An Amortized Efficiency Threshold for Comparing Neural and Heuristic Solvers in Combinatorial Optimization
Pith reviewed 2026-05-20 19:58 UTC · model grok-4.3
The pith
Neural solvers for combinatorial optimization become net energy-efficient compared to heuristics after a few thousand deployments once training cost is amortized.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
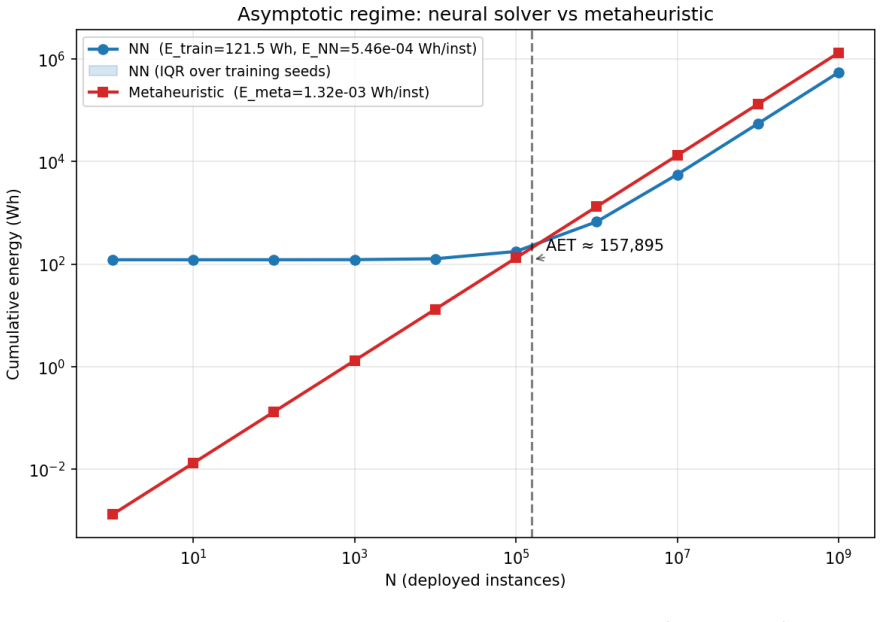
The central claim is that training a neural combinatorial solver incurs a large fixed energy cost while running a metaheuristic incurs a small per-instance cost that repeats with every deployment; these become commensurable only once a deployment volume is specified. The Amortized Efficiency Threshold is defined as the volume at which total energy or carbon equalizes under an explicit quality constraint. When the neural solver is cheaper per instance, the cumulative energy ratio tends to a constant strictly less than one, and this limiting ratio does not depend on the accounting method used for training energy. The same framework applies an embodied-carbon term symmetrically to both solvers.
What carries the argument
The Amortized Efficiency Threshold (AET), the deployment volume at which cumulative energy or carbon cost of a trained neural solver equals that of repeated heuristic runs under fixed solution quality.
If this is right
- The cumulative energy ratio between the two solvers converges to a constant strictly below one whenever the neural solver wins per instance.
- The value of this limiting ratio is independent of how training energy was measured.
- Embodied carbon for hardware fabrication amortizes symmetrically for neural and heuristic approaches.
- In the CVRP instantiation the operational crossover occurs near 4560 instances with a per-instance neural-to-heuristic ratio of 0.00229.
Where Pith is reading between the lines
- If real deployments encounter a wider range of instance difficulties than the training distribution, the constant per-instance cost assumption may need empirical validation.
- The framework could be applied to compare multiple neural architectures or training budgets within the same quality and energy accounting.
- Hardware or software updates after training could move the effective AET in field use.
Load-bearing premise
The per-instance operational energy cost of the trained neural solver remains constant and strictly lower than the heuristic for every future instance, independent of changes in instance difficulty or hardware.
What would settle it
Measure cumulative energy of both solvers over several thousand new instances drawn from the same distribution and check whether the observed crossover volume and long-run ratio match the values predicted by the AET calculation.
