VT-Bench: A Unified Benchmark for Visual-Tabular Multi-Modal Learning
Pith reviewed 2026-05-21 00:27 UTC · model grok-4.3
The pith
VT-Bench collects 14 visual-tabular datasets across nine domains to create the first standard test for models that combine images with tables.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
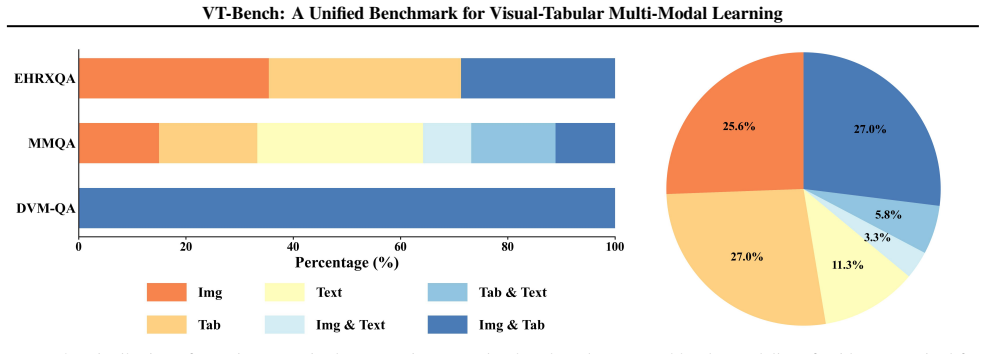
VT-Bench is the first unified benchmark for standardizing vision-tabular discriminative prediction and generative reasoning tasks. It aggregates 14 datasets across 9 domains with over 756K samples and evaluates 23 representative models, including unimodal experts, specialized visual-tabular models, general-purpose vision-language models, and tool-augmented methods, to highlight substantial challenges of visual-tabular learning.
What carries the argument
VT-Bench, the aggregated collection of 14 datasets and defined tasks that standardizes testing of models required to process both visual inputs and tabular records at once.
If this is right
- Researchers gain a single, reproducible way to compare unimodal, specialized, and vision-language models on the same visual-tabular problems.
- The evaluation results identify concrete performance gaps that new model designs must close.
- Development of foundation models able to handle combined vision and tabular data receives a clear target for improvement.
- High-stakes applications in healthcare and industry obtain a pathway toward more reliable multi-modal systems.
Where Pith is reading between the lines
- Similar aggregation efforts could be applied to other modality pairs such as audio with tables to test whether the same integration problems appear.
- Adding datasets from additional domains over time would let the benchmark track whether progress generalizes beyond the initial nine areas.
- The identified challenges suggest value in testing whether new fusion layers or reasoning modules improve results across the full set of tasks.
Load-bearing premise
The chosen datasets and domains supply a representative sample of visual-tabular difficulties without selection effects or domain artifacts shaping the measured challenges.
What would settle it
A new model achieving high scores on VT-Bench yet showing poor results on fresh visual-tabular cases drawn from a medical or industrial setting outside the nine included domains would show that the benchmark does not capture the full range of real difficulties.
Figures














read the original abstract
Multi-model learning has attracted great attention in visual-text tasks. However, visual-tabular data, which plays a pivotal role in high-stakes domains like healthcare and industry, remains underexplored. In this paper, we introduce \textit{VT-Bench}, the first unified benchmark for standardizing vision-tabular discriminative prediction and generative reasoning tasks. VT-Bench aggregates 14 datasets across 9 domains (medical-centric, while covering pets, media, and transportation) with over 756K samples. We evaluate 23 representative models, including unimodal experts, specialized visual-tabular models, general-purpose vision-language models (VLMs), and tool-augmented methods, highlighting substantial challenges of visual-tabular learning. We believe VT-Bench will stimulate the community to build more powerful multi-modal vision-tabular foundation models. Benchmark: https://github.com/Ziyi-Jia990/VT-Bench
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces VT-Bench as the first unified benchmark for visual-tabular multi-modal learning. It aggregates 14 datasets across 9 domains (described as medical-centric while covering pets, media, and transportation) totaling over 756K samples, defines discriminative prediction and generative reasoning tasks, and evaluates 23 models spanning unimodal experts, specialized visual-tabular models, VLMs, and tool-augmented approaches to demonstrate substantial challenges.
