Beyond Binary Instrument QA: Probing Instrument Grounding in Music Audio-Language Models
Pith reviewed 2026-07-01 03:28 UTC · model grok-4.3
The pith
High binary instrument QA accuracy does not ensure robust instrument grounding in music audio-language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
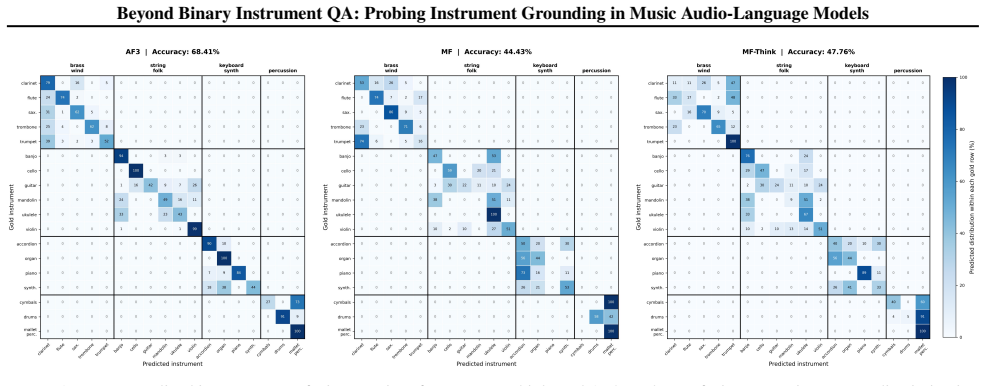
Models achieving high accuracy on standard binary instrument-presence questions still exhibit option-position bias, confusable-instrument errors, and temporal response bias when evaluated on genre-prior-reduced examples, confusable instrument discrimination, longer audio context, and temporal localization tasks.
What carries the argument
OpenMIC-derived diagnostic benchmark sequence that extends binary instrument QA across four additional axes to probe grounding.
If this is right
- Instrument grounding evaluation requires multiple diagnostic axes instead of one aggregate accuracy score.
- High performance on basic presence questions can result from positional or other shortcuts rather than audio features.
- Benchmark design must include confusable pairs and temporal questions to expose specific failure modes.
Where Pith is reading between the lines
- Training procedures may need explicit penalties for position or genre-based shortcuts.
- The same multi-axis testing approach could be applied to other audio attributes such as genre or playing technique.
Load-bearing premise
The added benchmark settings measure instrument grounding itself rather than unrelated abilities such as following instructions or exploiting dataset patterns.
What would settle it
A model that maintains high accuracy on the extended tasks without showing option-position bias, confusable-instrument errors, or temporal response bias would indicate that binary QA is adequate.
Figures
read the original abstract
Recent music audio-language models achieve high accuracy on instrument question-answering benchmarks, but it remains unclear whether this reflects robust audio grounding or benchmark-specific shortcuts. In this paper, we introduce an OpenMIC-derived diagnostic benchmark sequence for instrument grounding in music audio-language models, extending binary instrument-presence QA to genre-prior-reduced examples, confusable instrument discrimination, longer audio context, and temporal localization. Across these settings, high binary QA accuracy often fails to predict model behavior: models can exhibit option-position bias, confusable-instrument errors, and temporal response bias. These results suggest that instrument grounding should be evaluated with multi-axis diagnostic benchmarks rather than a single aggregate accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that high accuracy on binary instrument-presence QA benchmarks in music audio-language models does not indicate robust instrument grounding. It introduces an OpenMIC-derived diagnostic benchmark extending to genre-prior-reduced examples, confusable-instrument discrimination, longer audio context, and temporal localization tasks. Across these, models exhibit option-position bias, confusable-instrument errors, and temporal response bias, implying that evaluation should use multi-axis diagnostics rather than aggregate binary accuracy.
