WinDOM: Self-Family Distillation for Small-Model GUI Grounding
Pith reviewed 2026-06-25 19:56 UTC · model grok-4.3
The pith
Under-saturated self-family distillation cold-starts outperform converged ones as GRPO initializers for 2B GUI-grounding models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
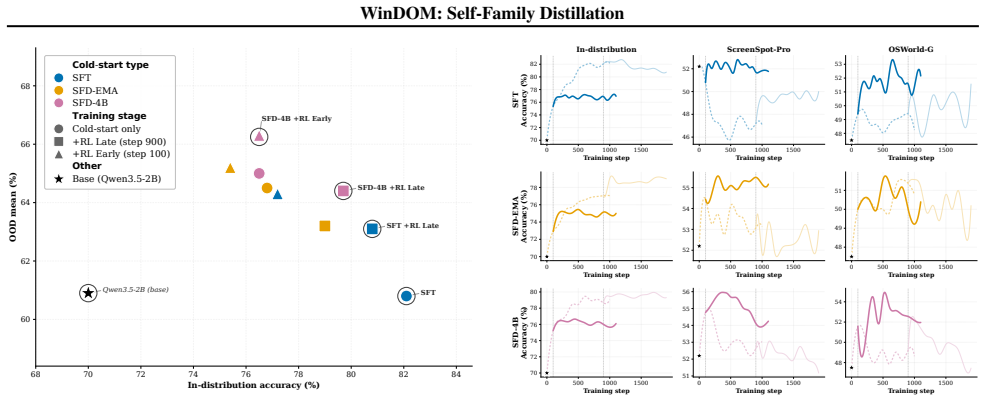
WinDOM supplies 54425 DOM-derived grounding examples with no OCR or human labels. Self-Family Distillation performs rejection sampling whose only parameters are teacher choice (EMA or same-family 4B model) and saturation depth, the latter treated as a GRPO hyperparameter. On Qwen3.5-2B the under-saturated SFD-4B cold-start followed by early-init RL yields +5.4 OOD-mean (+3.5 ScreenSpot-Pro, +7.0 OSWorld-G, +5.8 ScreenSpot-V2) over the base model, while the same-size EMA variant reaches 65.2 versus 66.3 for the cross-size version.
What carries the argument
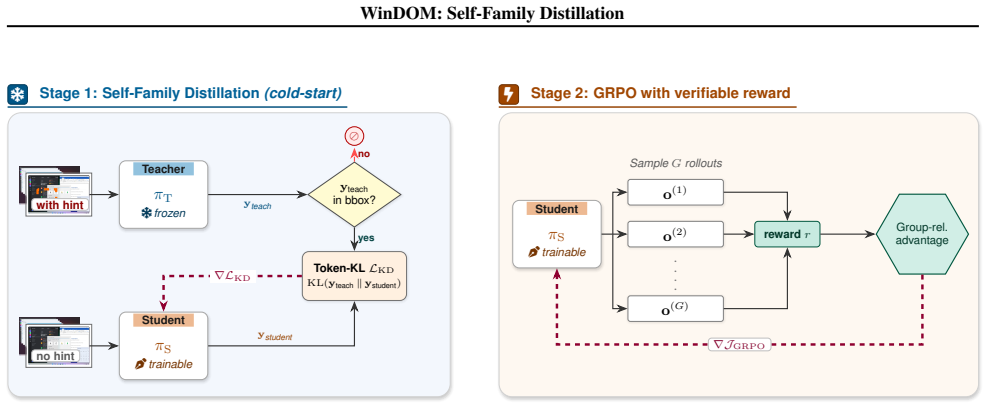
Self-Family Distillation (SFD), a rejection-sampling cold-start whose saturation depth is used as a controllable GRPO hyperparameter.
If this is right
- Small 2B models can reach competitive GUI grounding using only synthetic DOM data and same-family distillation.
- Saturation depth becomes a tunable hyperparameter that trades off cold-start quality against downstream RL gains.
- EMA-based SFD removes the need for an external larger teacher while staying within one OOD-mean point of the 4B-teacher result.
- The recipe separates data generation from model scaling, allowing iteration at fixed 2B size.
Where Pith is reading between the lines
- The same early-stopping principle could be tested on other reinforcement-learning algorithms or agent domains that use cold-start initialization.
