Factored Diffusion Policies:Compositionally Generalized Robot Control with a Single Score Network
Pith reviewed 2026-05-22 06:58 UTC · model grok-4.3
The pith
A single shared diffusion network with per-factor null-token dropout composes scores additively to generalize robot control to unseen factor combinations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under approximate conditional independence between factors given the action-observation pair, the additive composition of per-factor scores from a single shared diffusion network approximates the true joint score with a bounded uniform error. This reduces the training-task requirement from the product of factor cardinalities to their sum. A trajectory-tube certificate chains the score-level bound through the reverse-time sampling ODE and a contracting tracking controller to certify a closed-loop state-trajectory tube whose radius factors into an ODE-sensitivity constant and a per-factor score-error budget.
What carries the argument
Additive score decomposition from a single network trained with per-factor null-token dropout, certified by chaining the uniform score error bound through the reverse diffusion ODE and contracting controller into a trajectory tube.
If this is right
- The number of training demonstrations needed grows linearly with the number of factor values rather than combinatorially.
- The policy succeeds on combinations of factors never seen together during training.
- Trajectory deviation remains explicitly bounded by the per-factor score error and the contraction rate of the tracking controller.
- A single network suffices instead of training and combining separate networks for each factor.
Where Pith is reading between the lines
- The same null-token dropout and additive composition technique could be tested on other score-based or generative models for control.
- Collecting data to directly measure conditional dependence among factors would provide a practical check on when the error bound holds.
- The tube certificate could be adapted to different controller designs provided their contraction properties are quantified.
Load-bearing premise
The task factors are approximately conditionally independent given the current action and observation.
What would settle it
Compare the composed score against the score of a jointly trained network on held-out factor combinations and check whether the observed uniform error stays within the derived bound; also verify whether closed-loop trajectories remain inside the certified tube radius on physical drone tests.
Figures



read the original abstract
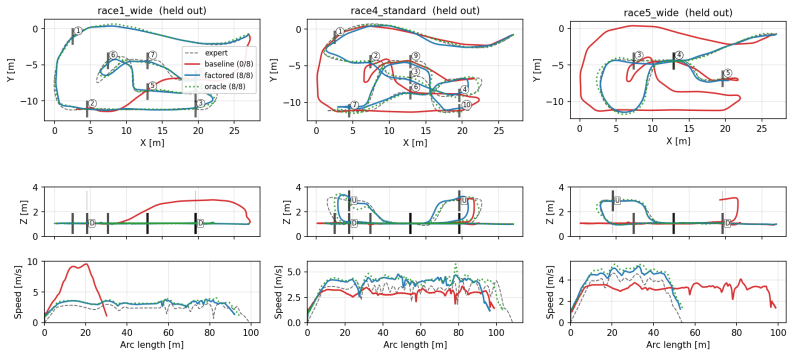
Robotic tasks are typically specified by a tuple of factors, such as the object to be grasped, the obstacles to be avoided, the color of the target, and so on. Collecting expert demonstrations for every combination of factor values grows combinatorially. We present factored diffusion policies: a single shared diffusion network trained with per-factor null-token dropout, whose score decomposes additively across factors at inference. Under approximate conditional independence between factors given the action-observation pair, this composition approximates the true joint score with a bounded uniform error, reducing the training-task budget from a product of factor cardinalities to a sum. A trajectory-tube certificate chains this score-level bound through the reverse-time sampling ODE and a contracting tracking controller into a closed-loop state-trajectory tube whose radius factors into an ODE-sensitivity constant and a per-factor score-error budget. Unlike compositional-diffusion methods for control that combine separately trained networks, we use one shared network. Drone racing experiments confirm both the generalization bound and the certificate. On state-based multi-gate racing, the factored policy passes 90% of held-out gates -- matching an oracle -- while a K-network composition baseline collapses to 3%; on vision-based single-gate traversal, it transfers zero-shot to an unseen venue with +11.7pp success-rate gain and 2.4X crash-rate reduction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces factored diffusion policies for compositional robot control: a single shared score network is trained via per-factor null-token dropout so that, at inference, the joint score is approximated by an additive sum over per-factor scores. Under an approximate conditional-independence assumption between factors given the action-observation pair, the composition incurs a bounded uniform error; this reduces the required training-task budget from a product to a sum of factor cardinalities. The authors derive a trajectory-tube certificate that propagates the score-level error through the reverse-time diffusion ODE and a contracting tracking controller to obtain a closed-loop state-trajectory guarantee whose radius factors into an ODE-sensitivity constant and a per-factor error budget. Drone-racing experiments (state-based multi-gate and vision-based single-gate) report strong generalization, with the factored policy achieving 90 % success on held-out gates (matching an oracle) versus 3 % for a K-network baseline, plus zero-shot transfer gains on an unseen venue.
