DRIFT: Refining Instruction Data via On-Policy Data Attribution
Pith reviewed 2026-06-27 01:54 UTC · model grok-4.3
The pith
DRIFT refines SFT data by using on-policy influence functions with model rollouts as validation targets to raise performance ceilings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
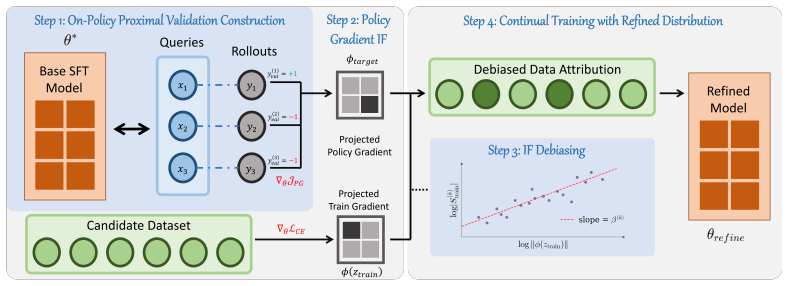
DRIFT (Data Refinement via On-Policy Influence Functions for Supervised Fine-Tuning) replaces external reference data with the model's on-policy rollouts as validation targets for influence estimation. It further applies signed weighting based on trajectory correctness and debiases influence scores against gradient norm bias, enabling a small set of validation queries to attribute influence across the full training dataset and thereby raise the performance upper bound.
What carries the argument
On-policy influence functions that use the model's own rollouts as validation targets, combined with signed weighting by correctness and debiasing of gradient-norm bias.
If this is right
- A small set of validation queries can serve as reliable anchors for attributing influence over the entire training dataset.
- Signed weighting by trajectory correctness improves the quality of influence attribution for refinement.
- Debiased influence scores reduce the dominance of high-gradient-norm instances in the selected data.
- The refined data distribution raises the performance ceiling on both instruction-following and reasoning tasks for 7B models.
Where Pith is reading between the lines
- The same on-policy attribution principle could be tested on other fine-tuning regimes that also generate their own trajectories.
- If the proximity-gap reduction holds, the method may allow smaller validation sets without loss of attribution reliability.
- The approach suggests that training-distribution alignment in validation targets matters more for influence estimation than previously emphasized in off-policy settings.
Load-bearing premise
The model's on-policy rollouts serve as suitable validation targets that minimize the parameter proximity gap and satisfy the local neighborhood assumption of influence functions.
What would settle it
An experiment that selects data with standard off-policy influence functions, retrains the same 7B models, and obtains equal or higher performance on the instruction and reasoning benchmarks would falsify the claimed advantage of on-policy targets.
Figures
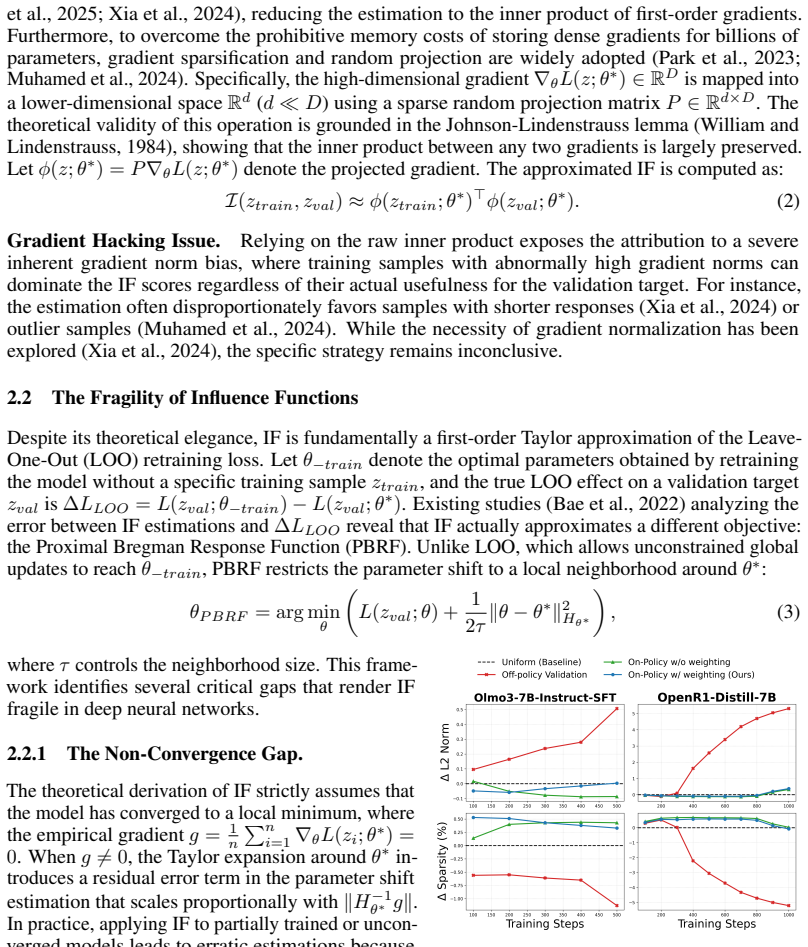


read the original abstract
Optimizing the training data distribution for Supervised Fine-Tuning (SFT) dictates the capability of Large Language Models (LLMs). While existing data curation methods excel at accelerating training under constrained budgets, they are less suited to elevating the capability upper bound. The challenge here is no longer to identify a smaller subset that preserves performance, but to refine the data distribution toward instances most capable of improving the final model. To address this problem, we explore instance-level data attribution using Influence Functions (IF). We identify that standard IF formulations struggle in this setting due to two structural limitations: a proximity gap caused by off-policy validation targets, and a severe bias towards gradient norm. We propose DRIFT (Data Refinement via On-Policy Influence Functions for Supervised Fine-Tuning). Instead of relying on external reference data, DRIFT utilizes the model's on-policy rollouts as validation targets, which empirically minimizes the parameter proximity gap and better aligns with the local neighborhood assumption of IF. It further applies signed weighting based on trajectory correctness and debiases influence scores against the gradient hacking issue, allowing a small set of validation queries to act as reliable anchors for attributing the full