Significance. If the empirical observations hold after controls, the work would usefully demonstrate limitations of single-metric QA evaluation for audio grounding and motivate richer benchmark design in music audio-language models. The explicit construction of genre-prior-reduced and confusable-instrument probes is a concrete contribution that could be adopted by others.
major comments (2)
- [Experimental Setup / Benchmark Construction] No audio-ablated control (text-only prompts, randomized audio, or noise input) is described that preserves question format while removing audio content. This is load-bearing for the central claim, because the reported option-position bias, confusable-instrument errors, and temporal response bias could arise from LM decoder sensitivities to prompt ordering or phrasing rather than from the audio encoder output.
- [Abstract and Results] The abstract asserts that 'high binary QA accuracy often fails to predict model behavior' yet supplies no quantitative accuracy drops, per-model error rates, or statistical significance for the new axes. Without these numbers or an error analysis section, it is impossible to judge whether the claimed failures are robust or driven by a small number of outlier examples.
minor comments (1)
- [Benchmark Construction] Clarify how the genre-prior-reduced subset is constructed (e.g., explicit filtering criteria or sampling procedure) so that the extension can be reproduced.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Experimental Setup / Benchmark Construction] No audio-ablated control (text-only prompts, randomized audio, or noise input) is described that preserves question format while removing audio content. This is load-bearing for the central claim, because the reported option-position bias, confusable-instrument errors, and temporal response bias could arise from LM decoder sensitivities to prompt ordering or phrasing rather than from the audio encoder output.
Authors: We agree that audio-ablated controls are essential to isolate whether the observed biases stem from audio encoder outputs. The current manuscript does not include such controls, which is a limitation of the experimental design. We will add text-only prompt baselines and noise-input conditions in the revised version to directly test this. revision: yes
-
Referee: [Abstract and Results] The abstract asserts that 'high binary QA accuracy often fails to predict model behavior' yet supplies no quantitative accuracy drops, per-model error rates, or statistical significance for the new axes. Without these numbers or an error analysis section, it is impossible to judge whether the claimed failures are robust or driven by a small number of outlier examples.
Authors: The full results in Sections 4 and 5 include per-model accuracy tables, confusable-instrument error rates, position-bias statistics, and temporal bias measurements with significance tests. We acknowledge the abstract is too high-level. We will revise the abstract to reference specific quantitative drops (e.g., accuracy reductions on confusable pairs and temporal tasks) while respecting length constraints. revision: partial
Circularity Check
No circularity: empirical benchmark evaluation with no derivations or fitted predictions
full rationale
The paper introduces a diagnostic benchmark sequence and reports empirical observations on model behavior across multiple axes (genre-prior-reduced examples, confusable discrimination, longer context, temporal localization). No equations, parameter fits, predictions derived from inputs, or self-citation chains appear in the provided text. The central claim rests on direct experimental results rather than any reduction to prior definitions or fitted quantities by construction. This is a standard self-contained empirical study against external model outputs and benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
MusicLM: Generating Music From Text
Agostinelli, A., Denk, T. I., Borsos, Z., Engel, J., Verzetti, M., Caillon, A., Huang, Q., Jansen, A., Roberts, A., Tagliasacchi, M., et al. Musiclm: Generating music from text.arXiv preprint arXiv:2301.11325,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
A Tutorial on Deep Learning for Music Information Retrieval
