What's a Credit Worth? A Market Framework for Attribution-Aware Compensation in Generative Music
Pith reviewed 2026-07-02 06:26 UTC · model grok-4.3
The pith
A market framework pays creators for training generative music AI based on attribution scores for their catalogs, with accuracy determining royalty versus fixed-fee contracts and welfare outcomes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
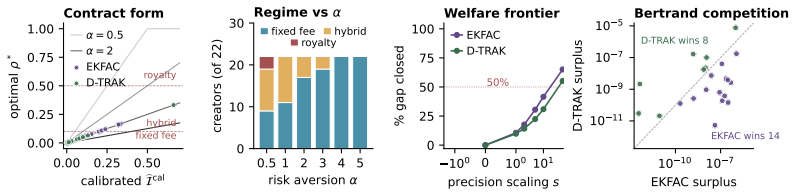
The framework yields a closed-form payment rule per creator and measures the welfare cost of inaccurate attribution for both creators and the platform. Whether the welfare-optimal contract is royalty-based or takes the form of fixed-fee licensing depends on how informative attribution is for that creator's catalog. We show that better attribution translates directly into welfare gains for both creators and the platform, yet under multi-platform competition a platform only captures gains from attribution improvements when its signal becomes the most precise in the market.
What carries the argument
The attribution-aware compensation mechanism that takes catalog-level data-attribution scores and their informativeness (signal-to-noise ratio) as direct inputs to the payment rule.
If this is right
- Better attribution directly increases welfare for both creators and the platform.
- Noisy attribution signals shift optimal payments toward fixed-fee licensing and lower overall welfare.
- Under multi-platform competition, a platform captures gains from attribution improvements only when its signal is the most precise.
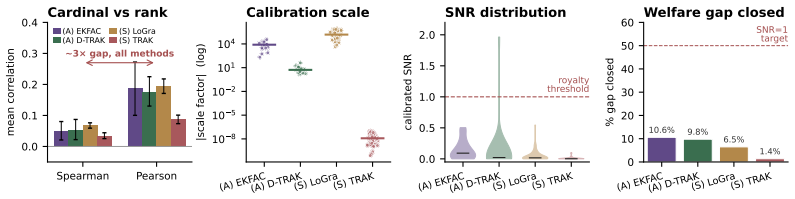
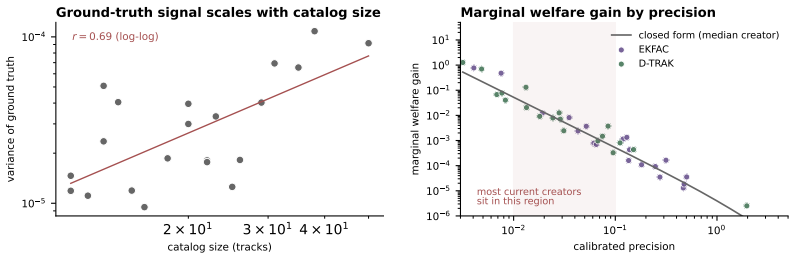
- Empirical tests with acoustic and symbolic music models show that noisy signals reduce welfare and favor fixed-fee contracts.
Where Pith is reading between the lines
- Platforms may invest in attribution technology to gain a competitive edge by becoming the most precise signal holder.
- The same catalog-level attribution logic could apply to compensating creators in other generative domains such as images or text if analogous scores exist.
- Creators might adjust their output strategies to maximize measured attribution if the payment rule is implemented.
Load-bearing premise
Attribution scores can be meaningfully computed for entire creator catalogs and their informativeness can be accurately estimated to serve as reliable inputs to the payment mechanism and welfare calculations.
What would settle it
An experiment or simulation in which switching to a higher-informativeness attribution method produces no measurable increase in creator or platform welfare relative to a lower-informativeness baseline.
