Learning to Throw: Agile and Accurate Cable-Suspended Payload Delivery with a Quadrotor
Pith reviewed 2026-06-29 01:06 UTC · model grok-4.3
The pith
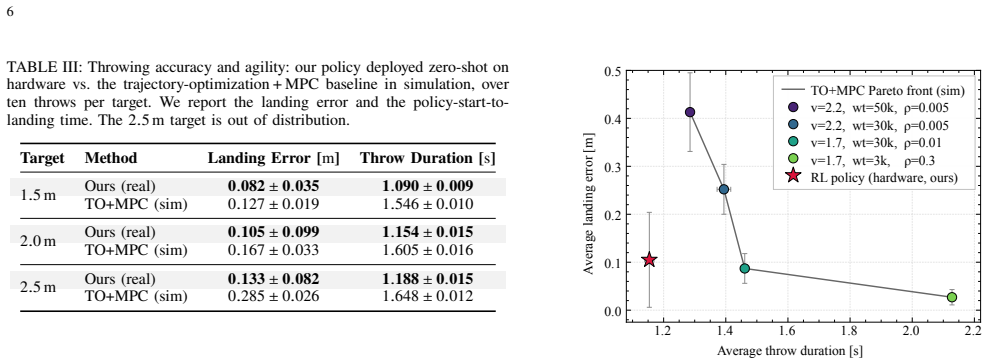
A reinforcement learning policy trained in hybrid simulation throws quadrotor payloads with up to 50 percent less error and 30 percent shorter time than model-based approaches.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
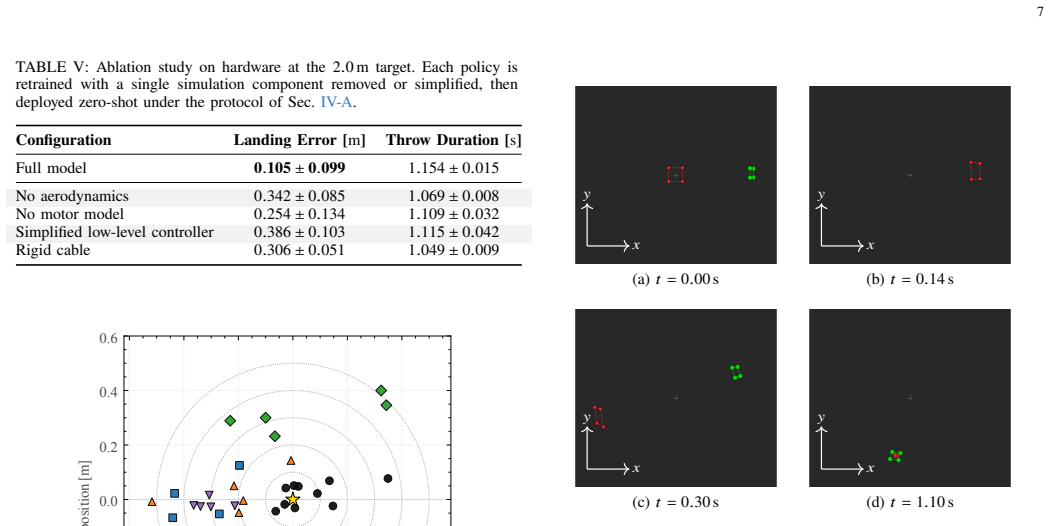
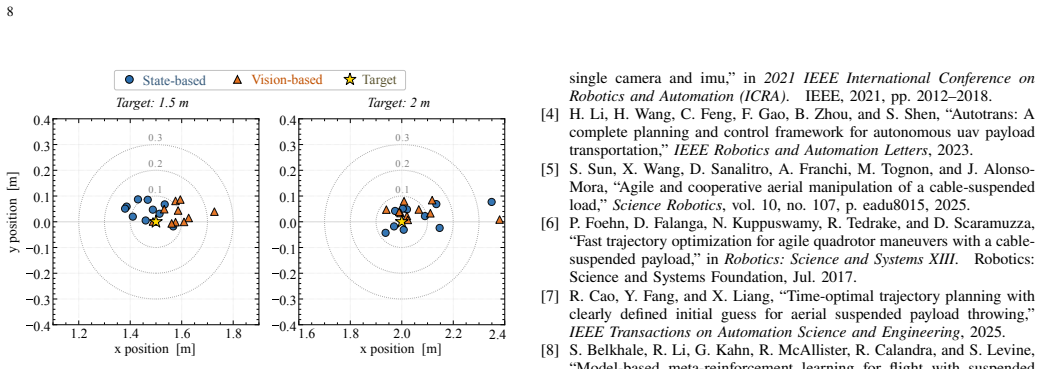
The central claim is that an RL policy trained via the hybrid simulation framework for suspended-payload quadrotor throws outperforms the model-based baseline on hardware by reducing landing error up to 50% and throw duration up to 30%, and that the coupled simulation is the key enabler as shown by ablations; the pipeline also supports vision-based policies with comparable accuracy.
