Agentic Hybrid RAG for Evidence-Grounded Muon Collider Analysis
Pith reviewed 2026-06-27 11:25 UTC · model grok-4.3
The pith
Agentic hybrid RAG outperforms standard retrieval and RAG baselines on muon collider literature tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
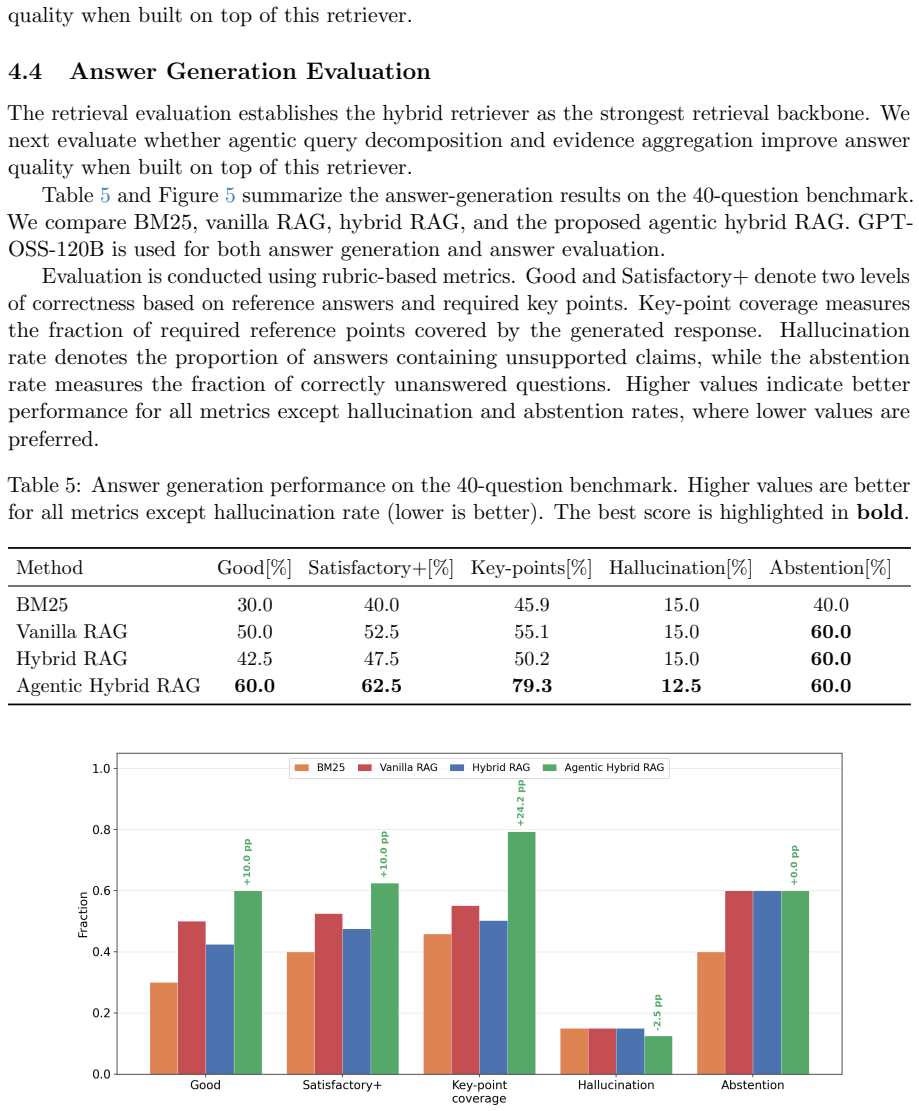
Agentic hybrid RAG combines hybrid retrieval with an agentic reasoning module that performs query decomposition, controlled evidence expansion, and grounded answer synthesis; when tested on the new muon collider benchmark this combination produces higher retrieval effectiveness, answer quality, evidence coverage, and factual grounding than representative retrieval-only and standard RAG baselines.
