RREDCoT: Segment-Level Reward Redistribution for Reasoning Models
Pith reviewed 2026-06-28 02:10 UTC · model grok-4.3
The pith
RREDCoT lets a reasoning model redistribute rewards across its own Chain-of-Thought segments without extra sampling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
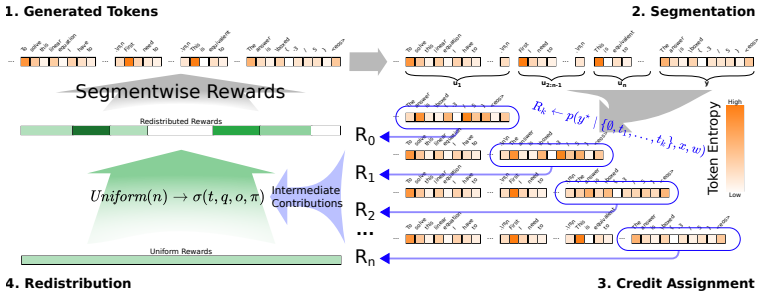
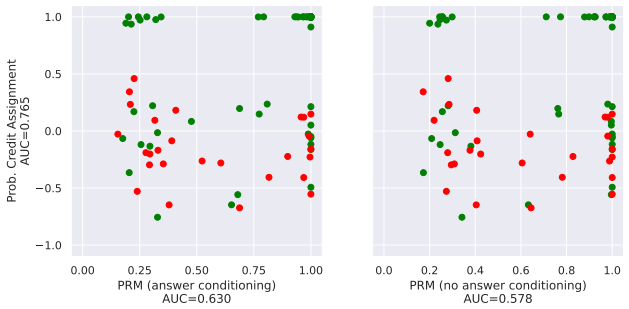
RREDCoT utilizes the model itself to approximate the optimal reward redistribution without additional generation, providing segment-level credit assignment for Chain-of-Thought traces that would otherwise receive only a terminal reward.
What carries the argument
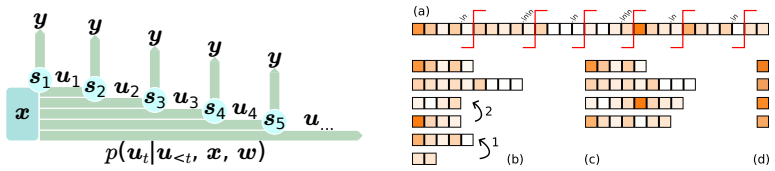
RREDCoT, which constructs a redistribution of the terminal reward by using the model’s internal estimates of state values over segmented CoT traces.
If this is right
- Policy updates during GRPO-style training exhibit lower variance because intermediate segments receive differentiated rewards.
- Training remains computationally feasible at high segmentation granularity and long context lengths.
- No separate value network or extra rollouts are required to obtain the redistribution.
- The approach can be combined with existing segmentation strategies for CoT traces.
Where Pith is reading between the lines
- The same self-estimation idea could be tested on other delayed-reward language-model tasks beyond mathematical reasoning.
- If the approximation holds, it reduces dependence on external verifiers or human feedback for intermediate credit.
- One could measure whether the method scales to multi-turn agent trajectories where only the final outcome is scored.
Load-bearing premise
The model’s own estimates of segment values serve as a sufficiently accurate and low-bias proxy for true credit assignment.
What would settle it
A controlled experiment in which RREDCoT-trained models underperform Monte-Carlo-redistributed models on the same reasoning tasks and data would show that the self-approximation introduces unacceptable bias.