Figures
read the original abstract
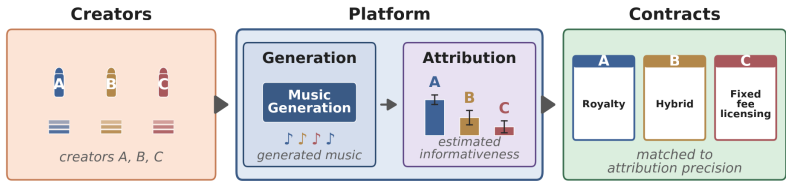
Advances in generative AI are rapidly increasing the quality and commercial value of generated music, and this progress depends on large catalogs of creators' recordings. This raises a central question for platform design: how should creators be compensated when their work is used to train generative AI models that in turn produce commercial outputs? We develop a framework for fairly compensating creators in generative-music markets, where each creator's payment depends on a data-attribution score estimating their contribution to model outputs. Compared to past compensation frameworks, our framework has two unique considerations: (1) attribution is traced to entire creator catalogs, not individual songs, and (2) the informativeness (signal-to-noise ratio) of the attribution score is an input to the payment mechanism. The framework yields a closed-form payment rule per creator and measures the welfare cost of inaccurate attribution for both creators and the platform. Whether the welfare-optimal contract is royalty-based or takes the form of fixed-fee licensing depends on how informative attribution is for that creator's catalog. We show that better attribution translates directly into welfare gains for both creators and the platform, yet under multi-platform competition a platform only captures gains from attribution improvements when its signal becomes the most precise in the market. To ground our framework in empirical behavior, we train acoustic and symbolic music generation models and measure the informativeness of scalable attribution techniques against a leave-one-catalog-out ground truth. Our experiments reveal that noisy attribution signals push payment toward fixed-fee licensing and diminish welfare for both creators and the platform, providing an economic motivation for further research on improved attribution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a market framework for compensating creators in generative music AI markets. Each creator receives a payment based on a catalog-level data-attribution score whose informativeness (signal-to-noise ratio) enters the mechanism as a parameter. The framework produces a closed-form payment rule, quantifies welfare losses from inaccurate attribution for both creators and the platform, shows that the welfare-optimal contract switches between royalty-based and fixed-fee licensing depending on attribution informativeness, demonstrates direct welfare gains from better attribution, and establishes that under multi-platform competition a platform captures those gains only when its attribution signal is the most precise. The theoretical results are grounded by training acoustic and symbolic music models and measuring attribution informativeness against leave-one-catalog-out ground truth.
Significance. If the central derivation and empirical estimates hold, the work supplies a principled, parameter-light mechanism for attribution-aware compensation that directly ties attribution quality to contract design and welfare. The closed-form rule, the royalty-versus-fixed-fee threshold result, and the multi-platform competition finding are all falsifiable and policy-relevant. The leave-one-catalog-out empirical protocol for estimating the key SNR parameter is a concrete methodological contribution that can be replicated in other generative domains.
major comments (2)
- [§3 (payment rule) and §4 (welfare analysis)] The abstract and §4 claim that the payment rule and welfare expressions are closed-form and that the royalty/fixed-fee threshold depends on catalog-level SNR, yet the manuscript provides neither the explicit derivation steps nor the intermediate equations that map the primitives (catalog attribution scores and SNR) to the final payment and welfare formulas. Without these steps it is impossible to confirm that the welfare cost of noisy attribution follows directly rather than from additional functional-form assumptions.
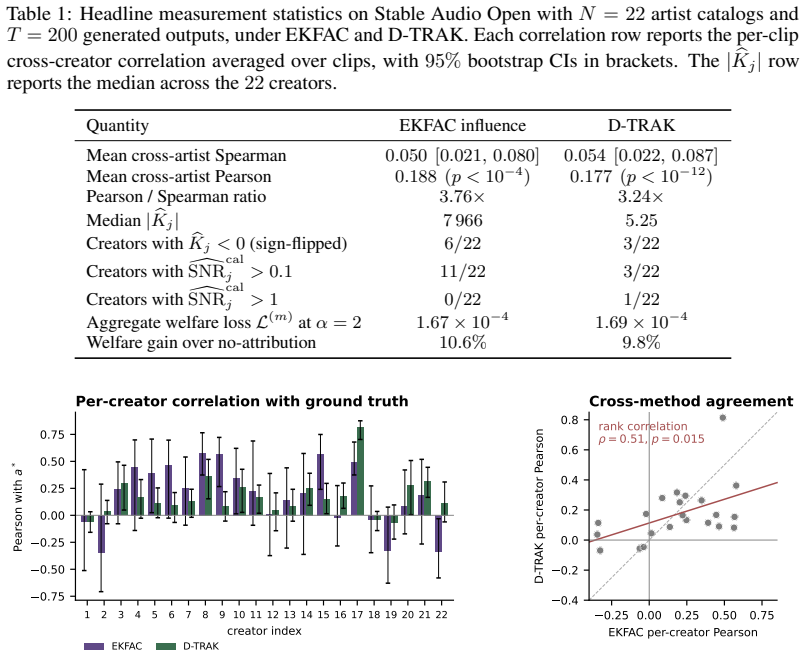
- [Empirical validation section] Experiments section: the leave-one-catalog-out results are reported only as point estimates of attribution informativeness; no sample sizes, standard errors, or sensitivity checks on the SNR values are shown. Because the model predicts that even moderate changes in SNR shift the optimal contract and welfare numbers, the absence of uncertainty quantification makes it difficult to assess whether the empirical finding that "noisy attribution pushes payment toward fixed-fee licensing" is robust.
minor comments (3)
- [§2] The definition of catalog-level attribution score and its aggregation from song-level scores should be stated explicitly before the payment rule is introduced.
