Cohort-Anchored Foundation Models for Electronic Health Records: From Risk Scores to Auditable Peer Cohorts
Pith reviewed 2026-06-26 12:29 UTC · model grok-4.3
The pith
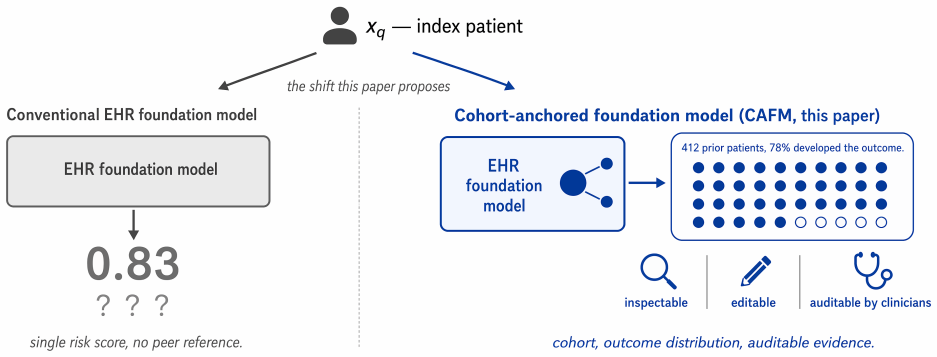
Anchoring foundation models to explicit patient cohorts organizes EHR representations around clinically meaningful groups for auditable decisions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
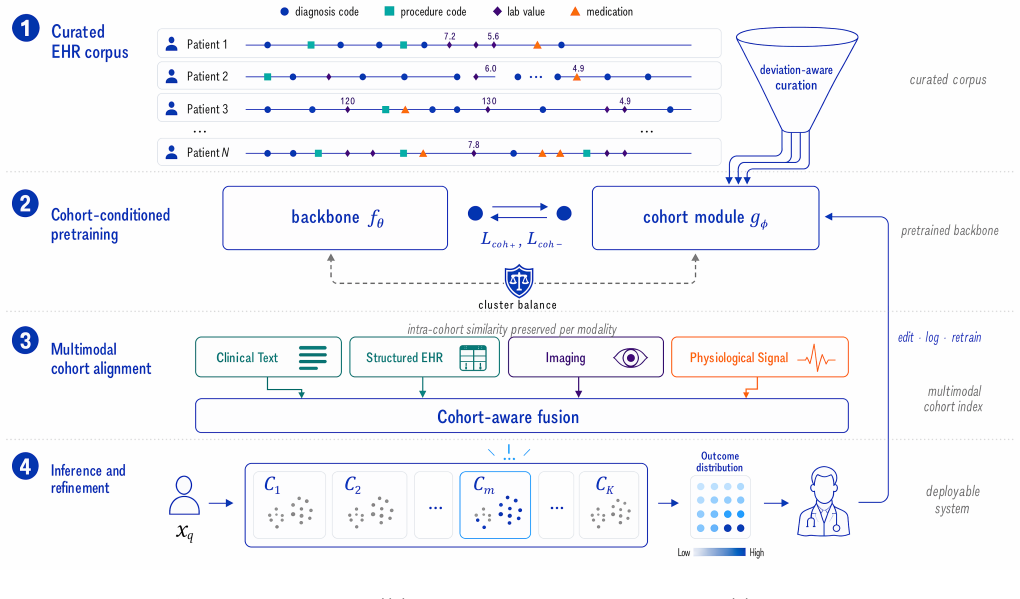
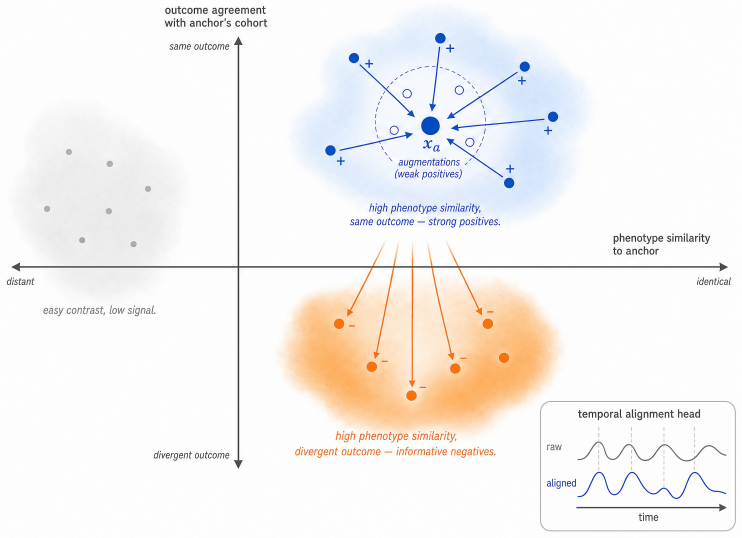
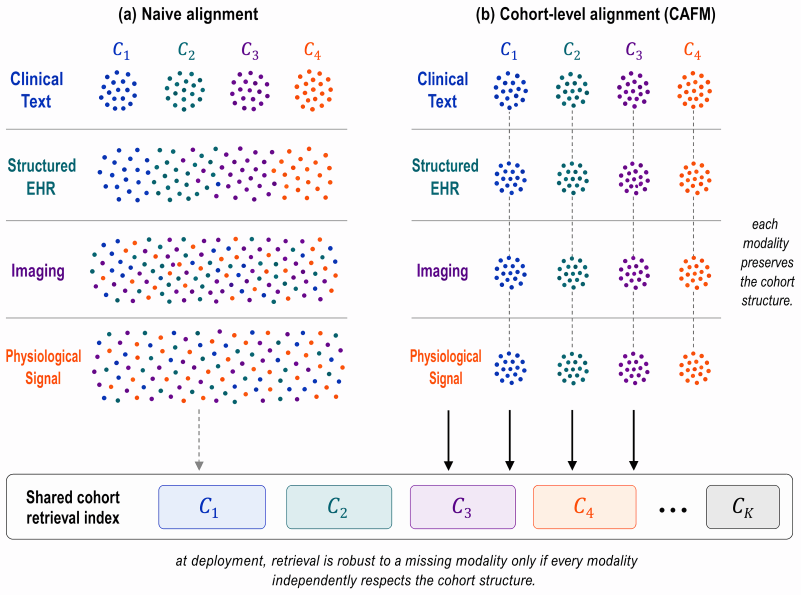
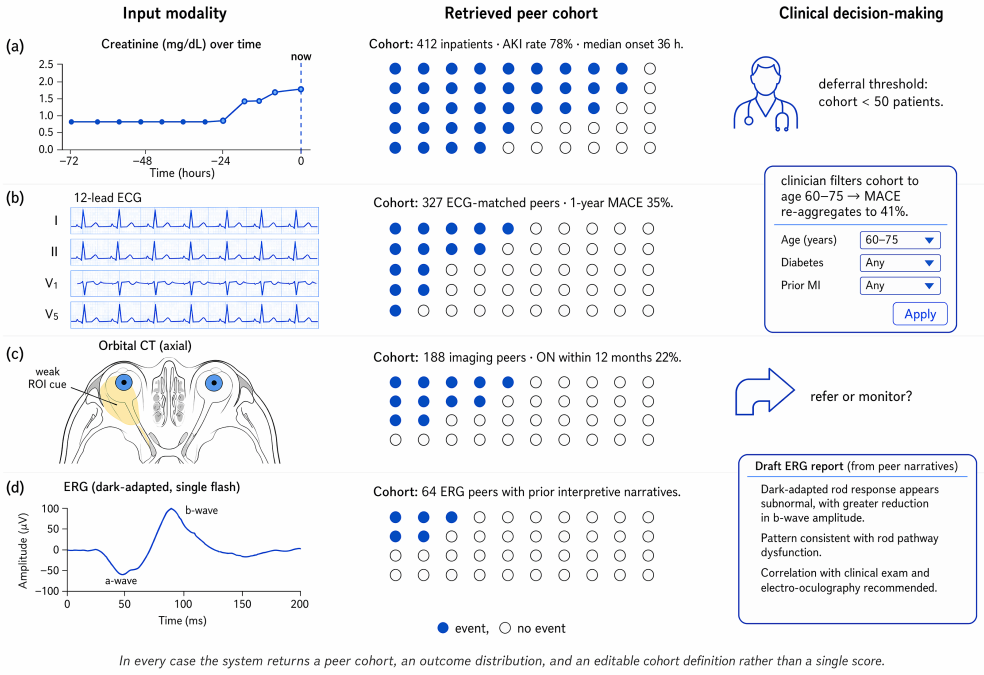
The central claim is that explicitly elevating patient cohorts to first-class objects throughout the learning pipeline, via deviation-aware data curation, cohort-conditioned pretraining, multimodal cohort alignment, and clinician-in-the-loop refinement, yields representations that preserve modality-specific relationships, organize around clinically meaningful cohort structure, and support auditable clinical decision-making. The resulting Cohort-Anchored Foundation Model framework augments existing EHR encoders without modifying them and is illustrated across acute kidney injury prediction, cardiovascular risk from ECGs, optic neuropathy triage from imaging, and electroretinogram-grounded rep
What carries the argument
The Cohort-Anchored Foundation Model (CAFM) framework, which inserts four cohort-centric stages into the training and refinement pipeline to make patient comparison a primary rather than emergent source of clinical evidence.
If this is right
- The framework augments existing EHR foundation models without changing their underlying encoders.
- Representations remain organized around clinically meaningful cohort structure while keeping modality-specific relationships intact.
- Clinician-in-the-loop refinement produces outputs that support direct audit against peer patient groups.
- The same four-stage structure applies across prediction, risk stratification, imaging triage, and report generation tasks.
- Five empirically testable hypotheses follow directly from the claim that cohort anchoring improves trustworthiness over standard representation learning.
Where Pith is reading between the lines
- If cohort conditioning reduces effective distribution shift within matched groups, the same stages could be applied to other high-stakes domains where peer comparison is already a standard of care.
- The clinician-in-the-loop stage implicitly treats human feedback as a source of cohort labels, suggesting a route to iterative refinement that does not require full retraining.