Significance. A well-curated, standardized benchmark in this underexplored area could provide a valuable testbed for future work on multi-modal models in high-stakes domains. The public release of the benchmark and associated code is a concrete strength that supports reproducibility and community follow-up.
major comments (3)
- [§3] §3 (Benchmark Construction): The manuscript states the collection is 'medical-centric' but provides no quantitative breakdown of sample counts or task difficulty per domain, nor explicit inclusion/exclusion criteria or cross-domain calibration. This directly bears on the central claim that the benchmark 'highlights substantial challenges' in a generalizable way rather than domain-specific artifacts.
- [§4] §4 (Evaluation Protocol): Task standardization, preprocessing pipelines, and handling of missing tabular values or image resolutions are not described with sufficient detail to verify fairness across the 23 models. Without these, performance gaps cannot be confidently attributed to intrinsic visual-tabular difficulties.
- [§5] §5 (Results): Reported model performances lack error bars, statistical significance tests, or ablation on domain subsets. This weakens the claim that the benchmark reveals 'substantial challenges' that are representative rather than driven by the majority medical samples.
minor comments (2)
- [Abstract] The abstract could more precisely state the number of discriminative vs. generative tasks and the primary quantitative findings from the 23-model evaluation.
- [Figure 1] Figure 1 or the benchmark overview table should include per-domain sample counts and modality statistics for immediate clarity.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive review. We have addressed each major comment by adding quantitative details, expanding methodological descriptions, and incorporating statistical analyses to strengthen the transparency and generalizability of VT-Bench.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark Construction): The manuscript states the collection is 'medical-centric' but provides no quantitative breakdown of sample counts or task difficulty per domain, nor explicit inclusion/exclusion criteria or cross-domain calibration. This directly bears on the central claim that the benchmark 'highlights substantial challenges' in a generalizable way rather than domain-specific artifacts.
Authors: We agree that a quantitative breakdown strengthens the claims. In the revised manuscript, we have added Table 2 in §3 detailing sample counts, task types, and difficulty proxies (e.g., class imbalance ratios) for each domain. Inclusion criteria are now explicitly stated: datasets were chosen for paired image-tabular availability, public accessibility, and coverage of high-stakes applications, with exclusion of purely synthetic or single-modality sets. Cross-domain calibration is achieved via unified task templates (e.g., standardized input formatting for prediction and reasoning), while preserving domain-specific features to reflect real-world variability. This supports that challenges are not artifacts of medical dominance alone. revision: yes
-
Referee: [§4] §4 (Evaluation Protocol): Task standardization, preprocessing pipelines, and handling of missing tabular values or image resolutions are not described with sufficient detail to verify fairness across the 23 models. Without these, performance gaps cannot be confidently attributed to intrinsic visual-tabular difficulties.
Authors: We appreciate this point on reproducibility. Section 4 has been expanded with a dedicated subsection on preprocessing: all images are resized to 224×224 with consistent augmentations; missing tabular values are handled via median imputation for numerical features and mode for categorical, with explicit masking flags; task standardization includes fixed prompt templates for generative tasks and label encoding for discriminative ones. These details ensure consistent evaluation across unimodal, VLM, and tool-augmented models. revision: yes
-
Referee: [§5] §5 (Results): Reported model performances lack error bars, statistical significance tests, or ablation on domain subsets. This weakens the claim that the benchmark reveals 'substantial challenges' that are representative rather than driven by the majority medical samples.
Authors: We acknowledge the need for statistical rigor. The revised §5 now includes error bars (standard deviation over 5 random seeds) for all reported metrics, paired t-tests for significance between top models, and a new ablation table comparing performance on medical vs. non-medical domain subsets. Results confirm that substantial challenges (e.g., low generative accuracy) persist in both subsets, supporting generalizability beyond medical data dominance. revision: yes
Circularity Check
No circularity: empirical benchmark with no derivations or self-referential predictions
full rationale
VT-Bench is a curation and evaluation paper that aggregates 14 existing datasets across domains and runs 23 models on them to report performance. No equations, fitted parameters, or first-principles derivations appear in the abstract or described content. The central claim (that the benchmark highlights substantial challenges) is an empirical observation from the released testbed rather than a closed-loop result that reduces to its own inputs by construction. Dataset selection and domain coverage are open to criticism on representativeness, but that is a question of external validity, not circularity in any derivation chain.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
VT-Bench aggregates 14 datasets across 9 domains (medical-centric...) with over 756K samples. We evaluate 23 representative models... highlighting substantial challenges of visual-tabular learning.
