ProCal: Inference-Time Proposal Calibration for Open-Vocabulary Object Detection
Pith reviewed 2026-07-03 16:23 UTC · model grok-4.3
The pith
A simple inference-time calibration of object proposals using foreground and background scores from vision-language models improves detection of novel categories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
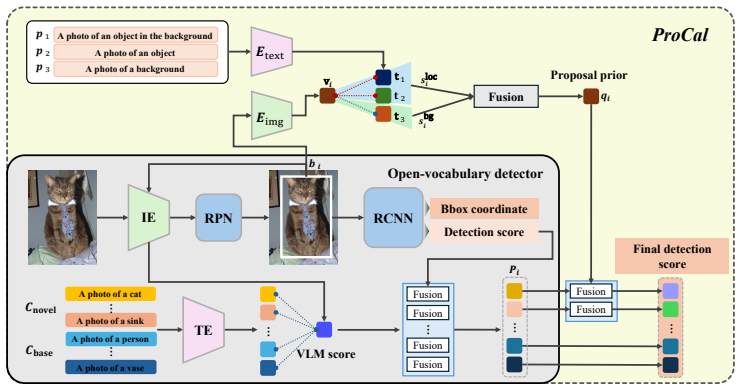
ProCal computes a proposal prior by combining a localization-aware foreground score, which checks if a proposal contains an object area, and a background-aware suppression score, which measures resemblance to background. This prior is used to adjust the classification score, resulting in better ranking of true novel proposals over false activations on background or partial objects.
What carries the argument
The proposal prior formed by combining the localization-aware foreground score and the background-aware suppression score to calibrate the VLM classification score.
If this is right
- ProCal suppresses false novel activation on background proposals.
- True novel proposals are ranked above background and partial novel proposals.
- The method mitigates ranking miscalibration for novel objects through proposal-level localization-aware reranking.
Where Pith is reading between the lines
- Similar calibration could be applied to other tasks using VLMs for localization, such as segmentation.
- If the foreground-background distinction holds across more VLMs, this could become a standard post-processing step.
- The approach highlights that position and scale information is present but underutilized in standard VLM classification outputs.
Load-bearing premise
Pretrained vision-language models distinguish foreground and background regions in a manner that yields useful scores transferable to novel object categories.
What would settle it
Measuring whether ProCal increases the rank of ground-truth novel object proposals relative to background proposals on a dataset with many novel categories would confirm or refute the calibration benefit.
Figures


read the original abstract
Open-vocabulary object detection aims to localize and classify objects beyond the fixed set of categories seen dur ing training. Recent open-vocabulary object detection methods improve localization and classification for unseen categories by leveraging a frozen VLM as a detector backbone. However, VLM classification score lacks recognizing position and scale of the object in an image. We observe that pretrained VLMs en able to classify foreground and background regions. According to this observation, we propose a simple inference-time Pro posal Calibration (ProCal) that improves localization quality of the classification score. ProCal computes a proposal prior by combining two scores: localization-aware foreground score and background-aware suppression score. Localization-aware foreground score captures whether a proposal contains an object area. Background-aware suppression score measures the extent to which the proposal resembles background. We analyze that ProCal suppresses false novel activation on background proposals and consistently ranks true novel proposals above background and partial novel proposals. Applied to CLIPSelf ViT-L/14, ProCal improves APr +2.5 on OV-LVIS. The analyses show that proposal-level localization-aware reranking effects to mitigate ranking miscalibration for novel objects.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ProCal, an inference-time proposal calibration method for open-vocabulary object detection. It leverages a frozen VLM based on the observation that pretrained VLMs can classify foreground and background regions, computing a proposal prior from a localization-aware foreground score and a background-aware suppression score. This is claimed to improve the localization quality of VLM classification scores, suppress false novel activations on background proposals, and consistently rank true novel proposals higher than background or partial ones. Applied to CLIPSelf ViT-L/14, ProCal is reported to yield a +2.5 APr gain on OV-LVIS, with accompanying analyses of its reranking effects on novel objects.