- Open challenges listed in the paper around irregular temporality and evaluation beyond accuracy point to the need for new metrics that score how well a prediction is justified by its retrieved cohort rather than by aggregate accuracy alone.
Load-bearing premise
The four stages can be composed on top of existing encoders while preserving modality-specific relationships and yielding clinically meaningful cohort structure.
What would settle it
A controlled comparison on one of the four case studies in which the cohort-anchored version shows no gain in clinician-rated auditability or agreement with reasoning compared with the unmodified base encoder.
Figures
read the original abstract
Foundation models have achieved remarkable performance across medical question answering, imaging, and electronic health record (EHR) tasks, yet reliable clinical deployment remains challenging due to limited interpretability, vulnerability to distribution shift, and weak alignment with clinician reasoning. We argue that these limitations arise because existing approaches prioritize representation learning while treating patient comparison as an emergent property rather than a primary source of clinical evidence. To address this gap, we propose CAFM, a Cohort-Anchored Foundation Model framework that elevates patient cohorts to a first-class object throughout the learning pipeline. The framework consists of four stages: deviation-aware data curation, cohort-conditioned pretraining, multimodal cohort alignment, and clinician-in-the-loop refinement. Together, these stages improve data quality, organize representations around clinically meaningful cohort structure, preserve modality-specific relationships, and support auditable clinical decision-making. The framework is compositional and can augment existing EHR foundation models without modifying their underlying encoders. We illustrate CAFM through four clinical case studies spanning acute kidney injury prediction, cardiovascular risk stratification from electrocardiograms, optic neuropathy triage from orbital imaging, and electroretinogram-grounded report generation. We further present five empirically testable hypotheses and identify open challenges in data quality, irregular temporality, multimodal learning, distribution shift, and evaluation beyond predictive accuracy. We argue that explicitly anchoring foundation models to patient cohorts provides a principled path toward trustworthy clinical AI.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Cohort-Anchored Foundation Model (CAFM) framework for electronic health records. It claims that elevating patient cohorts to a first-class object via four stages—deviation-aware data curation, cohort-conditioned pretraining, multimodal cohort alignment, and clinician-in-the-loop refinement—addresses limitations in interpretability, distribution shift, and clinical alignment of existing foundation models. The framework is described as compositional, augmenting existing EHR encoders without modification, and is illustrated through four clinical case studies (acute kidney injury prediction, cardiovascular risk from ECGs, optic neuropathy triage, and electroretinogram-grounded report generation). Five empirically testable hypotheses are listed along with open challenges in data quality, temporality, multimodality, shift, and evaluation.
Significance. If the four stages can be implemented to produce auditable cohort structure while preserving modality-specific relationships, the framework could supply a structured route to more trustworthy clinical AI by treating cohort comparison as a primary modeling objective rather than an emergent property. The explicit listing of testable hypotheses and open challenges is a constructive element. The absence of any quantitative results, derivations, or validation data means the significance remains prospective.
major comments (2)
- [Abstract] Abstract: the central composability claim—that the four stages 'can augment existing EHR foundation models without modifying their underlying encoders'—is load-bearing for the entire proposal, yet no mechanism is supplied for introducing cohort conditioning into the pretraining objective or performing multimodal alignment without encoder updates, new parameters, or changes to the forward pass or loss.
- [Abstract] Abstract (case studies paragraph): the four clinical case studies are presented only as illustrations with no quantitative results, performance metrics, error bars, or cohort-structure validation, leaving the claim that the stages 'yield clinically meaningful cohort structure' untested and preventing assessment of whether modality-specific relationships are preserved.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for recognizing the prospective value of the CAFM framework along with the explicit hypotheses and challenges. We address the two major comments point by point below. Both comments correctly identify that the abstract presents high-level claims without supporting implementation details or empirical data; we agree that revisions are required to clarify the manuscript's conceptual scope.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central composability claim—that the four stages 'can augment existing EHR foundation models without modifying their underlying encoders'—is load-bearing for the entire proposal, yet no mechanism is supplied for introducing cohort conditioning into the pretraining objective or performing multimodal alignment without encoder updates, new parameters, or changes to the forward pass or loss.
Authors: We agree that the abstract states the composability claim without supplying concrete mechanisms. The manuscript frames CAFM as a compositional framework at the conceptual level, with the four stages intended to operate via modular additions (e.g., auxiliary cohort embeddings or conditioning signals) rather than encoder modification. Because no explicit mechanism, derivation, or pseudocode is provided in the current text, this constitutes a genuine gap. We will revise the abstract and add a dedicated subsection under the framework description to outline candidate mechanisms (such as input-level cohort tokens or auxiliary losses that leave the base encoder unchanged) while preserving the claim that no encoder weights are altered. This revision will be marked clearly as prospective. revision: yes
-
Referee: [Abstract] Abstract (case studies paragraph): the four clinical case studies are presented only as illustrations with no quantitative results, performance metrics, error bars, or cohort-structure validation, leaving the claim that the stages 'yield clinically meaningful cohort structure' untested and preventing assessment of whether modality-specific relationships are preserved.
