Implicit vs. Explicit Prompting Strategies for LVLMs in Referential Communication
Pith reviewed 2026-06-27 01:49 UTC · model grok-4.3
The pith
LVLMs can coordinate efficient referring expressions only when explicitly prompted.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
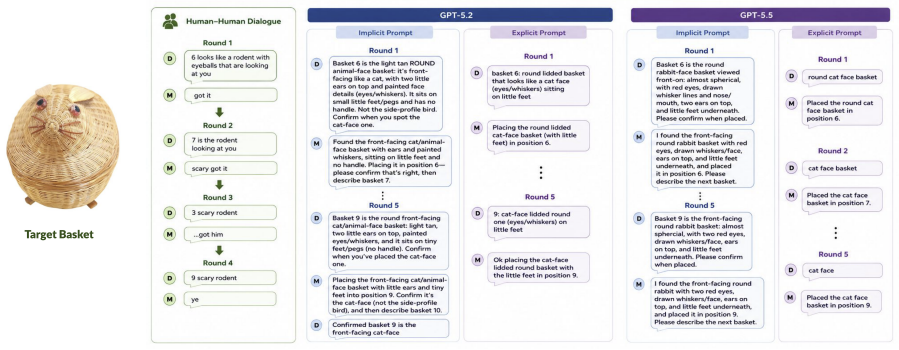
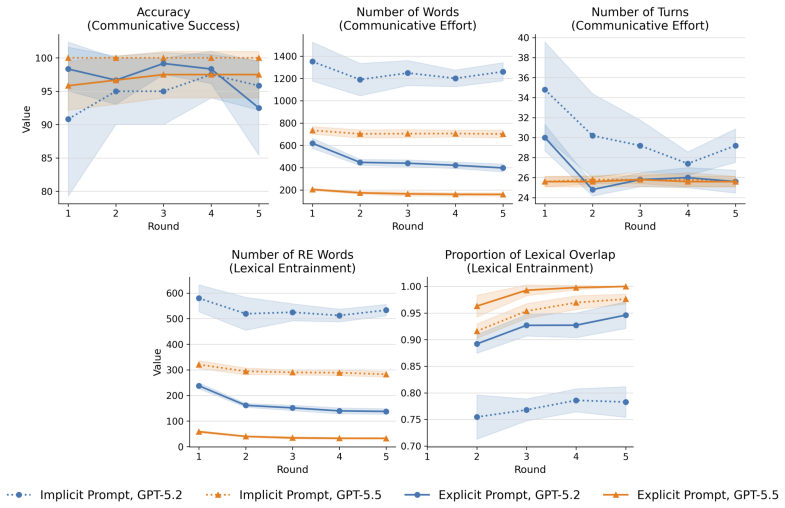
When task differences are controlled, LVLMs replicate the ability to coordinate on efficient referring expressions under explicit prompting but fail to infer the need for such efficiency from implicit prompts, indicating that the divergent results in prior work were due to prompting style.
What carries the argument
The controlled comparison of explicit and implicit prompting in referential communication tasks for large vision-language models (LVLMs).
If this is right
- Task differences do not account for the contradictory findings in previous studies on LVLMs.
- LVLMs require explicit prompting to produce efficient referring expressions.
- Implicit prompts do not lead models to spontaneously use efficient communication strategies.
- Human and AI systems differ in their ability to infer communicative efficiency from context.
Where Pith is reading between the lines
- If this pattern holds, AI systems may need additional training or architectures to handle implicit communicative cues.
- Human-AI interactions in collaborative settings could require more explicit instructions for efficiency.
- Testing this in other domains like dialogue or instruction following could reveal if the limitation is general.
Load-bearing premise
The premise that controlling for task differences between the two prior studies successfully isolates prompting style as the sole cause of the divergent results without introducing new confounds.
What would settle it
A result in which the models produce inefficient referring expressions under explicit prompts or efficient ones under implicit prompts in the controlled experimental setup.
Figures








read the original abstract
Two recent studies (Jones et al. (2026); Zeng et al. (2026)) reach apparently contradictory conclusions about whether LVLMs can coordinate on efficient referring expressions. We control for task differences between the studies while directly comparing their prompting styles. We replicate the finding that models can coordinate efficient referring expressions when explicitly prompted to do so, suggesting that other task differences are not responsible for divergent results. However, we also find that the same models fail to infer the need for communicative efficiency from a more implicit prompt, highlighting critical differences between how humans and AI systems communicate.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that controlling for task differences between Jones et al. (2026) and Zeng et al. (2026) isolates prompting style as the cause of divergent results on LVLM referential communication. Explicit prompting replicates the finding that models can coordinate on efficient referring expressions, while implicit prompting fails to elicit inference of the need for communicative efficiency, unlike human behavior.