What carries the argument
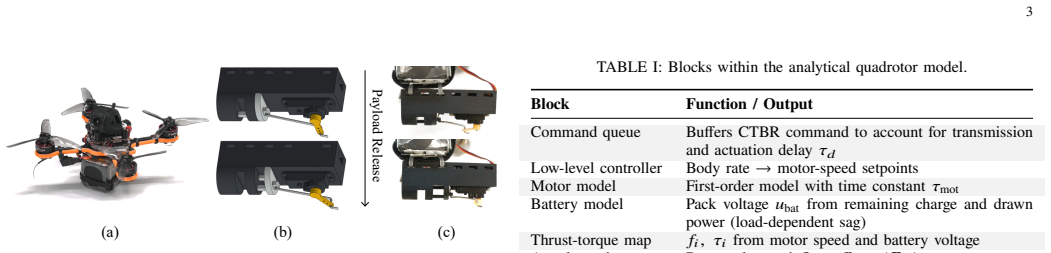
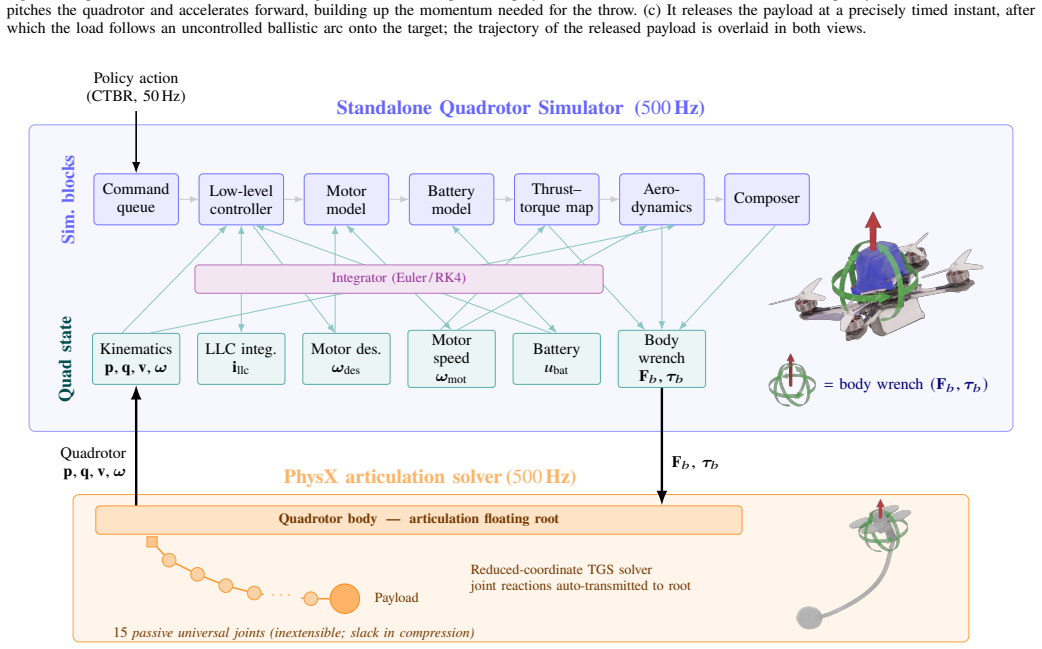
Hybrid simulation that exchanges forces at every step between a high-fidelity analytical quadrotor model and a physics solver modeling rope and payload interactions.
If this is right
- The RL policy executes agile and accurate throws directly on hardware without additional training.
- Visual observation policies achieve accuracy similar to state-estimate policies.
- The coupled simulation is essential, as ablations confirm performance drops without it.
- Releasing the simulator supports further research in dynamic aerial manipulation.
Where Pith is reading between the lines
- This hybrid approach could extend to other tasks involving underactuated payloads or flexible connections in robotics.