Authors: We agree that the case studies are presented solely as illustrations and contain no quantitative results, metrics, or validation of cohort structure or modality preservation. This is consistent with the manuscript's stated purpose as a framework proposal that lists five empirically testable hypotheses and open challenges rather than reporting experiments. The abstract's phrasing that the stages 'yield clinically meaningful cohort structure' is therefore unsupported by data in the current version. We will revise the abstract and case-study descriptions to explicitly label them as conceptual illustrations, remove any implication of empirical validation, and direct readers to the listed hypotheses for future testing. This change will be made in the next version. revision: yes
Circularity Check
Conceptual framework proposal exhibits no circularity
full rationale
The paper advances a high-level architectural proposal (CAFM) consisting of four named stages whose composability on unmodified encoders is asserted at the framework level. No equations, fitted parameters, or derivation steps appear in the provided text. No self-citations are invoked as load-bearing uniqueness theorems, and the central claim does not reduce by construction to any input data or prior result. The argument remains an independent design claim whose empirical testability is explicitly deferred to future work and hypotheses.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Existing approaches prioritize representation learning while treating patient comparison as an emergent property rather than a primary source of clinical evidence.
- domain assumption Cohort structure can organize representations while preserving modality-specific relationships.
invented entities (1)
-
Cohort-Anchored Foundation Model (CAFM)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Scalable and accurate deep learning with electronic health records
Alvin Rajkomar, Eyal Oren, Kai Chen, Andrew M Dai, Nissan Hajaj, Michaela Hardt, Peter J Liu, Xiaobing Liu, Jake Marcus, Mimi Sun, et al. Scalable and accurate deep learning with electronic health records. NPJ digital medicine, 1(1):18, 2018
2018
-
[2]
Retain: An interpretable predictive model for healthcare using reverse time attention mechanism
Edward Choi, Mohammad Taha Bahadori, Jimeng Sun, Joshua Kulas, Andy Schuetz, and Walter Stew- art. Retain: An interpretable predictive model for healthcare using reverse time attention mechanism. Advances in neural information processing systems, 29, 2016
2016
-
[3]
Doctor ai: Predicting clinical events via recurrent neural net- works
Edward Choi, Mohammad Taha Bahadori, Andy Schuetz, Walter F Stewart, and Jimeng Sun. Doctor ai: Predicting clinical events via recurrent neural net- works. InMachine learning for healthcare conference, pages 301–318. PMLR, 2016
2016
-
[4]
Benjamin Shickel, Patrick James Tighe, Azra Bihorac, and Parisa Rashidi. Deep ehr: a survey of recent ad- vances in deep learning techniques for electronic health record (ehr) analysis.IEEE journal of biomedical and health informatics, 22(5):1589–1604, 2017
2017
-
[5]
Attention is all you need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. 21 Advances in neural information processing systems, 30, 2017
2017
-
[6]
Bert: Pre-training of deep bidi- rectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidi- rectional transformers for language understanding. InProceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pages 4171–4186, 2019
2019
-
[7]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020
1901
-
[8]
Llama: Open and effi- cient foundation language models.arXiv preprint arXiv:2302.13971, 2023
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Ham- bro, Faisal Azhar, et al. Llama: Open and effi- cient foundation language models.arXiv preprint arXiv:2302.13971, 2023
Pith/arXiv arXiv 2023
-
[9]
Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
Pith/arXiv arXiv 2023
-
[10]
Learning transferable visual models from natu- ral language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sas- try, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natu- ral language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[11]
Dinov2: Learning robust visual fea- tures without supervision.Transactions on Machine Learning Research Journal, 2024
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fer- nandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual fea- tures without supervision.Transactions on Machine Learning Research Journal, 2024
2024
-
[12]
Large language models encode clinical knowl- edge.Nature, 620(7972):172–180, 2023
