Deep Reinforcement Learning for Spacecraft Attitude Control During Atmospheric Re-Entry
Pith reviewed 2026-07-01 06:12 UTC · model grok-4.3
The pith
Hybrid controllers that combine reinforcement learning with a PID baseline track the angle of attack more accurately during spacecraft re-entry and stay stable when mass, inertia, or flap actuator speed change.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
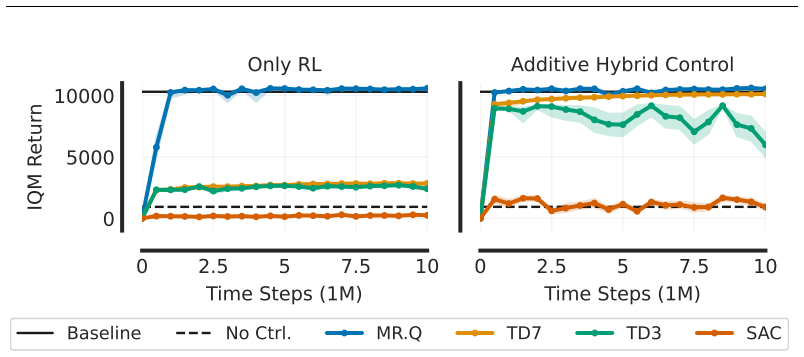