Significance. If the error bound and certificate are valid, the work supplies a practical, single-network route to compositional generalization in diffusion policies that materially lowers the combinatorial data-collection cost for multi-factor robotic tasks while furnishing an explicit closed-loop safety certificate. The empirical margins on drone racing are substantial and directly support the claimed product-to-sum reduction.
major comments (1)
- [Error-bound derivation and experimental validation sections] The uniform error bound on additive score composition (and therefore the entire trajectory-tube certificate) rests on the unquantified approximate conditional-independence assumption between factors given the action-observation pair. The manuscript reports no measurement of residual factor dependence (conditional mutual information, correlation after conditioning, etc.) for either the multi-gate or vision-based tasks, nor does it supply an explicit functional dependence of the bound on the strength of dependence. Consequently it is unclear whether the realized score deviation remains inside the per-factor budget allocated to ODE sensitivity and the contracting controller.
minor comments (2)
- [Experiments] In the experimental tables, explicitly state the exact number of training factor combinations used for the factored policy versus each baseline so that the claimed data-efficiency gain is numerically transparent.
- [Notation and preliminaries] Ensure that the notation for the per-factor score functions, the joint score, and the error terms is introduced once and used consistently in both the main text and the appendix.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the error-bound derivation. We address the concern point-by-point below and will revise the manuscript to strengthen the validation of the approximate conditional-independence assumption.
read point-by-point responses
-
Referee: [Error-bound derivation and experimental validation sections] The uniform error bound on additive score composition (and therefore the entire trajectory-tube certificate) rests on the unquantified approximate conditional-independence assumption between factors given the action-observation pair. The manuscript reports no measurement of residual factor dependence (conditional mutual information, correlation after conditioning, etc.) for either the multi-gate or vision-based tasks, nor does it supply an explicit functional dependence of the bound on the strength of dependence. Consequently it is unclear whether the realized score deviation remains inside the per-factor budget allocated to ODE sensitivity and the contracting controller.
Authors: We agree that an explicit quantification of residual factor dependence and its effect on the bound would improve the manuscript. In the revision we will (i) compute and report conditional mutual information (and pairwise correlations after conditioning on the action-observation pair) for the factors in both the state-based multi-gate and vision-based single-gate experiments, and (ii) derive and state the explicit functional dependence of the uniform score error on the strength of the conditional dependence (i.e., how the bound scales with the deviation from exact independence). These additions will confirm that the observed score deviation lies inside the per-factor budget used for the ODE-sensitivity and controller contraction constants. revision: yes
Circularity Check
No significant circularity; derivation follows from stated assumption and standard properties
full rationale
The paper states the approximate conditional independence assumption explicitly and derives the uniform error bound on additive score composition from it, then chains the bound through the reverse-time sampling ODE and contracting controller using standard sensitivity and contraction arguments. No equation reduces a claimed prediction or first-principles result to a fitted quantity or prior self-citation by construction. The training-budget reduction and trajectory-tube certificate are consequences of the given assumption plus diffusion and control theory, with no self-definitional loop or renamed fitted input visible in the derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Approximate conditional independence between factors given the action-observation pair
