FineREX: Fine-Tuned NER-RE for Human Smuggling Knowledge Graphs
Pith reviewed 2026-06-26 17:57 UTC · model grok-4.3
The pith
Fine-tuning an LLM on 512 legal text chunks for human smuggling entities and relations outperforms larger general models in building cleaner knowledge graphs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
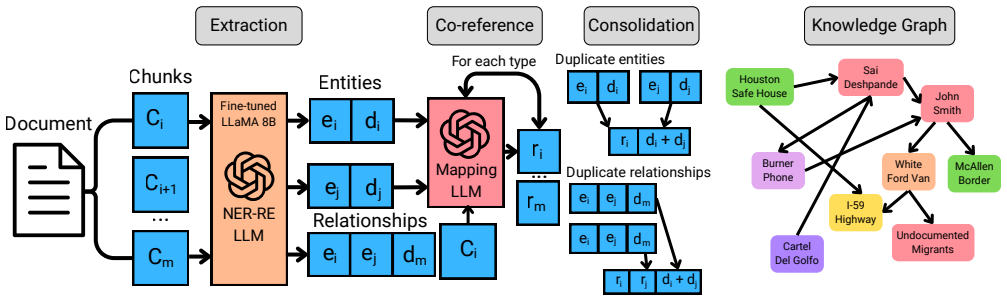
FineREX, a streamlined pipeline built around a fine-tuned LLM for named entity recognition and relationship extraction, achieves absolute F1 gains of 15.50% on entities and 31.46% on relations over a larger general-purpose baseline when trained on 512 manually annotated text chunks from court proceedings. These gains produce higher-quality knowledge graphs with nearly half the legal noise and reduced node duplication on long documents, while eliminating document rewriting and redundant extraction stages to cut total processing time by 50%. The results show domain-specific fine-tuning can outperform larger general models on both quality and efficiency for illicit network analysis.
What carries the argument
Fine-tuned LLM for named entity recognition and relationship extraction (NER-RE) tailored to human smuggling entities and relations extracted from court proceedings.
If this is right
- Entity F1 improves by 15.50% absolute and relation F1 by 31.46% absolute over the general baseline.
- Knowledge graphs contain nearly half as much legal noise.
- Node duplication on long documents falls from 17.78% to 11.17%.
- End-to-end processing time drops by 50% through removal of rewriting and redundant stages.
Where Pith is reading between the lines
- The same annotation and fine-tuning steps could be repeated for other specialized legal domains such as financial crime or drug trafficking networks.
- Agencies could maintain smaller domain models for repeated updates rather than depending on large general models each time.
- High-quality domain annotation effort may deliver better returns than further increases in general model size.
- pith_inferences
Load-bearing premise
The 512 manually annotated text chunks form a representative sample whose entity and relation definitions match what downstream knowledge-graph users need for human smuggling analysis.
What would settle it
Running the fine-tuned model and the general baseline on a fresh collection of court documents from different jurisdictions or years and finding no F1 improvement or no reduction in noise and duplication.
Figures
read the original abstract
Court proceedings contain valuable evidence about human smuggling networks, but this information is often buried within unstructured, jargon-heavy legal documents. While large language models (LLMs) can support knowledge graph construction through automated information extraction, existing approaches rely on general-purpose models that are not tailored to the entity and relationship definitions required in this domain. We introduce FineREX, a streamlined knowledge graph construction pipeline built around a fine-tuned LLM for named entity recognition and relationship extraction (NER-RE). Using a manually annotated dataset of $512$ text chunks, FineREX achieves absolute improvements of 15.50% and 31.46% in entity and relationship F1-score, respectively, compared to a larger general-purpose baseline. These gains translate into higher-quality knowledge graphs, reducing legal noise by nearly half and lowering node duplication on long documents from 17.78% to 11.17%. By eliminating document rewriting and redundant extraction stages, FineREX also reduces end-to-end processing time by 50.0%. Our results demonstrate that domain-specific fine-tuning can substantially outperform larger general-purpose models while improving both the quality and efficiency of knowledge graph construction for illicit network analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FineREX, a knowledge-graph construction pipeline centered on a fine-tuned LLM for joint named entity recognition and relation extraction (NER-RE) applied to court proceedings on human smuggling. Using a manually annotated set of 512 text chunks, it reports absolute F1 gains of 15.50% (entities) and 31.46% (relations) over a larger general-purpose baseline, together with downstream improvements in KG quality (halved legal noise, node duplication reduced from 17.78% to 11.17%) and a 50% reduction in end-to-end runtime achieved by removing document-rewriting and redundant extraction stages.