Karan Singhal, Shekoofeh Azizi, Tao Tu, S Sara Mah- davi, Jason Wei, Hyung Won Chung, Nathan Scales, Ajay Tanwani, Heather Cole-Lewis, Stephen Pfohl, et al. Large language models encode clinical knowl- edge.Nature, 620(7972):172–180, 2023
2023
-
[13]
Toward expert-level medical question answering with large language models.Nature medicine, 31(3):943– 950, 2025
Karan Singhal, Tao Tu, Juraj Gottweis, Rory Sayres, Ellery Wulczyn, Mohamed Amin, Le Hou, Kevin Clark, Stephen R Pfohl, Heather Cole-Lewis, et al. Toward expert-level medical question answering with large language models.Nature medicine, 31(3):943– 950, 2025
2025
-
[14]
Foundation models for generalist medical artificial intelligence.Nature, 616 (7956):259–265, 2023
Michael Moor, Oishi Banerjee, Zahra Shakeri Hossein Abad, Harlan M Krumholz, Jure Leskovec, Eric J Topol, and Pranav Rajpurkar. Foundation models for generalist medical artificial intelligence.Nature, 616 (7956):259–265, 2023
2023
-
[15]
Towards generalist biomedical ai.Nejm Ai, 1(3): AIoa2300138, 2024
Tao Tu, Shekoofeh Azizi, Danny Driess, Mike Schaek- ermann, Mohamed Amin, Pi-Chuan Chang, Andrew Carroll, Charles Lau, Ryutaro Tanno, Ira Ktena, et al. Towards generalist biomedical ai.Nejm Ai, 1(3): AIoa2300138, 2024
2024
-
[16]
A large language model for electronic health records.NPJ digital medicine, 5(1): 194, 2022
Xi Yang, Aokun Chen, Nima PourNejatian, Hoo Chang Shin, Kaleb E Smith, Christopher Parisien, Colin Compas, Cheryl Martin, Anthony B Costa, Mona G Flores, et al. A large language model for electronic health records.NPJ digital medicine, 5(1): 194, 2022
2022
-
[17]
A visual-language foundation model for compu- tational pathology.Nature medicine, 30(3):863–874, 2024
Ming Y Lu, Bowen Chen, Drew FK Williamson, Richard J Chen, Ivy Liang, Tong Ding, Guillaume Jaume, Igor Odintsov, Long Phi Le, Georg Gerber, et al. A visual-language foundation model for compu- tational pathology.Nature medicine, 30(3):863–874, 2024
2024
-
[18]
Ecg-fm: An open elec- trocardiogram foundation model.Jamia Open, 8(5): ooaf122, 2025
Kaden McKeen, Sameer Masood, Augustin Toma, Barry Rubin, and Bo Wang. Ecg-fm: An open elec- trocardiogram foundation model.Jamia Open, 8(5): ooaf122, 2025
2025
-
[19]
Self-supervised learning in medicine and health- care.Nature Biomedical Engineering, 6(12):1346–1352, 2022
Rayan Krishnan, Pranav Rajpurkar, and Eric J Topol. Self-supervised learning in medicine and health- care.Nature Biomedical Engineering, 6(12):1346–1352, 2022
2022
-
[20]
Capabilities of gpt-4 on medical challenge problems.arXiv preprint arXiv:2303.13375, 2023
Harsha Nori, Nicholas King, Scott Mayer McKinney, Dean Carignan, and Eric Horvitz. Capabilities of gpt-4 on medical challenge problems.arXiv preprint arXiv:2303.13375, 2023
Pith/arXiv arXiv 2023
-
[21]
Can large language models reason about medical questions?Pat- terns, 5(3), 2024
Valentin Liévin, Christoffer Egeberg Hother, An- dreas Geert Motzfeldt, and Ole Winther. Can large language models reason about medical questions?Pat- terns, 5(3), 2024
2024
-
[22]
Survey of hallucination in natural language generation.ACM computing surveys, 55(12):1–38, 2023
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. Survey of hallucination in natural language generation.ACM computing surveys, 55(12):1–38, 2023
2023
-
[23]
Med-halt: Medical domain hallu- cination test for large language models
Ankit Pal, Logesh Kumar Umapathi, and Malaikan- nan Sankarasubbu. Med-halt: Medical domain hallu- cination test for large language models. InProceedings of the 27th Conference on Computational Natural Lan- guage Learning (CoNLL), pages 314–334, 2023
2023
-
[24]
Variable generalization performance of a deep learning model to detect pneumonia in chest radio- graphs: a cross-sectional study.PLoS medicine, 15 (11):e1002683, 2018
John R Zech, Marcus A Badgeley, Manway Liu, An- thony B Costa, Joseph J Titano, and Eric Karl Oer- mann. Variable generalization performance of a deep learning model to detect pneumonia in chest radio- graphs: a cross-sectional study.PLoS medicine, 15 (11):e1002683, 2018
2018
-
[25]
The clini- cian and dataset shift in artificial intelligence.New England Journal of Medicine, 385(3):283–286, 2021
Samuel G Finlayson, Adarsh Subbaswamy, Karan- deep Singh, John Bowers, Annabel Kupke, Jonathan Zittrain, Isaac S Kohane, and Suchi Saria. The clini- cian and dataset shift in artificial intelligence.New England Journal of Medicine, 385(3):283–286, 2021
2021
-
[26]
The limits of fair medicalimagingaiinreal-worldgeneralization.Nature medicine, 30(10):2838–2848, 2024
Yuzhe Yang, Haoran Zhang, Judy W Gichoya, Dina Katabi, and Marzyeh Ghassemi. The limits of fair medicalimagingaiinreal-worldgeneralization.Nature medicine, 30(10):2838–2848, 2024