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Under approximate conditional independence between factors given the action-observation pair, this composition approximates the true joint score with a bounded uniform error... Theorem 1 (Decomposition error bound) ... ∥s−scomp∥≤2√GM
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
A trajectory-tube certificate chains this score-level bound through the reverse-time sampling ODE and a contracting tracking controller
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
A L yapunov approach to incremental stability properties
David Angeli. A L yapunov approach to incremental stability properties. IEEE Transactions on Automatic Control, 47 0 (3): 0 410--421, 2002
work page 2002
-
[3]
Nearly d -linear convergence bounds for diffusion models via stochastic localization
Joe Benton, Valentin De Bortoli, Arnaud Doucet, and George Deligiannidis. Nearly d -linear convergence bounds for diffusion models via stochastic localization. In International Conference on Learning Representations (ICLR), 2024
work page 2024
-
[4]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. _0 : A vision-language-action flow model for general robot control. arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Yongyuan Cao et al. Compose your policies! improving diffusion-based or flow-based robot policies via test-time distribution-level composition. In International Conference on Learning Representations (ICLR), 2026. To appear
work page 2026
-
[7]
Sitan Chen, Sinho Chewi, Jerry Li, Yuanzhi Li, Adil Salim, and Anru R. Zhang. Sampling is as easy as learning the score: Theory for diffusion models with minimal data assumptions. In International Conference on Learning Representations (ICLR), 2023
work page 2023
-
[8]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Siyuan Feng, Yilun Du, Zhenjia Xu, Eric Cousineau, Benjamin Burchfiel, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. In Robotics: Science and Systems (RSS), 2023
work page 2023
-
[9]
Tenenbaum, Sander Dieleman, Rob Fergus, Jascha Sohl-Dickstein, Arnaud Doucet, and Will Grathwohl
Yilun Du, Conor Durkan, Robin Strudel, Joshua B. Tenenbaum, Sander Dieleman, Rob Fergus, Jascha Sohl-Dickstein, Arnaud Doucet, and Will Grathwohl. Reduce, reuse, recycle: Compositional generation with energy-based diffusion models and MCMC . In International Conference on Machine Learning (ICML), 2023
work page 2023
-
[10]
Michael Everett, Golnaz Habibi, Chuangchuang Sun, and Jonathan P. How. Reachability analysis of neural feedback loops. IEEE Access, 9: 0 163938--163953, 2021
work page 2021
-
[11]
Locally optimal reach set over-approximation for nonlinear systems
Chuchu Fan, James Kapinski, Xiaoqing Jin, and Sayan Mitra. Locally optimal reach set over-approximation for nonlinear systems. In Proceedings of the 13th ACM-SIGBED International Conference on Embedded Software (EMSOFT), EMSOFT '16, pages 6:1--6:10, New York, NY, USA, 2016. ACM. URL http://doi.acm.org/10.1145/2968478.2968482. Nominated for best paper award
-
[12]
Mahyar Fazlyab, Alexander Robey, Hamed Hassani, Manfred Morari, and George J. Pappas. Efficient and accurate estimation of lipschitz constants for deep neural networks. Curran Associates Inc., Red Hook, NY, USA, 2019
work page 2019
-
[13]
Time-optimal planning for quadrotor waypoint flight
Philipp Foehn, Angel Romero, and Davide Scaramuzza. Time-optimal planning for quadrotor waypoint flight. Science Robotics, 6 0 (56), 2021
work page 2021
-
[14]
Classifier-free diffusion guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. In NeurIPS Workshop on Deep Generative Models and Downstream Applications, 2022
work page 2022
-
[15]
Compositional perception contracts for verified autonomy
Yifei Ji et al. Compositional perception contracts for verified autonomy. arXiv preprint, 2025
work page 2025
-
[16]
Champion-level drone racing using deep reinforcement learning
Elia Kaufmann, Leonard Bauersfeld, Antonio Loquercio, Matthias M \"u ller, Vladlen Koltun, and Davide Scaramuzza. Champion-level drone racing using deep reinforcement learning. Nature, 620: 0 982--987, 2023
work page 2023
-
[17]
Taeyoung Lee, Melvin Leok, and N. Harris McClamroch. Geometric tracking control of a quadrotor UAV on SE(3) . In IEEE Conference on Decision and Control (CDC), 2010
work page 2010
-
[18]
Zhixuan Liang, Yao Mu, Hengbo Ma, Masayoshi Tomizuka, Mingyu Ding, and Ping Luo. SkillDiffuser : Interpretable hierarchical planning via skill abstractions in diffusion-based task execution. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