- Reducing dependence on analytical models for flexible elements may simplify development of aerial delivery systems.
- Success with vision suggests potential for end-to-end learning in more complex environments.
Load-bearing premise
The hybrid simulation must match real-world dynamics closely enough that the policy trained in simulation performs well when transferred to hardware.
What would settle it
Running the trained policy on the physical quadrotor and measuring if the landing errors and throw durations match or exceed the simulated improvements over the baseline; failure to do so would indicate the simulation-reality gap prevents the claimed gains.
Figures


read the original abstract
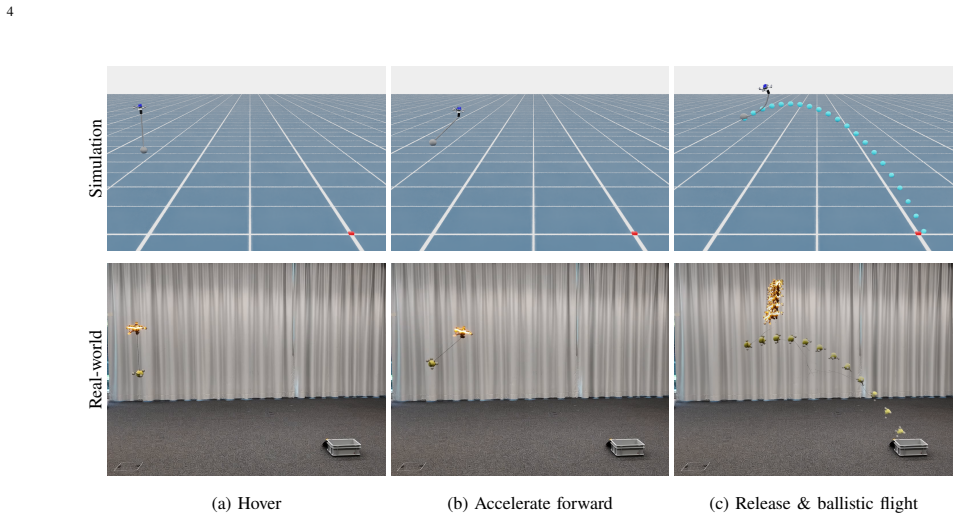
Quadrotors offer the agility needed to rapidly transport suspended payloads during time-critical applications, including search-and-rescue and medical delivery. While suspended-payload transport and traversal for these missions are well studied, the highly dynamic targeted release of the payload remains comparatively underexplored. State-of-the-art approaches typically rely on model-based trajectory optimization and tracking; however, these methods often yield sub-optimal performance due to conservative feasibility constraints, tracking errors, and the inherent difficulty of analytically modeling flexible rope dynamics. To overcome these limitations, we propose a hybrid simulation framework that couples a high-fidelity analytical quadrotor model with a physics solver for complex rope and payload interactions. By exchanging forces between the two domains at every step, we obtain a physically accurate simulation of the suspended-payload system. Leveraging this environment, we train a deep reinforcement learning (RL) policy that executes agile, accurate payload throws to designated targets. Deployed zero-shot on hardware, our RL policy pushes the boundary of the agility-accuracy trade-off, outperforming the model-based baseline by reducing the landing error by up to 50% and the throw duration by up to 30%. Ablation studies confirm that the coupled simulation is the key enabler of these gains. We further show that the same pipeline trains a policy driven by visual observations rather than an explicit state estimate, achieving accuracy comparable to that of the state-based policy. To accelerate future research in dynamic aerial manipulation, we open-source the simulator to the community upon acceptance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a hybrid simulation framework coupling a high-fidelity analytical quadrotor model with a physics solver for rope and payload interactions (with force exchange at each step) to train a deep RL policy for agile cable-suspended payload throws. The policy is deployed zero-shot on hardware and is reported to outperform a model-based baseline by up to 50% in landing error and 30% in throw duration; ablation studies are said to confirm the coupled simulation as the key enabler. A vision-based variant is also trained and achieves comparable accuracy. The simulator is to be open-sourced.
Significance. If the zero-shot transfer holds, the work would advance dynamic aerial manipulation by showing that RL can achieve superior agility-accuracy trade-offs in under-modeled flexible-payload systems compared with trajectory optimization, with direct relevance to time-critical delivery tasks. Open-sourcing the simulator constitutes a concrete contribution to reproducibility.
major comments (2)
- [Abstract] Abstract: the headline zero-shot hardware claim (50% landing-error reduction, 30% duration reduction) is load-bearing on the hybrid simulator producing dynamics sufficiently close to reality, yet the manuscript supplies no quantitative sim-to-real metrics (trajectory matching, force residuals, or identical-input landing-error distributions) to rule out exploitation of simulation artifacts such as incorrect tension propagation or neglected cable drag.
