UniTemp: Unlocking Video Generation in Any Temporal Order via Bidirectional Distillation
Pith reviewed 2026-06-26 21:30 UTC · model grok-4.3
The pith
One autoregressive video model generates in any temporal direction via bidirectional distillation and anchor latents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
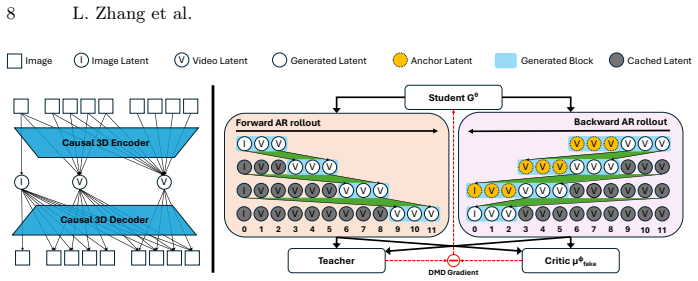
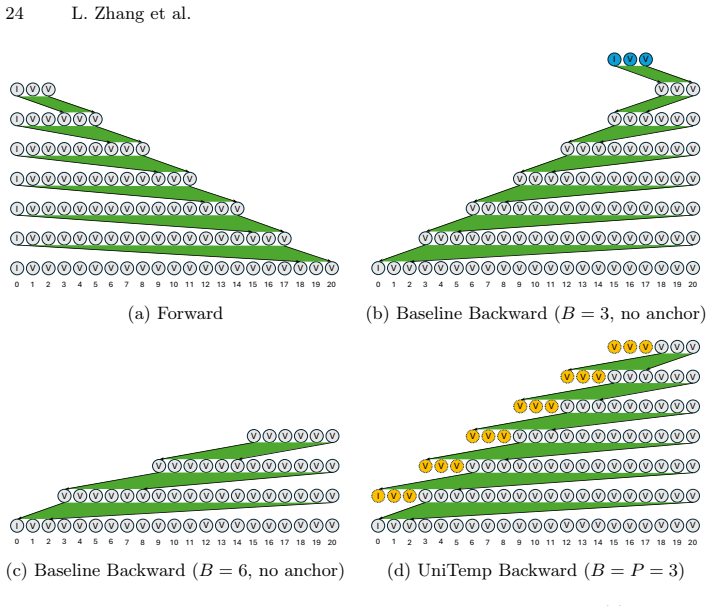
UniTemp trains one autoregressive student model that conditions on arbitrary past and future frames by using blockwise anchor latents to restore the context the causal 3D VAE withholds during backward passes, thereby supporting bidirectional extension, inbetween generation, and other flexible workflows at inference time while preserving competitive quality on standard video benchmarks.
What carries the argument
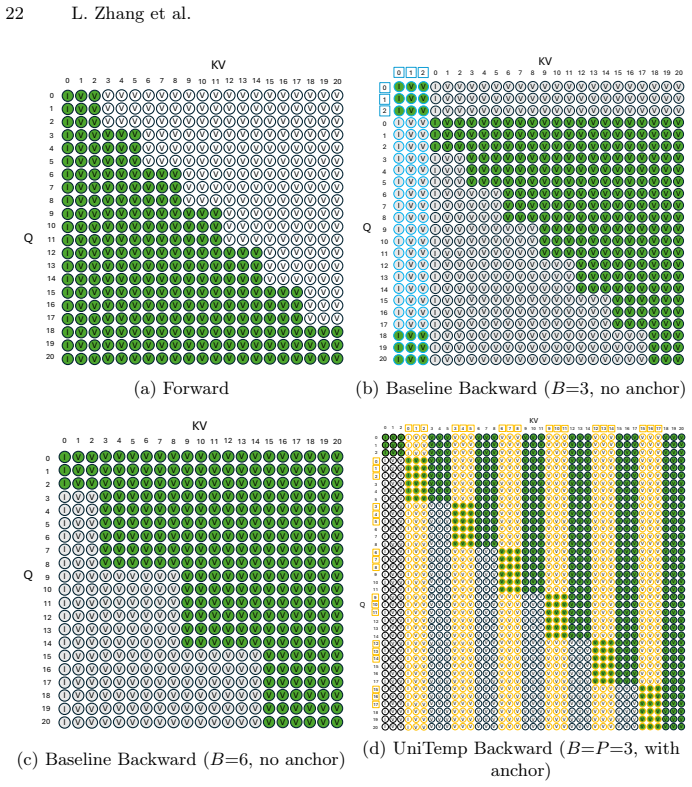
blockwise anchor latents that restore missing past context at block boundaries during backward generation, inside a bidirectional distillation framework that trains the single autoregressive model.
