Multi-Hypothesis Test-Time Adaptation to Mitigate Underspecification
Pith reviewed 2026-07-02 19:07 UTC · model grok-4.3
The pith
Treating test-time adaptation as inference over multiple low-entropy hypotheses, instead of a single parameter update, reduces underspecification and yields more stable performance under distribution shifts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
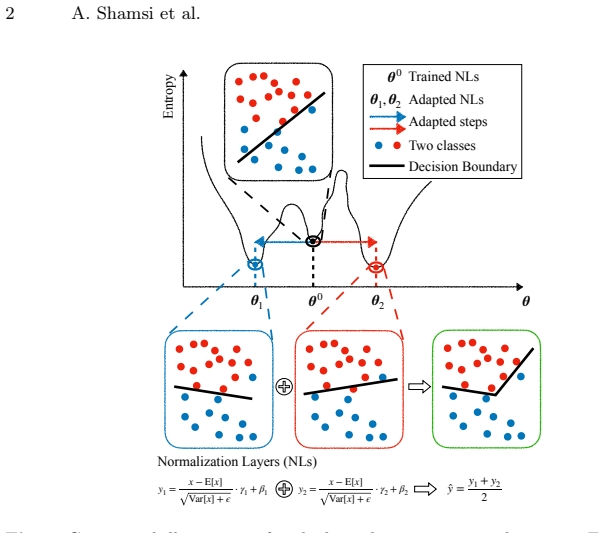
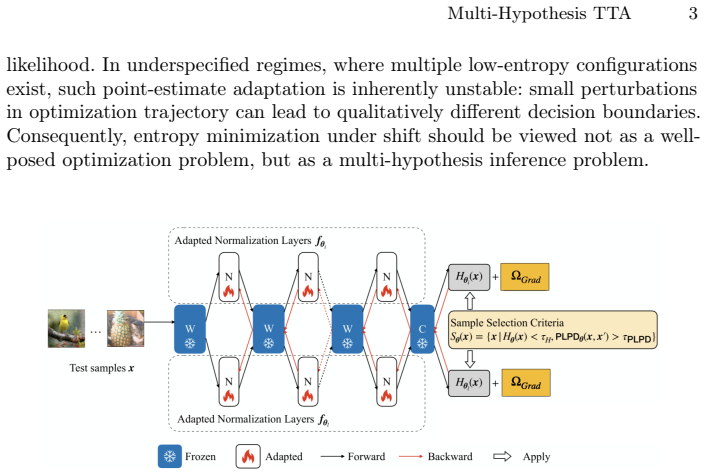
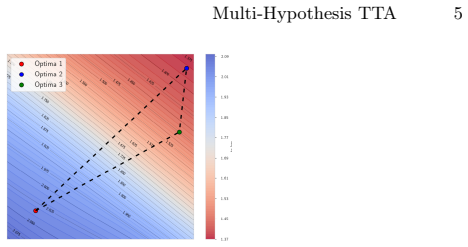
Entropy minimization during test-time adaptation defines a pseudo-likelihood over parameters, but this likelihood is underconstrained: multiple distinct parameter vectors achieve comparable low entropy yet induce different boundaries. The paper therefore reframes TTA as posterior inference over these solutions and replaces single-point optimization with a particle-based diversification procedure that simultaneously tracks multiple adaptation trajectories at four levels, producing an aggregated predictor that is less prone to collapse into spurious modes.
What carries the argument
Particle-based multi-level diversification framework that maintains and aggregates multiple plausible adaptation trajectories.
If this is right
- Gains of 3-4% on mixed distribution shifts, 2-3% at batch size one, and 1-2.5% under label shifts.
- The wrapper can be attached to any existing entropy-based TTA method.
- Diversification at output, parameter, optimizer, and input levels together produce the reported stability.
- The method treats low-entropy solutions as defining a pseudo-posterior rather than committing to one point estimate.
Where Pith is reading between the lines
- The same multi-hypothesis view could be applied to other unsupervised objectives that suffer from multiple equally low-loss solutions.