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce two modality-specific diagnostic metrics, Modality Contribution Ratio (MCR) and Modality Informativeness Ratio (MIR)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Multimodal Machine Learning: A Survey and Taxonomy , journal =
Baltru. Multimodal Machine Learning: A Survey and Taxonomy , journal =. 2018 , volume =
work page 2018
-
[2]
Proceedings of the 32nd International Conference on Machine Learning (ICML 2015) , address =
Xu, Kelvin and Ba, Jimmy and Kiros, Ryan and Cho, Kyunghyun and Courville, Aaron and Salakhudinov, Ruslan and Zemel, Rich and Bengio, Yoshua , title =. Proceedings of the 32nd International Conference on Machine Learning (ICML 2015) , address =. 2015 , pages =
work page 2015
-
[3]
Proceedings of the 15th IEEE International Conference on Computer Vision (ICCV 2015) , address =
Antol, Stanislaw and Agrawal, Aishwarya and Lu, Jiasen and Mitchell, Margaret and Batra, Dhruv and Zitnick, C Lawrence and Parikh, Devi , title =. Proceedings of the 15th IEEE International Conference on Computer Vision (ICCV 2015) , address =. 2015 , pages =
work page 2015
-
[4]
Vinyals, Oriol and Toshev, Alexander and Bengio, Samy and Erhan, Dumitru , title =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2015) , address =. 2015 , pages =
work page 2015
-
[5]
Yue, Xiang and Ni, Yuansheng and Zhang, Kai and Zheng, Tianyu and Liu, Ruoqi and Zhang, Ge and Stevens, Samuel and Jiang, Dongfu and Ren, Weiming and Sun, Yuxuan and others , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2024) , address =. 2024 , pages =
work page 2024
-
[6]
Proceedings of the 18th European Conference on Computer Vision (ECCV 2024) , address =
Liu, Yuan and Duan, Haodong and Zhang, Yuanhan and Li, Bo and Zhang, Songyang and Zhao, Wangbo and Yuan, Yike and Wang, Jiaqi and He, Conghui and Liu, Ziwei and others , title =. Proceedings of the 18th European Conference on Computer Vision (ECCV 2024) , address =. 2024 , pages =
work page 2024
-
[7]
Proceedings of the 38th International Conference on Machine Learning (ICML 2021) , address =
Radford, Alec and Kim, Jong Wook and Hallacy, Chris and Ramesh, Aditya and Goh, Gabriel and Agarwal, Sandhini and Sastry, Girish and Askell, Amanda and Mishkin, Pamela and Clark, Jack and others , title =. Proceedings of the 38th International Conference on Machine Learning (ICML 2021) , address =. 2021 , pages =
work page 2021
-
[8]
Proceedings of the 40th International Conference on Machine Learning (ICML 2023) , address =
Li, Junnan and Li, Dongxu and Savarese, Silvio and Hoi, Steven , title =. Proceedings of the 40th International Conference on Machine Learning (ICML 2023) , address =. 2023 , pages =
work page 2023
-
[9]
Advances in Neural Information Processing Systems , year =
Liu, Haotian and Li, Chunyuan and Wu, Qingyang and Lee, Yong Jae , title =. Advances in Neural Information Processing Systems , year =
-
[10]
Proceedings of the 39th International Conference on Machine Learning (ICML 2022) , address =
Li, Junnan and Li, Dongxu and Xiong, Caiming and Hoi, Steven , title =. Proceedings of the 39th International Conference on Machine Learning (ICML 2022) , address =. 2022 , pages =
work page 2022
-
[11]
Advances in Neural Information Processing Systems , year =
Lu, Jiasen and Batra, Dhruv and Parikh, Devi and Lee, Stefan , title =. Advances in Neural Information Processing Systems , year =
- [12]
-
[13]
Yang, Jiaxi and Chen, Kui and Ding, Kai and Na, Chongning and Wang, Meng , title =. Data Intelligence , year =
-
[14]