Choi, K., Fazekas, G., Cho, K., and Sandler, M. A tutorial on deep learning for music information retrieval.arXiv preprint arXiv:1709.04396,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Qwen-Audio: Advancing Universal Audio Understanding via Unified Large-Scale Audio-Language Models
Chu, Y ., Xu, J., Zhou, X., Yang, Q., Zhang, S., Yan, Z., Zhou, C., and Zhou, J. Qwen-audio: Advancing universal au- dio understanding via unified large-scale audio-language models.arXiv preprint arXiv:2311.07919,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Chu, Y ., Xu, J., Yang, Q., Wei, H., Wei, X., Guo, Z., Leng, Y ., Lv, Y ., He, J., Lin, J., et al. Qwen2-audio technical report.arXiv preprint arXiv:2407.10759,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Lp-musiccaps: Llm-based pseudo music captioning.arXiv preprint arXiv:2307.16372,
Doh, S., Choi, K., Lee, J., and Nam, J. Lp-musiccaps: Llm-based pseudo music captioning.arXiv preprint arXiv:2307.16372,
-
[7]
Clotho: An audio captioning dataset
Drossos, K., Lipping, S., and Virtanen, T. Clotho: An audio captioning dataset. InICASSP 2020-2020 IEEE Inter- national Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 736–740. IEEE,
2020
-
[8]
Clap learning audio concepts from natural language su- pervision
Elizalde, B., Deshmukh, S., Al Ismail, M., and Wang, H. Clap learning audio concepts from natural language su- pervision. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1–5. IEEE,
2023
-
[9]
Evaluating models’ local decision boundaries via contrast sets
Gardner, M., Artzi, Y ., Basmov, V ., Berant, J., Bogin, B., Chen, S., Dasigi, P., Dua, D., Elazar, Y ., Gottumukkala, A., et al. Evaluating models’ local decision boundaries via contrast sets. InFindings of the Association for Com- putational Linguistics: EMNLP 2020, pp. 1307–1323,
2020
-
[10]
Music flamingo: Scaling music understanding in audio language models,
Ghosh, S., Goel, A., Koroshinadze, L., Lee, S.-g., Kong, Z., Santos, J. F., Duraiswami, R., Manocha, D., Ping, W., Shoeybi, M., et al. Music flamingo: Scaling music understanding in audio language models.arXiv preprint arXiv:2511.10289, 2025a. Ghosh, S., Kong, Z., Kumar, S., Sakshi, S., Kim, J., Ping, W., Valle, R., Manocha, D., and Catanzaro, B. Audio fl...
-
[11]
Gong, Y ., Luo, H., Liu, A., Karlinsky, L., and Glass, J. R. Listen, think, and understand. InInternational Con- ference on Learning Representations, volume 2024, pp. 18516–18545,
2024
-
[12]
Gururangan, S., Swayamdipta, S., Levy, O., Schwartz, R., Bowman, S., and Smith, N. A. Annotation artifacts in natural language inference data. InProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Lan- guage Technologies, V olume 2 (Short Papers), pp. 107– 112,
2018
-
[13]
Openmic-2018: An open data-set for multiple instrument recognition
Humphrey, E., Durand, S., and McFee, B. Openmic-2018: An open data-set for multiple instrument recognition. In ISMIR, pp. 438–444,
2018
-
[14]
Hurst, A., Lerer, A., Goucher, A. P., Perelman, A., Ramesh, A., Clark, A., Ostrow, A., Welihinda, A., Hayes, A., Rad- ford, A., et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
D., Kim, B., Lee, H., and Kim, G
Kim, C. D., Kim, B., Lee, H., and Kim, G. Audiocaps: Gen- erating captions for audios in the wild. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Hu- man Language Technologies, V olume 1 (Long and Short Papers), pp. 119–132,
2019
-
[16]
Audio flamingo: A novel audio language model with few-shot learning and dialogue abilities
5 Beyond Binary Instrument QA: Probing Instrument Grounding in Music Audio-Language Models Kong, Z., Goel, A., Badlani, R., Ping, W., Valle, R., and Catanzaro, B. Audio flamingo: A novel audio lan- guage model with few-shot learning and dialogue abilities. arXiv preprint arXiv:2402.01831,
-
[17]
and Hruschka, E
Pezeshkpour, P. and Hruschka, E. Large language models sensitivity to the order of options in multiple-choice ques- tions. InFindings of the Association for Computational Linguistics: NAACL 2024, pp. 2006–2017,
2024
-
[18]
Salmonn: Towards generic hear- ing abilities for large language models
Tang, C., Yu, W., Sun, G., Chen, X., Tan, T., Li, W., Lu, L., Ma, Z., and Zhang, C. Salmonn: Towards generic hear- ing abilities for large language models. InInternational Conference on Learning Representations, volume 2024, pp. 16607–16629,