- [Abstract] Abstract: the reported performance gains are stated without error bars, statistical significance tests, or dataset size details, which prevents assessment of whether the observed deltas are robust or could be explained by run-to-run variance.
minor comments (1)
- [Abstract] Abstract: the ablation studies are asserted to confirm the coupled simulation's importance, but no description of the specific ablations, metrics, or controls is provided.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback. We address the two major comments point-by-point below, agreeing where the manuscript can be strengthened through revision.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline zero-shot hardware claim (50% landing-error reduction, 30% duration reduction) is load-bearing on the hybrid simulator producing dynamics sufficiently close to reality, yet the manuscript supplies no quantitative sim-to-real metrics (trajectory matching, force residuals, or identical-input landing-error distributions) to rule out exploitation of simulation artifacts such as incorrect tension propagation or neglected cable drag.
Authors: We agree that explicit quantitative sim-to-real metrics would better support the zero-shot claim. The manuscript reports successful hardware deployment and performance gains, with ablations confirming the coupled simulator's role in training, but does not include direct comparisons such as trajectory matching or force residuals. In the revised version we will add a dedicated sim-to-real validation subsection that reports quantitative metrics (e.g., RMS trajectory error between matched sim and real runs under identical inputs, and landing-error distributions) drawn from our existing experimental logs. revision: yes
-
Referee: [Abstract] Abstract: the reported performance gains are stated without error bars, statistical significance tests, or dataset size details, which prevents assessment of whether the observed deltas are robust or could be explained by run-to-run variance.
Authors: We concur that the presentation of results would be improved by statistical details. While the full manuscript describes results aggregated over multiple hardware trials, error bars, trial counts, and significance tests are not reported in the abstract or main results. In revision we will augment the results section and abstract with error bars on all reported metrics, explicit trial counts, and statistical significance tests (e.g., paired t-tests) comparing the RL policy against the model-based baseline. revision: yes
Circularity Check
No circularity: empirical sim-to-real results with no equation-level reduction to inputs
full rationale
The paper's core claims rest on training an RL policy inside a described hybrid simulator and reporting measured hardware outcomes (landing error, throw duration) plus ablations. No derivation chain, uniqueness theorem, ansatz, or fitted parameter is invoked such that any reported performance number reduces by construction to a quantity defined inside the paper. The abstract and described pipeline contain no equations at all; the results are external measurements, not algebraic identities or renamed fits. This is the standard non-circular case for an empirical robotics paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Geometric control and differential flatness of a quadrotor uav with a cable-suspended load,
K. Sreenath, T. Lee, and V. Kumar, “Geometric control and differential flatness of a quadrotor uav with a cable-suspended load,” in52nd IEEE Conference on Decision and Control, 2013, pp. 2269–2274
2013
-
[2]
Impact-aware planning and control for aerial robots with suspended payloads,
H. Wang, H. Li, B. Zhou, F. Gao, and S. Shen, “Impact-aware planning and control for aerial robots with suspended payloads,”IEEE Transac- tions on Robotics, vol. 40, pp. 2478–2497, 2024
2024
-
[3]
Pcmpc: Perception-constrained model predictive control for quadrotors with suspended loads using a single camera and imu,
G. Li, A. Tunchez, and G. Loianno, “Pcmpc: Perception-constrained model predictive control for quadrotors with suspended loads using a single camera and imu,” in2021 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2021, pp. 2012–2018
2021
-
[4]