If this is right
- The model conditions on future frames alone to extend video backward.
- It fills frames between given past and future clips for inbetween generation.
- It produces looping videos and handles scene transitions by mixing conditioning directions.
- It supports visual story generation by sequencing clips in non-forward orders.
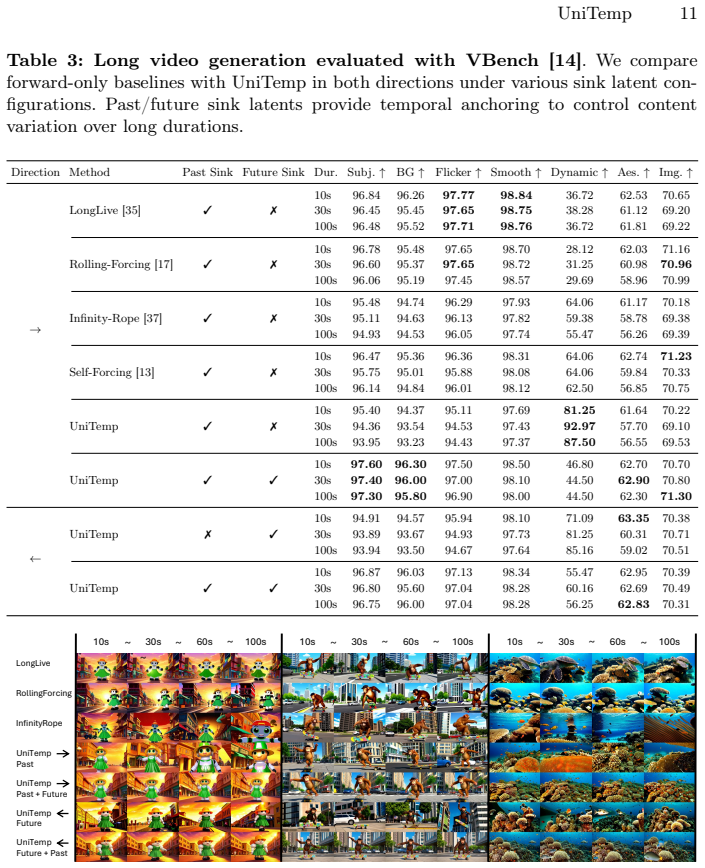
- Performance on short and long forward video tasks stays comparable to forward-only baselines.
Where Pith is reading between the lines
- The same anchor-latent fix could be tested on other causal encoders used in audio or text sequence models.
- A single trained checkpoint might replace multiple direction-specific models in video editing tools.
- Interactive applications could change generation direction mid-clip without reloading weights.
Load-bearing premise
The causal 3D VAE produces inter-block discontinuities in backward generation that can be fixed by auxiliary anchor latents without hurting forward performance.
What would settle it
Run backward generation on the same model and sequences with the anchor latents removed and measure whether visible discontinuities or motion breaks appear at block boundaries.
Figures



read the original abstract
Autoregressive video diffusion models have emerged as a promising approach for long video generation, achieving strong performance in streaming settings. However, existing methods are restricted to forward temporal generation, whereas practical video creation often requires flexible generation order, e.g., conditioning on future context to extend backward, or on both past and future context for inbetween generation. We bridge this gap by training an autoregressive model that supports generation in arbitrary temporal directions. A key technical challenge arises from the Causal 3D VAE widely used in video diffusion models, which encodes latents strictly conditioned on past context. While suited for forward generation, this causal structure causes inter-block discontinuities when generation proceeds backward. To address this, we introduce blockwise anchor latents, a set of auxiliary latents that restore the missing past context at block boundaries during backward generation. Built on this design, we propose UniTemp, a bidirectional distillation framework that trains a single autoregressive student model for any-direction video generation. At inference time, UniTemp conditions on arbitrary past and/or future frames, improving controllability for both bidirectional and inbetween generation. Experiments show that UniTemp maintains competitive performance on short and long video generation compared to forward-only methods, while enabling diverse workflows such as bidirectional video extension, inbetween generation, looping video generation, scene transition, and visual story generation. Project website: https://lzhangbj.github.io/projects/unitemp/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce UniTemp, a bidirectional distillation framework that trains a single autoregressive video diffusion model capable of generation in arbitrary temporal orders. It identifies the causal conditioning of the standard 3D VAE as the source of inter-block discontinuities in backward generation and proposes blockwise anchor latents to restore missing past context at boundaries. The resulting model is said to support bidirectional extension, inbetween generation, looping, scene transitions, and visual story generation while maintaining competitive performance on short and long video tasks relative to forward-only baselines.