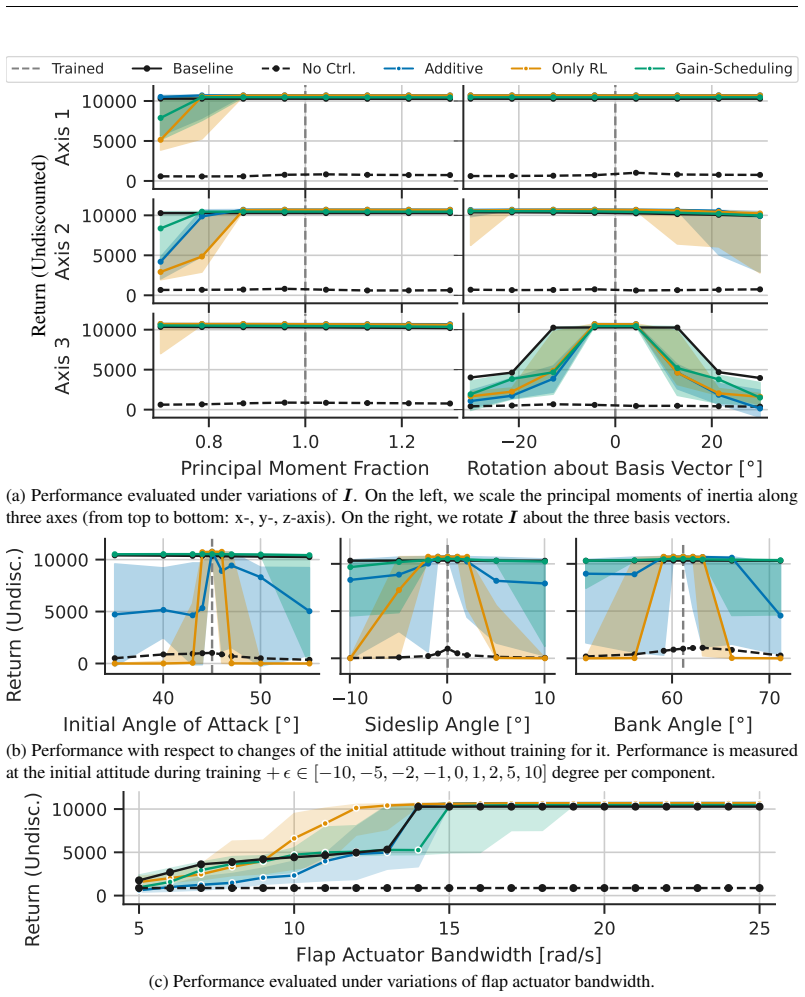
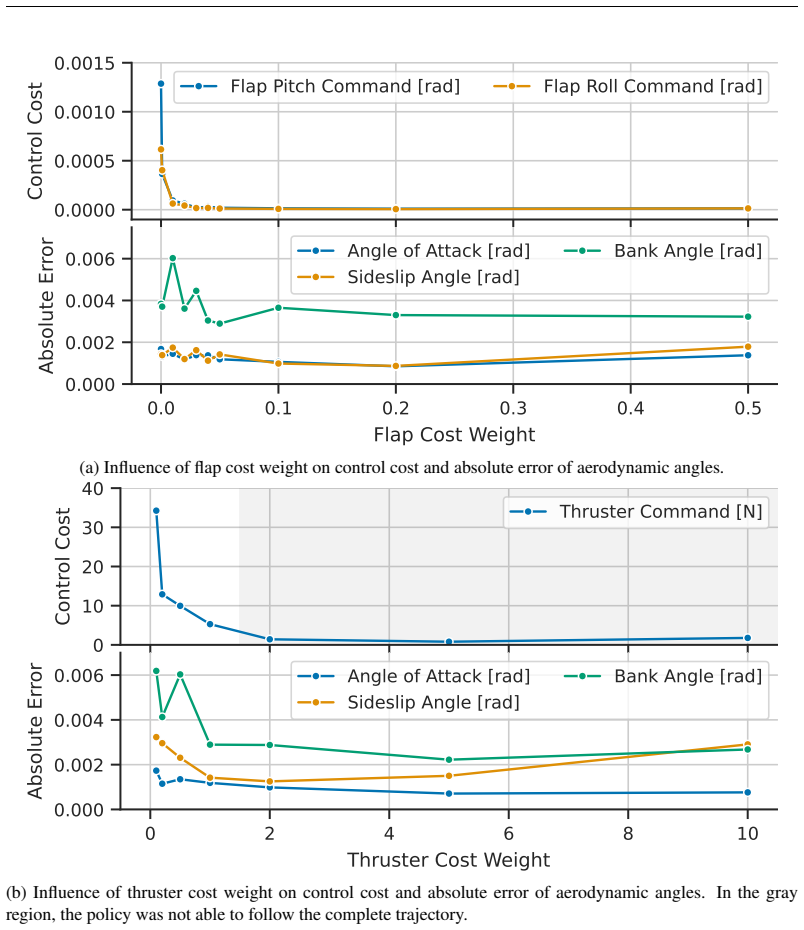
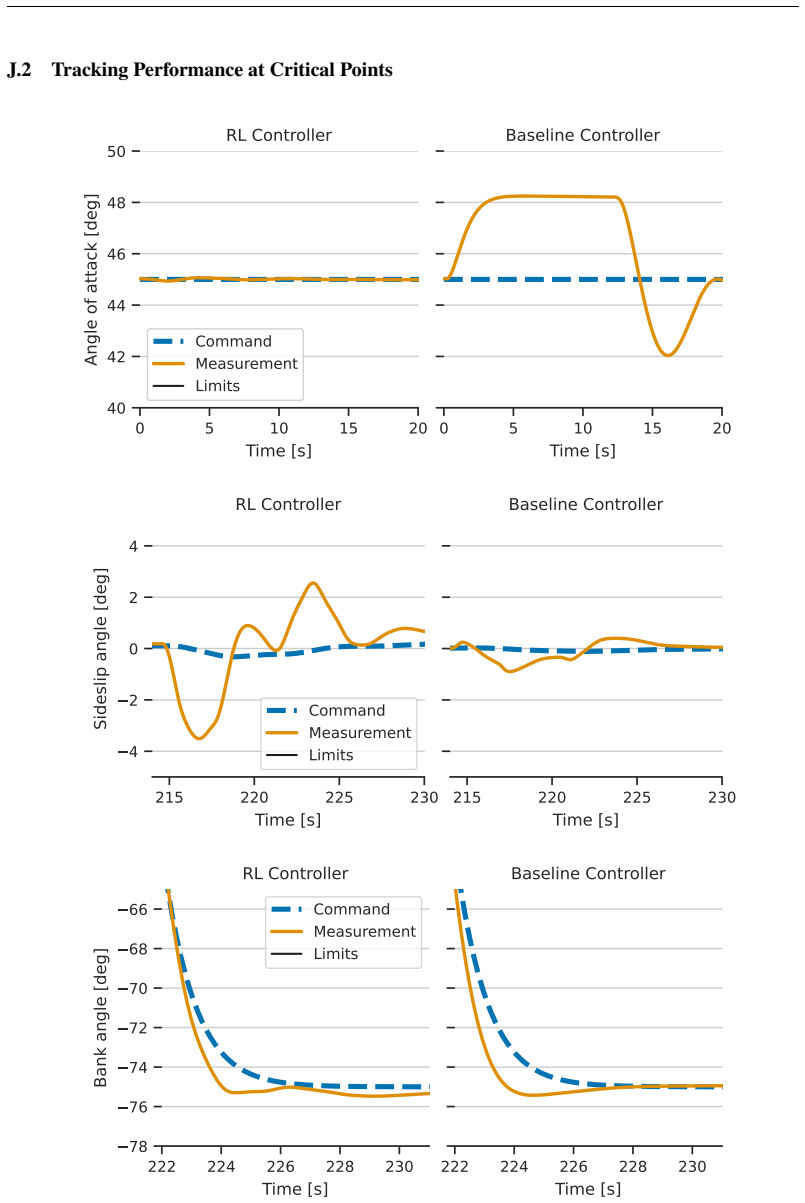
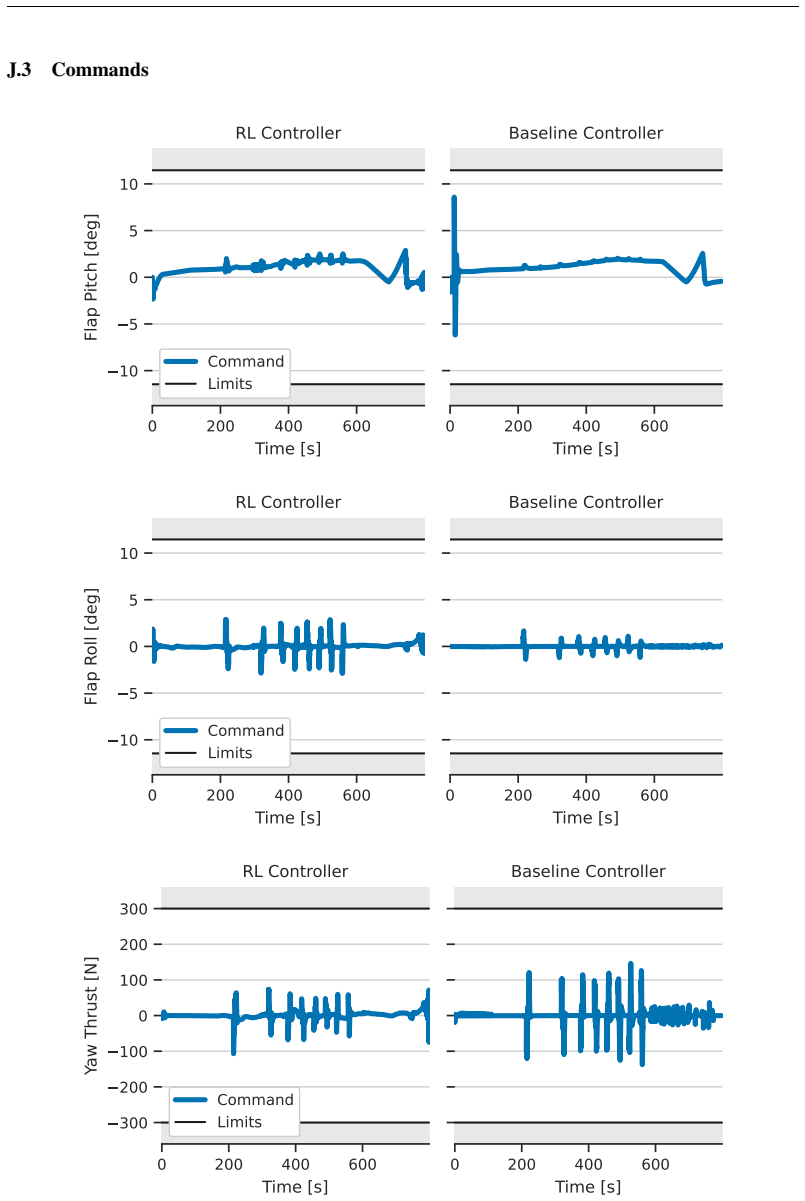
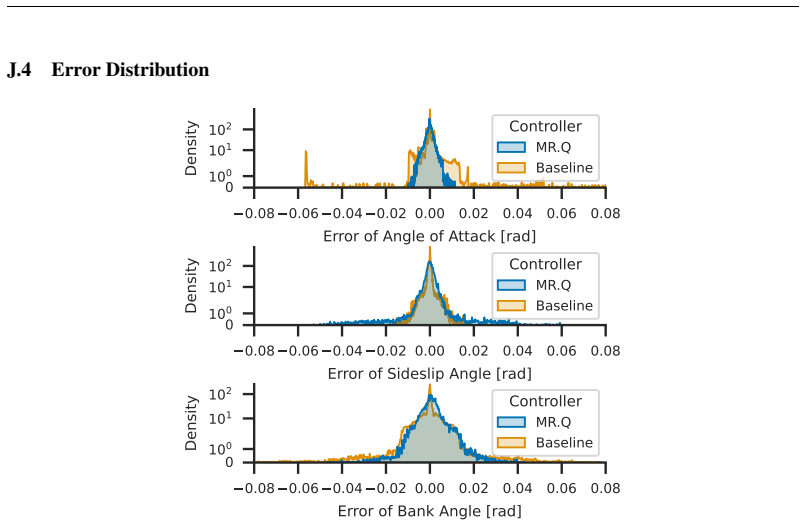
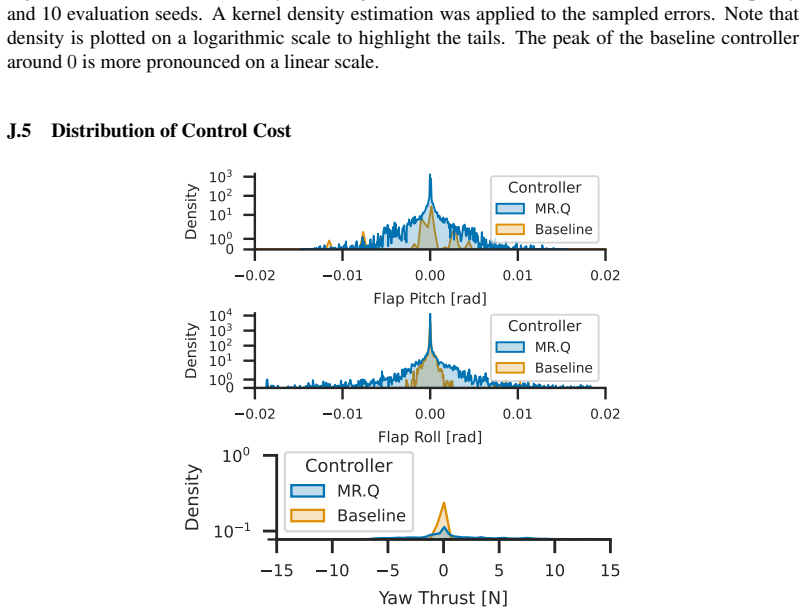
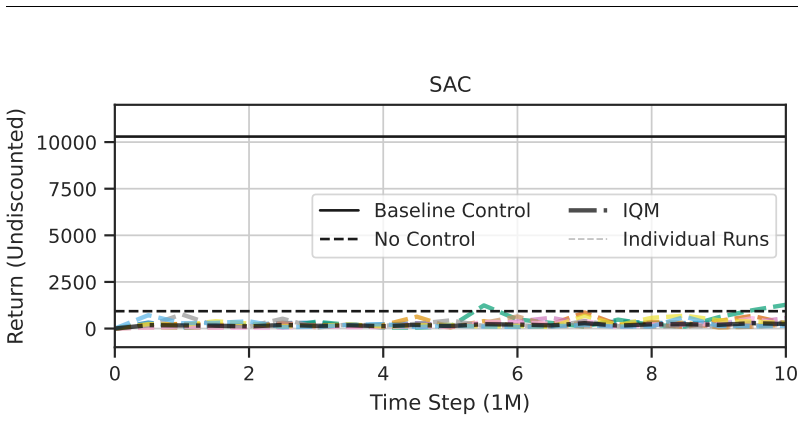
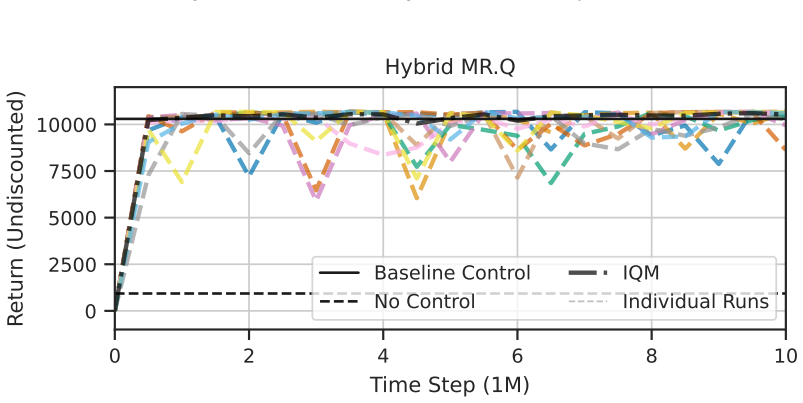
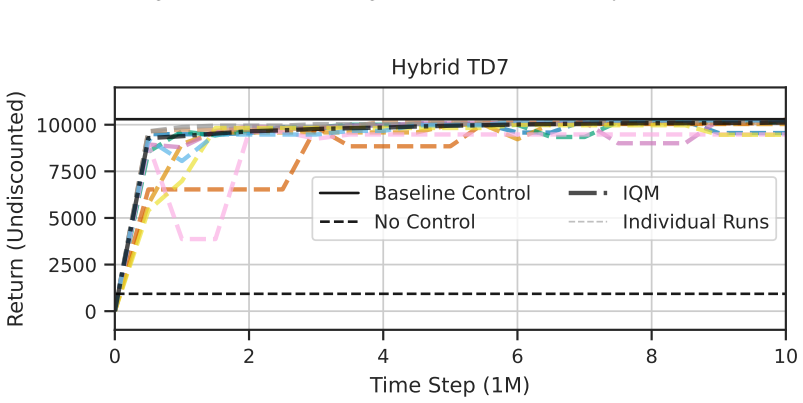
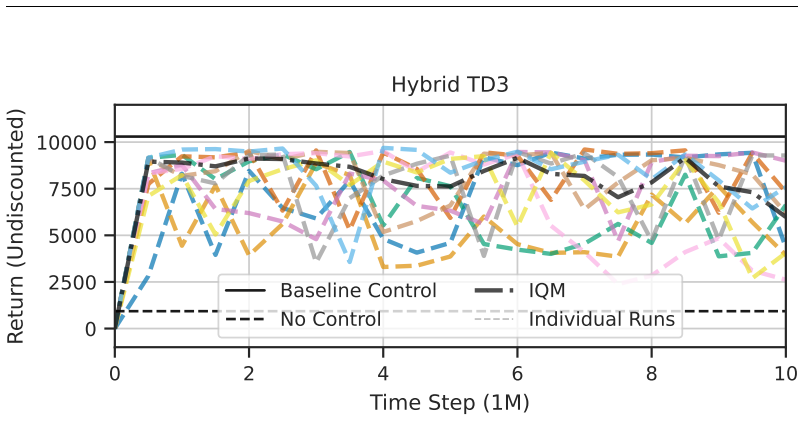
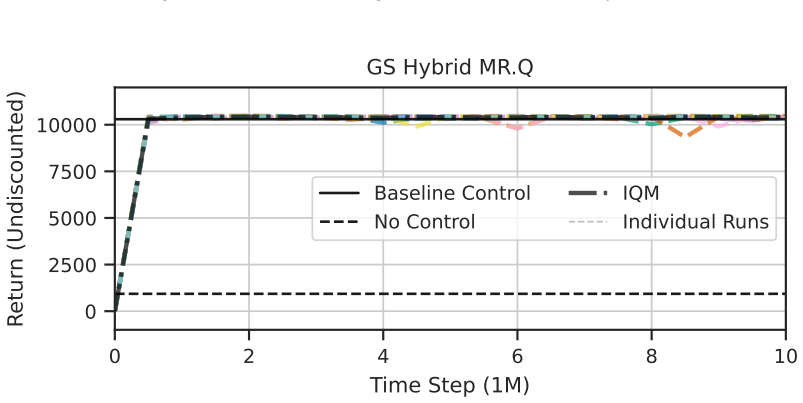
State-of-the-art continuous off-policy reinforcement learning matches the performance of a gain-scheduled PID controller on the re-entry attitude task, yet its out-of-distribution generalization remains insufficient. Dynamics randomization during training, together with a hybrid RL-plus-PID architecture, yields controllers that track the angle of attack better and exhibit greater robustness to variations in mass, inertia tensor, and flap actuator bandwidth inside the predefined operational envelope.