What carries the argument
The agentic hybrid RAG framework, which integrates a hybrid retriever (sparse lexical and dense semantic) with an agentic reasoning module for query decomposition, evidence expansion, and grounded answer generation.
If this is right
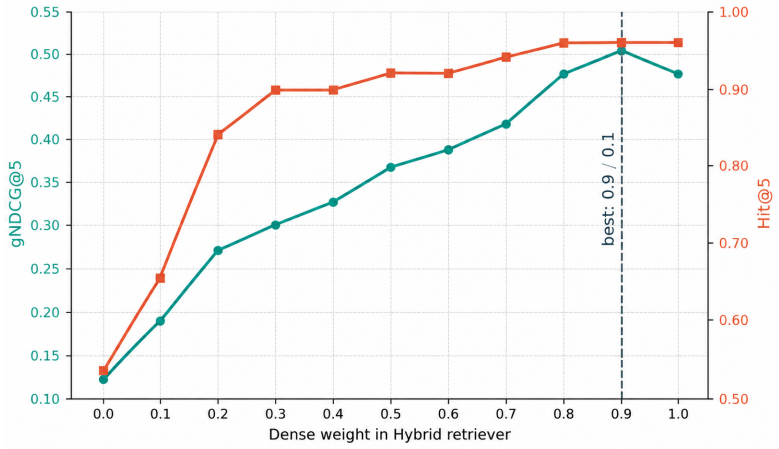
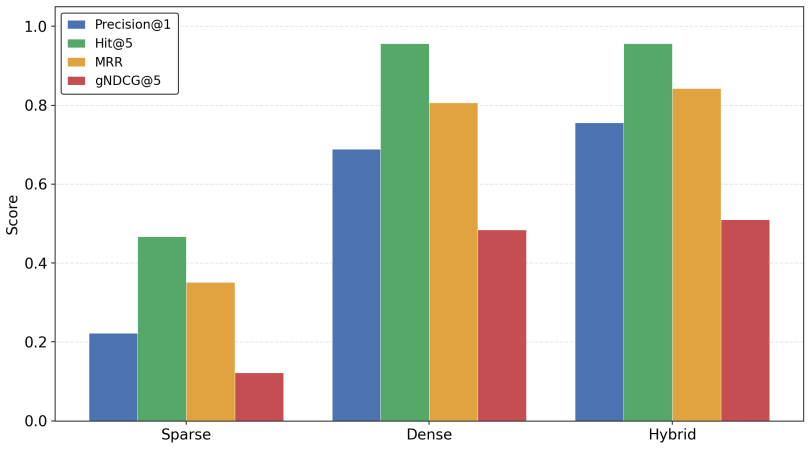
- Hybrid retrieval supplies the strongest single retrieval backbone for scientific literature in this domain.
- Agentic reasoning contributes most when used for controlled evidence expansion and answer synthesis rather than raw retrieval.
- The released benchmark enables reproducible comparison of future retrieval-augmented systems for high-energy physics questions.
- The overall approach supplies a concrete foundation for building larger-scale evidence-grounded analysis agents over HEP literature.
Where Pith is reading between the lines
- The same hybrid-plus-agentic pattern could be tested on other collider or neutrino experiments whose literature is similarly scattered across subfields.
- If the benchmark metrics track actual physicist productivity, the framework could be embedded in daily literature-review tools rather than used only for one-off queries.
- Extending the agentic module to include citation-graph traversal or cross-paper consistency checks would be a natural next increment that stays within the same architecture.
Load-bearing premise
The curated literature corpus and the retrieval/answer-generation benchmarks accurately represent the real information needs and challenges faced by muon collider researchers.
What would settle it
A follow-up experiment that applies the same agentic hybrid RAG pipeline and baselines to a fresh collection of muon collider queries drawn from papers published after the benchmark corpus cutoff and measures whether the performance advantage disappears.