- [Figures 3–5] Figure captions for the welfare plots should include the exact SNR values used and the number of catalogs in each panel.
- [§1.2] The related-work discussion of prior compensation schemes should cite the specific functional forms used in those papers so readers can see precisely how the SNR parameter differentiates the present mechanism.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our theoretical derivations and empirical robustness. We address each major comment below and will incorporate the suggested additions in the revised manuscript.
read point-by-point responses
-
Referee: [§3 (payment rule) and §4 (welfare analysis)] The abstract and §4 claim that the payment rule and welfare expressions are closed-form and that the royalty/fixed-fee threshold depends on catalog-level SNR, yet the manuscript provides neither the explicit derivation steps nor the intermediate equations that map the primitives (catalog attribution scores and SNR) to the final payment and welfare formulas. Without these steps it is impossible to confirm that the welfare cost of noisy attribution follows directly rather than from additional functional-form assumptions.
Authors: We agree that the main text did not include sufficient intermediate steps for the closed-form derivations. In the revision we will expand §3 to show the full mapping from catalog attribution scores and SNR to the payment rule, including all intermediate equations, and then derive the welfare expressions in §4 directly from those primitives. This will confirm that the welfare cost of noisy attribution follows from the model without additional functional-form assumptions. revision: yes
-
Referee: [Empirical validation section] Experiments section: the leave-one-catalog-out results are reported only as point estimates of attribution informativeness; no sample sizes, standard errors, or sensitivity checks on the SNR values are shown. Because the model predicts that even moderate changes in SNR shift the optimal contract and welfare numbers, the absence of uncertainty quantification makes it difficult to assess whether the empirical finding that "noisy attribution pushes payment toward fixed-fee licensing" is robust.
Authors: We acknowledge that the empirical section lacked uncertainty quantification. In the revision we will report the sample sizes for the leave-one-catalog-out protocol, add standard errors to the attribution informativeness estimates, and include sensitivity checks that vary SNR around the point estimates to show the resulting shifts in optimal contract type and welfare values. This will allow readers to assess the robustness of the finding that noisy attribution favors fixed-fee licensing. revision: yes
Circularity Check
No significant circularity; derivation self-contained with independent empirical inputs
full rationale
The framework derives closed-form payment rules, welfare costs, and optimal contract forms (royalty vs. fixed-fee) directly from primitives consisting of catalog-level attribution scores and their informativeness (signal-to-noise ratio) as exogenous inputs to the mechanism. These quantities are not defined in terms of the derived payments or welfare values. The informativeness parameter is measured separately via leave-one-catalog-out experiments on trained music models against ground-truth attribution, providing an external benchmark independent of the theoretical outputs. No equation reduces by construction to a fitted parameter renamed as a prediction, no self-citation is load-bearing for the central claims, and no ansatz or uniqueness result is smuggled in. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- attribution informativeness (SNR)
axioms (1)
- domain assumption Economic agents (creators and platforms) maximize expected welfare under the derived payment rules.