What carries the argument
Hybrid RL-PID controller trained with dynamics randomization to enforce generalization inside a fixed operational envelope.
If this is right
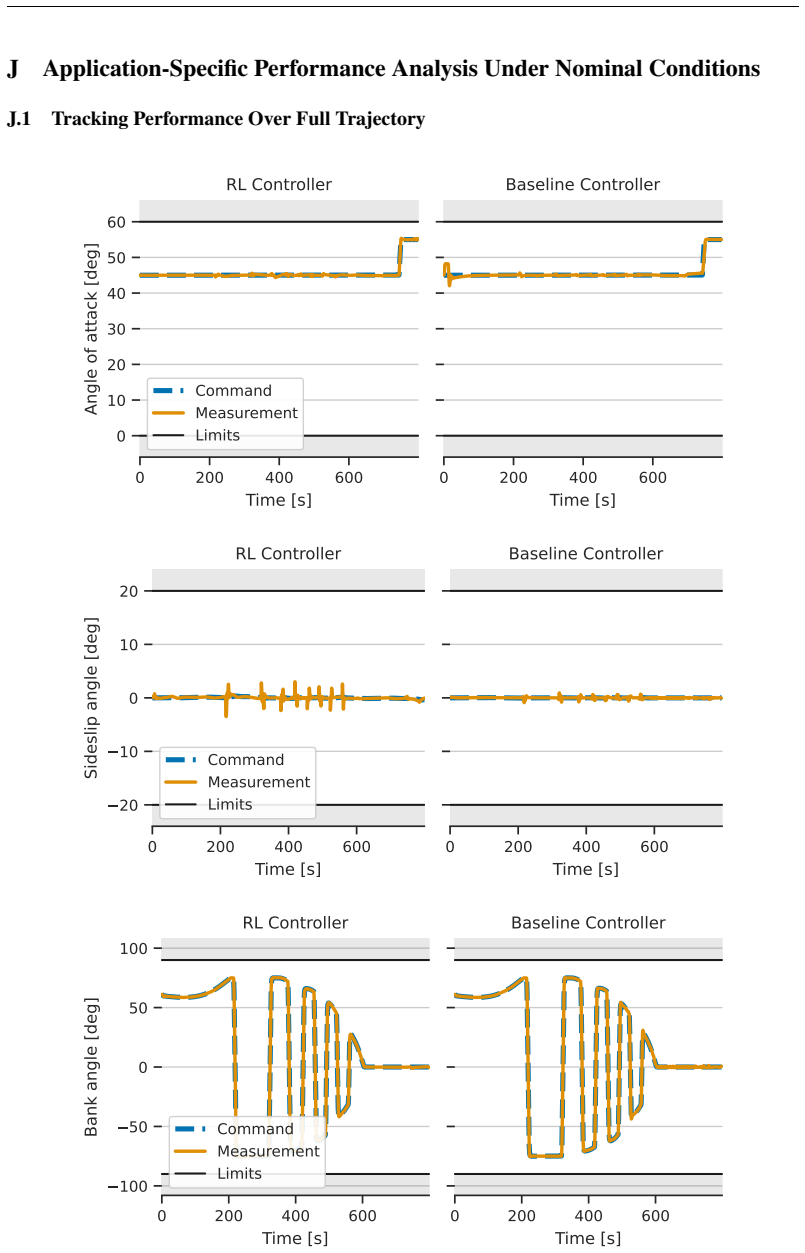
- Hybrid RL-PID controllers achieve tighter angle-of-attack tracking than pure PID inside the operational envelope.
- The same controllers maintain performance when spacecraft mass or inertia tensor changes within the tested range.
- They remain effective when flap actuator bandwidth varies inside the envelope.
- Dynamics randomization during training is what enables the observed generalization improvement over plain RL.
Where Pith is reading between the lines
- The same training recipe could be applied to other attitude-control problems that involve nonlinear aerodynamics and parameter uncertainty.
- If the operational envelope proves too narrow for real missions, the method would require either larger randomization ranges or online adaptation after deployment.
- Replacing the fixed PID baseline with an adaptive classical controller might further improve the hybrid result without extra simulation cost.
Load-bearing premise
The simulation environment and the predefined operational envelope sufficiently capture the relevant real-world uncertainties and failure modes that would be encountered during actual atmospheric re-entry.
What would settle it
A higher-fidelity simulation or flight test in which the hybrid controller loses angle-of-attack tracking or becomes unstable under a mass or inertia change that lies inside the claimed operational envelope would falsify the robustness claim.