- Aggregation of particles may reduce sensitivity to the exact choice of entropy-minimization hyperparameters.
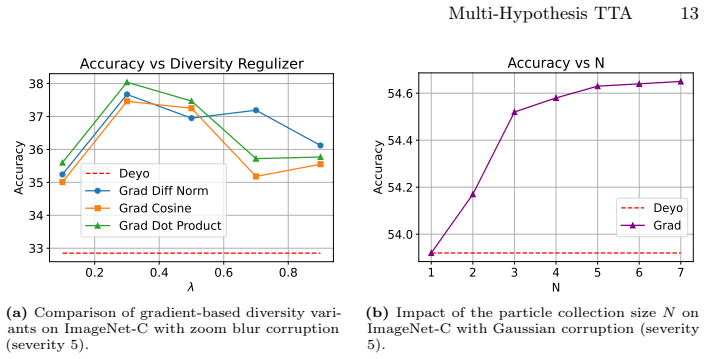
- If the diversification levels interact, ablating any one level should measurably reduce the observed gains.
Load-bearing premise
That several meaningfully different low-entropy parameter updates exist and can be combined without creating new failure modes that cancel the reported gains.
What would settle it
A controlled experiment on a benchmark where every low-entropy solution found by the base TTA method produces identical predictions on the test set, or where running the multi-hypothesis wrapper yields no improvement or a measurable drop.
Figures
read the original abstract
Test-Time Adaptation (TTA) seeks to improve model robustness under distribution shifts by adapting parameters using unlabeled target data. However, in the absence of supervision, entropy-based adaptation is fundamentally underconstrained: multiple distinct parameter updates can achieve similarly low entropy while inducing drastically different decision boundaries. This phenomenon, known as underspecification, renders standard TTA brittle and prone to collapse into spurious modes. In this work, we reinterpret TTA through a posterior-inspired lens induced by entropy minimization, where low-entropy solutions define a pseudo-likelihood over parameters. Instead of committing to a single point estimate, we introduce a particle-based diversification framework that explores multiple plausible adaptation trajectories simultaneously. Our method can be viewed as a structured exploration of multiple plausible adaptation solutions, implemented through multi-level diversification at the output, parameter, optimizer, and input levels. Crucially, the framework acts as a plug-and-play wrapper compatible with existing TTA methods. Extensive experiments on challenging benchmarks demonstrate consistent gains in stability and robustness, achieving improvements of 3-4% under mixed shifts, 2-3% with batch size one, and 1-2.5% under label shifts, outperforming state-of-the-art baselines. Our results suggest that treating TTA as a multi-hypothesis inference problem, rather than a single-point optimization task, is key to mitigating underspecification and enabling reliable real-world deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that entropy-minimization TTA is fundamentally underspecified because multiple distinct low-entropy parameter vectors can induce different decision boundaries on unlabeled target data. It reinterprets TTA via a pseudo-likelihood over parameters and introduces a particle-based diversification framework that performs multi-level exploration (output, parameter, optimizer, input) as a plug-and-play wrapper around existing TTA methods, reporting 3-4% gains under mixed shifts, 2-3% at batch size 1, and 1-2.5% under label shifts on standard benchmarks.
Significance. If the reported gains are shown to arise specifically from capturing distinct low-entropy modes rather than ancillary ensembling effects, the multi-hypothesis framing could meaningfully improve robustness of TTA under real-world shifts. The plug-and-play design is a practical strength that would facilitate adoption if the core premise is validated.
major comments (3)
- [Abstract] Abstract: the claim that 'multiple distinct parameter updates can achieve similarly low entropy while inducing drastically different decision boundaries' is load-bearing for the entire multi-hypothesis argument, yet the manuscript provides no direct measurements (parameter cosine similarity, prediction disagreement rates on target batches, or boundary divergence metrics) to confirm that the particles explore meaningfully distinct modes rather than correlated solutions.