- If under-saturation consistently helps, distillation pipelines might adopt scheduled early stopping rather than training to convergence.
- The approach suggests that partial teacher signals preserve exploration-friendly representations that full convergence removes.
Load-bearing premise
That the saturation depth of an SFD cold-start functions as a controllable GRPO hyperparameter whose under-saturated state reliably produces a superior initialization for downstream reinforcement learning.
What would settle it
Running the identical GRPO stage from a fully converged SFD checkpoint and measuring whether out-of-domain mean performance equals or exceeds the under-saturated checkpoint would falsify the central claim.
Figures
read the original abstract
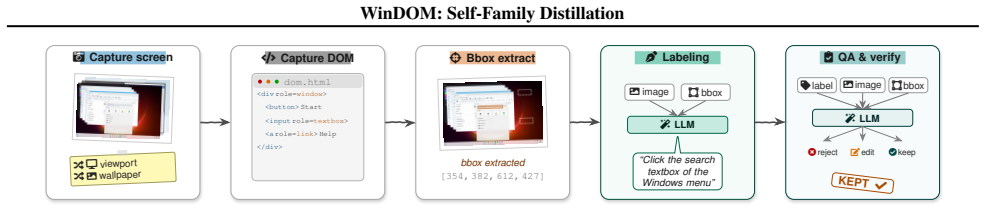
Small ($\sim$2B) GUI-grounding agents are attractive for on-device deployment, accessibility tooling, and low-cost iteration, but at this scale they face two open recipe questions: how to obtain bounding-box training data without expensive human annotation, and how to combine supervised fine-tuning with reinforcement learning. We address both, with the explicit goal of pushing small-model performance rather than scaling up. WinDOM is a $54{,}425$-record grounding corpus harvested by driving an open-source Windows 11 web reimplementation under headless Playwright, with bounding boxes read directly off the DOM and no OCR or human annotation. Self-Family Distillation (SFD) is a single rejection-sampling cold-start parameterised only by the teacher choice: either an EMA of the student (no external model) or a frozen larger same-family teacher. We then treat the saturation depth of the SFD cold-start as an explicit GRPO hyperparameter. On a Qwen3.5-2B student, the under-saturated cold-start is a better GRPO initialiser than the converged one: SFD-4B with Early-init RL gains $+5.4$ OOD-mean ($+3.5$ ScreenSpot-Pro, $+7.0$ OSWorld-G, $+5.8$ ScreenSpot-V2) over the base. The same-size EMA mode lands within roughly one OOD-mean point of the cross-size $4$B variant ($65.2$ vs $66.3$) without an external teacher.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces WinDOM, a 54,425-record GUI grounding corpus collected via direct DOM bounding-box extraction from a headless Windows 11 web reimplementation (no OCR or human annotation). It proposes Self-Family Distillation (SFD) as a rejection-sampling cold-start for ~2B models, using either an EMA of the student or a frozen larger same-family teacher. Saturation depth of the SFD cold-start is framed as an explicit GRPO hyperparameter; the central claim is that an under-saturated initialization outperforms a converged one after RL, yielding +5.4 OOD-mean (+3.5 ScreenSpot-Pro, +7.0 OSWorld-G, +5.8 ScreenSpot-V2) on Qwen3.5-2B, with the same-size EMA variant performing within ~1 point of the 4B teacher variant.
Significance. If the central claim holds after proper validation, the work supplies a practical, annotation-free recipe for improving small-model GUI grounding that reduces dependence on external teachers and human labels, which is relevant for on-device and accessibility use cases. Treating cold-start saturation depth as a controllable RL hyperparameter is a potentially useful framing, and the self-family (EMA) mode is a notable strength for settings without access to larger models. The DOM-based data harvesting is a clear methodological contribution that avoids common annotation bottlenecks.
major comments (2)
- [Abstract] Abstract: the central claim that under-saturated SFD cold-start is a superior GRPO initializer (yielding +5.4 OOD-mean) is presented without any definition or operationalization of saturation (loss plateau, validation accuracy threshold, or step count), without training curves, and without ablations that isolate saturation depth from total SFT steps or data exposure. This is load-bearing for the claim that saturation depth functions as a reliable, controllable hyperparameter.