2024
-
[19]
Weck, B., Manco, I., Benetos, E., Quinton, E., Fazekas, G., and Bogdanov, D. Muchomusic: Evaluating music un- derstanding in multimodal audio-language models.arXiv preprint arXiv:2408.01337,
-
[20]
Xu, J., Guo, Z., Hu, H., Chu, Y ., Wang, X., He, J., Wang, Y ., Shi, X., He, T., Zhu, X., et al. Qwen3-omni technical report.arXiv preprint arXiv:2509.17765,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Zang, Y ., O’Brien, S., Berg-Kirkpatrick, T., McAuley, J., and Novack, Z. Are you really listening? boosting percep- tual awareness in music-qa benchmarks.arXiv preprint arXiv:2504.00369,
-
[22]
Openmu: Your swiss army knife for music understanding.arXiv preprint arXiv:2410.15573,
Zhao, M., Zhong, Z., Mao, Z., Yang, S., Liao, W.-H., Taka- hashi, S., Wakaki, H., and Mitsufuji, Y . Openmu: Your swiss army knife for music understanding.arXiv preprint arXiv:2410.15573,
-
[23]
Large language models are not robust multiple choice selectors
Zheng, C., Zhou, H., Meng, F., Zhou, J., and Huang, M. Large language models are not robust multiple choice selectors. InInternational Conference on Learning Rep- resentations, volume 2024, pp. 19426–19454,
2024
-
[24]
Appendix A.1
6 Beyond Binary Instrument QA: Probing Instrument Grounding in Music Audio-Language Models A. Appendix A.1. OpenMIC-2018 Data Format OpenMIC-2018 provides 10-second music clips with instrument-level relevance annotations. The aggregated label file used in this work contains 41,534 clip–instrument annotations over 20,000 unique clips. As summarized in Tabl...
2018
-
[25]
Yes” and 4,666 “No
These groups are used in the confusion-aware two-choice benchmark and the strict 30-second choose-all benchmark. In both cases, candidates are sampled within the same group to make the alternatives acoustically or musically related. In the two-choice benchmark, one positive and one negative instrument are sampled from the same group. In the strict 30-seco...
2018
-
[26]
Table 7.Core CSV fields for the binary instrument-presence QA benchmark. Column Description qa_id Unique identifier of the QA instance sample_key OpenMIC-2018 clip identifier audio_path Path to the audio file instrument Target instrument in the question question Natural-language yes/no question gold_answer Ground-truth answer, Yes or No label_type Positiv...
2018
-
[27]
Is there a [instrument] in this audio clip?
All examples use the same prompt template as the main binary benchmark: “Is there a [instrument] in this audio clip?” Table 9.Core CSV fields for the genre-prior-reduced hard set. Column Description qa_id Unique identifier of the QA instance sample_key OpenMIC-2018 clip identifier audio_path Path to the audio file instrument Target instrument in the quest...
2018
-
[28]
Which instrument is present in this audio clip? Candidate instruments: [instrument 1], [instrument 2]. Answer with only one instrument name from the candidates
All examples use the prompt template: “Which instrument is present in this audio clip? Candidate instruments: [instrument 1], [instrument 2]. Answer with only one instrument name from the candidates.” This benchmark removes the yes/no response format and tests whether models can discriminate between acoustically or semantically confusable instruments. 9 B...
2018
-
[29]
Option rates report how often the model selects the first or second displayed candidate
Table 13.Prompt-variation analysis on MF for the confusion-aware two-choice benchmark. Option rates report how often the model selects the first or second displayed candidate. Gap denotes the absolute difference between the two option rates. Prompt/interface Acc. Opt. 1 Opt. 2 Unknown Gap Name, original order 44.43 55.47 44.53 0.00 10.94 Name, swapped ord...
2018
-
[30]
Which instruments are present in this audio clip? Candidate instruments: [instrument 1], [instrument 2], [instrument 3], [instrument 4]
All examples use the prompt template: “Listen carefully to the 30-second audio clip. Which instruments are present in this audio clip? Candidate instruments: [instrument 1], [instrument 2], [instrument 3], [instrument 4]. Answer with all instrument names from the candidates that are present, separated by commas.” Table 14.Core CSV fields for the long-cont...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.