Figures


read the original abstract
Recent advancements in reasoning language models have been driven by Reinforcement Learning (RL) fine-tuning. Most often, these rely on the Group Relative Policy Optimization (GRPO) algorithm or modifications thereof to steer the models to produce Chain-of-Thought (CoT) traces. The final answer can only be verified, and the reward assigned, after the CoT trace is complete, making it a delayed reward problem. GRPO and its modifications correspond to Monte Carlo methods in standard RL, which are known to suffer from high variance. A possible solution to this problem is the redistribution of rewards through credit assignment, where segments of the CoT trace that are important for arriving at the desirable solution are emphasized by assigning a higher reward. While Monte Carlo sampling can be used to provide an unbiased estimate of intermediate state values, its computational overhead makes it unsuitable for train-time credit assignment in long contexts at high granularity. We introduce RREDCoT (Reward REDistribution for Chain of Thoughts), which utilizes the model itself to approximate the optimal reward redistribution without additional generation. We investigate the advantages of our method compared to MC sampling and several attribution methods. We further analyze several aspects relevant to the construction of the redistribution such as segmentation of CoT traces and state value estimation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RREDCoT, a method for segment-level reward redistribution in RL fine-tuning of reasoning models using GRPO-style algorithms. It addresses the delayed-reward problem in CoT traces by having the model itself approximate optimal credit assignment for segments, avoiding the computational overhead of Monte Carlo sampling for value estimation. The authors compare the approach to MC sampling and attribution methods and analyze choices in CoT segmentation and state-value estimation.
Significance. If the self-estimation of segment values proves to be a low-bias proxy for true credit assignment, the method could enable efficient, high-granularity reward redistribution during training of long-CoT reasoning models without extra generations. This would directly mitigate the high-variance issue of MC-based GRPO while remaining computationally tractable, representing a practical advance for scaling RL to complex reasoning tasks.
major comments (2)
- [Abstract] Abstract: the central claim that 'the model itself [can] approximate the optimal reward redistribution without additional generation' is load-bearing yet unsupported by any derivation, bound, or analysis showing why the policy's own value estimates avoid introducing policy-correlated bias. The skeptic concern that self-estimates may reinforce existing generation biases before convergence is not addressed.
- [Abstract] The description of state value estimation (mentioned in the final sentence of the abstract) provides no mechanism or ablation demonstrating that the estimator remains sufficiently accurate and low-bias when the policy is still far from convergence; this directly affects whether the method solves rather than relocates the variance-bias tradeoff.
minor comments (1)
- [Abstract] The abstract mentions comparisons to 'several attribution methods' but does not name them or indicate which tables/figures report the results; this should be clarified for readability.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The concerns about unsupported claims in the abstract and the need for analysis of bias in self-estimation are well-taken. We address each point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'the model itself [can] approximate the optimal reward redistribution without additional generation' is load-bearing yet unsupported by any derivation, bound, or analysis showing why the policy's own value estimates avoid introducing policy-correlated bias. The skeptic concern that self-estimates may reinforce existing generation biases before convergence is not addressed.
Authors: We agree that the abstract states the claim without accompanying theoretical support. The manuscript relies on empirical comparisons to Monte Carlo sampling and attribution baselines to demonstrate practical effectiveness, but contains no derivation or bound on policy-correlated bias. We will revise the abstract to describe RREDCoT as an empirical approximation and add a dedicated limitations subsection discussing the risk of bias reinforcement prior to convergence, drawing on related RL literature on bootstrapped estimators. revision: yes
-
Referee: [Abstract] The description of state value estimation (mentioned in the final sentence of the abstract) provides no mechanism or ablation demonstrating that the estimator remains sufficiently accurate and low-bias when the policy is still far from convergence; this directly affects whether the method solves rather than relocates the variance-bias tradeoff.