- [Abstract] Abstract: the reported numeric gains lack any description of baselines, number of runs, error bars, statistical tests, or how the OOD-mean is aggregated across ScreenSpot-Pro / OSWorld-G / ScreenSpot-V2. Without these, the superiority of the early-init variant over both base and converged cold-start cannot be assessed.
minor comments (1)
- The dataset size notation '54{,}425' uses a non-standard thousands separator; conventional comma formatting would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential practical value of WinDOM and the self-family distillation approach. We address the two major comments below. Both points identify genuine gaps in the current presentation; we will revise the abstract and add supporting material in the main text and appendix.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that under-saturated SFD cold-start is a superior GRPO initializer (yielding +5.4 OOD-mean) is presented without any definition or operationalization of saturation (loss plateau, validation accuracy threshold, or step count), without training curves, and without ablations that isolate saturation depth from total SFT steps or data exposure. This is load-bearing for the claim that saturation depth functions as a reliable, controllable hyperparameter.
Authors: We agree that the abstract (and current manuscript) does not supply an explicit operational definition of saturation or the requested supporting analyses. In the revision we will (1) define saturation as the first checkpoint at which validation accuracy improves by less than 0.5 percentage points over the subsequent 500 SFT steps, (2) add training curves that mark the early-init and converged checkpoints, and (3) include an ablation that varies saturation depth while holding total SFT tokens fixed. These additions will appear in both the abstract and a new subsection of the methods. revision: yes
-
Referee: [Abstract] Abstract: the reported numeric gains lack any description of baselines, number of runs, error bars, statistical tests, or how the OOD-mean is aggregated across ScreenSpot-Pro / OSWorld-G / ScreenSpot-V2. Without these, the superiority of the early-init variant over both base and converged cold-start cannot be assessed.
Authors: We acknowledge that the abstract provides none of the requested experimental details. The OOD-mean is the simple arithmetic mean of the three reported OOD benchmarks. The baselines are the unmodified Qwen3.5-2B and the fully converged SFD checkpoint. All numbers derive from single training runs; we will state this limitation explicitly and will not claim statistical significance. In the revision we will expand the abstract and results section to include these clarifications and will move the full per-benchmark tables to the main body. revision: yes
Circularity Check
No circularity; results are empirical comparisons without derivations or self-referential reductions.
full rationale
The paper presents an empirical method: harvesting a grounding corpus from DOM, applying self-family distillation (SFD) as a rejection-sampling cold-start, and treating saturation depth as a GRPO hyperparameter. The central claim of superior performance from under-saturated initialization (+5.4 OOD-mean) is supported solely by benchmark comparisons (ScreenSpot-Pro, OSWorld-G, ScreenSpot-V2) rather than any equations, predictions, or first-principles results that reduce to inputs by construction. No self-citations, uniqueness theorems, or ansatzes are load-bearing for the reported gains. The derivation chain is absent; the work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2024 , url=
Shao, Zhihong and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Song, Junxiao and Bi, Xiao and Zhang, Haowei and others , journal=. 2024 , url=
2024
-
[2]
2025 , url=
Yu, Qiying and Zheng, Zheng and Song, Shenzhi and others , booktitle=. 2025 , url=
2025
-
[3]
Understanding