Huang, Shih-Cheng and Pareek, Anuj and Seyyedi, Saeed and Banerjee, Imon and Lungren, Matthew P , title =. NPJ Digital Medicine , year =
-
[15]
Proceedings of the 10th IEEE International Conference on Big Data (Big Data 2022) , address =
Huang, Jingmin and Chen, Bowei and Luo, Lan and Yue, Shigang and Ounis, Iadh , title =. Proceedings of the 10th IEEE International Conference on Big Data (Big Data 2022) , address =. 2022 , pages =
work page 2022
-
[16]
Cui, Can and Yang, Haichun and Wang, Yaohong and Zhao, Shilin and Asad, Zuhayr and Coburn, Lori A. and Wilson, Keith T. and Landman, Bennett A. and Huo, Yuankai , title =. Progress in Biomedical Engineering , year =
-
[17]
Medical Image Analysis , year =
Duenias, Daniel and Nichyporuk, Brennan and Arbel, Tal and Raviv, Tammy Riklin and others , title =. Medical Image Analysis , year =
-
[18]
Proceedings of the 18th IEEE/CVF International Conference on Computer Vision (ICCV 2021) , address =
Holste, Gregory and Partridge, Savannah C and Rahbar, Habib and Biswas, Debosmita and Lee, Christoph I and Alessio, Adam M , title =. Proceedings of the 18th IEEE/CVF International Conference on Computer Vision (ICCV 2021) , address =. 2021 , pages =
work page 2021
-
[19]
Long-term Cancer Survival Prediction Using Multimodal Deep Learning , journal =
Vale-Silva, Lu. Long-term Cancer Survival Prediction Using Multimodal Deep Learning , journal =. 2021 , volume =
work page 2021
-
[20]
Zheng, Hanci and Lin, Zongying and Zhou, Qizheng and Peng, Xingchen and Xiao, Jianghong and Zu, Chen and Jiao, Zhengyang and Wang, Yan , title =. Proceedings of the 25th International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI 2022) , address =. 2022 , pages =
work page 2022
- [21]
-
[22]
Jiang, Jun-Peng and Ye, Han-Jia and Wang, Leye and Yang, Yang and Jiang, Yuan and Zhan, De-Chuan , title =. 2024 , booktitle =
work page 2024
-
[23]
Hager, Paul and Menten, Martin J and Rueckert, Daniel , title =. Proceedings of the 36th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2023) , address =. 2023 , pages =
work page 2023
-
[24]
Proceedings of the 18th European Conference on Computer Vision (ECCV 2024) , address =
Du, Siyi and Zheng, Shaoming and Wang, Yinsong and Bai, Wenjia and O’Regan, Declan P and Qin, Chen , title =. Proceedings of the 18th European Conference on Computer Vision (ECCV 2024) , address =. 2024 , pages =
work page 2024
-
[25]
Luo, Haohao and Shen, Ying and Deng, Yang , title =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP 2023) , address =. 2023 , pages =
work page 2023
-
[26]
Advances in Neural Information Processing Systems , year =
Bae, Seongsu and Kyung, Daeun and Ryu, Jaehee and Cho, Eunbyeol and Lee, Gyubok and Kweon, Sunjun and Oh, Jungwoo and Ji, Lei and Chang, Eric and Kim, Tackeun and others , title =. Advances in Neural Information Processing Systems , year =
-
[27]
Talmor, Alon and Yoran, Ori and Catav, Amnon and Lahav, Dan and Wang, Yizhong and Asai, Akari and Ilharco, Gabriel and Hajishirzi, Hannaneh and Berant, Jonathan , title =. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL 2021) , address =. 2021 , pages =
work page 2021
-
[28]
Duanmu, Hongyi and Huang, Pauline Boning and Brahmavar, Srinidhi and Lin, Stephanie and Ren, Thomas and Kong, Jun and Wang, Fusheng and Duong, Tim Q , title =. Proceedings of the 23rd International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI 2020) , address =. 2020 , pages =
work page 2020
-
[29]
He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian , title =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2016) , address =. 2016 , pages =
work page 2016
-
