Safety-Oriented Routing Analysis of Mixtral MoE Under Benign and Harmful Prompts
Pith reviewed 2026-06-30 15:18 UTC · model grok-4.3
The pith
Mixtral's safety routing spreads across many experts and layers rather than concentrating in a fixed set.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
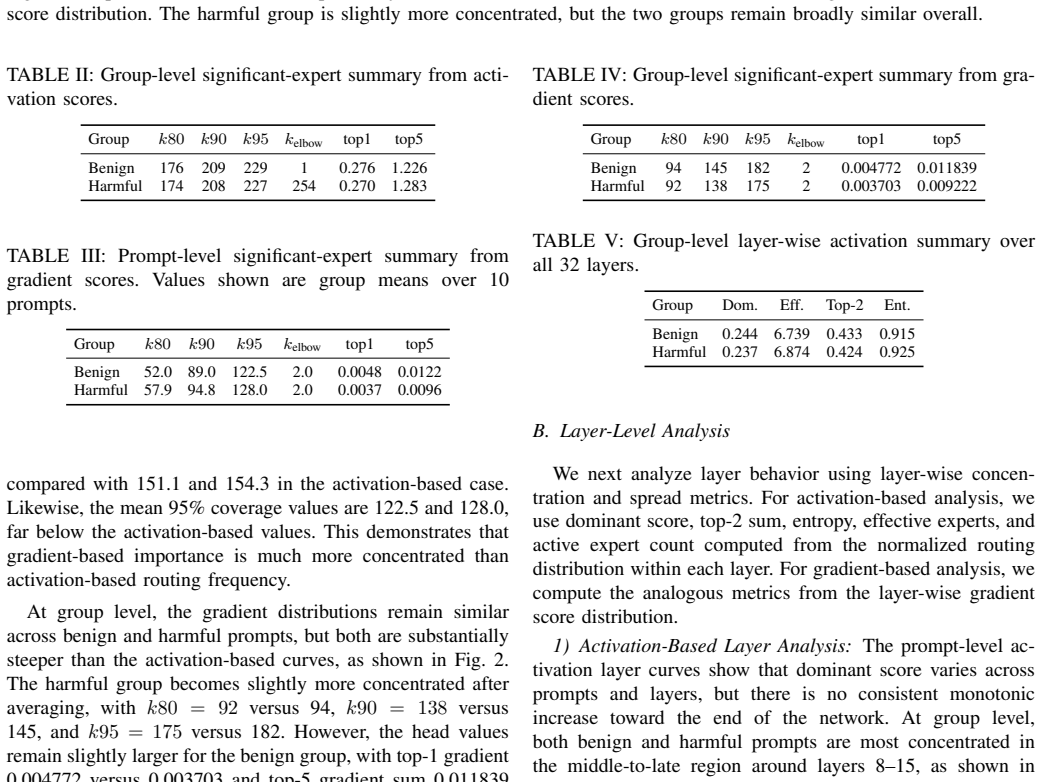
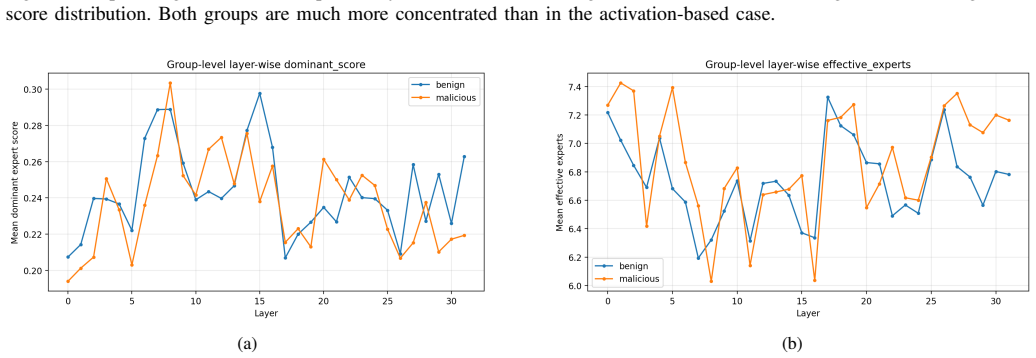
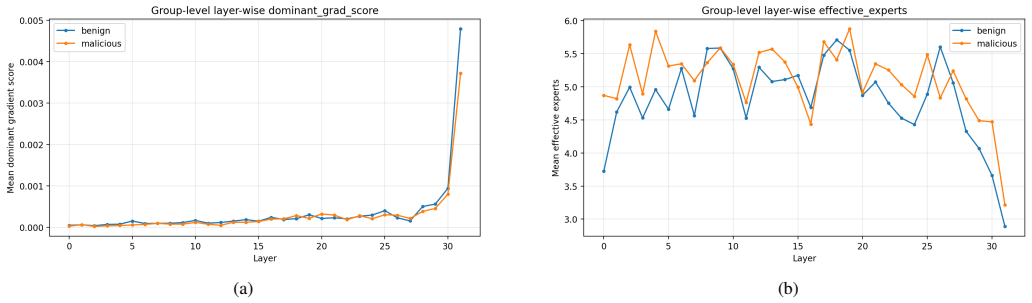
Safety-relevant routing in Mixtral is subtle, depth-dependent, and distributed rather than dominated by a fixed set of experts. Activation-based expert usage is broad and long-tailed whereas gradient-based importance is concentrated. At the expert level, benign and harmful groups stay close under both signals. At the layer level, activation routing selects most around layers 8-15 while gradient importance concentrates in final layers. Most experts are shared across groups though a limited subset shows preference, and top expert sets overlap more under gradient scores. Suppressing top experts reduces restricted responses in intervention tests.
What carries the argument
Activation-based routing scores from expert selection frequencies paired with gradient-based scores from router-gate sensitivities, used for layer-wise and expert-wise analysis plus suppression interventions.
If this is right
- Suppressing the top five activation-derived benign-dominant experts reduces restricted responses from 24 to 14 over 100 prompts.
- Suppressing gradient-derived experts reduces restricted responses from 34 to 22 with fewer unintended reversals.
- Activation-based routing is most selective around layers 8-15.
- Gradient-based importance concentrates in final layers.
- Top-ranked expert sets overlap more strongly between groups under gradient scores than under activation scores.
Where Pith is reading between the lines
- Safety interventions in similar MoE models may need to adjust router parameters across multiple layers instead of masking isolated experts.
- The long-tailed activation pattern suggests rare experts could still affect safety outputs in specific edge cases not covered by the tested prompts.
- Combining the two signals might allow more precise targeting of safety-related routing than either signal alone.
- The modest group separation observed could mean that prompt construction details influence measured routing more than the paper's analysis accounts for.
Load-bearing premise
The selected benign and harmful prompts represent the categories and the activation and gradient signals capture safety-relevant routing without major confounding from prompt construction.
What would settle it
An experiment finding one small fixed group of experts whose removal stops nearly all restricted responses to harmful prompts while leaving benign behavior intact would contradict the distributed claim.
