither distorts the ranking. Generated items show zero verbatim overlap with five public benchmarks, the panel cancels verbosity bias and precludes same-family self-preference, and rankings are domain-specific: three different models top four de-novo domains, so a generic leaderboard misdirects most practitioners. The same pipeline reruns on each model release, giving any team a contamination-free leaderboard for its application.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents CoEval, an open framework for ranking pretrained or fine-tuned language models on custom tasks or domains without labeled data or public benchmarks. Models rotate through teacher, student, and judge roles to generate a fresh benchmark from a task description, answer the items, and score one another; question weights are derived from discriminative power and judge weights from consensus with the panel, all computed solely from the 13-model response matrix. The abstract reports that where ground truth exists the method recovers the true ranking and tracks objective correctness at ρ=0.86, recovers the gold ranking of thirteen models at Spearman 0.95, produces zero verbatim overlap with five public benchmarks, cancels verbosity bias, and yields domain-specific rankings in which different models top four de-novo domains.
Significance. If the central claims hold, the work would be significant for LLM evaluation by supplying a reproducible, contamination-free pipeline that can be rerun on each model release to produce application-specific leaderboards. The reported correlations with ground truth, the zero-overlap verification, and the falsifiable prediction that panel composition (rather than size) suffices to zero out broken judges are concrete strengths that could be directly tested by independent replication.
major comments (2)
- [Abstract] Abstract: the claim that consensus-with-panel and discriminative-power weights computed from the 13-model response matrix recover the gold ranking at Spearman 0.95 is supported only on tasks that possess ground truth; the manuscript must demonstrate that these weights, derived solely from the models' own responses, produce externally valid rankings on tasks that lack ground truth, because this transfer is the load-bearing assumption for the no-GT use case.
- [Abstract] Abstract: the explicit formulas for computing judge weights from agreement with the panel and question weights from discriminative power are not supplied, leaving open whether the scheme avoids post-hoc selection or circular fitting when the same response matrix is used both to derive the weights and to produce the ranking.
minor comments (1)
- [Abstract] The abstract contains the typesetting artifact '\r{ho}' which should be rendered as ρ.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on validation scope and formula transparency. We respond point-by-point below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that consensus-with-panel and discriminative-power weights computed from the 13-model response matrix recover the gold ranking at Spearman 0.95 is supported only on tasks that possess ground truth; the manuscript must demonstrate that these weights, derived solely from the models' own responses, produce externally valid rankings on tasks that lack ground truth, because this transfer is the load-bearing assumption for the no-GT use case.
Authors: We agree that the reported Spearman 0.95 recovery is measured only on tasks possessing ground truth. The weighting procedure itself uses no ground truth and operates exclusively on the 13-model response matrix; its ability to recover the known ranking on GT tasks is offered as supporting evidence that the identical procedure remains valid when no external labels exist. Direct external validation on no-GT tasks is not feasible by definition, since no independent ground truth is available for comparison. We will revise the abstract to distinguish the GT-based validation results from the no-GT claims more explicitly. revision: partial
-
Referee: [Abstract] Abstract: the explicit formulas for computing judge weights from agreement with the panel and question weights from discriminative power are not supplied, leaving open whether the scheme avoids post-hoc selection or circular fitting when the same response matrix is used both to derive the weights and to produce the ranking.
Authors: We accept that the abstract (and, upon re-examination, the main text) omitted the explicit formulas. Judge weight for model j is the normalized average pairwise agreement (Pearson correlation of score vectors) between j and every other judge. Question weight for item i is the normalized variance of the 13 student answers to i, which quantifies discriminative power. Both quantities are computed once from the response matrix and then held fixed when the final weighted ranking is produced, so the procedure is non-circular. We will insert the precise equations into the Methods section in the revised manuscript. revision: yes
- Direct demonstration of externally valid rankings on tasks that lack any ground truth, because no independent external criterion exists against which to measure validity in that setting.
Circularity Check
No significant circularity; method validated against external ground truth
full rationale
The paper describes an ensemble procedure that generates responses from a panel of models, then derives question weights (discriminative power) and judge weights (consensus with panel) directly from those responses before producing a final ranking. This is an internal computation, but the central claims are not self-referential by construction: the authors explicitly validate the output rankings against independent ground-truth labels on tasks that possess them, reporting Spearman correlations of 0.86 with objective correctness and 0.95 with gold model rankings. Because external benchmarks are used to assess the procedure, the derivation chain does not reduce the claimed result to a renaming or reweighting of its own inputs. No self-citation load-bearing steps, uniqueness theorems, or ansatzes appear in the provided text. The method is therefore self-contained against external checks rather than circular.