Figures

read the original abstract
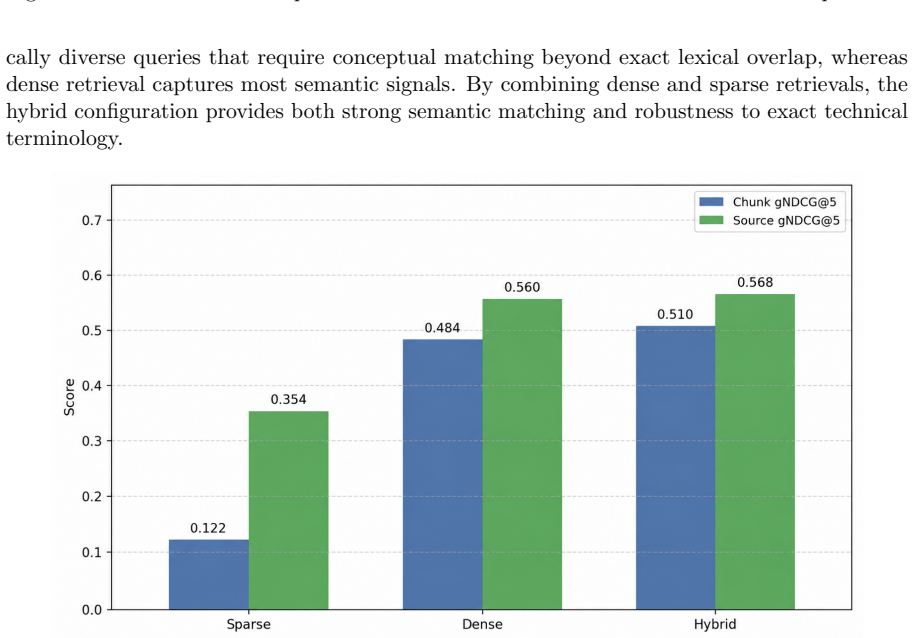
Muon collider research spans accelerator physics, detector instrumentation, and high-energy phenomenology, with relevant evidence scattered across a rapidly expanding and heterogeneous body of scientific literature. As high-energy physics (HEP) increasingly explores agent-assisted analysis workflows, efficiently locating, integrating, and verifying scientific evidence becomes an essential capability. While retrieval-augmented generation (RAG) offers a promising framework for scientific question answering, integrating agentic reasoning without compromising retrieval precision remains a key challenge. In this work, we present agentic hybrid RAG, an evidence-grounded RAG framework for muon collider research. The framework combines a hybrid retriever, integrating sparse lexical and dense semantic retrieval, with an agentic reasoning module for query decomposition, evidence expansion, and grounded answer generation. To enable systematic evaluation, we construct the first benchmark for retrieval-augmented scientific question answering in the muon collider domain, comprising a curated literature corpus together with dedicated retrieval and answer-generation benchmarks covering major detector and physics research topics. Extensive evaluation shows that hybrid retrieval provides the strongest retrieval backbone, while agentic reasoning is most effective for controlled evidence expansion and answer synthesis. Built on this principle, agentic hybrid RAG consistently outperforms representative retrieval and RAG baselines in retrieval effectiveness, answer quality, evidence coverage, and factual grounding. Together, the benchmark and framework provide a foundation for evidence-grounded scientific question answering and future HEP analysis agents operating over large-scale scientific literature.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an agentic hybrid RAG framework for evidence-grounded question answering in muon collider research. It combines a hybrid retriever (sparse lexical + dense semantic) with an agentic reasoning module for query decomposition, evidence expansion, and grounded answer generation. The authors construct a new benchmark comprising a curated literature corpus and dedicated retrieval/answer-generation tasks on detector and physics topics. They claim that hybrid retrieval provides the strongest backbone while agentic reasoning aids controlled expansion, and that the full framework consistently outperforms representative retrieval and RAG baselines in retrieval effectiveness, answer quality, evidence coverage, and factual grounding.