Significance. If the central technical claim holds, the work would meaningfully expand the practical utility of autoregressive video models by removing the forward-only restriction, enabling new controllable workflows without requiring separate models per direction. The distillation approach for multi-directional capability and the anchor-latent mechanism for causal VAE compatibility are the primary potential contributions.
major comments (1)
- [Abstract] Abstract / Method description: the assertion that blockwise anchor latents 'restore the missing past context at block boundaries during backward generation' without side effects is load-bearing for all bidirectional and inbetween claims, yet the provided text supplies neither a quantitative discontinuity metric (e.g., boundary artifact scores before/after anchors) nor an ablation isolating the anchors' contribution. If the anchors only approximate rather than recover exact causal conditioning, the reported performance on looping and inbetween tasks would be undermined.
minor comments (1)
- [Abstract] Abstract: no error bars, dataset details, or specific quantitative results (FID, FVD, etc.) are reported to support the 'competitive performance' statement, making direct comparison to forward-only methods difficult to evaluate from the given text.
Simulated Author's Rebuttal
We thank the referee for the constructive comment highlighting the need for stronger empirical support of the blockwise anchor latents. We address the point directly below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract / Method description: the assertion that blockwise anchor latents 'restore the missing past context at block boundaries during backward generation' without side effects is load-bearing for all bidirectional and inbetween claims, yet the provided text supplies neither a quantitative discontinuity metric (e.g., boundary artifact scores before/after anchors) nor an ablation isolating the anchors' contribution. If the anchors only approximate rather than recover exact causal conditioning, the reported performance on looping and inbetween tasks would be undermined.
Authors: We agree that the current manuscript does not include a dedicated quantitative discontinuity metric or an ablation isolating the anchors. The presented evidence consists of overall task metrics (FVD, CLIP similarity) on bidirectional and inbetween generation plus qualitative examples. In the revised version we will add (1) a boundary artifact score defined as the average L2 distance in VAE latent space (and optionally LPIPS in pixel space) across block boundaries for backward generation with vs. without anchors, and (2) an ablation table reporting performance on looping and inbetween tasks when the anchor mechanism is removed. These additions will directly test whether the anchors recover sufficient causal context or merely approximate it. revision: yes
Circularity Check
No circularity; derivation self-contained with no reductions to inputs
full rationale
The abstract and description introduce blockwise anchor latents and bidirectional distillation as new technical components to address causal VAE discontinuities, but contain no equations, no fitted parameters renamed as predictions, and no self-citations invoked as load-bearing uniqueness theorems. Claims of arbitrary-order generation rest on the introduced design rather than tautological redefinitions or self-referential fits. This is the normal case of an externally verifiable engineering contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Causal 3D VAE encodes latents strictly conditioned on past context
invented entities (1)
-
blockwise anchor latents
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the International Conference on Learning Representations (ICLR) (2024)