Significance. If substantiated, the work would provide concrete evidence that modest domain-specific fine-tuning can outperform larger general-purpose models on a specialized legal IE task while also delivering measurable efficiency and quality gains for downstream illicit-network analysis. The emphasis on a streamlined pipeline without intermediate rewriting stages is a practical contribution, though the absence of standard evaluation details prevents assessment of reproducibility or generalizability.
major comments (3)
- [Abstract] Abstract: the reported absolute F1 improvements (15.50% entity, 31.46% relation) are presented without any description of the train/test split, inter-annotator agreement, or annotation guidelines used for the 512 chunks; these omissions make it impossible to determine whether the measured gains reflect domain adaptation or differences in annotation schema and document selection.
- [Abstract] Abstract: the comparison to the 'larger general-purpose baseline' provides no information on model size, exact prompting or task formulation, or whether the baseline was evaluated under identical entity/relation definitions and test distribution; without these details the fairness of the 15.50%/31.46% deltas cannot be assessed.
- [Abstract] Abstract: the downstream KG metrics (legal noise reduction by nearly half, node duplication drop from 17.78% to 11.17%) and the 50.0% runtime reduction are stated without statistical tests, variance estimates across documents, or explicit definitions of the noise and duplication measures, rendering the translation from NER-RE F1 to KG quality unverified.
Simulated Author's Rebuttal
We appreciate the referee's comments highlighting areas where the abstract could be improved for clarity and completeness. We will revise the abstract accordingly and address each point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported absolute F1 improvements (15.50% entity, 31.46% relation) are presented without any description of the train/test split, inter-annotator agreement, or annotation guidelines used for the 512 chunks; these omissions make it impossible to determine whether the measured gains reflect domain adaptation or differences in annotation schema and document selection.
Authors: We agree with this observation. To improve the abstract, we will add a brief description of the train/test split, inter-annotator agreement, and annotation guidelines used for the 512 chunks. This will help clarify that the gains are attributable to domain-specific fine-tuning. revision: yes
-
Referee: [Abstract] Abstract: the comparison to the 'larger general-purpose baseline' provides no information on model size, exact prompting or task formulation, or whether the baseline was evaluated under identical entity/relation definitions and test distribution; without these details the fairness of the 15.50%/31.46% deltas cannot be assessed.
Authors: We concur that additional details on the baseline are necessary. We will revise the abstract to specify the model size of the general-purpose baseline, the prompting approach, and confirm that the same entity and relation definitions and test distribution were used for fair comparison. revision: yes
-
Referee: [Abstract] Abstract: the downstream KG metrics (legal noise reduction by nearly half, node duplication drop from 17.78% to 11.17%) and the 50.0% runtime reduction are stated without statistical tests, variance estimates across documents, or explicit definitions of the noise and duplication measures, rendering the translation from NER-RE F1 to KG quality unverified.
Authors: We acknowledge the validity of this comment. We will update the abstract and manuscript to include explicit definitions of the noise and duplication measures, as well as statistical tests and variance estimates where applicable to support the reported improvements in KG quality. revision: yes
Circularity Check
No circularity; purely empirical evaluation with no derivations
full rationale
The paper reports an empirical pipeline: manual annotation of 512 chunks, fine-tuning an LLM for NER-RE, and direct F1 comparison to a general-purpose baseline, followed by downstream KG metrics. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central claims rest on measured performance deltas rather than any reduction to inputs by construction. This matches the default expectation of no significant circularity for empirical work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Migrant smuggling patterns and challenges for law en- forcement,
Y . Dandurand, “Migrant smuggling patterns and challenges for law en- forcement,” International Centre for Criminal Law Reform and Criminal Justice Policy, Vancouver, Tech. Rep., Feb 2020
2020
-
[2]
Generating legal arguments using LLM and vector database to support precedents,
D. Sinha and O. Sharma, “Generating legal arguments using LLM and vector database to support precedents,” in2025 International Conference on Next Generation Information System Engineering (NGISE), 2025, pp. 1–5
2025
-
[3]
Synthesizing scientific literature with retrieval-augmented language models,
A. Asai, J. He, R. Shaoet al., “Synthesizing scientific literature with retrieval-augmented language models,”Nature, vol. 650, pp. 857–863,
-
[4]
[Online]. Available: https://doi.org/10.1038/s41586-025-10072-4
-
[5]
Ian Davidson, Michael Livanos, Antoine Gourru, Peter Walker, Julien Velcin, and S
S. Farquhar, J. Kossen, L. Kuhn, and Y . Gal, “Detecting hallucinations in large language models using semantic entropy,”Nature, vol. 630, no. 8017, pp. 625–630, 2024. [Online]. Available: https: //doi.org/10.1038/s41586-024-07421-0
-
[6]
When not to trust language models: Investigating effectiveness of parametric and non-parametric memories,
A. Mallen, A. Asai, V . Zhong, R. Das, D. Khashabi, and H. Hajishirzi, “When not to trust language models: Investigating effectiveness of parametric and non-parametric memories,” inProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), A. Rogers, J. Boyd-Graber, and N. Okazaki, Eds. Toronto, Canada...