Significance. If the empirical claims can be substantiated with full experimental details, the work would offer a concrete starting point for AI-assisted navigation of rapidly growing HEP literature in an emerging domain. The domain-specific benchmark construction is a positive step toward systematic evaluation, and the hybrid-plus-agentic design directly targets known precision challenges in scientific RAG. These elements could support future development of analysis agents, provided the benchmark's representativeness is demonstrated.
major comments (2)
- [Abstract] Abstract: the central claim that 'agentic hybrid RAG consistently outperforms representative retrieval and RAG baselines' is asserted without any description of experimental setup, baseline implementations, metrics, statistical significance testing, or controls for confounds such as data leakage. The manuscript supplies no Methods or Results sections containing these details, rendering the primary empirical result impossible to evaluate.
- [Abstract] Abstract: the muon collider benchmark is presented as author-constructed without any account of query selection criteria, ground-truth annotation process, inter-annotator agreement, or external validation against actual physicist workflows. This is load-bearing for the claim that measured gains in evidence coverage and factual grounding reflect practical utility rather than benchmark-specific artifacts.
minor comments (1)
- [Abstract] The abstract is information-dense; separating the framework description, benchmark contribution, and empirical findings into distinct sentences would improve readability.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address the two major comments point-by-point below. Both comments correctly identify that the abstract is too terse; we will revise the abstract and, where needed, expand the Methods section to make all experimental and benchmark details explicit and self-contained.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'agentic hybrid RAG consistently outperforms representative retrieval and RAG baselines' is asserted without any description of experimental setup, baseline implementations, metrics, statistical significance testing, or controls for confounds such as data leakage. The manuscript supplies no Methods or Results sections containing these details, rendering the primary empirical result impossible to evaluate.
Authors: We acknowledge that the abstract, as a concise summary, does not describe the experimental setup, baselines, metrics, statistical tests, or leakage controls. The full manuscript contains a Methods section that specifies the hybrid retriever (sparse + dense), agentic reasoning components, baseline implementations, the full set of metrics, and leakage-mitigation steps, together with a Results section that reports the comparative numbers and significance tests. Nevertheless, to eliminate any ambiguity we will revise the abstract to include a short statement of the experimental framework and will ensure the Methods and Results headings and content are fully explicit in the revised version. revision: yes
-
Referee: [Abstract] Abstract: the muon collider benchmark is presented as author-constructed without any account of query selection criteria, ground-truth annotation process, inter-annotator agreement, or external validation against actual physicist workflows. This is load-bearing for the claim that measured gains in evidence coverage and factual grounding reflect practical utility rather than benchmark-specific artifacts.
Authors: We agree that the abstract provides no information on query selection, annotation, inter-annotator agreement, or workflow validation. The Methods section of the manuscript describes the literature corpus curation and the construction of the retrieval and answer-generation tasks covering detector and physics topics. In the revision we will expand this description to detail the query selection criteria, the ground-truth annotation procedure (including expert involvement), any inter-annotator agreement statistics, and the steps taken to align the benchmark with real physicist workflows. revision: yes