Figures







read the original abstract
A common critique of neural combinatorial-optimization solvers is that they are less energy-efficient than CPU metaheuristics, given the operational energy cost of training them on GPUs. This paper examines the inferential step from "training is expensive" to "neural solvers are net-inefficient", which is where the critique actually goes wrong. Training the network costs a large fixed amount of GPU energy; running the metaheuristic costs a small amount of CPU energy on every instance, repeated as long as the solver is deployed. The two are not commensurable until a deployment volume is fixed. We define the Amortized Efficiency Threshold (AET) as the deployment volume above which a neural solver breaks even with a heuristic baseline in total energy or carbon, under an explicit constraint on solution quality. We show that the cumulative-energy ratio between the two solvers tends to a constant strictly below one whenever the network wins per instance, and that this limit does not depend on how the training cost was measured. An embodied-carbon term amortizes hardware fabrication symmetrically on both sides. We instantiate the framework on the CVRP environment at n=50 customers with the attention-based autoregressive solver of Kool et al. (2019), trained for 100 epochs on 20,000 instances over five random seeds, and HGS via PyVRP as the heuristic baseline. The measured operational crossover sits near 4.56e3 deployed instances at the median of a six-point baseline-budget sweep; the per-instance neural-to-heuristic ratio is 2.29e-3. The contribution is the framework, the open instrumentation, and the end-to-end measurement protocol. Code and benchmark pipeline are available at https://github.com/sohaibafifi/aet.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript defines the Amortized Efficiency Threshold (AET) as the deployment volume at which a neural combinatorial optimization solver breaks even with a heuristic baseline in total energy or carbon, subject to an explicit solution-quality constraint. It shows algebraically that the cumulative-energy ratio converges to the per-instance neural-to-heuristic ratio (strictly below one when the neural solver wins per instance) and that this limit is independent of how training cost is measured. The framework is instantiated on CVRP at n=50 using the attention-based autoregressive solver of Kool et al. (2019) and HGS via PyVRP, reporting a measured operational crossover near 4.56e3 instances and a per-instance ratio of 2.29e-3, with an embodied-carbon term amortized symmetrically.
Significance. If the core assumptions hold, the framework supplies a principled, volume-dependent metric for energy comparisons that directly addresses the common critique of neural solvers. The algebraic limit result is elementary and robust, and the open instrumentation plus reproducible measurement protocol constitute a concrete contribution that enables standardized follow-up experiments in combinatorial optimization.
major comments (1)
- [§4] §4 (Empirical Instantiation): the reported AET of 4.56e3 instances is obtained from a specific six-point baseline-budget sweep; the manuscript does not report how the crossover point varies when the heuristic budget is altered, leaving the robustness of the concrete numerical threshold unclear.
minor comments (2)
- [Abstract] Abstract: the phrase 'under an explicit constraint on solution quality' is stated but the concrete quality metric (e.g., optimality gap or feasibility rate) used in the CVRP experiments is not given; adding one sentence would improve readability.
- [§3] §3 (Framework): the embodied-carbon term is introduced symmetrically, yet the estimation procedure for GPU versus CPU fabrication emissions is not detailed; a short paragraph or reference would clarify the accounting.
Simulated Author's Rebuttal
We thank the referee for the constructive comment and the positive overall assessment. We address the single major comment below and will incorporate the requested clarification in the revision.
read point-by-point responses
-
Referee: [§4] §4 (Empirical Instantiation): the reported AET of 4.56e3 instances is obtained from a specific six-point baseline-budget sweep; the manuscript does not report how the crossover point varies when the heuristic budget is altered, leaving the robustness of the concrete numerical threshold unclear.
Authors: We agree that explicitly showing the variation of the AET across the baseline-budget sweep would improve transparency. The six-point sweep was performed precisely to select a representative operating point for the heuristic (HGS via PyVRP), and the reported median of 4.56e3 already reflects that choice. In the revised manuscript we will add a short table (or a supplementary figure) that lists the AET obtained for each of the six budgets together with the resulting range and inter-quartile spread. This addition will make the sensitivity of the numerical threshold to heuristic budget fully visible while leaving the algebraic framework and the per-instance ratio unchanged. No new experiments are required. revision: yes
Circularity Check
No significant circularity; derivation is direct algebraic limit
full rationale
The paper defines AET as the deployment volume at which total energy for the neural solver (fixed training cost T plus per-instance cost N repeated k times) equals that of the heuristic (per-instance cost H repeated k times). It then states that the ratio (T + k·N)/(k·H) converges to N/H < 1 as k grows whenever N < H. This convergence follows immediately from dividing the expressions and taking the limit; the fixed T term vanishes algebraically and the result holds independently of the numerical value or measurement method for T. The paper explicitly lists constancy of N as a framework assumption rather than a derived claim. The reported AET value (~4.56e3 instances) and per-instance ratio (2.29e-3) are obtained by direct instrumentation on the CVRP benchmark with Kool et al. (2019) and HGS, not by algebraic necessity from the model itself. No load-bearing step reduces to a fitted parameter, self-citation, or ansatz smuggled from prior work; the framework is self-contained against its stated assumptions.