- [Experiments] Experiments section: the 3-4% gains under mixed shifts are reported without ablations that isolate the contribution of the multi-hypothesis aggregation step versus the multi-level diversification components alone; this leaves open whether the pseudo-likelihood reinterpretation adds explanatory power beyond standard diversification or implicit ensembling.
- [Method] Method section: the particle-based framework is presented as exploring 'multiple plausible adaptation trajectories,' but without quantitative verification that the particles remain in distinct low-entropy basins (e.g., via entropy histograms or mode-separation statistics across runs), the central premise that aggregation mitigates underspecification remains unverified.
minor comments (2)
- [Method] The phrase 'structured exploration of multiple plausible adaptation solutions' is repeated without a concise formal definition; a short paragraph or pseudocode box early in the method would improve clarity.
- [Tables] Table captions should explicitly state whether reported numbers are means over multiple random seeds and whether error bars or standard deviations are shown.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger empirical validation of the multi-hypothesis premise. We address each major comment below and will incorporate the requested analyses and ablations in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'multiple distinct parameter updates can achieve similarly low entropy while inducing drastically different decision boundaries' is load-bearing for the entire multi-hypothesis argument, yet the manuscript provides no direct measurements (parameter cosine similarity, prediction disagreement rates on target batches, or boundary divergence metrics) to confirm that the particles explore meaningfully distinct modes rather than correlated solutions.
Authors: We agree that direct measurements are needed to substantiate the claim of distinct modes. In the revision we will add quantitative analyses including parameter cosine similarity between particles, prediction disagreement rates on held-out target batches, and boundary divergence metrics (e.g., via disagreement on synthetic boundary probes) to demonstrate that the particles occupy meaningfully different low-entropy solutions rather than correlated ones. revision: yes
-
Referee: [Experiments] Experiments section: the 3-4% gains under mixed shifts are reported without ablations that isolate the contribution of the multi-hypothesis aggregation step versus the multi-level diversification components alone; this leaves open whether the pseudo-likelihood reinterpretation adds explanatory power beyond standard diversification or implicit ensembling.
Authors: We acknowledge the value of isolating the aggregation step. The revised manuscript will include new ablation studies that (i) disable the multi-hypothesis aggregation while retaining all diversification components and (ii) compare against standard ensembling baselines, thereby quantifying the incremental benefit attributable to the pseudo-likelihood framing. revision: yes
-
Referee: [Method] Method section: the particle-based framework is presented as exploring 'multiple plausible adaptation trajectories,' but without quantitative verification that the particles remain in distinct low-entropy basins (e.g., via entropy histograms or mode-separation statistics across runs), the central premise that aggregation mitigates underspecification remains unverified.
Authors: We will add the requested verification. The revision will report entropy histograms across particles, mode-separation statistics (e.g., pairwise KL divergence of output distributions and basin occupancy counts over repeated runs), confirming that particles consistently occupy distinct low-entropy basins rather than collapsing to the same mode. revision: yes
Circularity Check
No circularity: conceptual reinterpretation without equations or self-referential reductions.
full rationale
The paper presents TTA as a multi-hypothesis problem via a pseudo-likelihood lens induced by entropy minimization, but this is framed as a conceptual shift rather than a derivation from equations. No mathematical steps, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The central claim rests on empirical gains from diversification, which are externally falsifiable via benchmarks and do not reduce to the inputs by construction. The absence of any derivation chain means the work is self-contained against external evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Entropy minimization defines a pseudo-likelihood over parameters
invented entities (1)
-
particle-based diversification framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In: Precup, D., Teh, Y.W
Arpit, D., Jastrzebski, S., Ballas, N., Krueger, D., Bengio, E., Kanwal, M.S., Ma- haraj, T., Fischer, A., Courville, A.C., Bengio, Y., Lacoste-Julien, S.: A closer look at memorization in deep networks. In: Precup, D., Teh, Y.W. (eds.) Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6-11 August 201...