Autotrans: A complete planning and control framework for autonomous uav payload transportation,
H. Li, H. Wang, C. Feng, F. Gao, B. Zhou, and S. Shen, “Autotrans: A complete planning and control framework for autonomous uav payload transportation,”IEEE Robotics and Automation Letters, 2023
2023
-
[5]
Agile and cooperative aerial manipulation of a cable-suspended load,
S. Sun, X. Wang, D. Sanalitro, A. Franchi, M. Tognon, and J. Alonso- Mora, “Agile and cooperative aerial manipulation of a cable-suspended load,”Science Robotics, vol. 10, no. 107, p. eadu8015, 2025
2025
-
[6]
Fast trajectory optimization for agile quadrotor maneuvers with a cable- suspended payload,
P. Foehn, D. Falanga, N. Kuppuswamy, R. Tedrake, and D. Scaramuzza, “Fast trajectory optimization for agile quadrotor maneuvers with a cable- suspended payload,” inRobotics: Science and Systems XIII. Robotics: Science and Systems Foundation, Jul. 2017
2017
-
[7]
Time-optimal trajectory planning with clearly defined initial guess for aerial suspended payload throwing,
R. Cao, Y. Fang, and X. Liang, “Time-optimal trajectory planning with clearly defined initial guess for aerial suspended payload throwing,” IEEE Transactions on Automation Science and Engineering, 2025
2025
-
[8]
Model-based meta-reinforcement learning for flight with suspended payloads,
S. Belkhale, R. Li, G. Kahn, R. McAllister, R. Calandra, and S. Levine, “Model-based meta-reinforcement learning for flight with suspended payloads,”IEEE Robotics and Automation Letters, vol. 6, no. 2, 2021
2021
-
[9]
Decentralized aerial manipulation of a cable-suspended load using multi-agent reinforcement learning,
J. Zeng, A. M. Gimenez, E. Vinitsky, J. Alonso-Mora, and S. Sun, “Decentralized aerial manipulation of a cable-suspended load using multi-agent reinforcement learning,”CoRL, 2025
2025
-
[10]
Aster: Attitude-aware suspended- payload quadrotor traversal via efficient reinforcement learning,
D. Cao, J. Zhou, and S. Li, “Aster: Attitude-aware suspended- payload quadrotor traversal via efficient reinforcement learning,”arXiv preprint:2603.10715, 2026
-
[11]
Flare: Agile flights for quadro- tor cable-suspended payload system via reinforcement learning,
D. Cao, J. Zhou, X. Wang, and S. Li, “Flare: Agile flights for quadro- tor cable-suspended payload system via reinforcement learning,”IEEE Robotics and Automation Letters, vol. PP, pp. 1–8, 2026
2026
-
[12]
Es-hpc-mpc: Expo- nentially stable hybrid perception constrained mpc for quadrotor with suspended payloads,
L. Recalde, M. Sarvaiya, G. Loianno, and G. Li, “Es-hpc-mpc: Expo- nentially stable hybrid perception constrained mpc for quadrotor with suspended payloads,”IEEE Robotics and Automation Letters, 2025
2025
-
[13]
Aerial transportation of cable-suspended loads with an event camera,
F. Panetsos, G. Karras, and K. Kyriakopoulos, “Aerial transportation of cable-suspended loads with an event camera,”IEEE Robotics and Automation Letters, vol. PP, pp. 1–8, 2023
2023
-
[14]
Rotortm: A flexible simulator for aerial transportation and manipulation,
G. Li, X. Liu, and G. Loianno, “Rotortm: A flexible simulator for aerial transportation and manipulation,”IEEE Transactions on Robotics, vol. 40, pp. 831–850, 2024
2024
-
[15]
Nonlinear predictive control of the continuum and hybrid dynamics of a suspended deformable cable for aerial pick and place,
A. Rapuano, Y. Shen, F. Califano, C. Gabellieri, and A. Franchi, “Nonlinear predictive control of the continuum and hybrid dynamics of a suspended deformable cable for aerial pick and place,” in2026 IEEE International Conference on Robotics and Automation (ICRA), 2026
2026
-
[16]
Aerothrow: An autonomous aerial throwing system for precise payload delivery,
Z. Li, H. Chen, Y. Lin, B. Ye, Z. Pan, and X. Lyu, “Aerothrow: An autonomous aerial throwing system for precise payload delivery,”IEEE Robotics and Automation Letters, vol. 11, pp. 2794–2801, 2025
2025
-
[17]
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
M. Mittalet al., “Isaac lab: A gpu-accelerated simulation framework for multi-modal robot learning,”arXiv preprint arXiv:2511.04831, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Warp: A High-performance Python Framework for GPU Simulation and Graphics,