[30]
Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil , title =. 2021 , booktitle =
work page 2021
-
[31]
Proceedings of the 34th International Conference on Machine Learning (ICML 2017) , address =
Sundararajan, Mukund and Taly, Ankur and Yan, Qiqi , title =. Proceedings of the 34th International Conference on Machine Learning (ICML 2017) , address =. 2017 , pages =
work page 2017
-
[32]
and Zhu, Yuke and others , title =
Liang, Paul Pu and Lyu, Yiwei and Fan, Xiang and Wu, Zetian and Cheng, Yun and Wu, Jason and Chen, Leslie and Wu, Peter and Lee, Michelle A. and Zhu, Yuke and others , title =. Advances in Neural Information Processing Systems , year =
-
[33]
arXiv preprint arXiv:2412.16243 , year =
Tang, Zhiqiang and Zhong, Zihan and He, Tong and Friedland, Gerald , title =. arXiv preprint arXiv:2412.16243 , year =
-
[34]
Johnson, Alistair E. W. and Bulgarelli, Lucas and Shen, Lu and Gayles, Alvin and Shammout, Ayad and Horng, Steven and Pollard, Tom J. and Hao, Sicheng and Moody, Benjamin and Gow, Brian and others , title =. Scientific Data , year =
-
[35]
Johnson, Alistair E. W. and Pollard, Tom J. and Berkowitz, Seth J. and Greenbaum, Nathaniel R. and Lungren, Matthew P. and Deng, Chih-ying and Mark, Roger G. and Horng, Steven , title =. Scientific Data , year =
-
[36]
Spasov, Simeon and Passamonti, Luca and Duggento, Andrea and Lio, Pietro and Toschi, Nicola and others , title =. NeuroImage , year =
-
[37]
Advances in Neural Information Processing Systems , year =
Ke, Guolin and Meng, Qi and Finley, Thomas and Wang, Taifeng and Chen, Wei and Ma, Weidong and Ye, Qiwei and Liu, Tie-Yan , title =. Advances in Neural Information Processing Systems , year =
-
[38]
TabTransformer: Tabular Data Modeling Using Contextual Embeddings
Huang, Xin and Khetan, Ashish and Cvitkovic, Milan and Karnin, Zohar , title =. arXiv preprint arXiv:2012.06678 , year =
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[39]
Accurate Predictions on Small Data with a Tabular Foundation Model , journal =
Hollmann, Noah and M. Accurate Predictions on Small Data with a Tabular Foundation Model , journal =. 2025 , volume =
work page 2025
-
[40]
Yang, An and Li, Anfeng and Yang, Baosong and Zhang, Beichen and Hui, Binyuan and Zheng, Bo and Yu, Bowen and Gao, Chang and others , title =. arXiv preprint arXiv:2505.09388 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
Zheng, Mingyu and Feng, Xinwei and Si, Qingyi and She, Qiaoqiao and Lin, Zheng and Jiang, Wenbin and Wang, Weiping , title =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , year =
-
[42]
The Carbon Footprint of Machine Learning Training Will Plateau, Then Shrink , journal =
Patterson, David and Gonzalez, Joseph and H. The Carbon Footprint of Machine Learning Training Will Plateau, Then Shrink , journal =. 2022 , volume =
work page 2022
-
[43]
Hong, Wenyi and Yu, Wenmeng and Gu, Xiaotao and Wang, Guo and Gan, Guobing and Tang, Haomiao and Cheng, Jiale and others , title =. arXiv preprint arXiv:2507.01006 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Zhu, Jinguo and Wang, Weiyun and Chen, Zhe and Liu, Zhaoyang and Ye, Shenglong and Gu, Lixin and others , title =. arXiv preprint arXiv:2504.10479 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
Informatics in Medicine Unlocked , year =
Mienye, Ibomoiye Domor and Obaido, George and Jere, Nobert and Mienye, Ebikella and Aruleba, Kehinde and Emmanuel, Ikiomoye Douglas and Ogbuokiri, Blessing , title =. Informatics in Medicine Unlocked , year =
-
[47]