Figures




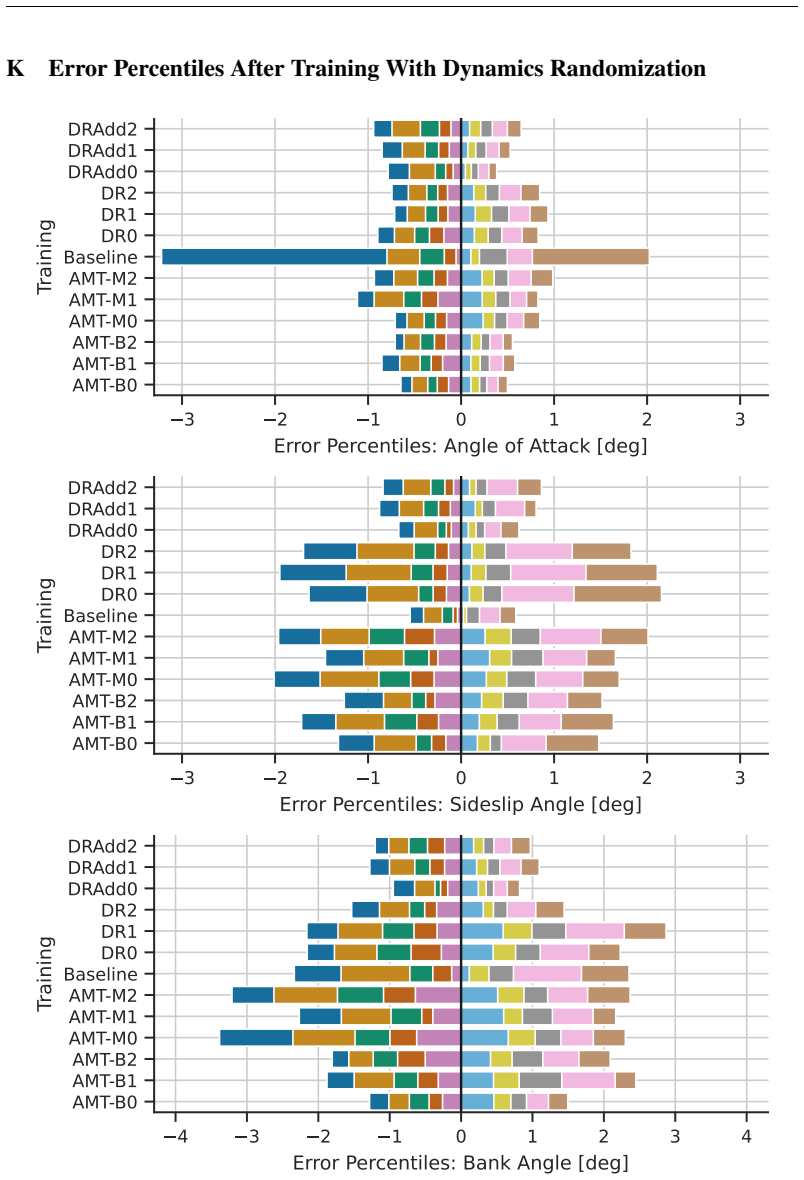

read the original abstract
Deep reinforcement learning has the potential to solve attitude control problems more adaptively, precisely, and robustly by handling nonlinear dynamics, uncertainties, and failure cases more effectively than traditional attitude control approaches. We explore reinforcement learning (RL) for attitude control in spacecraft re-entry. An industry-standard proportional-integral-derivative controller with gain scheduling serves as a strong baseline for model-free RL and hybrid controllers that combine these two approaches. We formalize the application in the RL framework to apply continuous, off-policy RL. State-of-the-art RL achieves comparable performance to traditional control approaches in this domain. However, its out-of-distribution generalization is not sufficient. Hence, we use dynamics randomization to introduce challenging task variations during training and enforce generalization in a predefined operational envelope. Finally, we assess the best obtained RL-based controllers with application-specific metrics to show superior performance in comparison to traditional controllers in the operational envelope, that is, hybrid controllers are able to track the angle of attack better and are more robust under variations of mass, inertia tensor, and flap actuator bandwidth.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates the application of deep reinforcement learning (RL) to spacecraft attitude control during atmospheric re-entry. It compares model-free RL and hybrid RL combined with PID controllers against a traditional PID with gain scheduling baseline. By employing dynamics randomization during training to enforce generalization within a predefined operational envelope, the authors claim that hybrid controllers outperform traditional approaches in tracking the angle of attack and in robustness to variations in mass, inertia tensor, and flap actuator bandwidth.
Significance. If the empirical results hold under proper validation of the simulation envelope, this work could demonstrate the viability of hybrid RL-PID controllers for handling nonlinear dynamics and uncertainties in re-entry scenarios, potentially improving adaptability over classical methods. The use of dynamics randomization is a positive step toward better generalization.
major comments (2)
- Abstract: The abstract asserts superior performance on application-specific metrics and robustness but provides no quantitative results, error bars, training details, or specific metrics, making the central claim impossible to evaluate from the given text.
- Abstract: The robustness claims depend on the simulation environment and predefined operational envelope capturing real-world uncertainties; however, no validation against flight data, higher-fidelity models, or domain-expert failure scenarios is indicated, which is load-bearing for the transferability of the hybrid superiority result.
minor comments (1)
- The abstract could benefit from including at least one key quantitative result to support the claims of superior performance.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments on the abstract below and indicate planned revisions.
read point-by-point responses
-
Referee: Abstract: The abstract asserts superior performance on application-specific metrics and robustness but provides no quantitative results, error bars, training details, or specific metrics, making the central claim impossible to evaluate from the given text.
Authors: We agree that the abstract would be strengthened by quantitative support. The revised version will incorporate key results including mean angle-of-attack tracking error, robustness metrics under mass/inertia/bandwidth variations, and a brief reference to dynamics randomization during training, with error bars where space permits. revision: yes
-
Referee: Abstract: The robustness claims depend on the simulation environment and predefined operational envelope capturing real-world uncertainties; however, no validation against flight data, higher-fidelity models, or domain-expert failure scenarios is indicated, which is load-bearing for the transferability of the hybrid superiority result.
Authors: The work is a simulation study that defines an operational envelope and uses dynamics randomization to promote generalization within it; no flight-data or higher-fidelity validation is performed. We will revise the abstract and add a limitations paragraph that explicitly states the simulation scope and the assumptions underlying the envelope, thereby clarifying the transferability boundary without overstating the results. revision: partial
Circularity Check
No circularity; empirical simulation comparison against external baseline
full rationale
The paper reports an empirical evaluation of RL, hybrid RL+PID, and PID controllers on angle-of-attack tracking and robustness metrics inside a predefined simulation envelope that includes dynamics randomization during training. All performance numbers are obtained by direct rollout comparison to an industry-standard PID baseline; no equations, fitted parameters, or self-citations are invoked to derive the superiority claim. The operational envelope is an explicit experimental design choice rather than a self-referential definition, and the central results remain falsifiable by external simulation or flight data.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
International Journal of Robotics Research , volume =
OpenAI: Marcin Andrychowicz and Bowen Baker and Maciek Chociej and Rafal Józefowicz and Bob McGrew and Jakub Pachocki and Arthur Petron and Matthias Plappert and Glenn Powell and Alex Ray and Jonas Schneider and Szymon Sidor and Josh Tobin and Peter Welinder and Lilian Weng and Wojciech Zaremba , title =. International Journal of Robotics Research , volum...