Significance. If the empirical result holds under rigorous verification, ProCal offers a lightweight, training-free post-hoc adjustment that directly targets ranking miscalibration in VLM-based OVOD pipelines. This could be practically significant for improving detection of unseen categories without modifying model weights or requiring additional data, and it explicitly credits the use of an existing frozen VLM backbone.
major comments (3)
- [Abstract] Abstract: The central empirical claim of a +2.5 APr improvement on OV-LVIS provides no implementation details, error bars, number of runs, or comparisons to other post-hoc scoring adjustments or baselines; this is load-bearing because the gain is the primary evidence for the method's utility.
- [Abstract] Abstract: The load-bearing premise that 'pretrained VLMs enable to classify foreground and background regions' in a manner that transfers useful localization-aware scores to novel categories is presented only as an observation with no derivation, ablation, or test for out-of-distribution transfer; if this does not hold, the combined proposal prior cannot systematically improve novel-object ranking.
- [Analyses] Analyses section: The claims that ProCal 'suppresses false novel activation on background proposals' and 'consistently ranks true novel proposals above background and partial novel proposals' lack quantitative metrics (e.g., precision-recall shifts or ranking position statistics before/after calibration) to substantiate the mechanism.
minor comments (2)
- [Abstract] Abstract contains multiple typographical errors including 'dur ing', 'en able', and 'Pro posal'.
- [Abstract] The final sentence of the abstract ('The analyses show that proposal-level localization-aware reranking effects to mitigate ranking miscalibration for novel objects.') is grammatically incomplete.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We respond to each major comment below and will make revisions to strengthen the presentation of empirical results and supporting analyses.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central empirical claim of a +2.5 APr improvement on OV-LVIS provides no implementation details, error bars, number of runs, or comparisons to other post-hoc scoring adjustments or baselines; this is load-bearing because the gain is the primary evidence for the method's utility.
Authors: We agree that the abstract would benefit from additional context on the experimental protocol. In the revision we will expand the abstract to note that the reported +2.5 APr is the mean over three independent runs, that standard deviations appear in the main results table, and that direct comparisons against other post-hoc scoring baselines are provided in the experiments section. revision: yes
-
Referee: [Abstract] Abstract: The load-bearing premise that 'pretrained VLMs enable to classify foreground and background regions' in a manner that transfers useful localization-aware scores to novel categories is presented only as an observation with no derivation, ablation, or test for out-of-distribution transfer; if this does not hold, the combined proposal prior cannot systematically improve novel-object ranking.
Authors: Section 3.1 already contains initial quantitative support showing that VLM patch-level scores correlate with object presence on both base and novel classes. To directly address the OOD transfer question we will add an explicit ablation that measures foreground/background classification accuracy separately on novel versus base categories; this will be included in the revised manuscript. revision: partial
-
Referee: [Analyses] Analyses section: The claims that ProCal 'suppresses false novel activation on background proposals' and 'consistently ranks true novel proposals above background and partial novel proposals' lack quantitative metrics (e.g., precision-recall shifts or ranking position statistics before/after calibration) to substantiate the mechanism.