dataset. Experiments on 7B-parameter instruction and reasoning models show that DRIFT consistently raises the performance ceiling on both, outperforming existing data curation baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DRIFT, a method to refine SFT training data for LLMs via instance-level influence functions. It replaces off-policy validation targets with the model's on-policy rollouts to close the parameter proximity gap, introduces signed weighting by trajectory correctness, and applies gradient-norm debiasing. Experiments on 7B instruction and reasoning models report that the resulting data selection raises the performance ceiling and outperforms prior curation baselines.
Significance. If the influence scores remain reliable after the on-policy and debiasing modifications, DRIFT would offer a concrete mechanism for elevating capability ceilings rather than merely accelerating convergence under fixed budgets. The on-policy construction is a clear technical contribution worth testing, provided the local-neighborhood assumption of IF can be shown to hold in the non-convex SFT setting.
major comments (2)
- [Abstract and §3] Abstract and §3: The central justification—that on-policy rollouts 'empirically minimizes the parameter proximity gap and better aligns with the local neighborhood assumption of IF'—is load-bearing for the validity of the influence scores. No diagnostic is reported (e.g., Spearman correlation between DRIFT scores and leave-one-out retraining deltas, or trace of the Hessian at the fine-tuned point) to confirm that the quadratic approximation remains valid after signed weighting and debiasing.
- [§4] §4 (experimental results): The claim that DRIFT 'consistently raises the performance ceiling' on both instruction and reasoning 7B models requires explicit reporting of the number of independent runs, standard deviations, and statistical tests; without these, it is impossible to determine whether the reported gains exceed the variance of the baseline methods.
minor comments (2)
- [§3] Notation for the signed-weighting term and the debiasing factor should be introduced with explicit equations rather than prose descriptions only.
- [§4] The manuscript should include a short ablation isolating the contribution of on-policy targets versus the signed-weighting and debiasing steps.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3: The central justification—that on-policy rollouts 'empirically minimizes the parameter proximity gap and better aligns with the local neighborhood assumption of IF'—is load-bearing for the validity of the influence scores. No diagnostic is reported (e.g., Spearman correlation between DRIFT scores and leave-one-out retraining deltas, or trace of the Hessian at the fine-tuned point) to confirm that the quadratic approximation remains valid after signed weighting and debiasing.
Authors: We agree that direct diagnostics would strengthen the claim that the quadratic approximation remains valid. The on-policy construction is motivated by reducing the proximity gap, with downstream gains providing supporting evidence, but we will add a diagnostic subsection in the revision. Specifically, we will report Spearman correlation between DRIFT scores and performance deltas obtained from retraining after removing high-influence instances on a held-out validation subset, along with a note on the Hessian trace at the fine-tuned point where computationally feasible. revision: yes
-
Referee: [§4] §4 (experimental results): The claim that DRIFT 'consistently raises the performance ceiling' on both instruction and reasoning 7B models requires explicit reporting of the number of independent runs, standard deviations, and statistical tests; without these, it is impossible to determine whether the reported gains exceed the variance of the baseline methods.