Axiom & Free-Parameter Ledger
free parameters (1)
- weighting parameters for discriminative power and consensus
axioms (1)
- domain assumption Model responses can be used to estimate question quality and judge reliability without external labels.
Reference graph
Works this paper leans on
-
[1]
Zheng, L., Chiang, W.-L., Sheng, Y., et al. (2023). Judging LLM-as-a-Judge with MT -Bench and Chatbot Arena. Neu- rIPS. arxiv.org/abs/2306.05685
Pith/arXiv arXiv 2023
-
[2]
Liu, Y., Iter, D., Xu, Y., et al. (2023). G-Eval: NLG Evalu- ation using GPT-4 with Better Human Alignment. EMNLP. arxiv.org/abs/2303.16634
Pith/arXiv arXiv 2023
-
[3]
Kim, S., Suk, J., Longpre, S., et al. (2024). Prometheus 2: An Open Source Language Model Specialized in Evaluating Other Language Models. arxiv.org/abs/2405.01535
arXiv 2024
-
[4]
Vu, T., Krishna, K., Alzubi, S., et al. (2024). Foundational Autoraters: Taming Large Language Models for Better Au- tomatic Evaluation (FLAMe). EMNLP. arxiv.org/abs/2407.10817
arXiv 2024
-
[5]
Verga, P., Hofstatter, S., Althammer, S., et al. (2024). Re- placing Judges with Juries: Evaluating LLM Generations with a Panel of Diverse Models (PoLL). arxiv.org/abs/2404.18796
Pith/arXiv arXiv 2024
-
[6]
Tan, S., Zhuang, S., Montgomery, K., et al. (2025). Judge- Bench: A Benchmark for Evaluating LLM -based Judges. ICLR. arxiv.org/abs/2410.12784
Pith/arXiv arXiv 2025
- [7]
-
[8]
Dubois, Y., Galambosi, B., Liang, P., Hashimoto, T. B. (2024). Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators. arxiv.org/abs/2404.04475
Pith/arXiv arXiv 2024
-
[9]
Li, X. L., Kazemi, M., et al. (2024). AutoBencher: Towards Declarative Benchmark Construction. arxiv.org/abs/2407.08351
arXiv 2024
-
[10]
Butt, N., Awadalla, H., et al. (2024). BenchAgents: Auto- mated Benchmark Creation with Agent Interaction. arxiv.org/abs/2410.22584
arXiv 2024
-
[11]
Shashidhar, S., et al. (2025). YourBench: Easy Custom Evaluation Sets for Everyone. arxiv.org/abs/2504.01833
arXiv 2025
-
[12]
Zhang, H., Da, J., Lee, D., et al. (2024). A Careful Exam- ination of Large Language Model Performance on Grade School Arithmetic (GSM1k). arxiv.org/abs/2405.00332
arXiv 2024
-
[13]
Xu, C., et al. (2025). Benchmark Data Contamination of Large Language Models: A Survey. arxiv.org/abs/2502.14425
arXiv 2025
-
[14]
Kiela, D., Bartolo, M., Nie, Y., et al. (2021). Dynabench: Rethinking Benchmarking in NLP. NAACL. arxiv.org/abs/2104.14337
arXiv 2021
-
[15]
Li, D., Sun, R., Huang, Y., et al. (2026). Preference Leak- age: A Contamination Problem in LLM -as-a-Judge. ICLR. arxiv.org/abs/2502.01534
arXiv 2026
-
[16]
Spiliopoulou, E., et al. (2025). Play Favorites: A Statisti- cal Method to Measure Self -Bias in LLM -as-a-Judge. arxiv.org/abs/2508.06709
arXiv 2025
-
[17]
Ye, J., Wang, Y., Huang, Y., et al. (2024). Justice or Prej- udice? Quantifying Biases in LLM -as-a-Judge. arxiv.org/abs/2410.02736
Pith/arXiv arXiv 2024
-
[18]
Wataoka, K., Takahashi, T., Ri, R. (2024). Self-Preference Bias in LLM-as-a-Judge. arxiv.org/abs/2410.21819 14
Pith/arXiv arXiv 2024
-
[19]
Gu, J., Jiang, X., Shi, Z., et al. (2024). A Survey on LLM- as-a-Judge. arxiv.org/abs/2411.15594
Pith/arXiv arXiv 2024
-
[20]
Li, D., Jiang, B., Huang, L., et al. (2025). From Genera- tion to Judgment: Opportunities and Challenges of LLM-as- a-Judge. EMNLP. arxiv.org/abs/2411.16594
arXiv 2025
-
[21]
Chan, C.-M., Chen, W., Su, Y., et al. (2024). ChatEval: Towards Better LLM -based Evaluators through Multi - Agent Debate. ICLR. arxiv.org/abs/2308.07201
Pith/arXiv arXiv 2024
-
[22]
White, C., Dooley, S., Roberts, M., et al. (2025). LiveBench: A Challenging, Contamination -Limited LLM Benchmark. ICLR. arxiv.org/abs/2406.19314