2017
-
[2]
In: NeurIPS 2021 Competitions and Demonstrations Track
Bashkirova, D., Hendrycks, D., Kim, D., Liao, H., Mishra, S., Rajagopalan, C., Saenko, K., Saito, K., Tayyab, B.U., Teterwak, P., et al.: Visda-2021 competition: Universal domain adaptation to improve performance on out-of-distribution data. In: NeurIPS 2021 Competitions and Demonstrations Track. pp. 66–79. PMLR (2022)
2021
-
[3]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Chen, D., Wang, D., Darrell, T., Ebrahimi, S.: Contrastive test-time adaptation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 295–305 (2022)
2022
-
[4]
In: 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., Houlsby, N.: An image is worth 16x16 words: Transformers for image recognition at scale. In: 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. O...
2021
-
[5]
In: Bach, F.R., Blei, D.M
Ganin, Y., Lempitsky, V.S.: Unsupervised domain adaptation by backpropagation. In: Bach, F.R., Blei, D.M. (eds.) Proceedings of the 32nd International Conference on Machine Learning, ICML 2015, Lille, France, 6-11 July 2015. JMLR Workshop and Conference Proceedings, vol. 37, pp. 1180–1189. JMLR.org (2015),http: //proceedings.mlr.press/v37/ganin15.html
2015
-
[6]
Ganin, Y., Ustinova, E., Ajakan, H., Germain, P., Larochelle, H., Laviolette, F., Marchand, M., Lempitsky, V.S.: Domain-adversarial training of neural networks. J. Mach. Learn. Res.17, 59:1–59:35 (2016),https://jmlr.org/papers/v17/15- 239.html
2016
-
[7]
In: Proceedings of the IEEE/CVF international conference on computer vision
Hendrycks, D., Basart, S., Mu, N., Kadavath, S., Wang, F., Dorundo, E., Desai, R., Zhu, T., Parajuli, S., Guo, M., et al.: The many faces of robustness: A critical analysis of out-of-distribution generalization. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 8340–8349 (2021)
2021
-
[8]
Benchmarking Neural Network Robustness to Common Corruptions and Perturbations
Hendrycks, D., Dietterich, T.: Benchmarking neural network robustness to common corruptions and perturbations. arXiv preprint arXiv:1903.12261 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[9]
In: 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019
Hendrycks, D., Dietterich, T.G.: Benchmarking neural network robustness to com- mon corruptions and perturbations. In: 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenRe- view.net (2019),https://openreview.net/forum?id=HJz6tiCqYm
2019
-
[10]
Ilharco, G., Wortsman, M., Wightman, R., Gordon, C., Carlini, N., Taori, R., Dave, A., Shankar, V., Namkoong, H., Miller, J., Hajishirzi, H., Farhadi, A., Schmidt, L.: Openclip (Jul 2021).https://doi.org/10.5281/zenodo.5143773 , 16 A. Shamsi et al. https://doi.org/10.5281/zenodo.5143773, if you use this software, please cite it as below
-
[11]
In: The Twelfth International Conference on Learning Representations (2024), https://openreview.net/forum?id=9w3iw8wDuE
Lee, J., Jung, D., Lee, S., Park, J., Shin, J., Hwang, U., Yoon, S.: Entropy is not enough for test-time adaptation: From the perspective of disentangled factors. In: The Twelfth International Conference on Learning Representations (2024), https://openreview.net/forum?id=9w3iw8wDuE
2024
-
[12]
arXiv preprint arXiv:2403.07366 (2024)
Lee, J., Jung, D., Lee, S., Park, J., Shin, J., Hwang, U., Yoon, S.: Entropy is not enough for test-time adaptation: From the perspective of disentangled factors. arXiv preprint arXiv:2403.07366 (2024)
-
[13]
Liang, J., He, R., Tan, T.: A comprehensive survey on test-time adaptation under distribution shifts. CoRRabs/2303.15361(2023). https://doi.org/10.48550/ ARXIV.2303.15361,https://doi.org/10.48550/arXiv.2303.15361
-
[14]
In: Advances in Neural Information Processing Systems
Liu, Q., Wang, D.: Stein variational gradient descent: A general purpose bayesian inference algorithm. In: Advances in Neural Information Processing Systems. vol. 29 (2016)