Axiom & Free-Parameter Ledger
free parameters (1)
- per-instance neural-to-heuristic energy ratio
axioms (2)
- domain assumption Training energy is incurred once and remains fixed regardless of subsequent deployment volume.
- domain assumption Per-instance energy costs are constant and independent of instance index after training.
Reference graph
Works this paper leans on
-
[1]
Product environmental reports.https://www.apple.com/environment/, 2023
Apple Inc. Product environmental reports.https://www.apple.com/environment/, 2023
work page 2023
-
[2]
Le, Mohammad Norouzi, and Samy Bengio
Irwan Bello, Hieu Pham, Quoc V. Le, Mohammad Norouzi, and Samy Bengio. Neural combinatorial optimization with reinforcement learning. InICLR Workshop, 2017
work page 2017
-
[3]
RL4CO: An extensive reinforcement learning for combinatorial optimization benchmark
Federico Berto, Chuanbo Hua, Junyoung Park, Laurin Luttmann, Yining Ma, Fanchen Bu, Jiarui Wang, Haoran Ye, Minsu Kim, Sanghyeok Choi, André Hottung, Jianan Zhou, Jieyi Bi, Yu Hu, Fei 11 An Amortized Efficiency Threshold for Comparing Neural and Heuristic Solvers in Combinatorial OptimizationA Preprint Liu, Hyeonah Kim, Jiwoo Son, Haeyeon Kim, Wouter Kool...
work page 2024
-
[4]
Lee, Gu-Yeon Wei, David Brooks, and Carole-Jean Wu
Udit Gupta, Young Geun Kim, Sylvia Lee, Jordan Tse, Hsien-Hsin S. Lee, Gu-Yeon Wei, David Brooks, and Carole-Jean Wu. Chasing carbon: The elusive environmental footprint of computing. InHPCA, 2021
work page 2021
-
[5]
Keld Helsgaun. An extension of the Lin-Kernighan-Helsgaun TSP solver for constrained traveling salesman and vehicle routing problems.Roskilde University Technical Report, 2017
work page 2017
-
[6]
Peter Henderson, Jieru Hu, Joshua Romoff, Emma Brunskill, Dan Jurafsky, and Joelle Pineau. Towards the systematic reporting of the energy and carbon footprints of machine learning.Journal of Machine Learning Research, 21(248):1–43, 2020
work page 2020
-
[7]
Efficient active search for combinatorial optimiza- tion problems
André Hottung, Yeong-Dae Kwon, and Kevin Tierney. Efficient active search for combinatorial optimiza- tion problems. InICLR, 2022
work page 2022
-
[8]
David S. Johnson and Lyle A. McGeoch. The traveling salesman problem: A case study in local optimization.Local Search in Combinatorial Optimization, pages215–310, 1997. DIMACSImplementation Challenges
work page 1997
-
[9]
Joshi, Quentin Cappart, Louis-Martin Rousseau, and Thomas Laurent
Chaitanya K. Joshi, Quentin Cappart, Louis-Martin Rousseau, and Thomas Laurent. Learning the travelling salesperson problem requires rethinking generalization.Constraints, 27(1–2):70–98, 2022
work page 2022
-
[10]
Attention, learn to solve routing problems! InICLR, 2019
Wouter Kool, Herke van Hoof, and Max Welling. Attention, learn to solve routing problems! InICLR, 2019
work page 2019
-
[11]
POMO: Policy optimization with multiple optima for reinforcement learning
Yeong-Dae Kwon, Jinho Choo, Byoungjip Kim, Iljoo Yoon, Youngjune Gwon, and Seungjai Min. POMO: Policy optimization with multiple optima for reinforcement learning. InNeurIPS, 2020
work page 2020
-
[12]
Quantifying the Carbon Emissions of Machine Learning
Alexandre Lacoste, Alexandra Luccioni, Victor Schmidt, and Thomas Dandres. Quantifying the carbon emissions of machine learning.arXiv preprint arXiv:1910.09700, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[13]