2023
-
[7]
Evaluating position bias in large language model recommendations,
E. Bito, Y . Ren, and E. He, “Evaluating position bias in large language model recommendations,”arXiv preprint arXiv:2508.02020, 2025
arXiv 2025
-
[8]
From single to multi: How LLMs hallucinate in multi-document summarization,
C. G. Bel ´em, P. Pezeshkpour, H. Iso, S. Maekawa, N. Bhutani, and E. Hruschka, “From single to multi: How LLMs hallucinate in multi-document summarization,” inFindings of the Association for Computational Linguistics: NAACL 2025. Albuquerque, New Mexico: Association for Computational Linguistics, Apr. 2025, pp. 5291–5324. [Online]. Available: https://acl...
2025
-
[9]
Structured information extraction from scientific text with large language models,
J. Dagdelen, A. Dunn, S. Lee, N. Walker, A. S. Rosen, G. Ceder, K. A. Persson, and A. Jain, “Structured information extraction from scientific text with large language models,”Nature Communications, vol. 15, p. 1418, 2024
2024
-
[10]
S. Efeoglu and A. Paschke, “Relation extraction with fine-tuned large language models in retrieval augmented generation frameworks,”arXiv preprint arXiv:2406.14745, 2024
arXiv 2024
-
[11]
From local to global: A graph rag approach to query-focused summarization,
D. Edge, H. Trinh, N. Cheng, J. Bradley, A. Chao, A. Mody, S. Truitt, D. Metropolitansky, R. O. Ness, and J. Larson, “From local to global: A graph rag approach to query-focused summarization,” arXiv preprint arXiv:2404.16130, 2024. [Online]. Available: https: //arxiv.org/abs/2404.16130
Pith/arXiv arXiv 2024
-
[12]
LINK-KG: LLM- driven coreference-resolved knowledge graphs for human smuggling networks,
D. Meher, C. Domeniconi, and G. Correa-Cabrera, “LINK-KG: LLM- driven coreference-resolved knowledge graphs for human smuggling networks,” inProceedings of the 2025 IEEE International Conference on Knowledge Graph (ICKG), 2025, pp. 277–284
2025
-
[13]
Inside CORE-KG: Evaluating structured prompting and coreference resolution for knowledge graphs,
D. Meher and C. Domeniconi, “Inside CORE-KG: Evaluating structured prompting and coreference resolution for knowledge graphs,” in2025 IEEE International Conference on Data Mining Workshops (ICDMW), Washington, DC, USA, Nov. 2025
2025
-
[14]
CORE-KG: An LLM-driven knowledge graph construction framework for human smuggling networks,
D. Meher, C. Domeniconi, and G. Correa-Cabrera, “CORE-KG: An LLM-driven knowledge graph construction framework for human smuggling networks,”arXiv preprint arXiv:2506.21607, Jun. 2025. [Online]. Available: https://arxiv.org/abs/2506.21607
arXiv 2025
-
[15]
Legal en- tity extraction using a pointer generator network,
S. Skylaki, A. Oskooei, O. Bari, N. Herger, and Z. Kriegman, “Legal en- tity extraction using a pointer generator network,” in2021 International Conference on Data Mining Workshops (ICDMW), 2021, pp. 653–658
2021
-
[16]
Generating knowledge graphs from unstructured texts: Experi- ences in the e-commerce field for question answering,
D. T. Sant’Anna, R. O. Caus, L. d. S. Ramos, V . Hochgreb, and J. C. d. Reis, “Generating knowledge graphs from unstructured texts: Experi- ences in the e-commerce field for question answering,” inProceedings of the ASLD Workshop at the International Semantic Web Conference (ISWC). Campinas, Brazil: ASLD@ISWC, 2020, pp. 56–71
2020
-
[17]
Towards practical graphrag: Efficient knowledge graph construction and hybrid retrieval at scale,