2016
-
[15]
Advances in neural information processing systems29(2016)
Liu, Q., Wang, D.: Stein variational gradient descent: A general purpose bayesian inference algorithm. Advances in neural information processing systems29(2016)
2016
-
[16]
In: Proceedings of the 30th International Conference on Machine Learning, ICML 2013, Atlanta, GA, USA, 16-21 June 2013
Muandet, K., Balduzzi, D., Schölkopf, B.: Domain generalization via invariant feature representation. In: Proceedings of the 30th International Conference on Machine Learning, ICML 2013, Atlanta, GA, USA, 16-21 June 2013. JMLR Workshop and Conference Proceedings, vol. 28, pp. 10–18. JMLR.org (2013), http://proceedings.mlr.press/v28/muandet13.html
2013
-
[17]
CoRRabs/2006.10963(2020),https://arxiv.org/abs/2006.10963
Nado, Z., Padhy, S., Sculley, D., D’Amour, A., Lakshminarayanan, B., Snoek, J.: Evaluating prediction-time batch normalization for robustness under covariate shift. CoRRabs/2006.10963(2020),https://arxiv.org/abs/2006.10963
-
[18]
In: Wallach, H.M., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E.B., Garnett, R
Nagarajan, V., Kolter, J.Z.: Uniform convergence may be unable to explain gen- eralization in deep learning. In: Wallach, H.M., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E.B., Garnett, R. (eds.) Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8-14, 2...
2019
-
[19]
In: Internetional Conference on Learning Representations (2023)
Niu, S., Wu, J., Zhang, Y., Wen, Z., Chen, Y., Zhao, P., Tan, M.: Towards stable test- time adaptation in dynamic wild world. In: Internetional Conference on Learning Representations (2023)
2023
-
[20]
arXiv preprint arXiv:2406.13875 (2024)
Osowiechi, D., Noori, M., Hakim, G.A.V., Yazdanpanah, M., Bahri, A., Cher- aghalikhani, M., Dastani, S., Beizaee, F., Ayed, I.B., Desrosiers, C.: Watt: Weight average test-time adaptation of clip. arXiv preprint arXiv:2406.13875 (2024)
-
[21]
In: International Conference on Machine Learning
Press, O., Shwartz-Ziv, R., LeCun, Y., Bethge, M.: The entropy enigma: Success and failure of entropy minimization. In: International Conference on Machine Learning. PMLR (2024)
2024
-
[22]
Qiu, Z., Zhang, Y., Lin, H., Niu, S., Liu, Y., Du, Q., Tan, M.: Source-free domain adaptation via avatar prototype generation and adaptation. In: Zhou, Z. (ed.) Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI 2021, Virtual Event / Montreal, Canada, 19-27 August 2021. pp. 2921–2927. ijcai.org (2021). https://do...
-
[23]
MIT Press, Cambridge, MA (2009) Multi-Hypothesis TTA 17
Quiñonero, J., Sugiyama, M., Schwaighofer, A., Lawrence, N.D.: Dataset Shift in Machine Learning. MIT Press, Cambridge, MA (2009) Multi-Hypothesis TTA 17
2009
-
[24]
In: Meila, M., Zhang, T
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning transferable visual models from natural language supervision. In: Meila, M., Zhang, T. (eds.) Proceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual E...
2021
-
[25]
In: Proceedings of the 38th International Conference on Machine Learning (ICML) (2021)
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning transferable visual models from natural language supervision. In: Proceedings of the 38th International Conference on Machine Learning (ICML) (2021)
2021
-
[26]
Recht, B., Roelofs, R., Schmidt, L., Shankar, V.: Do imagenet classifiers generalize to imagenet? In: International conference on machine learning. pp. 5389–5400. PMLR (2019)
2019
-
[27]
In: Proceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event
Sagawa, S., Raghunathan, A., Koh, P.W., Liang, P.: An investigation of why overparameterization exacerbates spurious correlations. In: Proceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event. Proceedings of Machine Learning Research, vol. 119, pp. 8346–8356. PMLR (2020),http://proceedings.mlr.press/v...