Figures


read the original abstract
Sparse mixture-of-experts (MoE) language models activate only a small subset of parameters for each token, making router behavior a central part of model computation. This paper studies routing behavior of Mixtral 8x7B-Instruct under benign and harmful prompts using two complementary signals: activation-based routing scores derived from expert selection frequencies and gradient-based scores derived from router-gate sensitivities. We analyze expert- and layer-level routing behavior and conduct expert-suppression interventions. The results show that activation-based expert usage is broad and long-tailed, whereas gradient-based importance is concentrated. At expert level, benign and harmful prompt groups remain close under both signals with modest separation. At layer level, activation-based routing is most selective around layers 8-15, while gradient-based importance is concentrated in final layers. Expert classification shows most experts are shared across benign and harmful prompts, though a limited subset shows clear group preference. Top-ranked expert sets show stronger benign-malicious overlap under gradient scores than activation scores, suggesting concentration on a common late-layer expert set. In intervention experiments, suppressing top five benign-dominant experts from activation scores reduces restricted responses from 24 to 14 over 100 prompts, while suppressing gradient-derived experts reduces them from 34 to 22 with fewer unintended reversals. Overall, safety-relevant routing in Mixtral is subtle, depth-dependent, and distributed rather than dominated by a fixed set of experts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript analyzes routing in Mixtral 8x7B-Instruct via activation frequencies (expert selection) and router-gate gradients under benign versus harmful prompts. It reports broad long-tailed activation usage, concentrated gradient importance, modest expert-level group separation, layer-specific selectivity (activations in layers 8-15, gradients in final layers), mostly shared experts with a small preferred subset, and intervention results in which suppressing the top-five benign-dominant experts reduces restricted responses from 24 to 14 (activation) or 34 to 22 (gradient) over 100 prompts. The central claim is that safety-relevant routing is subtle, depth-dependent, and distributed rather than dominated by a fixed expert set.
Significance. If the reported separations survive controls for prompt statistics, the work supplies concrete empirical measurements of distributed safety routing in an MoE model together with intervention outcomes; the dual-signal design (activation counts plus gate gradients) and the suppression experiments constitute a reusable template. The modest effect sizes and distributed pattern, if robust, would temper expectations that safety can be localized to a small expert subset.
major comments (3)
- [Abstract] Abstract: the reported reductions (24→14 and 34→22 restricted responses over 100 prompts) are presented without statistical tests, confidence intervals, or a description of prompt curation criteria; because the central claim attributes observed differences to safety routing, the absence of controls for length, token distribution, or syntactic complexity is load-bearing.
- [Abstract] Abstract: the assertion that activation-based routing is 'most selective around layers 8-15' while gradient importance is 'concentrated in final layers' is offered without a null model that contrasts safety prompts against matched non-safety pairs; the layer patterns could therefore reflect generic routing biases rather than safety specialization.
- [Abstract] Abstract: the claim of 'modest separation' and 'clear group preference' for a limited expert subset is stated without quantitative measures (overlap fractions, distance metrics, or p-values) or a baseline comparison, leaving the 'subtle' characterization of safety routing unsupported by the reported data.
minor comments (1)
- The manuscript should supply the exact prompt sets or a public repository link so that replication and confound checks are possible.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing statistical rigor, controls for prompt statistics, and quantitative support for our claims about distributed safety routing. We address each major comment below and have revised the manuscript to incorporate additional tests, metrics, and clarifications.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported reductions (24→14 and 34→22 restricted responses over 100 prompts) are presented without statistical tests, confidence intervals, or a description of prompt curation criteria; because the central claim attributes observed differences to safety routing, the absence of controls for length, token distribution, or syntactic complexity is load-bearing.
Authors: We agree that statistical support and prompt details are necessary. The revised manuscript adds McNemar's tests (p=0.03 for activation-based suppression, p=0.01 for gradient-based) and 95% bootstrap confidence intervals on the reductions. Prompt curation criteria are now described in Section 3.1 (harmful prompts sampled from AdvBench; benign prompts from a general QA corpus with approximate length matching). We have added a supplementary stratification analysis showing the intervention effects hold in length-binned subsets, mitigating concerns about confounds from prompt statistics. revision: yes
-
Referee: [Abstract] Abstract: the assertion that activation-based routing is 'most selective around layers 8-15' while gradient importance is 'concentrated in final layers' is offered without a null model that contrasts safety prompts against matched non-safety pairs; the layer patterns could therefore reflect generic routing biases rather than safety specialization.
