Semantic Allocation in Ordered Bottlenecks: Predictive Residual Inference for Visual Representation Learning
Pith reviewed 2026-06-25 23:25 UTC · model grok-4.3
The pith
Predictive residual inference orders visual representations so early tokens hold coarse information and later tokens add refinements.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
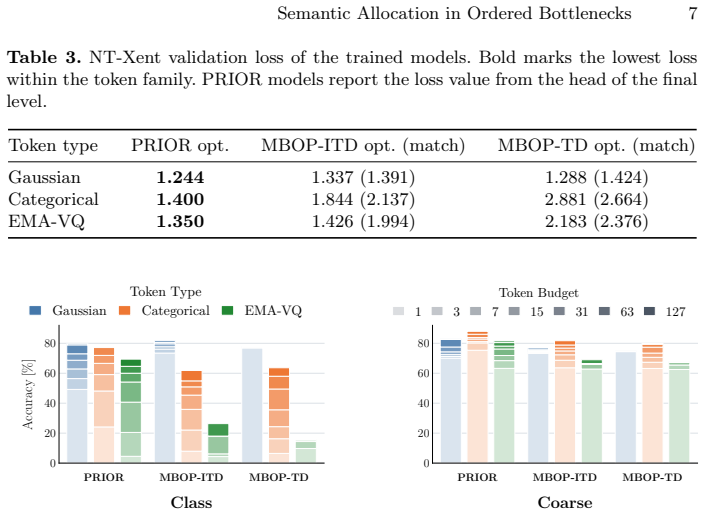
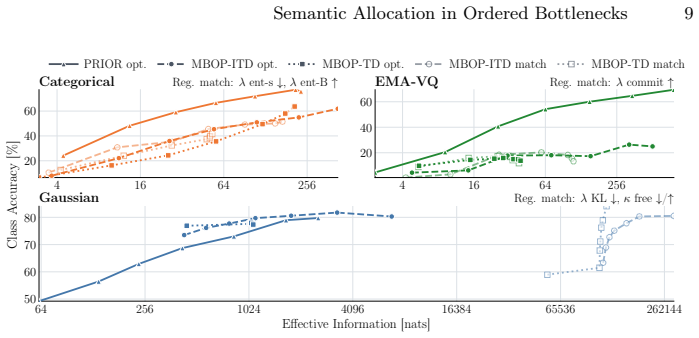
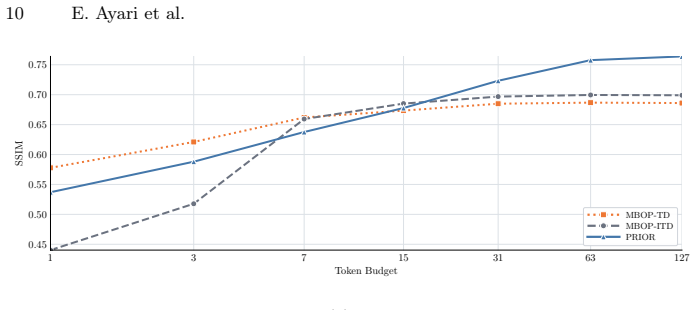
PRIOR replaces activation-rate control with log2-scaled levels and level-wise predictors. These predictors separate already explained from unexplained information, focusing each level on residual error. Unlike masking-based ordering pressure, this approach yields well-ordered representations: low budgets provide coarse descriptors while high budgets add refinements. Full-budget performance is higher in all but one setting and comparable in the remaining case. Masking baselines remain severely limited in discrete and quantized regimes, whereas PRIOR approaches the performance of continuous counterparts.
What carries the argument
Level-wise predictors on residual error at log2-scaled levels, each trained to explain only the information left unexplained by prior levels.
If this is right
- Low budgets yield coarse but still useful descriptors while higher budgets add measurable refinements.
- Full-budget accuracy equals or exceeds masking baselines in contrastive and reconstruction tasks.
- Representations remain effective when tokens must be discrete or quantized, unlike masking approaches.
- Ordering emerges without explicit masking, avoiding weak late-token utility.
Where Pith is reading between the lines
- The residual structure could reduce feature redundancy across levels, making the representation more compressible at inference time.
- Budget selection might be made dynamic per sample by monitoring residual magnitude after each level.
- The same residual-predictor pattern may transfer to sequence models where token order must reflect semantic priority.