Authors: We will augment the analyses section with the requested quantitative metrics: mean rank change for true novel proposals and the reduction in background false-positive rate before versus after ProCal, computed on the OV-LVIS validation set. These numbers will be added to the revised version. revision: yes
Circularity Check
No circularity; post-hoc scoring method rests on empirical observation without reduction to inputs
full rationale
The paper introduces ProCal as an inference-time adjustment that combines localization-aware foreground and background-suppression scores derived from a frozen VLM, motivated by the stated observation that pretrained VLMs distinguish foreground/background regions. No equations, parameter fits, or derivations appear in the provided text that reduce the proposal prior or ranking improvement to a self-referential definition, fitted subset, or self-citation chain. The central performance claim (APr +2.5 on OV-LVIS) is presented as an empirical outcome of the reranking effect rather than a quantity forced by construction from the method's own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Self-augmentation: General- izing deep networks to unseen classes for few-shot learning,
J.-W. Seo, H.-G. Jung, and S.-W. Lee, “Self-augmentation: General- izing deep networks to unseen classes for few-shot learning,”IEEE Trans. Neural Netw., vol. 138, pp. 140–149, 2021
2021
-
[2]
View-independent human action recognition with volume motion template on single stereo camera,
M.-C. Roh, H.-K. Shin, and S.-W. Lee, “View-independent human action recognition with volume motion template on single stereo camera,”Pattern Recog., vol. 31, no. 7, pp. 639–647, 2010
2010
-
[3]
Holistic approaches to music genre classification using efficient transfer and deep learning techniques,
S. K. Prabhakar and S.-W. Lee, “Holistic approaches to music genre classification using efficient transfer and deep learning techniques,” Expert Syst. Appl., vol. 211, p. 118636, 2023
2023
-
[4]
Learning transferable visual models from natural language supervision,
A. Radfordet al., “Learning transferable visual models from natural language supervision,” inInt. Conf. Mach. Learn. (ICML), vol. 139, 2021, pp. 8748–8763
2021
-
[5]
Open-vocabulary object detection via vision and language knowledge distillation,
X. Gu, T.-Y . Lin, W. Kuo, and Y . Cui, “Open-vocabulary object detection via vision and language knowledge distillation,” inInt. Conf. Learn. Represent. (ICLR), 2022
2022
-
[6]
Detect- ing twenty-thousand classes using image-level supervision,
X. Zhou, R. Girdhar, A. Joulin, P. Kr ¨ahenb¨uhl, and I. Misray, “Detect- ing twenty-thousand classes using image-level supervision,” inProc. Eur. Conf. Comput. Vis. (ECCV), 2022
2022
-
[7]
Region-aware pretraining for open-vocabulary object detection with vision transformers,
D. Kim, A. Angelova, and W. Kuo, “Region-aware pretraining for open-vocabulary object detection with vision transformers,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recog. (CVPR), 2023
2023
-
[8]
DST-Det: Simple dynamic self-training for open-vocabulary object detection,
S. Xu, X. Li, S. Wu, W. Zhang, Y . Tong, and C. C. Loy, “DST-Det: Simple dynamic self-training for open-vocabulary object detection,” inInt. Conf. Learn. Represent. (ICLR), 2024
2024
-
[9]
Open- vocabulary object detection upon frozen vision and language models,
W. Kuo, Y . Cui, X. Gu, A. Piergiovanni, and A. Angelova, “Open- vocabulary object detection upon frozen vision and language models,” inInt. Conf. Learn. Represent. (ICLR), 2023
2023
-
[10]
CLIPSelf: Vision transformer distills itself for open- vocabulary dense prediction,
S. Wuet al., “CLIPSelf: Vision transformer distills itself for open- vocabulary dense prediction,” inInt. Conf. Learn. Represent. (ICLR), 2024
2024
-
[11]
OV-DQUO: Open-vocabulary detr with denoising text query training and open-world unknown objects supervision,
J. Wanget al., “OV-DQUO: Open-vocabulary detr with denoising text query training and open-world unknown objects supervision,” inProc. AAAI Conf. Artif. Intell. (AAAI), 2025
2025
-
[12]
CORA: Adapting clip for open- vocabulary detection with region prompting and anchor pre-matching,
X. Wu, F. Zhu, R. Zhao, and H. Li, “CORA: Adapting clip for open- vocabulary detection with region prompting and anchor pre-matching,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recog. (CVPR), 2023
2023
-
[13]