Blattmann, A., Dockhorn, T., Kulal, S., Mendelevitch, D., Kilian, M., Lorber, D., Levi, Y., English, Z., Voleti, V., Letts, A., Jampani, V., Rombach, R.: Stable video diffusion: Scaling latent video diffusion models to large datasets. In: Proceedings of the International Conference on Learning Representations (ICLR) (2024)
2024
-
[2]
arXiv preprint arXiv:2311.15127 (2023)
Blattmann, A., Dockhorn, T., Kulal, S., Mendelevitch, D., Kilian, M., Lorenz, D., Levi, Y., English, Z., Voleti, V., Letts, A., Jampani, V., Rombach, R.: Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv preprint arXiv:2311.15127 (2023)
Pith/arXiv arXiv 2023
-
[3]
OpenAI Technical Report (2024)
Brooks, T., Peebles, B., Holmes, C., DePue, W., Guo, Y., Jing, L., Schnurr, D., Taylor, J., Luhman, T., Luhman, E., Ng, C., Wang, R., Ramesh, A.: Video gener- ation models as world simulators. OpenAI Technical Report (2024)
2024
-
[4]
Chen, J., Fu, Z., He, X.: Infinite-forcing: Towards infinite-long video generation (2025),https://github.com/SOTAMak1r/Infinite-Forcing
2025
-
[5]
arXiv preprint arXiv:2510.02283 (2025)
Cui, J., Wu, J., Li, M., Yang, T., Li, X., Wang, R., Bai, A., Ban, Y., Hsieh, C.J.: Self-forcing++: Towards minute-scale high-quality video generation. arXiv preprint arXiv:2510.02283 (2025)
Pith/arXiv arXiv 2025
-
[6]
In: AAAI (2024)
Danier, D., Zhang, F., Bull, D.: Ldmvfi: Video frame interpolation with latent diffusion models. In: AAAI (2024)
2024
-
[7]
arXiv preprint arXiv:2403.14611 (2024)
Feng, H., Ding, Z., Xia, Z., Niklaus, S., Abrevaya, V., Black, M.J., Zhang, X.: Ex- plorative inbetweening of time and space. arXiv preprint arXiv:2403.14611 (2024)
arXiv 2024
-
[8]
In: Proceedings of the International Conference on Learning Representations (ICLR) (2024)
Geyer, M., Bar-Tal, O., Bagon, S., Dekel, T.: Tokenflow: Consistent diffusion fea- tures for consistent video editing. In: Proceedings of the International Conference on Learning Representations (ICLR) (2024)
2024
-
[9]
In: Advances in Neural Information Processing Systems (NeurIPS) (2014)
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., Bengio, Y.: Generative adversarial nets. In: Advances in Neural Information Processing Systems (NeurIPS) (2014)
2014
-
[10]
In: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR) (2025)
Henschel, R., Khachatryan, L., Poghosyan, H., Hayrapetyan, D., Tadevosyan, V., Wang, Z., Navasardyan, S., Shi, H.: Streamingt2v: Consistent, dynamic, and ex- tendable long video generation from text. In: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR) (2025)
2025
-
[11]
In: Advances in Neural Information Processing Systems (NeurIPS) (2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. In: Advances in Neural Information Processing Systems (NeurIPS) (2020)
2020
-
[12]
In: Transactions on Machine Learning Research (TMLR) (2022)
Höppe, T., Mehrjou, A., Bauer, S., Nielsen, D., Dittadi, A.: Diffusion models for video prediction and infilling. In: Transactions on Machine Learning Research (TMLR) (2022)
2022
-
[13]
arXiv preprint arXiv:2506.08009 (2025)
Huang, X., Li, Z., He, G., Zhou, M., Shechtman, E.: Self-forcing: Bridging the train-test gap in autoregressive video diffusion. arXiv preprint arXiv:2506.08009 (2025)
Pith/arXiv arXiv 2025
-
[14]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2024)
Huang, Z., He, Y., Yu, J., Zhang, F., Si, C., Jiang, Y., Zhang, Y., Wu, T., Jin, Q., Chanpaisit, N., et al.: Vbench: Comprehensive benchmark suite for video gener- ative models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2024)
2024
-
[15]
In: Pro- ceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (2025)
Jiang, Z., Han, Z., et al.: Vace: All-in-one video creation and editing. In: Pro- ceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (2025)
2025