2020
-
[2]
CoRR , volume =
Rika Antonova and Silvia Cruciani and Christian Smith and Danica Kragic , title =. CoRR , volume =. 2017 , url =
2017
-
[3]
Robotics: Science and Systems , YEAR =
Jie Tan AND Tingnan Zhang AND Erwin Coumans AND Atil Iscen AND Yunfei Bai AND Danijar Hafner AND Steven Bohez AND Vincent Vanhoucke , TITLE =. Robotics: Science and Systems , YEAR =
-
[4]
Sim-to-Real Transfer of Robotic Control with Dynamics Randomization , year=
Peng, Xue Bin and Andrychowicz, Marcin and Zaremba, Wojciech and Abbeel, Pieter , booktitle=. Sim-to-Real Transfer of Robotic Control with Dynamics Randomization , year=
-
[5]
Root Mean Square Layer Normalization , url =
Zhang, Biao and Sennrich, Rico , booktitle =. Root Mean Square Layer Normalization , url =
-
[6]
Johannink, Tobias and Bahl, Shikhar and Nair, Ashvin and Luo, Jianlan and Kumar, Avinash and Loskyll, Matthias and Ojea, Juan Aparicio and Solowjow, Eugen and Levine, Sergey , title =. 2019 , url =. doi:10.1109/ICRA.2019.8794127 , booktitle =
-
[7]
International Conference on Learning Representations , year=
High-Dimensional Continuous Control Using Generalized Advantage Estimation , author=. International Conference on Learning Representations , year=
-
[8]
2018 , number =
Joan Solà and Jérémie Deray and Dinesh Atchuthan , title =. 2018 , number =
2018
-
[9]
Journal of Machine Learning Research , year =
Zintgraf, Luisa and Schulze, Sebastian and Lu, Cong and Feng, Leo and Igl, Maximilian and Shiarlis, Kyriacos and Gal, Yarin and Hofmann, Katja and Whiteson, Shimon , title =. Journal of Machine Learning Research , year =
-
[10]
International Conference on Machine Learning , pages =
Hard Tasks First: Multi-Task Reinforcement Learning Through Task Scheduling , author =. International Conference on Machine Learning , pages =. 2024 , volume =
2024
-
[11]
Journal of Machine Learning Research , year =
Alexander Fabisch and Jan Hendrik Metzen , title =. Journal of Machine Learning Research , year =
-
[12]
International Conference on Learning Representations , year=
Learning to Multi-Task by Active Sampling , author=. International Conference on Learning Representations , year=
-
[13]
Discounted
Kocsis, Levente and Szepesvári, Csaba , booktitle =. Discounted
-
[14]
International Conference on Algorithmic Learning Theory , year = 2011, pages =
On Upper-Confidence Bound Policies for Switching Bandit Problems , author =. International Conference on Algorithmic Learning Theory , year = 2011, pages =
2011
-
[15]
Contextualize Me
Carolin Benjamins and Theresa Eimer and Frederik Schubert and Aditya Mohan and Sebastian D. Contextualize Me. EWRL , year=
-
[16]
Contextual Markov Decision Processes
Assaf Hallak and Dotan Di Castro and Shie Mannor , year=. Contextual. CoRR , volume=. 1502.02259 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Hafner, Danijar and Pasukonis, Jurgis and Ba, Jimmy and Lillicrap, Timothy , title =. Nature , pages =. doi:10.1038/s41586-025-08744-2 , year =
-
[18]
2024 , url=
Nicklas Hansen and Hao Su and Xiaolong Wang , booktitle=. 2024 , url=
2024
-
[19]
Deep Reinforcement Learning at the Edge of the Statistical Precipice , url =
Agarwal, Rishabh and Schwarzer, Max and Castro, Pablo Samuel and Courville, Aaron C and Bellemare, Marc , booktitle =. Deep Reinforcement Learning at the Edge of the Statistical Precipice , url =
-
[20]
International Conference on Machine Learning , year=
Hyperspherical Normalization for Scalable Deep Reinforcement Learning , author=. International Conference on Machine Learning , year=
-
[21]
Bigger, Regularized, Optimistic: scaling for compute and sample efficient continuous control , url =
Nauman, Michal and Ostaszewski, Mateusz and Jankowski, Krzysztof and Mi o\'. Bigger, Regularized, Optimistic: scaling for compute and sample efficient continuous control , url =. Advances in Neural Information Processing Systems , pages =
-
[22]
International Conference on Learning Representations , year=
CrossQ: Batch Normalization in Deep Reinforcement Learning for Greater Sample Efficiency and Simplicity , author=. International Conference on Learning Representations , year=
-
[23]
Takuya Hiraoka and Takahisa Imagawa and Taisei Hashimoto and Takashi Onishi and Yoshimasa Tsuruoka , booktitle=. Dropout. 2022 , url=
2022
-
[24]
International Conference on Learning Representations , year=
Towards General-Purpose Model-Free Reinforcement Learning , author=. International Conference on Learning Representations , year=
-
[25]
For SALE: State-Action Representation Learning for Deep Reinforcement Learning , url =
Fujimoto, Scott and Chang, Wei-Di and Smith, Edward and Gu, Shixiang (Shane) and Precup, Doina and Meger, David , booktitle =. For SALE: State-Action Representation Learning for Deep Reinforcement Learning , url =
-
[26]
An Equivalence between Loss Functions and Non-Uniform Sampling in Experience Replay , url =
Fujimoto, Scott and Meger, David and Precup, Doina , booktitle =. An Equivalence between Loss Functions and Non-Uniform Sampling in Experience Replay , url =
-
[27]
International Conference on Machine Learning , pages =
Addressing Function Approximation Error in Actor-Critic Methods , author =. International Conference on Machine Learning , pages =. 2018 , volume =
2018
-
[28]
Towers, Mark and Kwiatkowski, Ariel and Terry, Jordan and Balis, John U. and Cola, Gianluca De and Deleu, Tristan and Goulão, Manuel and Kallinteris, Andreas and Krimmel, Markus and KG, Arjun and Perez-Vicente, Rodrigo and Pierré, Andrea and Schulhoff, Sander and Tai, Jun Jet and Tan, Hannah and Younis, Omar G. , year =. Gymnasium: A Standard Interface fo...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.17032
-
[29]
Towers, Mark and Kwiatkowski, Ariel and Terry, Jordan K and Balis, John U. and de Cola, Gianluca and Deleu, Tristan and Goulão, Manuel and Kallinteris, Andreas and Krimmel, Markus and KG, Arjun and Perez-Vicente, Rodrigo and Pierré, Andrea and Schulhoff, Sander and Tai, Jun Jet and Tan, Hannah Jin Shen and Younis, Omar G. , month =. Gymnasium: A Standard ...
