Controllable Narrative Rendering for Enhanced Assisted Writing
Pith reviewed 2026-07-03 00:13 UTC · model grok-4.3
The pith
Loom separates story from discourse in a three-layer pipeline to let LLMs enhance creative writing without either polishing blandly or expanding plots uncontrollably.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
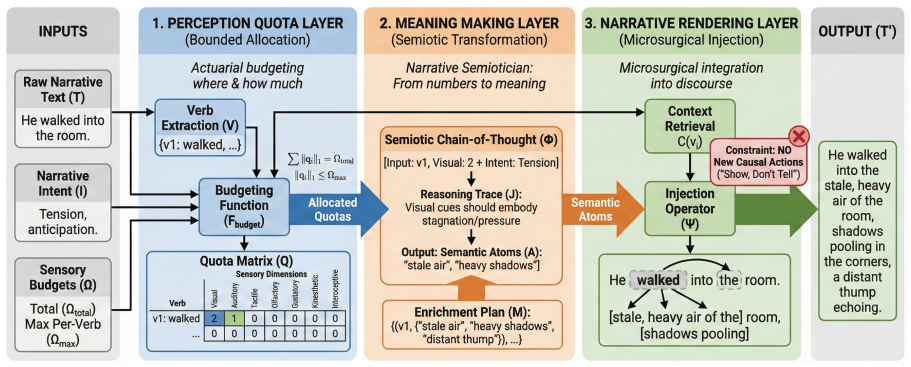
Loom operationalizes the narratological distinction between story and discourse via a three-layer pipeline that applies an intent-centered semiotic chain-of-thought; the pipeline generates perceptual material independently of syntactic insertion, so that rendering density can be raised without altering the original event structure, producing the highest overall quality scores and clear improvements in factual integrity and descriptive intensity.
What carries the argument
The three-layer pipeline with intent-centered semiotic chain-of-thought that separates perceptual-material generation from syntactic insertion.
If this is right
- Writers receive text that is both more vivid and faithful to their stated events.
- Factual drift is reduced compared with direct prompting or polishing baselines.
- Control over how much description is added becomes explicit rather than emergent.
- The same architecture can be applied to different genres without retraining the underlying model.
- Overall quality rises because the two failure modes of remedial polishing and plot expansion are blocked at the architectural level.
Where Pith is reading between the lines
- The same separation of intent from surface rendering could be tested on longer multi-chapter texts to check whether control remains stable across scale.
- If the pipeline works, it suggests a general pattern for other creative generation tasks where fidelity to a plan must coexist with expressive variation.
- User studies that vary the explicitness of the initial intent statement would show how much the chain-of-thought step depends on precise human input.
- Integration with iterative user feedback after each layer might further tighten the match between intended and realized discourse.
Load-bearing premise
The narratological split between story and discourse can be turned into a controllable three-layer process that keeps event structure intact while varying rendering density.
What would settle it
A side-by-side human evaluation in which Loom outputs are rated no higher than baselines on either factual integrity or descriptive intensity, or in which event sequences are altered despite the pipeline.
Figures
read the original abstract
Despite the remarkable proficiency of large language models (LLMs) in basic writing assistance, their utility in creative writing is fundamentally hindered by a persistent binary failure. This issue manifests as an oscillation between safe, surface-level editing, referred to as remedial polishing, and destructive, uncontrolled plot expansion. This dilemma defines a critical trade-off between narrative fidelity and descriptive intensity. We propose Loom, an assisted writing framework grounded in the narratological distinction between story and discourse. Loom employs a three-layer pipeline that operationalizes an intent-centered semiotic chain-of-thought to enforce precise control over narrative intent and rendering density. This architecture separates the generation of perceptual material from syntactic insertion, ensuring that enhancement occurs without violating the original event structure. Our comprehensive evaluation, which includes LLM-based metrics and human assessment, demonstrates that Loom successfully resolves this fundamental tension. Loom achieves the highest overall quality score, yielding substantial gains in factual integrity and descriptive intensity compared to state-of-the-art baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Loom, an assisted writing framework that grounds controllable narrative generation in the narratological distinction between story and discourse. It introduces a three-layer pipeline using an intent-centered semiotic chain-of-thought to separate perceptual material generation from syntactic insertion, thereby aiming to resolve the trade-off between narrative fidelity and descriptive intensity without altering original event structure. The abstract asserts that comprehensive evaluation via LLM-based metrics and human assessment shows Loom achieving the highest overall quality score with substantial gains in factual integrity and descriptive intensity over state-of-the-art baselines.