work page 2024
- [20]
-
[21]
Winfried Lohmiller and Jean-Jacques E. Slotine. On contraction analysis for non-linear systems. Automatica, 34 0 (6): 0 683--696, 1998
work page 1998
-
[23]
Mishra, Shangjie Xue, Yongxin Chen, and Danfei Xu
Utkarsh A. Mishra, Shangjie Xue, Yongxin Chen, and Danfei Xu. Generative skill chaining: Long-horizon skill planning with diffusion models. In Conference on Robot Learning (CoRL), 2023
work page 2023
-
[24]
CoInD : Enabling logical compositions in diffusion models
Sachit Pal et al. CoInD : Enabling logical compositions in diffusion models. arXiv preprint, 2024. Please verify exact author list, arXiv ID, and venue
work page 2024
-
[25]
Multimodal diffusion transformer: Learning versatile behavior from multimodal goals
Moritz Reuss, \"O mer Erdin c Yagmurlu, Fabian Wenzel, and Rudolf Lioutikov. Multimodal diffusion transformer: Learning versatile behavior from multimodal goals. In Robotics: Science and Systems (RSS), 2024
work page 2024
-
[26]
CAD ^2 RL : Real single-image flight without a single real image
Fereshteh Sadeghi and Sergey Levine. CAD ^2 RL : Real single-image flight without a single real image. In Robotics: Science and Systems (RSS), 2017
work page 2017
-
[27]
Denoising diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. In International Conference on Learning Representations (ICLR), 2021 a
work page 2021
-
[28]
Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole
Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. In International Conference on Learning Representations (ICLR), 2021 b
work page 2021
-
[29]
Reaching the limit in autonomous racing: Optimal control versus reinforcement learning
Yunlong Song, Angel Romero, Matthias M \"u ller, Vladlen Koltun, and Davide Scaramuzza. Reaching the limit in autonomous racing: Optimal control versus reinforcement learning. Science Robotics, 8 0 (82), 2023
work page 2023
-
[30]
Domain randomization for transferring deep neural networks from simulation to the real world
Joshua Tobin, Rachel Fong, Alex Ray, Jonas Schneider, Wojciech Zaremba, and Pieter Abbeel. Domain randomization for transferring deep neural networks from simulation to the real world. In IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2017
work page 2017
-
[31]
Lirui Wang, Jialiang Zhao, Yilun Du, Edward H. Adelson, and Russ Tedrake. PoCo : Policy composition from and for heterogeneous robot learning. In Robotics: Science and Systems (RSS), 2024
work page 2024
-
[32]
Concept algebra for (score-based) text-controlled generative models
Zihao Wang, Lin Gui, Jeffrey Negrea, and Victor Veitch. Concept algebra for (score-based) text-controlled generative models. In Advances in Neural Information Processing Systems (NeurIPS), 2023
work page 2023
-
[33]
3D diffusion policy: Generalizable visuomotor policy learning via simple 3D representations
Yanjie Ze, Gu Zhang, Kangning Zhang, Chenyuan Hu, Muhan Wang, and Huazhe Xu. 3D diffusion policy: Generalizable visuomotor policy learning via simple 3D representations. In Robotics: Science and Systems (RSS), 2024
work page 2024
-
[34]
Robotics: Science and Systems (RSS) , year =
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion , author =. Robotics: Science and Systems (RSS) , year =
-
[35]
Robotics: Science and Systems (RSS) , year =
Multimodal Diffusion Transformer: Learning Versatile Behavior from Multimodal Goals , author =. Robotics: Science and Systems (RSS) , year =
-
[36]
Ze, Yanjie and Zhang, Gu and Zhang, Kangning and Hu, Chenyuan and Wang, Muhan and Xu, Huazhe , booktitle =
-
[37]
Black, Kevin and Brown, Noah and Driess, Danny and Esmail, Adnan and Equi, Michael and Finn, Chelsea and Fusai, Niccolo and Groom, Lachy and Hausman, Karol and Ichter, Brian and others , journal =
-
[38]
European Conference on Computer Vision (ECCV) , year =
Compositional Visual Generation with Composable Diffusion Models , author =. European Conference on Computer Vision (ECCV) , year =
-
[39]
Du, Yilun and Durkan, Conor and Strudel, Robin and Tenenbaum, Joshua B. and Dieleman, Sander and Fergus, Rob and Sohl-Dickstein, Jascha and Doucet, Arnaud and Grathwohl, Will , booktitle =. Reduce, Reuse, Recycle: Compositional Generation with Energy-Based Diffusion Models and
-
[40]
NeurIPS Workshop on Deep Generative Models and Downstream Applications , year =