- Extending the number of levels beyond the tested log2 schedule could reveal whether ordering holds at very fine granularity.
Load-bearing premise
Training each level on the residual error from previous levels will reliably produce ordered utility without creating new optimization failures in the contrastive or reconstruction objectives.
What would settle it
Measure task performance at successive token budgets in a discrete setting; if performance does not increase monotonically with added levels or if it falls below the continuous baseline at full budget, the ordering and refinement claims would be contradicted.
Figures


read the original abstract
Ordered bottlenecks aim to provide utility at flexible budgets by assigning coarse information to early tokens and task-relevant detail to later ones. Prior work, including tail dropping (TD), typically enforces ordering by means of a masking-based ordering pressure (MBOP): Late tokens are masked more frequently than early tokens and are therefore encouraged to store less essential fine details. We introduce predictive residual inference for ordered representations (PRIOR), a framework designed to address inherent weaknesses of MBOP. MBOP is prone to weak late-token utility because it lacks an explicit refinement objective and uses gradient exposure as a proxy for importance. Furthermore, representations may become particularly brittle in optimization-sensitive settings, such as when using discrete or quantized token representations. PRIOR replaces activation-rate control with log2-scaled levels and level-wise predictors. These predictors separate already explained from unexplained information, focusing each level on residual error. We compare PRIOR against MBOP-TD and independent tail-biased dropout (MBOP-ITD) in contrastive learning and image reconstruction tasks. Unlike the baselines, PRIOR learns well-ordered representations across experiments: low budgets provide coarse descriptors, while high budgets add refinements. Simultaneously, full-budget performance with PRIOR is higher in all but one experimental setting, where performance remains comparable. MBOP baselines are severely limited in discrete and quantized settings, while PRIOR approaches the performance of continuous counterparts. Taken together, these findings establish PRIOR as an effective framework for ordered representation learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Predictive Residual Inference for Ordered Representations (PRIOR) to address limitations of masking-based ordering pressure (MBOP) in ordered bottlenecks. PRIOR employs log2-scaled levels with level-wise residual predictors that separate explained from unexplained information, aiming to produce representations where low budgets yield coarse descriptors and higher budgets add refinements. Experiments in contrastive learning and image reconstruction tasks are reported to show that PRIOR achieves well-ordered representations, higher or comparable full-budget performance versus MBOP-TD and MBOP-ITD baselines, and greater robustness in discrete and quantized regimes.
Significance. If the empirical outcomes hold under full experimental scrutiny, the work supplies an explicit residual objective that directly targets refinement rather than relying on gradient-exposure proxies, offering a more stable approach to ordered visual representations. This is particularly relevant for settings with discrete or quantized tokens where MBOP baselines degrade. The design choice of level-wise predictors is a concrete methodological contribution that could support flexible-budget inference in vision models.
minor comments (2)
- [Abstract] Abstract: the statement that full-budget performance is 'higher in all but one experimental setting' lacks identification of the tasks, datasets, or the specific setting where performance is only comparable, which reduces the precision of the central empirical claim.
- [Abstract] Abstract: no quantitative metrics, dataset names, or model architectures are referenced, making it harder to evaluate the scale of the reported improvements over baselines.
Simulated Author's Rebuttal
We thank the referee for their positive summary of the manuscript, the assessment of its significance, and the recommendation for minor revision. The report does not contain any specific major comments requiring point-by-point rebuttal.