Circularity Check
No significant circularity; evaluation rests on external baselines
full rationale
The paper constructs a domain-specific benchmark and reports empirical outperformance of its agentic hybrid RAG framework against representative external retrieval and RAG baselines. No self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations appear in the provided text. The central claims derive from comparative metrics on retrieval effectiveness, answer quality, evidence coverage, and factual grounding rather than reducing to the framework's own inputs by construction. The benchmark curation is a standard methodological choice and does not create circularity under the enumerated patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Automating high energy physics data analysis with llm-powered agents
Eli Gendreau-Distler, Joshua Ho, Dongwon Kim, Luc Tomas Le Pottier, Haichen Wang, and Chengxi Yang. Automating high energy physics data analysis with llm-powered agents. arXiv preprint arXiv:2512.07785, 2025
arXiv 2025
-
[2]
Moreno, Samuel Bright-Thonney, Andrzej Novak, Dolores Garcia, and Philip Harris
Eric A. Moreno, Samuel Bright-Thonney, Andrzej Novak, Dolores Garcia, and Philip Harris. Ai agents can already autonomously perform experimental high energy physics.arXiv preprint arXiv:2603.20179, 2026
Pith/arXiv arXiv 2026
-
[3]
Survey of hallucination in natural language generation
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Yejin Bang, Andrea Madotto, and Pascale Fung. Survey of hallucination in natural language generation. ACM Computing Surveys, 55(12):1–38, 2023
2023
-
[4]
Retrieval- augmented generation for knowledge-intensive nlp tasks.Advances in Neural Information Processing Systems, 33:9459–9474, 2020
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich K¨ uttler, Mike Lewis, Wen-tau Yih, Tim Rockt¨ aschel, et al. Retrieval- augmented generation for knowledge-intensive nlp tasks.Advances in Neural Information Processing Systems, 33:9459–9474, 2020
2020
-
[5]
Dense passage retrieval for open-domain question answering
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. InProceedings of EMNLP, pages 6769–6781, 2020
2020
-
[6]
Sentence-bert: Sentence embeddings using siamese bert-networks
Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert-networks. InProceedings of EMNLP-IJCNLP, pages 3982–3992, 2019
2019
-
[7]
Stephen Robertson and Hugo Zaragoza. The Probabilistic Relevance Framework: BM25 and beyond.Foundations and Trends®in Information Retrieval, 4(1-2):1–174, 2009. doi: 10.1561/1500000019
-
[8]
Gordon V. Cormack, Charles L. A. Clarke, and Stefan B¨ uttcher. Reciprocal rank fusion outperforms Condorcet and individual rank learning methods. InProceedings of the 32nd Annual International ACM SIGIR Conference, pages 758–759. ACM, 2009. doi: 10.1145/1571941.1572114
-
[9]
Aditi Singh, Abul Ehtesham, Saket Kumar, Tala Talaei Khoei, and Athanasios V Vasi- lakos. Agentic retrieval-augmented generation: A survey on agentic rag.arXiv preprint arXiv:2501.09136, 2025
Pith/arXiv arXiv 2025
-
[11]
C. Aime et al. Muon collider physics summary. Technical report, International Muon Collider Collaboration, 2022. arXiv:2203.07256
arXiv 2022
-
[12]
Billion-scale similarity search with gpus
Jeff Johnson, Matthijs Douze, and Herv´ e J´ egou. Billion-scale similarity search with gpus. IEEE Transactions on Big Data, 7(3):535–547, 2019
2019
-
[13]
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Meng Wang, and Haofen Wang. Retrieval-augmented generation for large language models: A survey.arXiv preprint arXiv:2312.10997, 2024. 15