Reference graph
Works this paper leans on
-
[1]
Acemoglu, A
D. Acemoglu, A. Makhdoumi, A. Malekian, and A. Ozdaglar. Too much data: Prices and inefficiencies in data markets.American Economic Journal: Microeconomics, 14(4):218–256, 2022
2022
-
[2]
Agarwal, M
A. Agarwal, M. Dahleh, and T. Sarkar. A marketplace for data: An algorithmic solution. In Proceedings of the 2019 ACM Conference on Economics and Computation, pages 701–726, 2019
2019
-
[3]
MusicLM: Generating Music From Text
A. Agostinelli, T. I. Denk, Z. Borsos, J. Engel, M. Verzetti, A. Caber, N. Zeghidour, and C. Frank. MusicLM: Generating music from text, 2023. arXiv preprint arXiv:2301.11325
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
G. A. Akerlof. The market for “lemons”: Quality uncertainty and the market mechanism.The Quarterly Journal of Economics, 84(3):488–500, 1970
1970
-
[5]
J. Bae, W. Lin, J. Lorraine, and R. Grosse. Training data attribution via approximate unrolled differentiation. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[6]
J. Barnett, H. Flores Garcia, and B. Pardo. Exploring musical roots: Applying audio embed- dings to empower influence attribution for a generative music model, 2024. arXiv preprint arXiv:2401.14542
-
[7]
Bergemann, A
D. Bergemann, A. Bonatti, and A. Smolin. The design and price of information.American Economic Review, 108(1):1–48, 2018
2018
-
[8]
Bogdanov, M
D. Bogdanov, M. Won, P. Tovstogan, A. Porter, and X. Serra. The MTG-Jamendo dataset for automatic music tagging. InMachine Learning for Music Discovery Workshop, International Conference on Machine Learning (ICML), 2019
2019
-
[9]
A. Caillon, B. McWilliams, C. Tarakajian, I. Simon, I. Manco, J. Engel, N. Constant, Y . Li, et al. Live music models. InAdvances in Neural Information Processing Systems (NeurIPS), Creative AI Track, 2025. arXiv preprint arXiv:2508.04651
-
[10]
Y . Chen, H. Liu, and A. Karbasi. Selling data to a machine learner. InInternational Conference on Machine Learning (ICML), 2022. 10
2022
-
[11]
Sang Keun Choe, Hwijeen Ahn, Juhan Bae, Kewen Zhao, Minsoo Kang, Youngseog Chung, Adithya Pratapa, Willie Neiswanger, Emma Strubell, Teruko Mitamura, et al. What is your data worth to gpt? llm-scale data valuation with influence functions.arXiv preprint arXiv:2405.13954, 2024
-
[12]
W. Choi, J. Koo, K. W. Cheuk, J. Serrà, M. A. Martinez-Ramirez, Y . Ikemiya, N. Murata, Y . Takida, W.-H. Liao, and Y . Mitsufuji. Large-scale training data attribution for music generative models via unlearning. InAdvances in Neural Information Processing Systems (NeurIPS), Creative AI Track, 2025
2025
-
[13]
L. W. Cong, W. Wei, D. Xie, and L. Zhang. Data, ai, and economic growth. Nber working paper, NBER, 2022
2022
-
[14]
Copet, F
J. Copet, F. Kreuk, I. Gat, T. Remez, D. Kant, G. Synnaeve, Y . Adi, and A. Défossez. Simple and controllable music generation. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[15]
T. M. Cover and J. A. Thomas.Elements of Information Theory. Wiley-Interscience, 2nd edition, 2006
2006
-
[16]
Deezer: AI-generated tracks now represent 44% of all new uploaded mu- sic
Deezer. Deezer: AI-generated tracks now represent 44% of all new uploaded mu- sic. Deezer Newsroom, 2026. URL https://newsroom.deezer.com/2026/04/ai- generated-tracks-represent-44-of-new-uploaded-music/ . Published April 20, 2026
2026
- [17]
-
[18]
Jukebox: A Generative Model for Music
P. Dhariwal, H. Jun, C. Payne, J. W. Kim, A. Radford, and I. Sutskever. Jukebox: A generative model for music, 2020. arXiv preprint arXiv:2005.00341
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[19]
Dieleman, A
S. Dieleman, A. van den Oord, and K. Simonyan. The challenge of realistic music generation: modelling raw audio at scale. InAdvances in Neural Information Processing Systems (NeurIPS), 2018
2018
-
[20]
Melody transcription via generative pre- training
Chris Donahue, John Thickstun, and Percy Liang. Melody transcription via generative pre- training. InISMIR, 2022
2022
-
[21]
Hookpad aria: A copilot for songwriters.arXiv preprint arXiv:2502.08122, 2025
Chris Donahue, Shih-Lun Wu, Yewon Kim, Dave Carlton, Ryan Miyakawa, and John Thickstun. Hookpad aria: A copilot for songwriters.arXiv preprint arXiv:2502.08122, 2025
-
[22]
Engstrom, A