Pith/arXiv arXiv 2025
-
[23]
Jain, N., Han, K., Gu, A., et al. (2025). LiveCodeBench: Holistic and Contamination Free Evaluation of Large Lan- guage Models for Code. ICLR. arxiv.org/abs/2403.07974
Pith/arXiv arXiv 2025
-
[24]
Chen, W.-L., Wu, Z., Bansal, H., et al. (2025). Do LLM Evaluators Prefer Themselves for a Reason? arxiv.org/abs/2504.03846
arXiv 2025
-
[25]
Raju, R., Jain, S., Li, B., et al. (2024). Constructing Do- main-Specific Evaluation Sets for LLM -as-a-judge. arxiv.org/abs/2408.08808
arXiv 2024
-
[26]
Li, Y., et al. (2025). Leveraging LLMs as Meta-Judges: A Multi-Agent Framework. arxiv.org/abs/2504.17087
arXiv 2025
-
[27]
Qian, C., Sun, G., Gales, M., Knill, K. (2026). Who can we trust? LLM-as-a-jury for Comparative Assessment. ICML. arxiv.org/abs/2602.16610
Pith/arXiv arXiv 2026
-
[28]
Zhao, Y., Shin, J., Huang, Z., Namburi, S., Sala, F. (2026). CARE: Confounder -Aware Aggregation for Reliable LLM Evaluation. arxiv.org/abs/2603.00039
arXiv 2026
-
[29]
Xu, C., Tan, Z., Wu, J., Zhou, T. (2026). A Judge-Aware Ranking Framework for Evaluating Large Language Mod- els without Ground Truth. arxiv.org/abs/2601.21817
Pith/arXiv arXiv 2026
-
[30]
Patel, A., Reddy, S., Bahdanau, D. (2025). CHASE: How to Get Your LLM to Generate Challenging Problems for Evaluation. arxiv.org/abs/2502.14678
arXiv 2025
-
[31]
Filice, S., Horowitz, G., Carmel, D., Karnin, Z., Lewin-Ey- tan, L., Maarek, Y. (2025). Generating Diverse Q&A Bench- marks for RAG Evaluation with DataMorgana. SIGIR LiveRAG. arxiv.org/abs/2501.12789
arXiv 2025
-
[32]
Chen, Y., et al. (2025). Recent Advances in Large Lan- guage Model Benchmarks against Data Contamination: From Static to Dynamic Evaluation. EMNLP. arxiv.org/abs/2502.17521
arXiv 2025
-
[33]
de Zarz `a, I., de Curt `o, J., Cabot, J., Manzoni, P., and Calafate, C
Dawid, A. P., Skene, A. M. (1979). Maximum Likelihood Estimation of Observer Error -Rates Using the EM Algo- rithm. Journal of the Royal Statistical Society: Series C (Ap- plied Statistics), 28(1), 20–28. doi.org/10.2307/2346806 Appendix A. Statistical methods This appendix collects the estimator definitions used in the main text. CoEval reports the agree...
-
[34]
Assess the drug –drug interaction between these medications, identify the mecha- nism, and provide the severity and clinical recom- mendation."
DDI (severity = moderate, mechanism = pharma- cokinetic, patient_context = pregnancy): "A 30 - year-old pregnant woman is prescribed lamotrig- ine for bipolar disorder and is also taking oral con- traceptives. Assess the drug –drug interaction between these medications, identify the mecha- nism, and provide the severity and clinical recom- mendation."
-
[35]
On examination, you note elevated jugular venous pressure and a third heart sound
Clinical (specialty = cardiology, difficulty = rou- tine): "A 62-year-old male with a history of hyper- tension and hyperlipidemia presents with progressive shortness of breath and occasional palpitations. On examination, you note elevated jugular venous pressure and a third heart sound. An ECG shows left ventricula r hypertrophy. What is the most likely ...
-
[36]
The park is owned by the city, and Alice claims the city is liable for her injuries due to negligence
Legal (area_of_law = torts, complexity = basic): "Alice, while jogging in the park, trips over a tree root that has been exposed due to erosion and falls, breaking her wrist. The park is owned by the city, and Alice claims the city is liable for her injuries due to negligence. Identify the relevant rule and de- termine if Alice can successfully hold the c...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.