Faster R-CNN: Towards real- time object detection with region proposal networks,
S. Ren, K. He, R. Girshick, and J. Sun, “Faster R-CNN: Towards real- time object detection with region proposal networks,” inAdv. Neural Inf. Process. Syst. (NeurIPS), 2015
2015
-
[14]
Nighttime face recog- nition at large standoff: Cross-distance and cross-spectral matching,
D. Kang, H. Han, A. K. Jain, and S.-W. Lee, “Nighttime face recog- nition at large standoff: Cross-distance and cross-spectral matching,” Pattern Recog., vol. 47, no. 12, pp. 3750–3766, 2014
2014
-
[15]
Plausmal-gan: Plausible malware training based on generative adversarial networks for analo- gous zero-day malware detection,
D.-O. Won, Y .-N. Jang, and S.-W. Lee, “Plausmal-gan: Plausible malware training based on generative adversarial networks for analo- gous zero-day malware detection,”IEEE Trans. Emerg. Top. Comput., vol. 11, no. 1, pp. 82–94, 2022
2022
-
[16]
Pill-id: Matching and retrieval of drug pill images,
Y .-B. Lee, U. Park, A. K. Jain, and S.-W. Lee, “Pill-id: Matching and retrieval of drug pill images,”Pattern Recog. Lett., vol. 33, no. 7, pp. 904–910, 2012
2012
-
[17]
PerceptionCLIP: Visual classification by inferring and conditioning on contexts,
B. An, S. Zhu, M.-A. Panaitescu-Liess, C. K. Mummadi, and F. Huang, “PerceptionCLIP: Visual classification by inferring and conditioning on contexts,” inInt. Conf. Learn. Represent. (ICLR), 2024
2024
-
[18]
RegionCLIP: Region-based language-image pretrain- ing,
Y . Zhonget al., “RegionCLIP: Region-based language-image pretrain- ing,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recog. (CVPR), 2022
2022
-
[19]
Scaling up visual and vision-language representation learning with noisy text supervision,
C. Jiaet al., “Scaling up visual and vision-language representation learning with noisy text supervision,” inInt. Conf. Mach. Learn. (ICML), 2021
2021
-
[20]
Imagenet large scale visual recognition challenge,
O. Russakovskyet al., “Imagenet large scale visual recognition challenge,” inAdv. Neural Inf. Process. Syst. (NeurIPS), 2012
2012
-
[21]
Discriminative context learning with gated recurrent unit for group activity recognition,
P.-S. Kim, D.-G. Lee, and S.-W. Lee, “Discriminative context learning with gated recurrent unit for group activity recognition,”Pattern Recog., vol. 76, pp. 149–161, 2018
2018
-
[22]
Robust sign language recognition by combining manual and non-manual features based on conditional random field and support vector machine,
H.-D. Yang and S.-W. Lee, “Robust sign language recognition by combining manual and non-manual features based on conditional random field and support vector machine,”Pattern Recog. Lett., vol. 34, no. 16, pp. 2051–2056, 2013
2051
-
[23]
Leveraging coupled interaction for multimodal alzheimer’s disease diagnosis,
Y . Shi, H.-I. Suk, Y . Gao, S.-W. Lee, and D. Shen, “Leveraging coupled interaction for multimodal alzheimer’s disease diagnosis,”IEEE Trans. Neural Netw. Learn. Syst., vol. 31, no. 1, pp. 186–200, 2019
2019
-
[24]
Microsoft COCO: Common objects in context,
T.-Y . Linet al., “Microsoft COCO: Common objects in context,” in Proc. Eur. Conf. Comput. Vis. (ECCV), 2014
2014
-
[25]
LVIS: A dataset for large vocabulary instance segmentation,
A. Gupta, P. Doll ´ar, and R. Girshick, “LVIS: A dataset for large vocabulary instance segmentation,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recog. (CVPR), 2019
2019
-
[26]
Open-vocabulary object detection using captions,
A. Zareian, K. D. Rosa, D. H. Hu, and S.-F. Chang, “Open-vocabulary object detection using captions,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recog. (CVPR), 2021
2021
-
[27]
NoOVD: Novel category discovery and embedding for open-vocabulary object detection,
Y . Zhang, R. Han, Z. Chen, W. Feng, and L. Wan, “NoOVD: Novel category discovery and embedding for open-vocabulary object detection,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recog. (CVPR), 2026
2026
-
[28]
Reproducible scaling laws for contrastive language- image learning,
M. Chertiet al., “Reproducible scaling laws for contrastive language- image learning,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recog. (CVPR), 2023
2023
-
[29]
Cascaded multitask 3-d fully convolutional networks for pancreas segmentation,
J. Xueet al., “Cascaded multitask 3-d fully convolutional networks for pancreas segmentation,”IEEE Trans. Cybern., vol. 51, no. 4, pp. 2153–2165, 2019
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.