L. Engstrom, A. Feldmann, and A. M ˛ adry. DsDm: Model-aware dataset selection with data- models. InInternational Conference on Machine Learning (ICML), 2024
2024
-
[23]
Regulation (EU) 2024/1689 laying down harmonised rules on artificial intelligence (AI act)
European Parliament and Council of the European Union. Regulation (EU) 2024/1689 laying down harmonised rules on artificial intelligence (AI act). Technical report, European Parliament and Council of the European Union, 2024. Official Journal of the European Union
2024
- [24]
-
[25]
Forsgren and H
S. Forsgren and H. Martiros. Riffusion: Stable diffusion for real-time music generation, 2022. URLhttps://riffusion.com/about
2022
-
[26]
K. Georgiev, J. Vendrow, H. Salman, S. M. Park, and A. Madry. The journey, not the destination: How data guides diffusion models, 2023. arXiv preprint arXiv:2312.06205
-
[27]
Ghorbani and J
A. Ghorbani and J. Zou. Data Shapley: Equitable valuation of data for machine learning. In Proceedings of the 36th International Conference on Machine Learning, pages 2242–2251, 2019
2019
-
[28]
Giordano, W
R. Giordano, W. Stephenson, R. Liu, M. Jordan, and T. Broderick. A Swiss army infinitesimal jackknife. InProceedings of the 22nd International Conference on Artificial Intelligence and Statistics, pages 1139–1147, 2019
2019
- [29]
-
[31]
R. Grosse, J. Bae, C. Anil, et al. Studying large language model generalization with influence functions, 2023. arXiv preprint arXiv:2308.03296
-
[32]
Guruganesh, J
G. Guruganesh, J. Schneider, and J. R. Wang. Contracts under moral hazard and adverse selection. InProceedings of the 22nd ACM Conference on Economics and Computation (EC), 2021
2021
-
[33]
Hirshleifer
J. Hirshleifer. The private and social value of information and the reward to inventive activity. The American Economic Review, 61(4):561–574, 1971
1971
-
[34]
J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilistic models. InAdvances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[35]
Holmström
B. Holmström. Moral hazard and observability.The Bell Journal of Economics, 10(1):74–91, 1979
1979
-
[36]
Holmström and P
B. Holmström and P. Milgrom. Aggregation and linearity in the provision of intertemporal incentives.Econometrica, 55(2):303–328, 1987
1987
-
[37]
Ilyas, S
A. Ilyas, S. M. Park, L. Engstrom, G. Leclerc, and A. Madry. Datamodels: Predicting predictions from training data. InProceedings of the 39th International Conference on Machine Learning, pages 9525–9587, 2022
2022
-
[38]
Global music report 2025
International Federation of the Phonographic Industry (IFPI). Global music report 2025. Technical report, IFPI, 2025
2025
-
[39]
R. Jia, D. Dao, B. Wang, F. A. Hubis, N. Hynes, N. M. Gürel, B. Li, C. Zhang, D. Song, and C. Spanos. Towards efficient data valuation based on the Shapley value. InProceedings of the 22nd International Conference on Artificial Intelligence and Statistics, pages 1167–1176, 2019
2019
-
[40]
C. I. Jones and C. Tonetti. Nonrivalry and the economics of data.American Economic Review, 110(9):2819–2858, 2020
2020
-
[41]
Amuse: Human-ai collaborative songwriting with multimodal inspirations
Yewon Kim, Sung-Ju Lee, and Chris Donahue. Amuse: Human-ai collaborative songwriting with multimodal inspirations. InProceedings of the 2025 CHI conference on human factors in computing systems, pages 1–28, 2025
2025
-
[42]
P. W. Koh and P. Liang. Understanding black-box predictions via influence functions. In Proceedings of the 34th International Conference on Machine Learning, pages 1885–1894, 2017
2017
-
[43]
Y . Kwon, E. Wu, K. Wu, and J. Zou. DataInf: Efficiently estimating data influence in LoRA- tuned LLMs and diffusion models. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[44]
Markowitz
H. Markowitz. Portfolio selection.The Journal of Finance, 7(1):77–91, 1952
1952
-
[45]
Maskin and J
E. Maskin and J. Riley. Monopoly with incomplete information.The RAND Journal of Economics, 15(2):171–196, 1984
1984
-
[46]
Bruno Kacper Mlodozeniec, Runa Eschenhagen, Juhan Bae, Alexander Immer, David Krueger, and Richard E. Turner. Influence functions for scalable data attribution in diffusion models. InInternational Conference on Learning Representations (ICLR), 2025. URL https:// openreview.net/forum?id=esYrEndGsr
2025
-
[47]