-
[16]
arXiv preprint arXiv:2412.03603 (2024) 16 L
Kong, W., Tian, Q., Zhang, Z., Min, R., et al.: Hunyuanvideo: A systematic frame- work for large video generative models. arXiv preprint arXiv:2412.03603 (2024) 16 L. Zhang et al
Pith/arXiv arXiv 2024
-
[17]
arXiv preprint arXiv:2509.25161 (2025)
Liu, K., Hu, W., Xu, J., Shan, Y., Lu, S.: Rolling forcing: Autoregressive long video diffusion in real time. arXiv preprint arXiv:2509.25161 (2025)
Pith/arXiv arXiv 2025
-
[18]
arXiv preprint arXiv:2512.04678 (2025)
Lu, Y., Zeng, Y., Li, H., Ouyang, H., Wang, Q., Cheng, K.L., Zhu, J., Cao, H., Zhang, Z., Zhu, X., Shen, Y., Zhang, M.: Reward forcing: Efficient streaming video generation with rewarded distribution matching distillation. arXiv preprint arXiv:2512.04678 (2025)
Pith/arXiv arXiv 2025
-
[19]
arXiv preprint arXiv:2501.03575 (2025)
NVIDIA: Cosmos world foundation model platform for physical ai. arXiv preprint arXiv:2501.03575 (2025)
Pith/arXiv arXiv 2025
-
[20]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (2023)
Peebles, W., Xie, S.: Scalable diffusion models with transformers. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (2023)
2023
-
[22]
arXiv preprint arXiv:2410.13720 (2024)
Polyak, A., Zohar, A., Brown, A., Tjandra, A., Sinha, A., Lee, A., Vyas, A., Shi, B., Ma, C.Y., Chuang, C.Y., et al.: Movie gen: A cast of media foundation models. arXiv preprint arXiv:2410.13720 (2024)
Pith/arXiv arXiv 2024
-
[23]
In: Proceedings of the European Conference on Computer Vision (ECCV)
Reda, F., Kontkanen, J., Tabellion, E., Sun, D., Pantofaru, C., Curless, B.: FILM: Frame interpolation for large motion. In: Proceedings of the European Conference on Computer Vision (ECCV). pp. 250–266 (2022)
2022
-
[24]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2022)
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2022)
2022
-
[25]
In: Medical Image Computing and Computer-Assisted Intervention (MICCAI) (2015)
Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomed- ical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention (MICCAI) (2015)
2015
-
[26]
Neurocomputing568, 127063 (2024)
Su, J., Ahmed, M., Lu, Y., Pan, S., Bo, W., Liu, Y.: Roformer: Enhanced trans- former with rotary position embedding. Neurocomputing568, 127063 (2024)
2024
-
[27]
arXiv preprint arXiv:2510.08561 (2025)
Tanveer, M., Zhou, Y., Niklaus, S., Amiri, A.M., Zhang, H., Singh, K.K., Zhao, N.: Multicoin: Multi-modal controllable video inbetweening. arXiv preprint arXiv:2510.08561 (2025)
arXiv 2025
-
[28]
In: Advances in Neural Information Processing Systems (NeurIPS) (2017)
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, L., Polosukhin, I.: Attention is all you need. In: Advances in Neural Information Processing Systems (NeurIPS) (2017)
2017
-
[29]
In: Advances in Neural Infor- mation Processing Systems (NeurIPS) (2022)
Voleti, V., Jolicoeur-Martineau, A., Pal, C.: Mcvd: Masked conditional video dif- fusion for prediction, generation, and interpolation. In: Advances in Neural Infor- mation Processing Systems (NeurIPS) (2022)
2022
-
[30]
Wan-AI: Wan2.1: Text-to-video generation model.https://github.com/Wan-AI/ Wan2.1(2024)
2024
-
[31]
In: NeurIPS Datasets and Benchmarks (2024)
Wang, W., Yang, Y.: Vidprom: A million-scale real-world video prompt-gallery dataset for text-to-video diffusion models. In: NeurIPS Datasets and Benchmarks (2024)
2024
-
[32]
In: Proceedings of the International Conference on Learning Repre- sentations (ICLR) (2025)
Wang, X., Zhou, B., Curless, B., Kemelmacher-Shlizerman, I., Holynski, A., Seitz, S.M.: Generative inbetweening: Adapting image-to-video models for keyframe in- terpolation. In: Proceedings of the International Conference on Learning Repre- sentations (ICLR) (2025)
2025
-
[33]