Classifier-Free Diffusion Guidance , author =. NeurIPS Workshop on Deep Generative Models and Downstream Applications , year =
-
[41]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Concept Algebra for (Score-Based) Text-Controlled Generative Models , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[42]
and Tedrake, Russ , booktitle =
Wang, Lirui and Zhao, Jialiang and Du, Yilun and Adelson, Edward H. and Tedrake, Russ , booktitle =
-
[43]
International Conference on Learning Representations (ICLR) , year =
Compose Your Policies! Improving Diffusion-based or Flow-based Robot Policies via Test-time Distribution-level Composition , author =. International Conference on Learning Representations (ICLR) , year =
-
[44]
Flexible Multitask Learning with Factorized Diffusion Policy
Flexible Multitask Learning with Factorized Diffusion Policy , author =. arXiv preprint arXiv:2512.21898 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[45]
arXiv preprint arXiv:2503.12466 , year =
Modality-Composable Diffusion Policy via Inference-Time Distribution-level Composition , author =. arXiv preprint arXiv:2503.12466 , year =
-
[46]
arXiv preprint 2410.17479v1 , year =
Composing Diffusion Policies for Few-Shot Learning of Trajectory Generation in Autonomous Racing , author =. arXiv preprint 2410.17479v1 , year =
-
[47]
International Conference on Learning Representations (ICLR) , year =
Denoising Diffusion Implicit Models , author =. International Conference on Learning Representations (ICLR) , year =
-
[48]
International Conference on Learning Representations (ICLR) , year =
Score-Based Generative Modeling through Stochastic Differential Equations , author =. International Conference on Learning Representations (ICLR) , year =
-
[49]
International Conference on Learning Representations (ICLR) , year =
Sampling is as Easy as Learning the Score: Theory for Diffusion Models with Minimal Data Assumptions , author =. International Conference on Learning Representations (ICLR) , year =
-
[50]
International Conference on Learning Representations (ICLR) , year =
Nearly d -Linear Convergence Bounds for Diffusion Models via Stochastic Localization , author =. International Conference on Learning Representations (ICLR) , year =
- [51]
-
[52]
Reachability Analysis of Neural Feedback Loops , author =. IEEE Access , volume =
-
[53]
Astorga, Angello and Hsieh, Chiao and Madhusudan, P. and Mitra, Sayan , title =. Proc. ACM Program. Lang. , month = oct, articleno =. 2023 , issue_date =. doi:10.1145/3622875 , abstract =
-
[54]
Compositional Perception Contracts for Verified Autonomy , author =. arXiv preprint , year =
-
[55]
Liang, Zhixuan and Mu, Yao and Ma, Hengbo and Tomizuka, Masayoshi and Ding, Mingyu and Luo, Ping , booktitle =
-
[56]
Conference on Robot Learning (CoRL) , year =
Generative Skill Chaining: Long-Horizon Skill Planning with Diffusion Models , author =. Conference on Robot Learning (CoRL) , year =
-
[57]
Champion-Level Drone Racing Using Deep Reinforcement Learning , author =. Nature , volume =
-
[58]
Reaching the Limit in Autonomous Racing: Optimal Control versus Reinforcement Learning , author =. Science Robotics , volume =
-
[59]
Time-Optimal Planning for Quadrotor Waypoint Flight , author =. Science Robotics , volume =
-
[60]
IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , year =
Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World , author =. IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , year =
-
[61]
Sadeghi, Fereshteh and Levine, Sergey , booktitle =
-
[62]
Lee, Taeyoung and Leok, Melvin and McClamroch, N. Harris , booktitle =. Geometric Tracking Control of a Quadrotor
-
[63]
On Contraction Analysis for Non-linear Systems , author =. Automatica , volume =
-
[64]
Angeli, David , journal =. A
-
[65]
IEEE Transactions on Automatic Control , volume =
Smooth Stabilization Implies Coprime Factorization , author =. IEEE Transactions on Automatic Control , volume =
-
[66]
Proceedings of the 13th ACM-SIGBED International Conference on Embedded Software (EMSOFT) , year =
Fan, Chuchu and Kapinski, James and Jin, Xiaoqing and Mitra, Sayan , title =. Proceedings of the 13th ACM-SIGBED International Conference on Embedded Software (EMSOFT) , year =
-
[67]
Transactions on Machine Learning Research (TMLR) , year =
Oquab, Maxime and Darcet, Timoth. Transactions on Machine Learning Research (TMLR) , year =
- [68]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.