Mussa and S
M. Mussa and S. Rosen. Monopoly and product quality.Journal of Economic Theory, 18(2): 301–317, 1978
1978
-
[48]
S. M. Park, K. Georgiev, A. Ilyas, G. Leclerc, and A. Madry. TRAK: Attributing model behavior at scale. InProceedings of the 40th International Conference on Machine Learning, pages 27074–27113, 2023
2023
-
[49]
J. W. Pratt. Risk aversion in the small and in the large.Econometrica, 32(1/2):122–136, 1964
1964
-
[50]
Pruthi, F
G. Pruthi, F. Liu, S. Kale, and M. Sundararajan. Estimating training data influence by tracing gradient descent. InAdvances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[51]
Major record labels file copyright in- fringement suits against AI music generators Suno and Udio
Recording Industry Association of America (RIAA). Major record labels file copyright in- fringement suits against AI music generators Suno and Udio. Press release, Recording Industry Association of America (RIAA), 2024. Press release, June 2024. 12
2024
-
[52]
Rombach, A
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[53]
L. L. Scharf.Statistical Signal Processing: Detection, Estimation, and Time Series Analysis. Addison-Wesley, 1991
1991
-
[54]
Serrà, E
J. Serrà, E. Gómez, and P. Herrera. Audio cover song identification and similarity: Background, approaches, evaluation, and beyond. InAdvances in Music Information Retrieval, pages 307–332. Springer, 2010
2010
-
[55]
C. E. Shannon. A mathematical theory of communication.The Bell System Technical Journal, 27(3):379–423, 1948
1948
-
[56]
Silberling
A. Silberling. AI music generator Suno hits 2M paid subscribers and $300M in annual recurring revenue. TechCrunch, 2026. URL https://techcrunch.com/2026/02/27/ai-music- generator-suno-hits-2-million-paid-subscribers-and-300m-in-annual- recurring-revenue/. Published February 27, 2026
2026
-
[57]
Spijkervet and J
J. Spijkervet and J. A. Burgoyne. Contrastive learning of musical representations. InProceedings of the 22nd International Society for Music Information Retrieval Conference (ISMIR), 2021
2021
-
[58]
Anticipatory music transformer
John Thickstun, David Hall, Chris Donahue, and Percy Liang. Anticipatory music transformer. TMLR, 2024
2024
-
[59]
van den Oord, O
A. van den Oord, O. Vinyals, and K. Kavukcuoglu. Neural discrete representation learning. In Advances in Neural Information Processing Systems (NeurIPS), 2017
2017
-
[60]
A. L.-C. Wang. An industrial-strength audio search algorithm. InProceedings of the 4th International Conference on Music Information Retrieval (ISMIR), pages 7–13, 2003
2003
-
[61]
Zhang, C
L. Zhang, C. Jiao, B. Li, and C. Xiong. Fairshare data pricing via data valuation for large language models. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[62]
Zheng, T
X. Zheng, T. Pang, C. Du, Q. Liu, J. Jiang, and M. Lin. Intriguing properties of data attribution on diffusion models. InInternational Conference on Learning Representations (ICLR), 2024. 13 A Gaussian special case and simplifying conditions The main results (Theorem 1, Propositions 1–3) hold for any noise structure through the general informativeness mea...
2024
-
[63]
The excess isL uniform j =R uniform j −R ∗ j
For creators who remain (j /∈ Sexit), the risk premium is Runiform j = αj 2 ¯ρ2 Var(vj), which is generically larger thanR ∗ j since¯ρ̸=ρ ∗ j . The excess isL uniform j =R uniform j −R ∗ j
-
[64]
Summing these two terms yields the uniform-contract welfare gap
For creators who exit ( j∈ S exit), the platform loses their entire contribution, which by Claim 2 is superlinear. Summing these two terms yields the uniform-contract welfare gap. E Multi-platform Bertrand competition This appendix gives the formal results behind the attribution-moat analysis (Section 3.3): the proof of the multi-platform Bertrand equilib...
-
[65]
Budget shares follow a square law in marginal welfare gains
Closed form under square-root technology.If gj(β) =γ j √β, the first-order approximation of the optimal allocation is βapprox j = (ϕjγj)2 P k(ϕkγk)2 ·B. Budget shares follow a square law in marginal welfare gains. 4.Comparative statics.∂β j/∂Sj <0,∂β j/∂αj <0,∂β j/∂Var(a ∗ j)>0. Proof. (i) L(S) is strictly convex for S >0 : L′′ = Λ(6S2 + 6S+ 2)/[S 3(1 +S)...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.