In: Proceedings of the International Conference on Learning Representations (ICLR) (2024)
Xiao, G., Tian, Y., Chen, B., Han, S., Lewis, M.: Efficient streaming language models with attention sinks. In: Proceedings of the International Conference on Learning Representations (ICLR) (2024)
2024
-
[34]
arXiv preprint arXiv:2412.15115 (2024) UniTemp 17
Yang,A.,Yang,B.,Zhang,B.,Hui,B.,Zheng,B.,Yu,B.,Li,C.,Liu,D.,Huang,F., Wei, H., et al.: Qwen2.5 technical report. arXiv preprint arXiv:2412.15115 (2024) UniTemp 17
Pith/arXiv arXiv 2024
-
[35]
arXiv preprint arXiv:2509.22622 (2025)
Yang, S., Huang, W., Chu, R., Xiao, Y., Zhao, Y., Wang, X., Li, M., Xie, E., Chen, Y., Lu, Y., Han, S., Chen, Y.: Longlive: Real-time interactive long video generation. arXiv preprint arXiv:2509.22622 (2025)
Pith/arXiv arXiv 2025
-
[36]
In: Proceedings of the International Conference on Learning Representations (ICLR) (2025)
Yang, Z., Teng, J., Zheng, W., Ding, M., Huang, S., Xu, J., Yang, Y., Hong, W., Zhang, X., Feng, G., et al.: Cogvideox: Text-to-video diffusion models with an expert transformer. In: Proceedings of the International Conference on Learning Representations (ICLR) (2025)
2025
-
[37]
arXiv preprint arXiv:2511.20649 (2025)
Yesiltepe, H., Meral, T.H.S., Akan, A.K., Oktay, K., Yanardag, P.: Infinity-rope: Action-controllable infinite video generation emerges from autoregressive self- rollout. arXiv preprint arXiv:2511.20649 (2025)
arXiv 2025
-
[38]
arXiv preprint arXiv:2512.05081 (2025)
Yi, J., Jang, W., Cho, P.H., Nam, J., Yoon, H., Kim, S.: Deep forcing: Training-free long video generation with deep sink and participative compression. arXiv preprint arXiv:2512.05081 (2025)
arXiv 2025
-
[39]
In: Advances in Neural Information Processing Systems (NeurIPS) (2024)
Yin, T., Gharbi, M., Park, T., Zhang, R., Shechtman, E., Durand, F., Freeman, W.T.: Improved distribution matching distillation for fast image synthesis. In: Advances in Neural Information Processing Systems (NeurIPS) (2024)
2024
-
[40]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2024)
Yin, T., Gharbi, M., Zhang, R., Shechtman, E., Durand, F., Freeman, W.T., Park, T.: One-step diffusion with distribution matching distillation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2024)
2024
-
[41]
arXiv preprint arXiv:2412.07772 (2024)
Yin, T., Zhang, Q., Zhang, R., Freeman, W.T., Durand, F., Shechtman, E., Huang, X.: From slow bidirectional to fast causal video generators. arXiv preprint arXiv:2412.07772 (2024)
arXiv 2024
-
[42]
In: Proceedings of the International Conference on Learning Representations (ICLR) (2024)
Yu, L., Lezama, J., Gundavarapu, N.B., Versari, L., Sohn, K., Minnen, D., Cheng, Y., Gupta, A., Gu, X., Hauptmann, A.G., et al.: Language model beats diffu- sion – tokenizer is key to visual generation. In: Proceedings of the International Conference on Learning Representations (ICLR) (2024)
2024
-
[43]
Zheng, Z., Peng, X., Yang, T., Shen, C., Li, S., Liu, H., Zhou, Y., Li, T., You, Y.: Open-sora: Democratizing efficient video production for all. arXiv preprint arXiv:2412.20404 (2024) UniTemp: Unlocking Video Generation in Any Temporal Order via Bidirectional Distillation Supplementary Material We use numbers (e.g., Sec. 1) to refer to the main paper and...
Pith/arXiv arXiv 2024
-
[44]
With 6 latents in attention, RoPE can thus distinguish the two cases and allow the model to generate correctly
to condition the generation of the first block (z18, z19, z20). With 6 latents in attention, RoPE can thus distinguish the two cases and allow the model to generate correctly. Loss is not applied on the dummy block. The noise level is sampled independently for the dummy block and the real initial block (z0, z1, z2). In stage-2 training, we also prepend a ...
1966
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.