Authors: The full manuscript does analyze state-value estimation choices and includes comparisons to MC methods, but we acknowledge the absence of targeted ablations or analysis isolating estimator accuracy during early training (far from convergence). We will add an experiment or figure tracking estimator correlation with MC baselines across training epochs and revise the abstract's final sentence to reference this new analysis, thereby clarifying how the approach addresses rather than relocates the tradeoff. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper introduces RREDCoT as a practical method that re-uses the current policy model to estimate segment values for reward redistribution in GRPO-style RL, explicitly positioned as a lower-cost alternative to Monte Carlo sampling. The abstract and description contain no equations, self-citations, or uniqueness theorems that reduce the claimed redistribution to a fitted parameter or prior result by construction. The central proposal is an engineering choice whose validity is to be checked empirically against MC and attribution baselines; no load-bearing step collapses into self-definition or self-citation. This is the normal case of a self-contained algorithmic contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the Sixteenth International Conference on Machine Learning , author =
Policy Invariance under Reward Transformations:. Proceedings of the Sixteenth International Conference on Machine Learning , author =. 1999 , series =
1999
-
[2]
Agarwal, Rishabh and Vieillard, Nino and Zhou, Yongchao and Stanczyk, Piotr and Ramos, Sabela and Geist, Matthieu and Bachem, Olivier , date =. On-. 2024 , eprint =
2024
-
[3]
2025 , eprint =
Aghazadeh, Ehsan and Ghasemi, Ahmad and Beyhaghi, Hedyeh and Pishro-Nik, Hossein , date =. 2025 , eprint =
2025
-
[4]
Ahmadian, Arash and Cremer, Chris and Gallé, Matthias and Fadaee, Marzieh and Kreutzer, Julia and Pietquin, Olivier and Üstün, Ahmet and Hooker, Sara , date =. Back to. 2024 , eprint =
2024
-
[5]
2019 , volume =
Advances in Neural Information Processing Systems , author =. 2019 , volume =
2019
-
[6]
Bang, Jihwan and Lee, Juntae and Yang, Seunghan and Choi, Sungha , date =. Think. 2025 , eprint =
2025
-
[7]
Bartoldson, Brian R. and Venkatraman, Siddarth and Diffenderfer, James and Jain, Moksh and Ben-Nun, Tal and Lee, Seanie and Kim, Minsu and Obando-Ceron, Johan and Bengio, Yoshua and Kailkhura, Bhavya , date =. Trajectory. 2025 , eprint =
2025
-
[8]
Demystifying
Besta, Maciej and Memedi, Florim and Zhang, Zhenyu and Gerstenberger, Robert and Piao, Guangyuan and Blach, Nils and Nyczyk, Piotr and Copik, Marcin and Kwaśniewski, Grzegorz and Müller, Jürgen and Gianinazzi, Lukas and Kubicek, Ales and Niewiadomski, Hubert and O'Mahony, Aidan and Mutlu, Onur and Hoefler, Torsten , date =. Demystifying. 2025 , eprint =
2025
-
[9]
Normalized (Pointwise) Mutual Information in Collocation Extraction , author =
-
[10]
Escaping the
Cai, Locke and Provilkov, Ivan , date =. Escaping the. 2025 , url =
2025
-
[11]
and Sun, Hao and Holt, Samuel and family=Schaar, given=Mihaela, prefix=van der, useprefix=false , date =
Chan, Alex J. and Sun, Hao and Holt, Samuel and family=Schaar, given=Mihaela, prefix=van der, useprefix=false , date =. Dense. 2024 , eprint =
2024
-
[12]
Incorrect
Chandak, Nikhil and Goel, Shashwat and Ameya, Prabhu , year =. Incorrect
-
[13]
Language
Chen, Haolin and Feng, Yihao and Liu, Zuxin and Yao, Weiran and Prabhakar, Akshara and Heinecke, Shelby and Ho, Ricky and Mui, Phil and Savarese, Silvio and Xiong, Caiming and Wang, Huan , date =. Language. 2024 , eprint =
2024
-
[14]
2024 , eprint =
Chen, Guoxin and Liao, Minpeng and Li, Chengxi and Fan, Kai , date =. 2024 , eprint =
2024
-
[15]
2025 , eprint =
Chen, Yang and Yang, Zhuolin and Liu, Zihan and Lee, Chankyu and Xu, Peng and Shoeybi, Mohammad and Catanzaro, Bryan and Ping, Wei , date =. 2025 , eprint =
2025
-
[16]
Conditional
Chen, Guanxu and Li, Yafu and Jiang, Yuxian and Qian, Chen and Ren, Qihan and Yang, Jingyi and Cheng, Yu and Liu, Dongrui and Shao, Jing , date =. Conditional. 2025 , eprint =
2025
-
[17]
Cui, Ganqu and Yuan, Lifan and Wang, Zefan and Wang, Hanbin and Li, Wendi and He, Bingxiang and Fan, Yuchen and Yu, Tianyu and Xu, Qixin and Chen, Weize and Yuan, Jiarui and Chen, Huayu and Zhang, Kaiyan and Lv, Xingtai and Wang, Shuo and Yao, Yuan and Han, Xu and Peng, Hao and Cheng, Yu and Liu, Zhiyuan and Sun, Maosong and Zhou, Bowen and Ding, Ning , d...