-
[30]
and Calandra, Roberto , month =
Pineda, Luis and Amos, Brandon and Zhang, Amy and Lambert, Nathan O. and Calandra, Roberto , month =. MBRL-Lib: A Modular Library for Model-based Reinforcement Learning , shorttitle =. 2021 , note =. doi:10.48550/arXiv.2104.10159 , abstract =
-
[31]
RLlib: Abstractions for Distributed Reinforcement Learning , shorttitle =
Liang, Eric and Liaw, Richard and Nishihara, Robert and Moritz, Philipp and Fox, Roy and Goldberg, Ken and Gonzalez, Joseph and Jordan, Michael and Stoica, Ion , month =. RLlib: Abstractions for Distributed Reinforcement Learning , shorttitle =. International Conference on Machine Learning , publisher =. 2018 , note =
2018
-
[32]
Journal of Machine Learning Research , author =
Stable-Baselines3: Reliable Reinforcement Learning Implementations , volume =. Journal of Machine Learning Research , author =. 2021 , pages =
2021
-
[33]
and Potter, Donald K
Orwat, Joseph C. and Potter, Donald K. , year =. Application of the Extended Kalman Filter to Ballistic Trajectory Estimation and Prediction , url =
-
[34]
Journal of Aerospace Information Systems , author =
Bridging Reinforcement Learning and Online Learning for Spacecraft Attitude Control , volume =. Journal of Aerospace Information Systems , author =. 2021 , pages =. doi:10.2514/1.I010958 , number =
-
[35]
A Survey on Design and Control of Lower Extremity Exoskeletons for Bipedal Walking , volume =. Applied Sciences , author =. 2022 , file =. doi:10.3390/app12052395 , number =
-
[36]
International Conference on Neural Information Processing Systems , author =
Deep reinforcement learning in a handful of trials using probabilistic dynamics models , url =. International Conference on Neural Information Processing Systems , author =. 2018 , pages =
2018
-
[37]
Journal of LatinX in AI (LXAI) Research , author =
Terrain Classification Enhanced with Uncertainty for Space Exploration Robots from Proprioceptive Data , volume =. Journal of LatinX in AI (LXAI) Research , author =. 2023 , file =
2023
-
[38]
A New Extension of the Kalman Filter to Nonlinear Systems , doi =
Julier, Simon J and Uhlmann, Jeffrey K , year =. A New Extension of the Kalman Filter to Nonlinear Systems , doi =
-
[39]
International Conference on Machine Learning , author =
Learning Latent Dynamics for Planning from Pixels , abstract =. International Conference on Machine Learning , author =. 2019 , file =
2019
-
[40]
International Conference on Machine Learning , author =
BOHB: Robust and Efficient Hyperparameter Optimization at Scale , abstract =. International Conference on Machine Learning , author =. 2018 , file =
2018
-
[41]
Journal of Machine Learning Research , author =
Active Contextual Policy Search , volume =. Journal of Machine Learning Research , author =. 2014 , pages =
2014
-
[42]
Xiao, Bing and Zhang, Haichao and Chen, Zhaoyue and Cao, Lu , year =. Fixed-Time Fault-Tolerant Optimal Attitude Control of Spacecraft With Performance Constraint via Reinforcement Learning , journal=. doi:10.1109/TAES.2023.3292809 , number =
-
[43]
International Conference on Hybrid Systems: Computation and Control , author =
A few lessons learned in reinforcement learning for quadcopter attitude control , doi =. International Conference on Hybrid Systems: Computation and Control , author =
-
[44]
International Conference on Neural Information Processing Systems , author =
When to trust your model: model-based policy optimization , url =. International Conference on Neural Information Processing Systems , author =. 2019 , file =
2019
-
[45]
RIANN-A Robust Neural Network Outperforms Attitude Estimation Filters , volume =. AI , author =. 2021 , pages =. doi:10.3390/ai2030028 , number =
-
[46]
Industrial Robot: the international journal of robotics research and application , author =
Model-based deep reinforcement learning with heuristic search for satellite attitude control , volume =. Industrial Robot: the international journal of robotics research and application , author =. 2018 , note =. doi:10.1108/IR-05-2018-0086 , abstract =
-
[47]
IEEE Transactions on Control Systems Technology , author =
Reinforcement Learning-Based Approximate Optimal Control for Attitude Reorientation Under State Constraints , volume =. IEEE Transactions on Control Systems Technology , author =. 2021 , note =. doi:10.1109/TCST.2020.3007401 , abstract =
-
[48]
IEEE Transactions on Neural Networks and Learning Systems , author =
Data-Efficient Deep Reinforcement Learning for Attitude Control of Fixed-Wing. IEEE Transactions on Neural Networks and Learning Systems , author =. 2024 , pages =. doi:10.1109/TNNLS.2023.3263430 , number =
-
[49]
Bernini, Nicola and Bessa, Mikhail and Delmas, Rémi and Gold, Arthur and Goubault, Eric and Pennec, Romain and Putot, Sylvie and Sillion, François , year =. Reinforcement learning with formal performance metrics for quadcopter attitude control under non-nominal contexts , volume =. doi:10.1016/j.engappai.2023.107090 , journal =
-
[50]
Solar Orbiter fine pointing Mode improvement in flight: Challenges and achievements , volume =. Acta Astronautica , author =. 2023 , keywords =. doi:10.1016/j.actaastro.2023.09.016 , abstract =
-
[51]
A survey on modularity and distributivity in series-parallel hybrid robots , volume =. Mechatronics , author =. 2020 , keywords =. doi:10.1016/j.mechatronics.2020.102367 , abstract =
-
[52]
A Survey of Behavior Learning Applications in Robotics -- State of the Art and Perspectives , url =
Fabisch, Alexander and Petzoldt, Christoph and Otto, Marc and Kirchner, Frank , month =. A Survey of Behavior Learning Applications in Robotics -- State of the Art and Perspectives , url =. 2024 , note =. doi:10.48550/arXiv.1906.01868 , abstract =
-
[53]
Addressing Function Approximation Error in Actor-Critic Methods
Fujimoto, Scott and Hoof, Herke van and Meger, David , month =. Addressing Function Approximation Error in Actor -Critic Methods , url =. 2018 , note =. doi:10.48550/arXiv.1802.09477 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1802.09477 2018
-
[54]
International Conference on Machine Learning , pages =
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor , author =. International Conference on Machine Learning , pages =. 2018 , volume =
2018
-
[55]
Proximal Policy Optimization Algorithms
Schulman, John and Wolski, Filip and Dhariwal, Prafulla and Radford, Alec and Klimov, Oleg , month =. Proximal Policy Optimization Algorithms , url =. 2017 , note =. doi:10.48550/arXiv.1707.06347 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1707.06347 2017
-
[56]
IEEE Transactions on Instrumentation and Measurement , author =