Significance. If the task controls are robust, the work would clarify why prior studies reached contradictory conclusions and provide evidence that LVLMs lack spontaneous pragmatic inference of efficiency goals. This has implications for prompt engineering and for understanding the limits of current models' communicative abilities relative to humans.
major comments (1)
- [Methods] Methods section (task equalization procedure): The central claim requires that the authors' control successfully equates the setups from Jones et al. (2026) and Zeng et al. (2026) in all respects except prompt explicitness. The manuscript states that task differences were controlled but supplies no description of the original differences or the modifications applied (e.g., to referent set size, visual complexity, turn structure, or success metric). Without this information the isolation assumption remains unverified and the observed difference between conditions could stem from uncontrolled factors.
minor comments (2)
- [Abstract] Abstract: The sentence 'we control for task differences between the studies' would be clearer if it briefly indicated which dimensions were equalized.
- [Results] Results: Ensure that all reported findings include trial counts, statistical tests, and effect sizes so that the strength of the explicit vs. implicit contrast can be evaluated.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address the major comment on the Methods section below and agree that additional detail is warranted.
read point-by-point responses
-
Referee: [Methods] Methods section (task equalization procedure): The central claim requires that the authors' control successfully equates the setups from Jones et al. (2026) and Zeng et al. (2026) in all respects except prompt explicitness. The manuscript states that task differences were controlled but supplies no description of the original differences or the modifications applied (e.g., to referent set size, visual complexity, turn structure, or success metric). Without this information the isolation assumption remains unverified and the observed difference between conditions could stem from uncontrolled factors.
Authors: We agree that the Methods section would benefit from a more explicit description of the task differences between Jones et al. (2026) and Zeng et al. (2026) and the specific controls we implemented. In the revised manuscript, we will add a dedicated subsection in Methods that outlines the original experimental setups from both studies, including details on referent set size, visual complexity, turn structure, and success metrics. We will then describe the modifications made to equalize these factors while preserving the distinction in prompting style. This will allow readers to verify that the observed differences are attributable to prompt explicitness. revision: yes
Circularity Check
No significant circularity in empirical replication study
full rationale
This is an empirical comparison study that replicates prior experimental findings on LVLMs while controlling for task differences between two cited works. It contains no mathematical derivations, fitted parameters presented as predictions, self-definitional equations, or ansatzes smuggled via citation. The central claims rest on new experimental results comparing explicit vs. implicit prompts rather than any chain that reduces to its own inputs by construction. Self-citations to Jones et al. (2026) and Zeng et al. (2026) report independent prior empirical results and do not invoke uniqueness theorems or load-bearing self-referential premises. The paper is self-contained against external benchmarks as an experimental report.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Prompting style can be isolated as the variable responsible for differences in model output when tasks are controlled.
Reference graph
Works this paper leans on
-
[1]
Start with the FIRST basket in the 2x6 grid (top-left, basket 1), then move left-to-right across the top row (baskets 1-6), then left-to-right across the bottom row (baskets 7-12)
By default, describe the baskets in strict order from basket 1 to basket 12. Start with the FIRST basket in the 2x6 grid (top-left, basket 1), then move left-to-right across the top row (baskets 1-6), then left-to-right across the bottom row (baskets 7-12). Do not skip around or reorder the sequence on your own
-
[2]
You may temporarily return to an EARLIER basket only when your MATCHER partner explicitly asks for clarification about that basket. When you do this, clearly say which basket you are revisiting (for example,'Let me clarify basket 3 again...') and then resume with the lowest- numbered basket that still needs a clear description
-
[3]
On each turn, focus your description on exactly ONE basket in this sequence (normally the next basket that has not yet been clearly described)
-
[4]
Describe the unique, visually distinctive features of the current basket so your partner can locate the correct basket in their pool and place it in the right position
-
[5]
Answer the MATCHER's clarification questions about the current basket
-
[6]
Keep the conversation focused on the baskets and their visual properties
-
[7]
reasoning
Encourage the MATCHER to confirm when they think they have placed a basket correctly before you move on to the next basket. COMMUNICATION RULES: - Be concise but informative; favor short turns over longer ones. - Focus on the most visual features that best distinguish this basket from the others. These features include: shape, size, material, handles, per...
-
[8]
Pay attention carefully to the DIRECTOR's descriptions of the baskets in order
-
[9]
Do not skip ahead to later positions while an earlier position is still empty or uncertain
Always reason about and talk about the LOWEST-NUMBERED empty position in the 12-position sequence. Do not skip ahead to later positions while an earlier position is still empty or uncertain
-
[10]
Ask clarification questions when the description could match multiple baskets
-
[11]
Explain what features you are using to narrow down the possibilities
-
[12]
reasoning
Indicate when you think you have identified the right basket and are ready to move on. COMMUNICATION RULES: - You may ask targeted questions about shape, size, material, handles, perspective, color, and distinctive details. - Be transparent about uncertainty: say when you are unsure or need more detail. - Use phrases like'I think I found it...','I'm not s...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.