Significance. If the evaluation claims were substantiated, the work would offer a structured, narratologically motivated approach to controllable enhancement in creative writing assistance, potentially improving LLM utility beyond remedial polishing. The separation of intent control from rendering density is a conceptually clear contribution, though no machine-checked proofs, reproducible code, or parameter-free derivations are present to strengthen it.
major comments (1)
- [Abstract] Abstract: The central claim that 'comprehensive evaluation, which includes LLM-based metrics and human assessment, demonstrates that Loom successfully resolves this fundamental tension' and yields 'substantial gains in factual integrity and descriptive intensity compared to state-of-the-art baselines' is unsupported, as the manuscript provides no description of the evaluation protocol, baselines, datasets, specific metrics, quantitative scores, statistical tests, or results. This directly undermines the paper's primary assertion of successful resolution.
Simulated Author's Rebuttal
We thank the referee for their careful reading of the manuscript and for identifying this important issue with the abstract's claims. We address the comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'comprehensive evaluation, which includes LLM-based metrics and human assessment, demonstrates that Loom successfully resolves this fundamental tension' and yields 'substantial gains in factual integrity and descriptive intensity compared to state-of-the-art baselines' is unsupported, as the manuscript provides no description of the evaluation protocol, baselines, datasets, specific metrics, quantitative scores, statistical tests, or results. This directly undermines the paper's primary assertion of successful resolution.
Authors: We agree that the abstract asserts evaluation outcomes without the manuscript supplying the required supporting details on protocol, baselines, datasets, metrics, scores, tests, or results. This is a substantive gap that must be addressed. In the revised manuscript we will add a dedicated evaluation section that fully describes the experimental setup, including all baselines, datasets, LLM-based and human metrics, quantitative results with statistical tests, and any limitations. We will also revise the abstract to ensure its claims are precisely supported by the new content. revision: yes
Circularity Check
No circularity: empirical framework with external evaluation claims
full rationale
The paper presents a descriptive system (Loom three-layer pipeline) and asserts performance via LLM metrics plus human assessment, with no equations, fitted parameters, predictions derived from inputs, or self-citation chains. The central claim reduces to an empirical assertion rather than any self-referential derivation or renaming of results. No load-bearing step matches the enumerated circularity patterns; the derivation chain is absent and the evaluation is positioned as external.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Large language models exhibit a persistent binary failure in creative writing assistance, oscillating between remedial polishing and destructive plot expansion.
- ad hoc to paper The narratological distinction between story and discourse can be operationalized through a three-layer pipeline to control narrative rendering density while preserving event structure.