Authors: We acknowledge that variance and statistical testing are necessary to support claims of consistent improvement. The reported results used single runs owing to the substantial compute required for 7B-scale SFT. In the revised manuscript we will rerun the primary comparisons across at least three independent random seeds, report means and standard deviations, and include paired statistical tests (e.g., t-tests) against the strongest baselines to demonstrate that the observed gains exceed run-to-run variance. revision: yes
Circularity Check
No circularity detected; claims rest on empirical fixes without self-referential derivation.
full rationale
The provided abstract and text describe DRIFT as an empirical refinement of influence functions using on-policy rollouts to address proximity gap and gradient bias, with performance gains shown via experiments. No equations or derivation chain is exhibited that reduces any prediction or attribution score to its own inputs by construction. The on-policy choice is presented as an empirical alignment step rather than a fitted parameter renamed as output. No self-citation load-bearing or ansatz smuggling is visible in the given material. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Influence functions remain valid when validation targets are replaced by on-policy model rollouts.
- domain assumption Signed weighting by trajectory correctness and gradient-norm debiasing remove the dominant bias in standard IF scores.
Reference graph
Works this paper leans on
-
[1]
Efficient online data mixing for language model pre-training.arXiv preprint arXiv:2312.02406,
Alon Albalak, Liangming Pan, Colin Raffel, and William Yang Wang. Efficient online data mixing for language model pre-training.arXiv preprint arXiv:2312.02406,
-
[2]
Sang Keun Choe, Hwijeen Ahn, Juhan Bae, Kewen Zhao, Minsoo Kang, Youngseog Chung, Adithya Pratapa, Willie Neiswanger, Emma Strubell, Teruko Mitamura, et al. What is your data worth to gpt? llm-scale data valuation with influence functions.arXiv preprint arXiv:2405.13954,
-
[3]
If-guide: Influence function- guided detoxification of llms.arXiv preprint arXiv:2506.01790,
Zachary Coalson, Juhan Bae, Nicholas Carlini, and Sanghyun Hong. If-guide: Influence function- guided detoxification of llms.arXiv preprint arXiv:2506.01790,
-
[4]
Roger Grosse, Juhan Bae, Cem Anil, Nelson Elhage, Alex Tamkin, Amirhossein Tajdini, Benoit Steiner, Dustin Li, Esin Durmus, Ethan Perez, et al. Studying large language model generalization with influence functions.arXiv preprint arXiv:2308.03296,
-
[5]
URL https: //github.com/huggingface/open-r1. Prateek Humane, Paolo Cudrano, Daniel Z Kaplan, Matteo Matteucci, Supriyo Chakraborty, and Irina Rish. Influence functions for efficient data selection in reasoning.arXiv preprint arXiv:2510.06108,
-
[6]
Large-scale data selection for instruction tuning.arXiv preprint arXiv:2503.01807,
Hamish Ivison, Muru Zhang, Faeze Brahman, Pang Wei Koh, and Pradeep Dasigi. Large-scale data selection for instruction tuning.arXiv preprint arXiv:2503.01807,
-
[7]
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code.arXiv preprint arXiv:2403.07974,
-
[8]
Yongchan Kwon, Eric Wu, Kevin Wu, and James Zou. Datainf: Efficiently estimating data influence in lora-tuned llms and diffusion models.arXiv preprint arXiv:2310.00902,
-
[9]
Do influence functions work on large language models
10 Zhe Li, Wei Zhao, Yige Li, and Jun Sun. Do influence functions work on large language models. arXiv preprint arXiv:2409.19998, 3, 2024b. Bill Yuchen Lin, Ronan Le Bras, and Yejin Choi. Zebralogic: Benchmarking the logical reason- ing ability of language models,
-
[10]
URL https: //openreview.net/forum?id=1qvx610Cu7. Qian Liu, Xiaosen Zheng, Niklas Muennighoff, Guangtao Zeng, Longxu Dou, Tianyu Pang, Jing Jiang, and Min Lin. Regmix: Data mixture as regression for language model pre-training.arXiv preprint arXiv:2407.01492,
-
[11]
Xing Han Lù. Bm25s: Orders of magnitude faster lexical search via eager sparse scoring.arXiv preprint arXiv:2407.03618,
-
[12]
Grass: Compute efficient low-memory llm training with structured sparse gradients
Aashiq Muhamed, Oscar Li, David Woodruff, Mona Diab, and Virginia Smith. Grass: Compute efficient low-memory llm training with structured sparse gradients. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 14978–15003,