2025
-
[18]
family=Curtò, given=J., prefix=de, useprefix=false and family=Zarzà, given=I., prefix=de, useprefix=false and García, Pablo and Cabot, Jordi , date =. Cross-. 2025 , eprint =
2025
-
[19]
family=Aliberti, given=Liv G., prefix=d', useprefix=true and Ribeiro, Manoel Horta , date =. The. 2026 , eprint =
2026
-
[20]
Reinforcement
Dang, Quy-Anh and Ngo, Chris , date =. Reinforcement. 2025 , eprint =
2025
-
[21]
and Roongta, Manan and Cai, Colin and Luo, Jeffrey and Li, Li Erran and Popa, Raluca Ada and Stoica, Ion , date =
Luo, Michael and Tan, Sijun and Wong, Justin and Shi, Xiaoxiang and Tang, William Y. and Roongta, Manan and Cai, Colin and Luo, Jeffrey and Li, Li Erran and Popa, Raluca Ada and Stoica, Ion , date =
-
[22]
2025 , eprint =
DeepSeek-AI and Liu, Aixin and Feng, Bei and Xue, Bing and Wang, Bingxuan and Wu, Bochao and Lu, Chengda and Zhao, Chenggang and Deng, Chengqi and Zhang, Chenyu and Ruan, Chong and Dai, Damai and. 2025 , eprint =
2025
-
[23]
DeepSeek-AI and Guo, Daya and Yang, Dejian and Zhang, Haowei and Song, Junxiao and Zhang, Ruoyu and Xu, Runxin and Zhu, Qihao and Ma, Shirong and Wang, Peiyi and Bi, Xiao and Zhang, Xiaokang and Yu, Xingkai and Wu, Yu and Wu, Z. F. and Gou, Zhibin and Shao, Zhihong and. 2025 , eprint =
2025
-
[24]
Dong, Perry and Zheng, Chongyi and Finn, Chelsea and Sadigh, Dorsa and Eysenbach, Benjamin , date =. Value. 2025 , eprint =
2025
-
[25]
Efficient
Feng, Sicheng and Fang, Gongfan and Ma, Xinyin and Wang, Xinchao , date =. Efficient. 2025 , eprint =
2025
-
[26]
, date =
Gandhi, Kanishk and Chakravarthy, Ayush and Singh, Anikait and Lile, Nathan and Goodman, Noah D. , date =. Cognitive. 2025 , eprint =
2025
-
[27]
Segmental
Gong, Xue and Yi, Qi and Nan, Ziyuan and Huang, Guanhua and Li, Kejiao and Jiang, Yuhao and Xiong, Ruibin and Xu, Zenan and Guo, Jiaming and Peng, Shaohui and Zhou, Bo , date =. Segmental. 2026 , eprint =
2026
-
[28]
2025 , eprint =
Guha, Etash and Marten, Ryan and Keh, Sedrick and Raoof, Negin and Smyrnis, Georgios and Bansal, Hritik and Nezhurina, Marianna and Mercat, Jean and Vu, Trung and Sprague, Zayne and Suvarna, Ashima and Feuer, Benjamin and Chen, Liangyu and Khan, Zaid and Frankel, Eric and Grover, Sachin and Choi, Caroline and Muennighoff, Niklas and Su, Shiye and Zhao, Wa...