Alexandra Sasha Luccioni, Sylvain Viguier, and Anne-Laure Ligozat. Estimating the carbon footprint of BLOOM, a 176B parameter language model.Journal of Machine Learning Research, 24(253):1–15, 2023
work page 2023
-
[14]
Carbon Emissions and Large Neural Network Training
David Patterson, Joseph Gonzalez, Quoc Le, Chen Liang, Lluis-Miquel Munguia, Daniel Rothchild, David So, Maud Texier, and Jeff Dean. Carbon emissions and large neural network training.arXiv preprint arXiv:2104.10350, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[15]
Roy Schwartz, Jesse Dodge, Noah A. Smith, and Oren Etzioni. Green AI.Communications of the ACM, 63(12):54–63, 2020
work page 2020
-
[16]
Outrageously large neural networks: The sparsely-gated mixture-of-experts layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. InICLR, 2017
work page 2017
-
[17]
Arman Shehabi, Sarah Smith, Dale Sartor, Richard Brown, Magnus Herrlin, Jonathan Koomey, Eric Masanet, Nathaniel Horner, Inês Azevedo, and William Lintner. United states data center energy usage report.Lawrence Berkeley National Laboratory Technical Report LBNL-1005775, 2016
work page 2016
-
[18]
Masked label prediction: Unified message passing model for semi-supervised classification
Yunsheng Shi, Zhengjie Huang, Shikun Feng, Hui Zhong, Wenjing Wang, and Yu Sun. Masked label prediction: Unified message passing model for semi-supervised classification. InIJCAI, 2021
work page 2021
-
[19]
Energy and policy considerations for deep learning in NLP
Emma Strubell, Ananya Ganesh, and Andrew McCallum. Energy and policy considerations for deep learning in NLP. InACL, 2019
work page 2019
-
[20]
Algorithm selection on a meta level.Machine Learning, 112(4):1255–1290, 2023
Alexander Tornede, Lukas Gehring, Tanja Tornede, Marcel Wever, and Eyke Hüllermeier. Algorithm selection on a meta level.Machine Learning, 112(4):1255–1290, 2023
work page 2023
-
[21]
CVRPLIB: Capacitated vehicle routing problem library.http://vrp.atd-lab.inf.puc-rio.br/, 2017
Eduardo Uchoa, Diego Pecin, Artur Pessoa, Marcus Poggi, Thibaut Vidal, and Anand Subramanian. CVRPLIB: Capacitated vehicle routing problem library.http://vrp.atd-lab.inf.puc-rio.br/, 2017
work page 2017
-
[22]
Thibaut Vidal. Hybrid genetic search for the CVRP: Open-source implementation and SWAP* neigh- borhood.Computers & Operations Research, 140:105643, 2022
work page 2022
-
[23]
Thibaut Vidal, Teodor Gabriel Crainic, Michel Gendreau, Nadia Lahrichi, and Walter Rei. A hybrid genetic algorithm for multidepot and periodic vehicle routing problems.Operations Research, 60(3):611– 624, 2012
work page 2012
-
[24]
Oriol Vinyals, Meire Fortunato, and Navdeep Jaitly. Pointer networks. InNeurIPS, 2015. 12 An Amortized Efficiency Threshold for Comparing Neural and Heuristic Solvers in Combinatorial OptimizationA Preprint
work page 2015
-
[25]
Wouda, Leon Lan, and Wouter Kool
Niels A. Wouda, Leon Lan, and Wouter Kool. PyVRP: A high-performance VRP solver package. INFORMS Journal on Computing, 36(4):943–955, 2024
work page 2024
-
[26]
Lee, Bugra Akyildiz, Maximilian Balandat, Joe Spisak, Ravi Jain, Mike Rabbat, and Kim Hazelwood
Carole-Jean Wu, Ramya Raghavendra, Udit Gupta, Bilge Acun, Newsha Ardalani, Kiwan Maeng, Gloria Chang, Fiona Aga Behram, James Huang, Charles Bai, Michael Gschwind, Anurag Gupta, Myle Ott, Anastasia Melnikov, Salvatore Candido, David Brooks, Geeta Chauhan, Benjamin Lee, Hsien-Hsin S. Lee, Bugra Akyildiz, Maximilian Balandat, Joe Spisak, Ravi Jain, Mike Ra...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.