M. Macklin, “Warp: A High-performance Python Framework for GPU Simulation and Graphics,” Mar. 2022. [Online]. Available: https://github.com/NVIDIA/warp
2022
-
[19]
Nvidia physx sdk,
NVIDIA, “Nvidia physx sdk,” 2026. [Online]. Available: https: //github.com/NVIDIA-Omniverse/PhysX
2026
-
[20]
Agilicious: Open-source and open-hardware agile quadrotor for vision-based flight,
P. Foehnet al., “Agilicious: Open-source and open-hardware agile quadrotor for vision-based flight,”Science Robotics, vol. 7, 06 2022
2022
-
[21]
Reach- ing the limit in autonomous racing: Optimal control versus reinforcement learning,
Y. Song, A. Romero, M. Müller, V. Koltun, and D. Scaramuzza, “Reach- ing the limit in autonomous racing: Optimal control versus reinforcement learning,”Science Robotics, vol. 8, no. 82, p. eadg1462, 2023
2023
-
[22]
Multi-task reinforcement learning for quadrotors,
J. Xing, I. Geles, Y. Song, E. Aljalbout, and D. Scaramuzza, “Multi-task reinforcement learning for quadrotors,”IEEE Robotics and Automation Letters, vol. 10, no. 3, pp. 2112–2119, 2024
2024
-
[23]
Pa-mppi: Perception-aware model predictive path integral control for quadrotor navigation in un- known environments,
Y. Zhai, R. Reiter, and D. Scaramuzza, “Pa-mppi: Perception-aware model predictive path integral control for quadrotor navigation in un- known environments,”IEEE Robotics and Automation Letters, 2025
2025
-
[24]
Dynamicobstacleavoidance for quadrotors with event cameras,
D.Falanga,K.Kleber,andD.Scaramuzza,“Dynamicobstacleavoidance for quadrotors with event cameras,”Science Robotics, vol. 5, no. 40, p. eaaz9712, 2020
2020
-
[25]
Learning acrobatic flight from preferences,
C. Merk, I. Geles, J. Xing, A. Romero, G. Ramponi, and D. Scaramuzza, “Learning acrobatic flight from preferences,”arXiv preprint, 2026
2026
-
[26]
Unlocking aerobatic potential of quadcopters: Autonomous freestyle flight generation and execution,
M. Wang, Q. Wang, Z. Wang, Y. Gao, J. Wang, C. Cui, Y. Li, Z. Ding, K. Wang, C. Xu, and F. Gao, “Unlocking aerobatic potential of quadcopters: Autonomous freestyle flight generation and execution,” Science Robotics, vol. 10, no. 101, p. eadp9905, 2025
2025
-
[27]
Proximal policy optimization algorithms,
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,”arXiv preprint, 2017
2017
-
[28]
On the continuity of rotation representations in neural networks,
Y. Zhou, C. Barnes, J. Lu, J. Yang, and H. Li, “On the continuity of rotation representations in neural networks,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 5745–5753. 9
2019
-
[29]
acados—a modular open-source framework for fast embedded optimal control,
R. Verschueren, G. Frison, D. Kouzoupis, J. Frey, N. van Duijkeren, A. Zanelli, B. Novoselnik, T. Albin, R. Quirynen, and M. Diehl, “acados—a modular open-source framework for fast embedded optimal control,”Mathematical Programming Computation, 2022
2022
-
[30]
The reality gap in robotics: Challenges, solutions, and best practices,
E. Aljalbout, J. Xing, A. Romero, I. Akinola, C. R. Garrett, E. Heiden, A. Gupta, T. Hermans, Y. Narang, D. Foxet al., “The reality gap in robotics: Challenges, solutions, and best practices,”Annual Review of Control, Robotics, and Autonomous Systems, vol. 9, 2025
2025
-
[31]
Bootstrapping reinforcement learning with imitation for vision-based agile flight,
J. Xing, A. Romero, L. Bauersfeld, and D. Scaramuzza, “Bootstrapping reinforcement learning with imitation for vision-based agile flight,”8th Conference on Robot Learning (CoRL), 2024
2024
-
[32]
Learning quadrotor control from visual features using differentiable simulation,
J. Heeg, Y. Song, and D. Scaramuzza, “Learning quadrotor control from visual features using differentiable simulation,”IEEE Robotics and Automation Letters, 2025
2025
-
[33]
Learning on the fly: Rapid policy adaptation via differentiable simula- tion,
J. Pan, J. Xing, R. Reiter, Y. Zhai, E. Aljalbout, and D. Scaramuzza, “Learning on the fly: Rapid policy adaptation via differentiable simula- tion,”IEEE Robotics and Automation Letters, 2025
2025
-
[34]
You only look once: Unified, real-time object detection,
J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, “You only look once: Unified, real-time object detection,” in2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 779–788
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.