2025
-
[29]
Guo, Yiran and Xu, Lijie and Liu, Jie and Ye, Dan and Qiu, Shuang , date =. Segment. 2025 , eprint =
2025
-
[30]
Learning to
Gurung, Alexander and Lapata, Mirella , date =. Learning to. 2025 , eprint =
2025
-
[31]
Beyond the
Hammoud, Hasan Abed Al Kader and Itani, Hani and Ghanem, Bernard , date =. Beyond the. 2025 , eprint =
2025
-
[32]
2025 , eprint =
Hou, Bairu and Zhang, Yang and Ji, Jiabao and Liu, Yujian and Qian, Kaizhi and Andreas, Jacob and Chang, Shiyu , date =. 2025 , eprint =
2025
-
[33]
Unveiling the
Hu, Xinyang and Zhang, Fengzhuo and Chen, Siyu and Yang, Zhuoran , date =. Unveiling the. 2024 , eprint =
2024
-
[34]
The Illusion of Thinking:
Shojaee, Parshin and Mirzadeh, Iman and Alizadeh, Keivan and Horton, Maxwell and Bengio, Samy and Farajtabar, Mehrdad , year =. The Illusion of Thinking:
-
[35]
Compute as
Jayalath, Dulhan and Goel, Shashwat and Foster, Thomas and Jain, Parag and Gururangan, Suchin and Zhang, Cheng and Goyal, Anirudh and Schelten, Alan , date =. Compute as. 2025 , eprint =
2025
-
[36]
Reinforcement
Jiang, Kai and Qin, XiaoLong , date =. Reinforcement. 2020 , eprint =
2020
-
[37]
Jo, Hwiyeol and Lee, Joosung and Lee, Jaehone and Lee, Sang-Woo and Park, Joonsuk and Yoo, Kang Min , date =. Finding. 2025 , eprint =
2025
-
[38]
Kambhampati, Subbarao and Stechly, Kaya and Valmeekam, Karthik and Saldyt, Lucas and Bhambri, Siddhant and Palod, Vardhan and Gundawar, Atharva and Samineni, Soumya Rani and Kalwar, Durgesh and Biswas, Upasana , date =. Stop. 2025 , eprint =
2025
-
[39]
2025 , eprint =
Kang, Beomseok and Song, Jiwon and Kim, Jae-Joon , date =. 2025 , eprint =
2025
-
[40]
2025 , eprint =
Kazemnejad, Amirhossein and Aghajohari, Milad and Portelance, Eva and Sordoni, Alessandro and Reddy, Siva and Courville, Aaron and Roux, Nicolas Le , date =. 2025 , eprint =
2025
-
[41]
Kleinman, Michael and Trager, Matthew and Achille, Alessandro and Xia, Wei and Soatto, Stefano , date =. E1:. 2025 , eprint =
2025
- [42]
-
[43]
Lewkowycz, Aitor and Andreassen, Anders Johan and Dohan, David and Dyer, Ethan and Michalewski, Henryk and Ramasesh, Vinay Venkatesh and Slone, Ambrose and Anil, Cem and Schlag, Imanol and Gutman-Solo, Theo and Wu, Yuhuai and Neyshabur, Behnam and Gur-Ari, Guy and Misra, Vedant , date =. Solving. Advances in. 2022 , url =
2022
-
[44]
Li, Wendi and Li, Yixuan , date =. Process. 2025 , eprint =
2025
-
[45]
Li, Mengqi and Zhao, Lei and So, Anthony Man-Cho and Sun, Ruoyu and Li, Xiao , date =. Online. 2025 , eprint =
2025
-
[46]
2025 , eprint =
Li, Jiahui and Li, Lin and Chang, Tai-wei and Kuang, Kun and Chen, Long and Zhou, Jun and Yang, Cheng , date =. 2025 , eprint =
2025
-
[47]
Outcome-
Li, Ziheng and Kang, Liu and Xiao, Feng and Xing, Luxi and Si, Qingyi and Li, Zhuoran and Gong, Weikang and Yang, Deqing and Xiao, Yanghua and Guo, Hongcheng , date =. Outcome-. 2026 , eprint =
2026
-
[48]