2024
-
[27]
The myth of generalisability in clinical research and machine learning in health care.The Lancet Digital Health, 2 (9):e489–e492, 2020
Joseph Futoma, Morgan Simons, Trishan Panch, Fi- nale Doshi-Velez, and Leo Anthony Celi. The myth of generalisability in clinical research and machine learning in health care.The Lancet Digital Health, 2 (9):e489–e492, 2020. 22
2020
-
[28]
The false hope of current approaches to explainable artificial intelligence in health care.The lancet digital health, 3(11):e745–e750, 2021
Marzyeh Ghassemi, Luke Oakden-Rayner, and An- drew L Beam. The false hope of current approaches to explainable artificial intelligence in health care.The lancet digital health, 3(11):e745–e750, 2021
2021
-
[29]
Stop explaining black box machine learning models for high stakes decisions and use inter- pretable models instead.Nature machine intelligence, 1(5):206–215, 2019
Cynthia Rudin. Stop explaining black box machine learning models for high stakes decisions and use inter- pretable models instead.Nature machine intelligence, 1(5):206–215, 2019
2019
-
[30]
Behrt: transformer for electronic health records.Scientific reports, 10(1):7155, 2020
Yikuan Li, Shishir Rao, José Roberto Ayala Solares, Abdelaali Hassaine, Rema Ramakrishnan, Dexter Canoy, Yajie Zhu, Kazem Rahimi, and Gholamreza Salimi-Khorshidi. Behrt: transformer for electronic health records.Scientific reports, 10(1):7155, 2020
2020
-
[31]
Med-bert: pretrained contextualized em- beddings on large-scale structured electronic health records for disease prediction.NPJ digital medicine, 4(1):86, 2021
Laila Rasmy, Yang Xiang, Ziqian Xie, Cui Tao, and Degui Zhi. Med-bert: pretrained contextualized em- beddings on large-scale structured electronic health records for disease prediction.NPJ digital medicine, 4(1):86, 2021
2021
-
[32]
Cehr-bert: Incorporating tempo- ral information from structured ehr data to improve prediction tasks
Chao Pang, Xinzhuo Jiang, Krishna S Kalluri, Matthew Spotnitz, RuiJun Chen, Adler Perotte, and Karthik Natarajan. Cehr-bert: Incorporating tempo- ral information from structured ehr data to improve prediction tasks. InMachine learning for health, pages 239–260. PMLR, 2021
2021
-
[33]
MOTOR: A time-to-event foundation model for structured medical records
Ethan Steinberg, Jason Fries, Yizhe Xu, and Nigam Shah. MOTOR: A time-to-event foundation model for structured medical records. InICLR. OpenReview.net, 2024
2024
-
[34]
The shaky founda- tions of large language models and foundation models for electronic health records.npj digital medicine, 6 (1):135, 2023
Michael Wornow, Yizhe Xu, Rahul Thapa, Birju Patel, Ethan Steinberg, Scott Fleming, Michael A Pfeffer, Jason Fries, and Nigam H Shah. The shaky founda- tions of large language models and foundation models for electronic health records.npj digital medicine, 6 (1):135, 2023
2023
-
[35]
Ehrshot: An ehr bench- mark for few-shot evaluation of foundation models
Michael Wornow, Rahul Thapa, Ethan Steinberg, Ja- son Fries, and Nigam Shah. Ehrshot: An ehr bench- mark for few-shot evaluation of foundation models. Advances in Neural Information Processing Systems, 36:67125–67137, 2023
2023
-
[36]
Holistic evaluation of large language models for medical tasks with medhelm.Nature Medicine, pages 1–9, 2026
Suhana Bedi, Hejie Cui, Miguel Fuentes, Alyssa Unell, Michael Wornow, Juan M Banda, Nikesh Kotecha, Timothy Keyes, Yifan Mai, Mert Oez, et al. Holistic evaluation of large language models for medical tasks with medhelm.Nature Medicine, pages 1–9, 2026
2026
-
[37]
Medmcqa: A large-scale multi- subject multi-choice dataset for medical domain ques- tion answering
Ankit Pal, Logesh Kumar Umapathi, and Malaikan- nan Sankarasubbu. Medmcqa: A large-scale multi- subject multi-choice dataset for medical domain ques- tion answering. InConference on health, inference, and learning, pages 248–260. PMLR, 2022
2022
-
[38]
Next-generation phenotyping of electronic health records.Journal of the American Medical Informatics Association, 20(1): 117–121, 2013
George Hripcsak and David J Albers. Next-generation phenotyping of electronic health records.Journal of the American Medical Informatics Association, 20(1): 117–121, 2013
2013
-
[39]
Phewas: demonstrating the feasibility of a phenome-wide scan to discover gene– disease associations.Bioinformatics, 26(9):1205–1210, 2010
Joshua C Denny, Marylyn D Ritchie, Melissa A Bas- ford, Jill M Pulley, Lisa Bastarache, Kristin Brown- Gentry, Deede Wang, Dan R Masys, Dan M Roden, and Dana C Crawford. Phewas: demonstrating the feasibility of a phenome-wide scan to discover gene– disease associations.Bioinformatics, 26(9):1205–1210, 2010