Circularity Check
No significant circularity detected
full rationale
The paper introduces PRIOR as a new framework using log2-scaled levels and level-wise residual predictors to replace MBOP's masking-based ordering pressure. No load-bearing step reduces by construction to fitted inputs, self-citations, or renamed known results; the central claims rest on experimental comparisons between PRIOR and baselines in contrastive and reconstruction tasks, with ordering enforced via explicit residual objectives rather than definitional equivalence. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: International Conference on Learning Representations (2017), https://arxiv.org/abs/1612.00410
Alemi, A.A., Fischer, I., Dillon, J.V., Murphy, K.: Deep variational informa- tion bottleneck. In: International Conference on Learning Representations (2017), https://arxiv.org/abs/1612.00410
Pith/arXiv arXiv 2017
-
[2]
The training process of many deep networks explores the same low-dimensional manifold
Bar, M., Kassam, K.S., Ghuman, A.S., Boshyan, J., Schmid, A.M., Dale, A.M., et al.: Top-down facilitation of visual recognition. Proceedings of the National Academy of Sciences103(2), 449–454 (2006).https://doi.org/10.1073/pnas. 0507062103
-
[3]
In: Proceedings of the 37th Interna- tional Conference on Machine Learning
Chen, T., Kornblith, S., Norouzi, M., Hinton, G.: A simple framework for con- trastive learning of visual representations. In: Proceedings of the 37th Interna- tional Conference on Machine Learning. Proceedings of Machine Learning Re- search, vol. 119, pp. 1597–1607. PMLR (2020)
2020
-
[4]
Neuron36(5), 791–804 (2002).https://doi.org/10.1016/ S0896-6273(02)01091-7
Hochstein, S., Ahissar, M.: View from the top: Hierarchies and reverse hierarchies in the visual system. Neuron36(5), 791–804 (2002).https://doi.org/10.1016/ S0896-6273(02)01091-7
2002
-
[5]
Jones, Matthias Schonlau, and William J
Jones, D.R., Schonlau, M., Welch, W.J.: Efficient global optimization of expensive black-box functions. Journal of Global Optimization13(4), 455–492 (1998).https: //doi.org/10.1023/A:1008306431147
-
[6]
Karras, T., Laine, S., Aila, T.: A style-based generator architecture for generative adversarial networks (2019),https://arxiv.org/abs/1812.04948
Pith/arXiv arXiv 2019
-
[7]
Kingma, D.P., Salimans, T., Jozefowicz, R., Chen, X., Sutskever, I., Welling, M.: Improving variational inference with inverse autoregressive flow (2017),https: //arxiv.org/abs/1606.04934
Pith/arXiv arXiv 2017
-
[8]
In: 2020 IEEE International Symposium on Infor- mation Theory (ISIT)
Koike-Akino, T., Wang, Y.: Stochastic bottleneck: Rateless auto-encoder for flex- ible dimensionality reduction. In: 2020 IEEE International Symposium on Infor- mation Theory (ISIT). pp. 2735–2740. IEEE (2020).https://doi.org/10.1109/ ISIT44484.2020.9174302
arXiv 2020
-
[9]
arXiv preprint arXiv:2501.10064 (2025)
Miwa, K., Sasaki, K., Arai, H., Takahashi, T., Yamaguchi, Y.: One-d-piece: Image tokenizer meets quality-controllable compression. arXiv preprint arXiv:2501.10064 (2025)
arXiv 2025
-
[10]
Cognitive Psychology9(3), 353–383 (1977).https://doi.org/10.1016/ 0010-0285(77)90012-3
Navon, D.: Forest before trees: The precedence of global features in visual per- ception. Cognitive Psychology9(3), 353–383 (1977).https://doi.org/10.1016/ 0010-0285(77)90012-3
1977
-
[11]
Rao, R.P.N., Ballard, D.H.: Predictive coding in the visual cortex: A functional interpretation of some extra-classical receptive-field effects. Nature Neuroscience 2(1), 79–87 (1999).https://doi.org/10.1038/4580
-
[12]
MIT Press (2006)
Rasmussen, C.E., Williams, C.K.I.: Gaussian Processes for Machine Learning. MIT Press (2006)
2006
-
[13]
Proceedings of Machine Learning Research, vol
Rippel, O., Gelbart, M., Adams, R.: Learning ordered representations with nested dropout.In:Proceedingsofthe31stInternationalConferenceonMachineLearning. Proceedings of Machine Learning Research, vol. 32, pp. 1746–1754. PMLR (2014)
2014
-
[14]
In: Lee, D., Sugiyama, M., Luxburg, U., Guyon, I., Garnett, R
Sohn, K.: Improved deep metric learning with multi-class n-pair loss objective. In: Lee, D., Sugiyama, M., Luxburg, U., Guyon, I., Garnett, R. (eds.) Advances in Neural Information Processing Systems. vol. 29. Curran Associates, Inc. (2016)
2016
-
[15]
Traub, M., Butz, M.V.: Looking locally: Object-centric vision transformers as foun- dation models for efficient segmentation (2025),https://arxiv.org/abs/2502. 02763
2025
-
[16]
Yu, X., Xu, M., Zhang, Y., Liu, H., Ye, C., Wu, Y., et al.: Mvimgnet: A large-scale dataset of multi-view images (2023)
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.