C. Min, S. Bansal, J. Pan, A. Keshavarzi, R. Mathew, and A. V . Kannan, “Towards practical graphrag: Efficient knowledge graph construction and hybrid retrieval at scale,”arXiv preprint arXiv:2507.03226, 2025. [Online]. Available: https://arxiv.org/abs/2507.03226
arXiv 2025
-
[18]
Combining knowledge graphs and nlp to ana- lyze instant messaging data in criminal investigations,
R. Pozzi, V . Barbera, R. Alva Principe, D. Giardini, R. Rubini, and M. Palmonari, “Combining knowledge graphs and nlp to ana- lyze instant messaging data in criminal investigations,”arXiv preprint arXiv:2509.26487, 2025
arXiv 2025
-
[19]
Joint extraction of entity and relation based on fine-tuning BERT for long biomedical literatures,
T. Gao, X. Zhai, C. Yang, L. Lv, and H. Wang, “Joint extraction of entity and relation based on fine-tuning BERT for long biomedical literatures,” Bioinformatics Advances, vol. 4, no. 1, p. vbae194, 2024
2024
-
[20]
[lions: 1] and [tigers: 2] and [bears: 3], oh my! literary coreference annotation with LLMs,
R. M. M. Hicke and D. Mimno, “[lions: 1] and [tigers: 2] and [bears: 3], oh my! literary coreference annotation with LLMs,” inProceedings of LaTeCH-CLfL 2024. Association for Computational Linguistics, 2024, pp. 270–277
2024
-
[21]
LLMLink: Dual LLMs for dynamic entity linking on long narratives with collaborative memorisation and prompt optimisation,
L. Zhu, J. Wang, and Y . He, “LLMLink: Dual LLMs for dynamic entity linking on long narratives with collaborative memorisation and prompt optimisation,” inProceedings of the 31st International Conference on Computational Linguistics, 2025, pp. 11 334–11 347
2025
-
[22]
Iterative zero-shot LLM prompting for knowledge graph construction,
S. Carta, A. Giuliani, L. Piano, A. S. Podda, L. Pompianu, and S. G. Tiddia, “Iterative zero-shot LLM prompting for knowledge graph construction,”arXiv preprint arXiv:2307.01128, 2023
arXiv 2023
-
[23]
C. Zhou, Q. Gong, H. Luan, W. Zhan, J. Zhu, and Q. Zhang, “Fine-tuned large language models with structured prompts enable efficient construction of lung cancer knowledge graphs,”Scientific Reports, vol. 16, no. 1, p. 9505, 2026. [Online]. Available: https://doi.org/10.1038/s41598-026-38959-w
-
[24]
Mindmap: Knowledge graph prompting sparks graph of thoughts in large language models,
Y . Wen, Z. Wang, and J. Sun, “Mindmap: Knowledge graph prompting sparks graph of thoughts in large language models,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Bangkok, Thailand: Association for Computational Linguistics, Aug. 2024, pp. 10 370–10 388. [Online]. Available: https://acl...
2024
-
[25]
Qlora: Ef- ficient finetuning of quantized llms,
T. Dettmers, A. Pagnoni, A. Holtzman, and L. Zettlemoyer, “Qlora: Ef- ficient finetuning of quantized llms,” inAdvances in Neural Information Processing Systems, vol. 36. Curran Associates, Inc., 2023, pp. 10 088– 10 115
2023
-
[26]
Inference for the generalization error,
C. Nadeau and Y . Bengio, “Inference for the generalization error,” Machine Learning, vol. 52, no. 3, pp. 239–281, 2003
2003
-
[27]
The control of the false discovery rate in multiple testing under dependency,
Y . Benjamini and D. Yekutieli, “The control of the false discovery rate in multiple testing under dependency,”The Annals of Statistics, vol. 29, no. 4, pp. 1165–1188, 2001. [Online]. Available: http: //www.jstor.org/stable/2674075
arXiv 2001
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.