2010
-
[40]
Observational health data sciences and informatics (ohdsi): opportunities for observational researchers.Studies in health technology and informatics, 216:574, 2015
George Hripcsak, Jon D Duke, Nigam H Shah, Chris- tian G Reich, Vojtech Huser, Martijn J Schuemie, Marc A Suchard, Rae Woong Park, Ian Chi Kei Wong, Peter R Rijnbeek, et al. Observational health data sciences and informatics (ohdsi): opportunities for observational researchers.Studies in health technology and informatics, 216:574, 2015
2015
-
[41]
Cohortnet: Em- powering cohort discovery for interpretable healthcare analytics.Proceedings of the VLDB Endowment, 17 (10):2487–2500, 2024
Qingpeng Cai, Kaiping Zheng, HV Jagadish, Beng Chin Ooi, and James Yip. Cohortnet: Em- powering cohort discovery for interpretable healthcare analytics.Proceedings of the VLDB Endowment, 17 (10):2487–2500, 2024
2024
-
[42]
Neuralcohort: Cohort-aware neural representa- tion learning for healthcare analytics
Changshuo Liu, Lingze Zeng, Kaiping Zheng, Shaofeng Cai, Beng Chin Ooi, and James Wei Luen Yip. Neuralcohort: Cohort-aware neural representa- tion learning for healthcare analytics. InForty-second International Conference on Machine Learning, 2025
2025
-
[43]
Exploiting negative samples: a catalyst for co- hort discovery in healthcare analytics
Kaiping Zheng, Horng-Ruey Chua, Melanie Herschel, HV Jagadish, Beng Chin Ooi, and James Wei Luen Yip. Exploiting negative samples: a catalyst for co- hort discovery in healthcare analytics. InForty-first International Conference on Machine Learning, 2024
2024
-
[44]
Benchmarking retrieval-augmented generation for medicine
Guangzhi Xiong, Qiao Jin, Zhiyong Lu, and Aidong Zhang. Benchmarking retrieval-augmented generation for medicine. InFindings of the Association for Com- putational Linguistics: ACL 2024, pages 6233–6251, 2024
2024
-
[45]
Ram-ehr: Retrieval augmentation meets clinical pre- dictions on electronic health records
Ran Xu, Wenqi Shi, Yue Yu, Yuchen Zhuang, Bowen Jin, May Dongmei Wang, Joyce Ho, and Carl Yang. Ram-ehr: Retrieval augmentation meets clinical pre- dictions on electronic health records. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 754–765, 2024
2024
-
[46]
Multimodal biomedical ai.Nature medicine, 28(9):1773–1784, 2022
Julián N Acosta, Guido J Falcone, Pranav Rajpurkar, and Eric J Topol. Multimodal biomedical ai.Nature medicine, 28(9):1773–1784, 2022
2022
-
[47]
Ai in health and medicine.Nature medicine, 28(1):31–38, 2022
Pranav Rajpurkar, Emma Chen, Oishi Banerjee, and Eric J Topol. Ai in health and medicine.Nature medicine, 28(1):31–38, 2022
2022
-
[48]
High-performance medicine: the con- vergence of human and artificial intelligence.Nature medicine, 25(1):44–56, 2019
Eric J Topol. High-performance medicine: the con- vergence of human and artificial intelligence.Nature medicine, 25(1):44–56, 2019
2019
-
[49]
Large language models in medicine.Nature medicine, 29(8):1930–1940, 2023
Arun James Thirunavukarasu, Darren Shu Jeng Ting, Kabilan Elangovan, Laura Gutierrez, Ting Fang Tan, and Daniel Shu Wei Ting. Large language models in medicine.Nature medicine, 29(8):1930–1940, 2023
1930
-
[50]
Publicly available clinical bert embed- dings
Emily Alsentzer, John Murphy, William Boag, Wei- Hung Weng, Di Jindi, Tristan Naumann, and Matthew McDermott. Publicly available clinical bert embed- dings. InProceedings of the 2nd clinical natural lan- guage processing workshop, pages 72–78, 2019
2019
-
[51]
Biobert: a pre-trained biomedical lan- guage representation model for biomedical text mining
Jinhyuk Lee, Wonjin Yoon, Sungdong Kim, Donghyeon Kim, Sunkyu Kim, Chan Ho So, and Jaewoo Kang. Biobert: a pre-trained biomedical lan- guage representation model for biomedical text mining. Bioinformatics, 36(4):1234–1240, 2020. 23
2020
-
[52]
Domain-specific language model pretraining for biomedical natural language processing.ACM Transactions on Comput- ing for Healthcare (HEALTH), 3(1):1–23, 2021
Yu Gu, Robert Tinn, Hao Cheng, Michael Lucas, Naoto Usuyama, Xiaodong Liu, Tristan Naumann, Jianfeng Gao, and Hoifung Poon. Domain-specific language model pretraining for biomedical natural language processing.ACM Transactions on Comput- ing for Healthcare (HEALTH), 3(1):1–23, 2021
2021
-
[53]
Biogpt: gen- erative pre-trained transformer for biomedical text generation and mining.Briefings in bioinformatics, 23(6):bbac409, 2022
Renqian Luo, Liai Sun, Yingce Xia, Tao Qin, Sheng Zhang, Hoifung Poon, and Tie-Yan Liu. Biogpt: gen- erative pre-trained transformer for biomedical text generation and mining.Briefings in bioinformatics, 23(6):bbac409, 2022
2022
-
[54]