Liu, Zichen and Chen, Changyu and Li, Wenjun and Qi, Penghui and Pang, Tianyu and Du, Chao and Lee, Wee Sun and Lin, Min , booktitle=. Understanding. 2025 , url=
2025
-
[4]
2025 , url=
Jin, Hangzhan and Luan, Sitao and Lyu, Sicheng and Rabusseau, Guillaume and Rabbany, Reihaneh and Precup, Doina and Hamdaqa, Mohammad , journal=. 2025 , url=
2025
-
[5]
2024 , publisher=
Cheng, Kanzhi and Sun, Qiushi and Chu, Yougang and Xu, Fangzhi and Li, Yantao and Zhang, Jianbing and Wu, Zhiyong , booktitle=. 2024 , publisher=
2024
-
[6]
Screenspot-pro: GUI grounding for professional high-resolution computer use
Li, Kaixin and Meng, Ziyang and Lin, Hongzhan and Luo, Ziyang and Tian, Yuchen and Ma, Jing and Huang, Zhiyong and Chua, Tat-Seng , booktitle=. 2025 , publisher=. doi:10.1145/3746027.3755688 , url=
-
[7]
2024 , url=
Hong, Wenyi and Wang, Weihan and Lv, Qingsong and Xu, Jiazheng and Yu, Wenmeng and Ji, Junhui and Wang, Yan and Wang, Zihan and Zhang, Yuxuan and Li, Juanzi and Xu, Bin and Dong, Yuxiao and Ding, Ming and Tang, Jie , booktitle=. 2024 , url=
2024
-
[8]
2026 , howpublished=
2026
-
[9]
2026 , url=
Yang, Yan and Li, Dongxu and Yang, Yuhao and Luo, Ziyang and Dai, Yutong and Chen, Zeyuan and Xu, Ran and Pan, Liyuan and Xiong, Caiming and Li, Junnan , booktitle=. 2026 , url=
2026
-
[10]
2025 , url=
Liu, Yuhang and Li, Pengxiang and Xie, Congkai and Hu, Xavier and Han, Xiaotian and Zhang, Shengyu and Yang, Hongxia and Wu, Fei , journal=. 2025 , url=
2025
-
[11]
2025 , url=
Zhou, Yuqi and Dai, Sunhao and Wang, Shuai and Zhou, Kaiwen and Jia, Qinglin and Xu, Jun , booktitle=. 2025 , url=
2025
-
[12]
2026 , url=
Lu, Zhengxi and Chai, Yuxiang and Guo, Yaxuan and Yin, Xi and Liu, Liang and Wang, Hao and Xiao, Han and Ren, Shuai and Xiong, Guanjing and Li, Hongsheng , booktitle=. 2026 , url=
2026
-
[13]
2025 , url=
Wang, Haoming and Zou, Haoyang and Song, Huatong and others , journal=. 2025 , url=
2025
-
[14]
arXiv preprint arXiv:2601.20802 , year=
Reinforcement Learning via Self-Distillation , author=. arXiv preprint arXiv:2601.20802 , year=
-
[15]
2026 , url=
Chen, Kun and Shi, Peng and Qiu, Haibo and Zeng, Zhixiong and Yang, Siqi and Mao, Wenji and Ma, Lin , booktitle=. 2026 , url=
2026
-
[16]
ICLR Workshop on Lifelong Agents: Learning, Aligning, Evolving , year=
Self-Distillation Enables Continual Learning , author=. ICLR Workshop on Lifelong Agents: Learning, Aligning, Evolving , year=
-
[17]
Proceedings of the 35th International Conference on Machine Learning (ICML) , series=
Born-Again Neural Networks , author=. Proceedings of the 35th International Conference on Machine Learning (ICML) , series=. 2018 , url=
2018
-
[18]
NeurIPS , year=
Mean Teachers Are Better Role Models: Weight-Averaged Consistency Targets Improve Semi-Supervised Deep Learning Results , author=. NeurIPS , year=
-
[19]
NeurIPS , year=
Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning , author=. NeurIPS , year=
-
[20]
2022 , url=
Zelikman, Eric and Wu, Yuhuai and Mu, Jesse and Goodman, Noah D , booktitle=. 2022 , url=
2022
-
[21]
Transactions on Machine Learning Research , year=
Beyond Human Data: Scaling Self-Training for Problem-Solving with Language Models , author=. Transactions on Machine Learning Research , year=
-
[22]
2025 , doi=
Nature , volume=. 2025 , doi=
2025
-
[23]
and Levine, Sergey and Ma, Yi , booktitle=
Chu, Tianzhe and Zhai, Yuexiang and Yang, Jihan and Tong, Shengbang and Xie, Saining and Schuurmans, Dale and Le, Quoc V. and Levine, Sergey and Ma, Yi , booktitle=. 2025 , url=
2025
-
[24]
2025 , url=
Wu, Zhiyong and Wu, Zhenyu and Xu, Fangzhi and Wang, Yian and Sun, Qiushi and Jia, Chengyou and Cheng, Kanzhi and Ding, Zichen and Chen, Liheng and Liang, Paul Pu and Qiao, Yu , booktitle=. 2025 , url=
2025
-
[25]
Advances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track , year=
Scaling Computer-Use Grounding via User Interface Decomposition and Synthesis , author=. Advances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.