Reference graph
Works this paper leans on
-
[1]
Reformulating unsupervised style transfer as paraphrase generation,
K. Krishna, J. Wieting, and M. Iyyer, “Reformulating unsupervised style transfer as paraphrase generation,”arXiv preprint arXiv:2010.05700, 2020
-
[2]
A recipe for arbitrary text style transfer with large language models,
E. Reif, D. Ippolito, A. Yuan, A. Coenen, C. Callison-Burch, and J. Wei, “A recipe for arbitrary text style transfer with large language models,” inProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), 2022, pp. 837– 848
2022
-
[3]
Openpi2. 0: An improved dataset for entity tracking in texts,
L. Zhang, H. Xu, A. Kommula, C. Callison-Burch, and N. Tandon, “Openpi2. 0: An improved dataset for entity tracking in texts,” in Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), 2024, pp. 166–178
2024
-
[4]
Genette,Narrative discourse: An essay in method
G. Genette,Narrative discourse: An essay in method. Cornell Univer- sity Press, 1980, vol. 3
1980
-
[5]
Editeval: An instruction-based benchmark for text improvements,
J. Dwivedi-Yu, T. Schick, Z. Jiang, M. Lomeli, P. Lewis, G. Izacard, E. Grave, S. Riedel, and F. Petroni, “Editeval: An instruction-based benchmark for text improvements,” inProceedings of the 28th Confer- ence on Computational Natural Language Learning, 2024, pp. 69–83
2024
-
[6]
Survey of hallucination in natural language generation,
Z. Ji, N. Lee, R. Frieske, T. Yu, D. Su, Y . Xu, E. Ishii, Y . J. Bang, A. Madotto, and P. Fung, “Survey of hallucination in natural language generation,”ACM computing surveys, vol. 55, no. 12, pp. 1–38, 2023
2023
-
[7]
Hierarchical Neural Story Generation
A. Fan, M. Lewis, and Y . Dauphin, “Hierarchical neural story genera- tion,”arXiv preprint arXiv:1805.04833, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[8]
Plan- and-write: Towards better automatic storytelling,
L. Yao, N. Peng, R. Weischedel, K. Knight, D. Zhao, and R. Yan, “Plan- and-write: Towards better automatic storytelling,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 33, no. 01, 2019, pp. 7378–7385
2019
-
[9]
Creating suspenseful stories: Iterative planning with large language models,
K. Xie and M. Riedl, “Creating suspenseful stories: Iterative planning with large language models,”arXiv preprint arXiv:2402.17119, 2024
-
[10]
A character-centric creative story gener- ation via imagination,
K. Park, M. Kim, and K. Jung, “A character-centric creative story gener- ation via imagination,” inFindings of the Association for Computational Linguistics: ACL 2025, 2025, pp. 1598–1645
2025
-
[11]
Rsa-control: A pragmatics-grounded lightweight controllable text generation framework,
Y . Wang and V . Demberg, “Rsa-control: A pragmatics-grounded lightweight controllable text generation framework,”arXiv preprint arXiv:2410.19109, 2024
-
[12]
Ctrl: a conditional transformer language model for controllable gener- ation,
N. Shirish Keskar, B. McCann, L. R. Varshney, C. Xiong, and R. Socher, “Ctrl: a conditional transformer language model for controllable gener- ation,”arXiv e-prints, pp. arXiv–1909, 2019
1909
-
[13]
arXiv preprint arXiv:1912.02164 , year =
S. Dathathri, A. Madotto, J. Lan, J. Hung, E. Frank, P. Molino, J. Yosin- ski, and R. Liu, “Plug and play language models: A simple approach to controlled text generation,”arXiv preprint arXiv:1912.02164, 2019
-
[14]
Collective critics for creative story generation,
M. Bae and H. Kim, “Collective critics for creative story generation,” arXiv preprint arXiv:2410.02428, 2024
-
[15]
Doc: Improving long story coherence with detailed outline control,
K. Yang, D. Klein, N. Peng, and Y . Tian, “Doc: Improving long story coherence with detailed outline control,” inProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2023, pp. 3378–3465
2023
-
[16]
A survey on llms for story gen- eration,
M. Teleki, V . Bengali, X. Dong, S. T. Janjur, H. Liu, T. Liu, C. Wang, T. Liu, Y . Zhang, F. Shipmanet al., “A survey on llms for story gen- eration,” inFindings of the Association for Computational Linguistics: EMNLP 2025, 2025, pp. 13 954–13 966
2025
-
[17]
A Corpus and Evaluation Framework for Deeper Understanding of Commonsense Stories
N. Mostafazadeh, N. Chambers, X. He, D. Parikh, D. Batra, L. Vander- wende, P. Kohli, and J. Allen, “A corpus and evaluation framework for deeper understanding of commonsense stories,”arXiv preprint arXiv:1604.01696, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[18]
A technique for the measurement of attitudes
R. Likert, “A technique for the measurement of attitudes.”Archives of psychology, 1932
1932
-
[19]
Vist-gpt: Ushering in the era of visual storytelling with llms?
M. Gado, T. Taliee, M. Memon, D. Ignatov, and R. Timofte, “Vist-gpt: Ushering in the era of visual storytelling with llms?”arXiv preprint arXiv:2504.19267, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.