2024
-
[13]
Sagnik Mukherjee, Lifan Yuan, Dilek Hakkani-Tur, and Hao Peng. Reinforcement learning finetunes small subnetworks in large language models.arXiv preprint arXiv:2505.11711,
-
[14]
Olmo 3.arXiv preprint arXiv:2512.13961,
Team Olmo, Allyson Ettinger, Amanda Bertsch, Bailey Kuehl, David Graham, David Heineman, Dirk Groeneveld, Faeze Brahman, Finbarr Timbers, Hamish Ivison, et al. Olmo 3.arXiv preprint arXiv:2512.13961,
-
[15]
Trak: Attributing model behavior at scale.arXiv preprint arXiv:2303.14186,
Sung Min Park, Kristian Georgiev, Andrew Ilyas, Guillaume Leclerc, and Aleksander Madry. Trak: Attributing model behavior at scale.arXiv preprint arXiv:2303.14186,
-
[16]
Gpqa: A graduate-level google-proof q&a benchmark
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. Gpqa: A graduate-level google-proof q&a benchmark. arXiv preprint arXiv:2311.12022,
-
[17]
Megatron-lm: Training multi-billion parameter language models using model parallelism
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catan- zaro. Megatron-lm: Training multi-billion parameter language models using model parallelism. arXiv preprint arXiv:1909.08053,
Pith/arXiv arXiv 1909
-
[18]
Ilia Shumailov, Zakhar Shumaylov, Yiren Zhao, Yarin Gal, Nicolas Papernot, and Ross Ander- son. The curse of recursion: Training on generated data makes models forget.arXiv preprint arXiv:2305.17493,
-
[19]
Avi Singh, John Hui, Zhihui Yin, Jianlin Tu, et al. Beyond human data: Scaling self-training for problem-solving with language models.arXiv preprint arXiv:2312.06585,
-
[20]
11 Mirac Suzgun, Nathan Scales, Nathanael Schärli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc V Le, Ed H Chi, Denny Zhou, , and Jason Wei. Challenging big-bench tasks and whether chain-of-thought can solve them.arXiv preprint arXiv:2210.09261,
-
[21]
Jiachen T Wang, Tong Wu, Dawn Song, Prateek Mittal, and Ruoxi Jia. Greats: Online selection of high-quality data for llm training in every iteration.Advances in Neural Information Processing Systems, 37:131197–131223, 2024a. Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, et...
-
[22]
Qurating: Selecting high-quality data for training language models.arXiv preprint arXiv:2402.09739,
Alexander Wettig, Aatmik Gupta, Saumya Malik, and Danqi Chen. Qurating: Selecting high-quality data for training language models.arXiv preprint arXiv:2402.09739,
-
[23]
Less: Selecting influential data for targeted instruction tuning.arXiv preprint arXiv:2402.04333,
Mengzhou Xia, Sadhika Malladi, Suchin Gururangan, Sanjeev Arora, and Danqi Chen. Less: Selecting influential data for targeted instruction tuning.arXiv preprint arXiv:2402.04333,
-
[24]
Sang Michael Xie, Hieu Pham, Xuanyi Dong, Nan Du, Hanxiao Liu, Yifeng Lu, Percy S Liang, Quoc V Le, Tengyu Ma, and Adams Wei Yu. Doremi: Optimizing data mixtures speeds up language model pretraining.Advances in Neural Information Processing Systems, 36:69798–69818, 2023a. Sang Michael Xie, Shibani Santurkar, Tengyu Ma, and Percy S Liang. Data selection fo...
-
[25]
Jia Zhang, Chen-Xi Zhang, Yao Liu, Yi-Xuan Jin, Xiao-Wen Yang, Bo Zheng, Yi Liu, and Lan-Zhe Guo. D3: Diversity, difficulty, and dependability-aware data selection for sample-efficient llm instruction tuning.arXiv preprint arXiv:2503.11441,
-
[26]
Data-efficient rlvr via off-policy influence guidance.arXiv preprint arXiv:2510.26491,
Erle Zhu, Dazhi Jiang, Yuan Wang, Xujun Li, Jiale Cheng, Yuxian Gu, Yilin Niu, Aohan Zeng, Jie Tang, Minlie Huang, et al. Data-efficient rlvr via off-policy influence guidance.arXiv preprint arXiv:2510.26491,
-
[27]
package. For each validation set sample, we assign a linear score between 0 and 1 to the training samples based on their BM25 similarity ranking, and then obtain the aggregated score by summing them up. DSIR.We instantiate the Data Selection with Importance Resampling (DSIR) (Xie et al., 2023b) framework with hashed n-gram features for tractable importanc...
2025
-
[28]
as our method. The critical distinction is that it computes scores against static, external validation sets (the original reference responses) and uses standard cosine similarity without our proposed log-space debiasing. B Motivating Analysis of Pure On-Policy Targets B.1 Theoretical Justification of the Proximity Gap Mitigation In this section, we provid...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.