Lightman, Hunter and Kosaraju, Vineet and Burda, Yura and Edwards, Harri and Baker, Bowen and Lee, Teddy and Leike, Jan and Schulman, John and Sutskever, Ilya and Cobbe, Karl , date =. Let's. 2023 , eprint =
2023
-
[49]
2025 , eprint =
Lin, Tianqianjin and Zhao, Xi and Zhang, Xingyao and Long, Rujiao and Xu, Yi and Jiang, Zhuoren and Su, Wenbo and Zheng, Bo , date =. 2025 , eprint =
2025
-
[50]
Understanding
Liu, Zichen and Chen, Changyu and Li, Wenjun and Qi, Penghui and Pang, Tianyu and Du, Chao and Lee, Wee Sun and Lin, Min , date =. Understanding. 2025 , eprint =
2025
-
[51]
Liu, Zihe and Liu, Jiashun and He, Yancheng and Wang, Weixun and Liu, Jiaheng and Pan, Ling and Hu, Xinyu and Xiong, Shaopan and Huang, Ju and Hu, Jian and Huang, Shengyi and Yang, Siran and Wang, Jiamang and Su, Wenbo and Zheng, Bo , date =. Part. 2025 , eprint =
2025
-
[52]
2025 , eprint =
Liu, Xiang and Hu, Xuming and Chu, Xiaowen and Choi, Eunsol , date =. 2025 , eprint =
2025
-
[53]
Luo, Haotian and Shen, Li and He, Haiying and Wang, Yibo and Liu, Shiwei and Li, Wei and Tan, Naiqiang and Cao, Xiaochun and Tao, Dacheng , date =. O1-. 2025 , eprint =
2025
-
[54]
General-
Ma, Xueguang and Liu, Qian and Jiang, Dongfu and Zhang, Ge and Ma, Zejun and Chen, Wenhu , date =. General-. 2025 , url =
2025
-
[55]
Noise-Corrected
Mansouri, Omar El and Seddik, Mohamed El Amine and Lahlou, Salem , date =. Noise-Corrected. 2025 , eprint =
2025
-
[56]
2025 , eprint =
Marjanović, Sara Vera and Patel, Arkil and Adlakha, Vaibhav and Aghajohari, Milad and BehnamGhader, Parishad and Bhatia, Mehar and Khandelwal, Aditi and Kraft, Austin and Krojer, Benno and Lù, Xing Han and Meade, Nicholas and Shin, Dongchan and Kazemnejad, Amirhossein and Kamath, Gaurav and Mosbach, Marius and Stańczak, Karolina and Reddy, Siva , date =. ...
2025
-
[57]
Muennighoff, Niklas and Yang, Zitong and Shi, Weijia and Li, Xiang Lisa and Fei-Fei, Li and Hajishirzi, Hannaneh and Zettlemoyer, Luke and Liang, Percy and Candès, Emmanuel and Hashimoto, Tatsunori , date =. S1:. 2025 , eprint =
2025
-
[58]
Reasoning
Nguyen, Bao and Nguyen, Hieu Trung and She, Ruifeng and Fu, Xiaojin and Nguyen, Viet Anh , date =. Reasoning. 2025 , eprint =
2025
-
[59]
Ni, Kangqi and Tan, Zhen and Liu, Zijie and Li, Pingzhi and Chen, Tianlong , date =. Can. 2025 , eprint =
2025
-
[60]
2025 , eprint =
Niu, Lujie and Shen, Lei and Jiang, Yi and Yuan, Caixia and Wang, Xiaojie and Su, Wenbo and. 2025 , eprint =
2025
-
[61]
Asynchronous
Noukhovitch, Michael and Huang, Shengyi and Xhonneux, Sophie and Hosseini, Arian and Agarwal, Rishabh and Courville, Aaron , date =. Asynchronous. 2025 , eprint =
2025
-
[62]
M., prefix=de, useprefix=false and Frujeri, Felipe V
family=Oliveira, given=Bryan L. M., prefix=de, useprefix=false and Frujeri, Felipe V. and Queiroz, Marcos P. C. M. and Martins, Luana G. B. and Soares, Telma W. de L. and Melo, Luckeciano C. , date =. Learning. 2025 , eprint =
2025
-
[63]
2025 , eprint =