Pith/arXiv arXiv 2024
-
[14]
Towards a RAG- based summarization for the Electron Ion Collider.JINST, 19(07):C07006, 2024
Karthik Suresh, Neeltje Kackar, Luke Schleck, and Cristiano Fanelli. Towards a RAG- based summarization for the Electron Ion Collider.JINST, 19(07):C07006, 2024. doi: 10.1088/1748-0221/19/07/C07006
-
[15]
Tina J. Jat, T. Ghosh, and Karthik Suresh. Retrieval-augmented question answering over scientific literature for the electron-ion collider.arXiv preprint arXiv:2604.02259, 2026
arXiv 2026
-
[16]
Seeing the Forest Through the Trees: Knowledge Retrieval for Streamlining Particle Physics Analysis
James McGreivy, Blaise Delaney, Anja Beck, and Mike Williams. Seeing the Forest Through the Trees: Knowledge Retrieval for Streamlining Particle Physics Analysis. 2025
2025
-
[17]
MITRA: An AI Assistant for Knowledge Retrieval in Physics Collaborations
Abhishikth Mallampalli and Sridhara Dasu. MITRA: An AI Assistant for Knowledge Retrieval in Physics Collaborations. In39th Annual Conference on Neural Information Processing Systems: Includes Machine Learning and the Physical Sciences (ML4PS), 2026
2026
-
[18]
Kyle Lo, Lucy Lu Wang, Mark Neumann, Rodney Kinney, and Daniel S. Weld. S2orc: The semantic scholar open research corpus. InProceedings of ACL, pages 4969–4983, 2020
2020
-
[19]
Scibert: A pretrained language model for scientific text
Iz Beltagy, Kyle Lo, and Arman Cohan. Scibert: A pretrained language model for scientific text. InProceedings of EMNLP-IJCNLP, pages 3615–3620, 2019
2019
-
[20]
Grobid: Combining automatic bibliographic data recognition and term extraction for scholarship publications
Patrice Lopez. Grobid: Combining automatic bibliographic data recognition and term extraction for scholarship publications. InProceedings of ECDL, pages 473–474, 2009
2009
-
[21]
Ragas: Automated evaluation of retrieval augmented generation.arXiv preprint arXiv:2309.15217, 2023
Shahul Es, Jithin James, Luis Espinosa-Anke, and Steven Schockaert. Ragas: Automated evaluation of retrieval augmented generation.arXiv preprint arXiv:2309.15217, 2023
Pith/arXiv arXiv 2023
-
[22]
Rouge: A package for automatic evaluation of summaries
Chin-Yew Lin. Rouge: A package for automatic evaluation of summaries. InText Summa- rization Branches Out, pages 74–81, 2004
2004
-
[23]
Voorhees
Ellen M. Voorhees. The trec-8 question answering track report. InProceedings of TREC, 1999
1999
-
[24]
Cumulated gain-based evaluation of ir techniques
Kalervo J¨ arvelin and Jaana Kek¨ al¨ ainen. Cumulated gain-based evaluation of ir techniques. ACM Transactions on Information Systems, 20(4):422–446, 2002
2002
-
[25]
J. P. Delahaye et al. Muon colliders.arXiv preprint arXiv:1901.06150, 2019
Pith/arXiv arXiv 1901
-
[26]
K. M. Black et al. Muon Collider Forum report.JINST, 19(02):T02015, 2024. doi: 10.1088/1748-0221/19/02/T02015
-
[27]
Muon Collider Physics Summary
Chiara Aime et al. Muon Collider Physics Summary. 2022
2022
-
[28]
C. Accettura et al. Interim report for the international muon collider collaboration.arXiv preprint arXiv:2407.12450, 2024
arXiv 2024
-
[29]
Searching for heavy leptoquarks at a muon collider.JHEP, 12:047, 2021
Sitian Qian, Congqiao Li, Qiang Li, Fanqiang Meng, Jie Xiao, Tianyi Yang, Meng Lu, and Zhengyun You. Searching for heavy leptoquarks at a muon collider.JHEP, 12:047, 2021. doi: 10.1007/JHEP12(2021)047
-
[30]
Searching for Majorana neutrinos at a same-sign muon collider.Phys
Ruobing Jiang, Tianyi Yang, Sitian Qian, Yong Ban, Jingshu Li, Zhengyun You, and Qiang Li. Searching for Majorana neutrinos at a same-sign muon collider.Phys. Rev. D, 109(3): 035020, 2024. doi: 10.1103/PhysRevD.109.035020
-
[31]
Searches for multi-Z boson productions and anomalous gauge boson couplings at a muon collider
Ruobing Jiang, Chuqiao Jiang, Alim Ruzi, Tianyi Yang, Yong Ban, and Qiang Li. Searches for multi-Z boson productions and anomalous gauge boson couplings at a muon collider. Chin. Phys. C, 48(10):103102, 2024. doi: 10.1088/1674-1137/ad5661. 16