Zhu, Fengbin and Lei, Wenqiang and Huang, Youcheng and Wang, Chao and Zhang, Shuo and Lv, Jiancheng and Feng, Fuli and Chua, Tat-Seng , title =. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , year =
-
[48]
Proceedings of the 30th ACM International Conference on Multimedia (MM 2022) , address =
Zhu, Fengbin and Lei, Wenqiang and Feng, Fuli and Wang, Chao and Zhang, Haozhou and Chua, Tat-Seng , title =. Proceedings of the 30th ACM International Conference on Multimedia (MM 2022) , address =. 2022 , pages =
work page 2022
-
[49]
Kim, Yoonsik and Yim, Moonbin and Song, Ka Yeon , journal=
-
[50]
Singh, Anshul and Biemann, Chris and Strich, Jan , journal=
-
[51]
Findings of the Association for Computational Linguistics: EMNLP 2024 , year =
Mathur, Suyash Vardhan and Bafna, Jainit Sushil and Kartik, Kunal and Khandelwal, Harshita and Shrivastava, Manish and Gupta, Vivek and Bansal, Mohit and Roth, Dan , title =. Findings of the Association for Computational Linguistics: EMNLP 2024 , year =
work page 2024
-
[52]
Radfusion: Benchmarking performance and fairness for multimodal pulmonary embolism detection from
Zhou, Yuyin and Huang, Shih-Cheng and Fries, Jason Alan and Youssef, Alaa and Amrhein, Timothy J and Chang, Marcello and Banerjee, Imon and Rubin, Daniel and Xing, Lei and Shah, Nigam and others , journal=. Radfusion: Benchmarking performance and fairness for multimodal pulmonary embolism detection from
-
[53]
Bycroft, Clare and Freeman, Colin and Petkova, Desislava and Band, Gavin and Elliott, Lloyd T and Sharp, Kevin and Motyer, Allan and Vukcevic, Damjan and Delaneau, Olivier and O’Connell, Jared and others , journal=. The. 2018 , publisher=
work page 2018
-
[54]
S. Bai and Y. Cai and R. Chen and K. Chen and others , title =. arXiv preprint arXiv:2511.21631 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[55]
Abhimanyu Dubey and Akhil Jauhri and Abhinav Pandey and Abhishek Kadian and Alon Altermatt and others , year =. The. 2407.21783 , archiveprefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[56]
P. Agrawal and others , title =. arXiv preprint arXiv:2410.07073 , year =
work page internal anchor Pith review Pith/arXiv arXiv
- [57]
-
[58]
2025 , howpublished =
work page 2025
-
[59]
arXiv preprint arXiv:2505.21771 , year =
Prasham Yatinkumar Titiya and Jainil Trivedi and Chitta Baral and Vivek Gupta , title =. arXiv preprint arXiv:2505.21771 , year =
-
[60]
Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
Jiang, Jinhao and Zhou, Kun and Dong, Zican and Ye, Keming and Zhao, Xin and Wen, Ji-Rong , title=. Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
work page 2023
-
[61]
Thyme: Think beyond images , author=. arXiv preprint arXiv:2508.11630 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[62]
International Conference on Machine Learning , pages=
Compositional Condition Question Answering in Tabular Understanding , author=. International Conference on Machine Learning , pages=
-
[63]
Advances in Neural Information Processing Systems , pages=
Multimodal tabular reasoning with privileged structured information , author=. Advances in Neural Information Processing Systems , pages=
-
[64]
Ji, An-Yang and Jiang, Jun-Peng and Zhan, De-Chuan and Ye, Han-Jia , journal=
-
[65]
Ma, Haoxuan and Lai, Guannan and Ye, Han-Jia , journal=
- [66]
-
[67]
Learngene: Inheriting Condensed Knowledge from the Ancestry Model to Descendant Models , author=. ArXiv , year=
-
[68]
arXiv preprint arXiv:2603.21928 , year=
The Golden Subspace: Where Efficiency Meets Generalization in Continual Test-Time Adaptation , author=. arXiv preprint arXiv:2603.21928 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.