Deep-Learning -Based Neural Network Training for State Estimation Enhancement: Application to Attitude Estimation , volume =. IEEE Transactions on Instrumentation and Measurement , author =. 2020 , note =. doi:10.1109/TIM.2019.2895495 , abstract =
-
[57]
In: 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
Deep Adversarial Reinforcement Learning for Object Disentangling , url =. 2020 IEEE RSJ International Conference on Intelligent Robots and Systems (IROS) , author =. 2020 , note =. doi:10.1109/IROS45743.2020.9341578 , abstract =
-
[58]
Grasping 3D Deformable Objects via Reinforcement Learning: A Benchmark and Evaluation , url =
Laux, Melvin and Singh, Chandandeep and Fabisch, Alexander , year =. Grasping 3D Deformable Objects via Reinforcement Learning: A Benchmark and Evaluation , url =
-
[59]
2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , author =
Learning Deep Features for Discriminative Localization , url =. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , author =. 2016 , note =. doi:10.1109/CVPR.2016.319 , abstract =
-
[60]
and Lee, Su-In , month =
Lundberg, Scott M. and Lee, Su-In , month =. A unified approach to interpreting model predictions , isbn =. International Conference on Neural Information Processing Systems , publisher =. 2017 , pages =
2017
-
[61]
Learning Deep Features for Discriminative Localization
Zhou, Bolei and Khosla, Aditya and Lapedriza, Agata and Oliva, Aude and Torralba, Antonio , month =. Learning Deep Features for Discriminative Localization , url =. 2015 , note =. doi:10.48550/arXiv.1512.04150 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1512.04150 2015
-
[62]
International Journal of Computer Vision , author =
Grad-CAM: Visual Explanations from Deep Networks via Gradient -Based Localization , volume =. International Journal of Computer Vision , author =. 2020 , keywords =. doi:10.1007/s11263-019-01228-7 , abstract =
-
[63]
Perturbation-Based Explanations of Prediction Models , isbn =
Robnik-Šikonja, Marko and Bohanec, Marko , editor =. Perturbation-Based Explanations of Prediction Models , isbn =. Human and Machine Learning: Visible, Explainable, Trustworthy and Transparent , publisher =. 2018 , doi =
2018
-
[64]
2019 14th IEEE International Conference on Electronic Measurement & Instruments (ICEMI) , author =
Attitude estimation based on recurrent neural network and vector observations for attitude and heading reference system , url =. 2019 14th IEEE International Conference on Electronic Measurement & Instruments (ICEMI) , author =. 2019 , keywords =. doi:10.1109/ICEMI46757.2019.9101833 , abstract =
-
[65]
Physics-informed neural ODE (PINODE): embedding physics into models using collocation points , volume =. Scientific Reports , author =. 2023 , note =. doi:10.1038/s41598-023-36799-6 , language =
-
[66]
IEEE Aerospace and Electronic Systems Magazine , author =
On Computational Complexity Reduction Methods for Kalman Filter Extensions , volume =. IEEE Aerospace and Electronic Systems Magazine , author =. 2019 , note =. doi:10.1109/MAES.2019.2927898 , abstract =
-
[67]
Ozaki, Yoshihiko and Tanigaki, Yuki and Watanabe, Shuhei and Onishi, Masaki , month =. Multiobjective tree-structured parzen estimator for computationally expensive optimization problems , isbn =. Genetic and Evolutionary Computation Conference , publisher =. 2020 , pages =. doi:10.1145/3377930.3389817 , abstract =
-
[68]
Unscented Kalman Filter-Trained Neural Networks for Slip Model Prediction , volume =. PLOS ONE , author =. 2016 , note =. doi:10.1371/journal.pone.0158492 , abstract =
-
[69]
How to train your differentiable filter , volume =. Autonomous Robots , author =. 2021 , keywords =. doi:10.1007/s10514-021-09990-9 , abstract =
-
[70]
IFAC Proceedings Volumes , author =
NEURAL NETWORK AUGMENTATION OF ATTITUDE ESTIMATION USING NAVIGATION SATELLITE SIGNAL PHASE , volume =. IFAC Proceedings Volumes , author =. 2007 , keywords =. doi:10.3182/20070829-3-RU-4911.00059 , abstract =
-
[71]
Accelerating neuroevolutionary methods using a Kalman filter , isbn =
Kassahun, Yohannes and de Gea, Jose and Edgington, Mark and Metzen, Jan Hendrik and Kirchner, Frank , month =. Accelerating neuroevolutionary methods using a Kalman filter , isbn =. Annual Conference on Genetic and Evolutionary Computation , publisher =. 2008 , pages =. doi:10.1145/1389095.1389365 , abstract =
-
[72]
Nature Reviews Physics , author =
Physics-informed machine learning , volume =. Nature Reviews Physics , author =. 2021 , note =. doi:10.1038/s42254-021-00314-5 , abstract =
-
[73]
Differentiable Particle Filters: End-to-End Learning with Algorithmic Priors , isbn =
Jonschkowski, Rico and Rastogi, Divyam and Brock, Oliver , month =. Differentiable Particle Filters: End-to-End Learning with Algorithmic Priors , isbn =. Robotics: Science and Systems XIV , publisher =. 2018 , file =. doi:10.15607/RSS.2018.XIV.001 , abstract =
-
[74]
2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC) , author =
Physics Informed Deep Learning for Traffic State Estimation , url =. 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC) , author =. 2020 , keywords =. doi:10.1109/ITSC45102.2020.9294236 , abstract =
-
[75]
IEEE Transactions on Automatic Control , author =
Cubature Kalman Filters , volume =. IEEE Transactions on Automatic Control , author =. 2009 , pages =. doi:10.1109/TAC.2009.2019800 , number =
-
[76]
Learning in compressed space , volume =. Neural Networks , author =. 2013 , keywords =. doi:10.1016/j.neunet.2013.01.020 , abstract =
-
[77]
AN APPROACH TO TARGET TRACKING , shorttitle =
Gruber, Michael , month =. AN APPROACH TO TARGET TRACKING , shorttitle =. 1967 , doi =
1967
-
[78]
ISPRS Journal of Photogrammetry and Remote Sensing , author =
HE2LM -AD: Hierarchical and efficient attitude determination framework with adaptive error compensation module based on ELM network , volume =. ISPRS Journal of Photogrammetry and Remote Sensing , author =. 2023 , keywords =. doi:10.1016/j.isprsjprs.2022.12.010 , abstract =
-
[79]
IEEE Transactions on Circuits and Systems I: Regular Papers , author =
Multi-Objective Surrogate-Model-Based Neural Architecture and Physical Design Co-Optimization of Energy Efficient Neural Network Hardware Accelerators , volume =. IEEE Transactions on Circuits and Systems I: Regular Papers , author =. 2023 , note =. doi:10.1109/TCSI.2022.3209574 , abstract =
-
[80]
PerSim: Perception for Planetary Prospection and Internal Simulation , url =
Domínguez, Raúl and De Lucas Alvarez, Mariela and Kadwe, Siddhant and Shette, Siddhant and Herztberg, Christoph and Cedric Danter, Leon and Jankovik, Marko and Vyas, Shubham and Eisenmenger, Jonas and Willenbrock, Pierre and Felmet, André and Unnithan, Vikram and Kirchner, Frank , month =. PerSim: Perception for Planetary Prospection and Internal Simulati...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.