Ou, Weixuan and Zheng, Yanzhao and Sun, Shuoshuo and Zhang, Wei and Dong, Baohua and Zhu, Hangcheng and Huang, Ruohui and Yu, Gang and Yan, Pengwei and Qiao, Yifan , date =. 2025 , eprint =
2025
-
[64]
2023 , eprint =
Ozturkler, Batu and Malkin, Nikolay and Wang, Zhen and Jojic, Nebojsa , date =. 2023 , eprint =
2023
-
[65]
and Bick, Aviv and Kolter, J
Paliotta, Daniele and Wang, Junxiong and Pagliardini, Matteo and Li, Kevin Y. and Bick, Aviv and Kolter, J. Zico and Gu, Albert and Fleuret, François and Dao, Tri , date =. Thinking. 2025 , eprint =
2025
-
[66]
Reasoning-
Park, Taekhyun and Lee, Yongjae and Bae, Hyerim , date =. Reasoning-. 2025 , eprint =
2025
-
[67]
2025 , eprint =
Parthasarathi, Prasanna and Reymond, Mathieu and Chen, Boxing and Cui, Yufei and Chandar, Sarath , date =. 2025 , eprint =
2025
-
[68]
Paruchuri, Akshay and Garrison, Jake and Liao, Shun and Hernandez, John and Sunshine, Jacob and Althoff, Tim and Liu, Xin and McDuff, Daniel , date =. What. 2024 , eprint =
2024
-
[69]
and Brandstetter, Johannes and
Patil, Vihang and Hofmarcher, Markus and Dinu, Marius-Constantin and Dorfer, Matthias and Blies, Patrick M. and Brandstetter, Johannes and. Align-. Proceedings of the 39th. 2022 , pages =
2022
-
[70]
Complexity
Qasim, Kaleem Ullah and Zhang, Jiashu and Rehman, Hafiz Saif Ur , date =. Complexity. 2025 , eprint =
2025
-
[71]
and Finn, Chelsea , date =
Rafailov, Rafael and Sharma, Archit and Mitchell, Eric and Ermon, Stefano and Manning, Christopher D. and Finn, Chelsea , date =. Direct. 2024 , eprint =
2024
-
[72]
2025 , eprint =
Schmied, Thomas and Bornschein, Jörg and Grau-Moya, Jordi and Wulfmeier, Markus and Pascanu, Razvan , date =. 2025 , eprint =
2025
-
[73]
2025 , eprint =
Sengupta, Saptarshi and Zhou, Zhengyu and Araki, Jun and Wang, Xingbo and Wang, Bingqing and Wang, Suhang and Feng, Zhe , date =. 2025 , eprint =
2025
-
[74]
Shafayat, Sheikh and Tajwar, Fahim and Salakhutdinov, Ruslan and Schneider, Jeff and Zanette, Andrea , date =. Can. 2025 , eprint =
2025
-
[75]
Shao, Zhihong and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Song, Junxiao and Bi, Xiao and Zhang, Haowei and Zhang, Mingchuan and Li, Y. K. and Wu, Y. and Guo, Daya , date =. 2024 , eprint =
2024
-
[76]
Shrivastava, Vaishnavi and Awadallah, Ahmed and Balachandran, Vidhisha and Garg, Shivam and Behl, Harkirat and Papailiopoulos, Dimitris , date =. Sample. 2025 , eprint =
2025
-
[77]
and Sayeedi, Md Faiyaz Abdullah and Mohiuddin, Tasnim and Islam, Md Mofijul and Shatabda, Swakkhar , date =
Sobhani, Mahbub E. and Sayeedi, Md Faiyaz Abdullah and Mohiuddin, Tasnim and Islam, Md Mofijul and Shatabda, Swakkhar , date =. 2025 , eprint =
2025
-
[78]
2025 , eprint =
Srivastava, Gaurav and Hussain, Aafiya and Bi, Zhenyu and Roy, Swastik and Pitre, Priya and Lu, Meng and Ziyadi, Morteza and Wang, Xuan , date =. 2025 , eprint =
2025
- [79]
-
[80]
2025 , eprint =
Sullivan, Michael , date =. 2025 , eprint =
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.