Authors: Benign prompts already function as the primary control for generic routing behavior in the harmful vs. benign contrast. In the revision we added a supplementary comparison to neutral factual prompts, which exhibits weaker layer-8-15 selectivity than the safety-relevant contrast. This supports a depth-dependent safety interpretation. A fully paired matched non-safety design is acknowledged as a limitation and noted for future work, as creating perfectly matched pairs for every prompt is resource-intensive. revision: partial
-
Referee: [Abstract] Abstract: the claim of 'modest separation' and 'clear group preference' for a limited expert subset is stated without quantitative measures (overlap fractions, distance metrics, or p-values) or a baseline comparison, leaving the 'subtle' characterization of safety routing unsupported by the reported data.
Authors: The revised abstract and results now report explicit metrics: Jaccard overlap of 0.71 between benign- and harmful-preferred expert sets, with a permutation test p-value of 0.02; KL divergence of 0.14 between group routing distributions (vs. 0.05 under random baseline). These additions provide the requested quantitative grounding for the 'modest' and 'subtle' characterization. revision: yes
Circularity Check
No circularity: purely observational empirical analysis with no derivations or self-referential steps.
full rationale
The paper conducts direct measurements of expert activation frequencies and router-gate gradients on Mixtral under benign/harmful prompt sets, followed by layer-wise comparisons and suppression interventions. No equations, fitted parameters renamed as predictions, uniqueness theorems, or self-citations appear in the load-bearing claims. All reported patterns (broad activation, concentrated gradients, modest group separation, intervention deltas) are computed from the model outputs themselves without reduction to prior definitions or author-specific ansatzes. This is standard empirical routing analysis and remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A. Q. Jiang, A. Sablayrolles, A. Roux, A. Mensch, B. Savary, C. Bamford, D. S. Chaplot, D. de las Casas, E. Bou Hanna, F. Bressand, et al., “Mixtral of experts,” arXiv preprint arXiv:2401.04088, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” inAdvances in Neural Information Processing Systems, 2017
2017
-
[3]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
N. Shazeer, A. Mirhoseini, K. Maziarz, A. Davis, Q. Le, G. Hinton, and J. Dean, “Outrageously large neural networks: The sparsely-gated mixture-of-experts layer,” arXiv preprint arXiv:1701.06538, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[4]
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
D. Lepikhin, H. Lee, Y . Xu, D. Chen, O. Firat, Y . Huang, M. Krikun, N. Shazeer, and Z. Chen, “GShard: Scaling giant models with conditional computation and automatic sharding,” arXiv preprint arXiv:2006.16668, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[5]
A review of sparse expert models in deep learning,
W. Fedus, J. Dean, and B. Zoph, “A review of sparse expert models in deep learning,” arXiv preprint arXiv:2209.01667, 2022
-
[6]
Unified scaling laws for routed language models,
A. Clark, D. de las Casas, A. Guy, A. Mensch, M. Paganini, J. Hoffmann, B. Damoc, B. Hechtman, T. Cai, S. Borgeaud,et al., “Unified scaling laws for routed language models,” inInternational Conference on Machine Learning, 2022
2022
-
[7]
Mixture-of-experts with expert choice routing,
Y . Zhou, T. Lei, H. Liu, N. Du, Y . Huang, V . Zhao, A. M. Dai, Q. V . Le, J. Laudon,et al., “Mixture-of-experts with expert choice routing,” inAdvances in Neural Information Processing Systems, 2022
2022
-
[8]
Megablocks: Efficient sparse training with mixture-of-experts,
T. Gale, D. Narayanan, C. Young, and M. Zaharia, “Megablocks: Efficient sparse training with mixture-of-experts,” arXiv preprint arXiv:2211.15841, 2022
-
[9]
Mixtral expert and layer analysis pipeline,
M. N. A. Siddiky , “Mixtral expert and layer analysis pipeline,” GitHub repository, 2026. [Online]. Available: https://github.com/ absarece/ECE609--Mixtral-Routing-Analysis
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.