2020
-
[28]
Saito, K., Watanabe, K., Ushiku, Y., Harada, T.: Maximum classifier discrepancy for unsupervised domain adaptation. In: 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, June 18-22, 2018. pp. 3723–3732. Computer Vision Foundation / IEEE Computer Society (2018). https://doi.org/10.1109/CVPR.2018.00392 , ht...
-
[29]
In: Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H
Shah, H., Tamuly, K., Raghunathan, A., Jain, P., Netrapalli, P.: The pitfalls of simplicity bias in neural networks. In: Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H. (eds.) Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual (2020...
2020
-
[30]
The Bell System Tech- nical Journal27, 379–423 (1948), http://plan9.bell-labs.com/cm/ms/what/ shannonday/shannon1948.pdf
Shannon, C.E.: A mathematical theory of communication. The Bell System Tech- nical Journal27, 379–423 (1948), http://plan9.bell-labs.com/cm/ms/what/ shannonday/shannon1948.pdf
1948
-
[31]
In: International conference on machine learning
Sun, Y., Wang, X., Liu, Z., Miller, J., Efros, A., Hardt, M.: Test-time training with self-supervision for generalization under distribution shifts. In: International conference on machine learning. pp. 9229–9248. PMLR (2020)
2020
-
[32]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Teney, D., Abbasnejad, E., Lucey, S., van den Hengel, A.: Evading the simplicity bias: TrainingadiversesetofmodelsdiscoverssolutionswithsuperiorOODgeneralization. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022. pp. 16740–16751. IEEE (2022). https://doi.org/10.1109/CVPR52688.2022.01626,...
-
[33]
In: International Conference on Learning Representations (2021),https://openreview.net/forum?id=uXl3bZLkr3c
Wang, D., Shelhamer, E., Liu, S., Olshausen, B., Darrell, T.: Tent: Fully test-time adaptation by entropy minimization. In: International Conference on Learning Representations (2021),https://openreview.net/forum?id=uXl3bZLkr3c
2021
-
[34]
Advances in neural information processing systems35, 38629–38642 (2022) 18 A
Zhang, M., Levine, S., Finn, C.: Memo: Test time robustness via adaptation and augmentation. Advances in neural information processing systems35, 38629–38642 (2022) 18 A. Shamsi et al. Multi-Hypothesis Test-Time Adaptation to Mitigate Underspecification Overview of Materials in the Appendices A brief overview of additional experimental results and finding...
2022
-
[35]
Related work (Appendix A)
-
[36]
Underspecification in TTA (Appendix B)
-
[37]
Beyond Corruption-Based Shifts (Appendix C)
-
[38]
Sample Selection and Hyperparameter Configuration (Appendix D)
-
[39]
Optimization Objective of SVGD (Appendix E)
-
[40]
Additional experiments regarding mild scenarios (Appendix F)
-
[41]
Additional experiments associated with wild scenarios for severity level of 3 (Appendix G)
-
[42]
Runtime comparison of methods (Appendix H)
-
[43]
Existing research in OOD generalization primarily focuses on domain adaptation and invariant representation learning
Limitation (Appendix I) A Related Work A.1 Out-of-distribution Generalization Out-of-distribution (OOD) generalization has become a critical research area, as models deployed in real-world scenarios often encounter data that are different from the training distribution. Existing research in OOD generalization primarily focuses on domain adaptation and inv...
-
[44]
proposed techniques based on adversarial training, where models are trained against perturbed data points, encouraging them to move beyond simpler features and to learn more generalizable representations. [32] trained a collection of models andidentifiedonlyoneforinference,whichdiscoveredpredictivepatternsnormally missed by a learning algorithm because of...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.