-
[32]
Barger, M
Vernon D. Barger, M. S. Berger, J. F. Gunion, and Tao Han. S-channel Higgs boson production at a muon muon collider.Phys. Rev. Lett., 75:1462–1465, 1995. doi: 10.1103/ PhysRevLett.75.1462
1995
-
[33]
Neuffer, M
D. Neuffer, M. Palmer, Y. Alexahin, C. Ankenbrandt, and J. P. Delahaye. A Muon Collider as a Higgs Factory. 2013
2013
-
[34]
Celada et al
E. Celada et al. Probing higgs-muon interactions at a multi-tev muon collider.Journal of High Energy Physics, 2024(8):21, 2024
2024
-
[35]
Vector boson fusion at multi-TeV muon colliders.JHEP, 09:080, 2020
Antonio Costantini, Federico De Lillo, Fabio Maltoni, Luca Mantani, Olivier Mattelaer, Richard Ruiz, and Xiaoran Zhao. Vector boson fusion at multi-TeV muon colliders.JHEP, 09:080, 2020. doi: 10.1007/JHEP09(2020)080
-
[36]
Electroweak couplings of the higgs boson at a multi-tev muon collider.Physical Review D, 103:013002, 2021
Tao Han, Da Liu, Ian Low, and Xing Wang. Electroweak couplings of the higgs boson at a multi-tev muon collider.Physical Review D, 103:013002, 2021
2021
-
[37]
Abbott et al
B. Abbott et al. Anomalous production of massive gauge boson pairs at muon colliders. Physical Review D, 108:093009, 2023
2023
-
[38]
N. V. Mokhov et al. Muon collider interaction region and machine-detector interface design. arXiv preprint arXiv:1202.3979, 2011
Pith/arXiv arXiv 2011
-
[39]
Bartosik et al
N. Bartosik et al. Detector and physics performance at a muon collider.Journal of Instrumentation, 15(05):P05001, 2020
2020
-
[40]
Collamati, C
F. Collamati, C. Curatolo, D. Lucchesi, A. Mereghetti, N. Mokhov, M. Palmer, and P. Sala. Advanced assessment of beam-induced background at a muon collider.Journal of Instrumentation, 16(11):P11009, 2021
2021
-
[41]
Lucchesi et al
D. Lucchesi et al. Detector performance studies at a muon collider.PoS EPS-HEP2019, page 118, 2020
2020
-
[42]
Ronak Pradeep, Rodrigo Nogueira, and Jimmy Lin. RRF102: Meeting the TREC-COVID challenge with a 100+ runs ensemble.arXiv preprint arXiv:2010.00200, 2021
arXiv 2010
-
[43]
general" only if no specific tag applies. - Return JSON only. Output schema: {
Ramtin Mesbahi et al. Ask-EDA: A design assistant empowered by LLM, hybrid RAG and abbreviation de-hallucination. 2024. 17 Appendix A Query Decomposition Prompt Templates The following prompts are used in the three-stage query decomposition pipeline described in Section 3.2. All prompts instruct the model to return structured JSON output only, with no pre...
2024
-
[44]
the original user query,
-
[45]
detected domain tags,
-
[46]
subqueries
query type, generate retrieval-oriented subqueries. Rules: - The first subquery must be the original query verbatim. - Generate 2 to 6 additional subqueries only if they genuinely aid retrieval. - Subqueries should retrieve supporting evidence, not answer the question directly. - For precise_fact queries: keep subqueries narrow; generate at most 2 extra s...
-
[47]
Why is a muon collider particularly sensitive to anomalous quartic gauge couplings in VBS?
-
[48]
Vector boson scattering at a muon collider
-
[49]
Vector boson fusion high-energy muon collider
-
[50]
VBS anomalous quartic gauge couplings muon collider
-
[51]
Sensitivity to aQGC in VBS at high-energy lepton colliders
-
[52]
Subquery 1 is the original query verbatim; subqueries 2–6 target mechanism, phenomenology, and theoretical context angles respectively
Unitarity and aQGC constraints from VBS Table 6: Pipeline output for a reasoning query tagged vbs + aqgc. Subquery 1 is the original query verbatim; subqueries 2–6 target mechanism, phenomenology, and theoretical context angles respectively. B Retrieval Metrics Formulation Let Rk = {d1, . . . , dk} denote the top- k retrieved chunks for a query, ranked by...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.