Capa- bilities of gemini models in medicine.arXiv preprint arXiv:2404.18416, 2024
Khaled Saab, Tao Tu, Wei-Hung Weng, Ryutaro Tanno, David Stutz, Ellery Wulczyn, Fan Zhang, Tim Strother, Chunjong Park, Elahe Vedadi, et al. Capa- bilities of gemini models in medicine.arXiv preprint arXiv:2404.18416, 2024
Pith/arXiv arXiv 2024
-
[55]
Do we still need clinical language models? InConference on health, inference, and learning, pages 578–597
Eric Lehman, Evan Hernandez, Diwakar Mahajan, Jonas Wulff, Micah J Smith, Zachary Ziegler, Daniel Nadler, Peter Szolovits, Alistair Johnson, and Emily Alsentzer. Do we still need clinical language models? InConference on health, inference, and learning, pages 578–597. PMLR, 2023
2023
-
[56]
Chao Pang, Xinzhuo Jiang, Nishanth Parameshwar Pavinkurve, Krishna S Kalluri, Elise L Minto, Jason Patterson, Linying Zhang, George Hripcsak, Gamze Gürsoy, Noémie Elhadad, et al. Cehr-gpt: Generating electronic health records with chronological patient timelines.arXiv preprint arXiv:2402.04400, 2024
arXiv 2024
-
[57]
Sheng Zhang, Yanbo Xu, Naoto Usuyama, Hanwen Xu, Jaspreet Bagga, Robert Tinn, Sam Preston, Ra- jesh Rao, Mu Wei, Naveen Valluri, et al. Biomedclip: a multimodal biomedical foundation model pretrained from fifteen million scientific image-text pairs.arXiv preprint arXiv:2303.00915, 2023
Pith/arXiv arXiv 2023
-
[58]
A visual–language foundation model for pathology image analysis using medical twitter.Nature medicine, 29(9):2307–2316, 2023
Zhi Huang, Federico Bianchi, Mert Yuksekgonul, Thomas J Montine, and James Zou. A visual–language foundation model for pathology image analysis using medical twitter.Nature medicine, 29(9):2307–2316, 2023
2023
-
[59]
Med- flamingo: a multimodal medical few-shot learner
Michael Moor, Qian Huang, Shirley Wu, Michihiro Yasunaga, Yash Dalmia, Jure Leskovec, Cyril Zakka, Eduardo Pontes Reis, and Pranav Rajpurkar. Med- flamingo: a multimodal medical few-shot learner. In Machine learning for health (ML4H), pages 353–367. PMLR, 2023
2023
-
[60]
Guiding masked representation learn- ing to capture spatio-temporal relationship of electro- cardiogram
Yeongyeon Na, Minje Park, Yunwon Tae, and Sunghoon Joo. Guiding masked representation learn- ing to capture spatio-temporal relationship of electro- cardiogram. InICLR. OpenReview.net, 2024
2024
-
[61]
Deep learning for ecg analysis: Benchmarks and insights from ptb-xl.IEEE journal of biomedical and health informatics, 25(5):1519–1528, 2020
Nils Strodthoff, Patrick Wagner, Tobias Schaeffter, and Wojciech Samek. Deep learning for ecg analysis: Benchmarks and insights from ptb-xl.IEEE journal of biomedical and health informatics, 25(5):1519–1528, 2020
2020
-
[62]
Scaling wear- able foundation models
Girish Narayanswamy, Xin Liu, Kumar Ayush, Yuzhe Yang, Xuhai Xu, Shun Liao, Jake Garrison, Shyam Tailor, Jacob Sunshine, Yun Liu, et al. Scaling wear- able foundation models. InICLR. OpenReview.net, 2025
2025
-
[63]
Screen- ing for cardiac contractile dysfunction using an arti- ficial intelligence–enabled electrocardiogram.Nature medicine, 25(1):70–74, 2019
Zachi I Attia, Suraj Kapa, Francisco Lopez-Jimenez, Paul M McKie, Dorothy J Ladewig, Gaurav Satam, Patricia A Pellikka, Maurice Enriquez-Sarano, Pe- ter A Noseworthy, Thomas M Munger, et al. Screen- ing for cardiac contractile dysfunction using an arti- ficial intelligence–enabled electrocardiogram.Nature medicine, 25(1):70–74, 2019
2019
-
[64]
Zachi I Attia, Peter A Noseworthy, Francisco Lopez- Jimenez, Samuel J Asirvatham, Abhishek J Desh- mukh, Bernard J Gersh, Rickey E Carter, Xiaoxi Yao, Alejandro A Rabinstein, Brad J Erickson, et al. An artificial intelligence-enabled ecg algorithm for the identification of patients with atrial fibrillation during sinus rhythm: a retrospective analysis of ...
2019
-
[65]
Diyhealth suite: Dataset, model, and bench- mark for health management at home
Changshuo Liu, Junran Wu, Zhongle Xie, Wenqiao Zhang, Kaiping Zheng, Jiaqi Zhu, Qingpeng Cai, Ooi Gene Anne, Marcus Chun Jin Tan, Jianwei Yin, et al. Diyhealth suite: Dataset, model, and bench- mark for health management at home. InForty-third International Conference on Machine Learning, 2026
2026
-
[66]
On the opportunities and risks of foundation models.arXiv preprint arXiv:2108.07258, 2021
Rishi Bommasani, Drew A Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S Bernstein, Jeannette Bohg, Antoine Bosselut, Emma Brunskill, et al. On the opportunities and risks of foundation models.arXiv preprint arXiv:2108.07258, 2021
Pith/arXiv arXiv 2021
-
[67]
Transparent reporting of a multivariable prediction model for individual prognosis or diagnosis (tripod): the tripod statement
Gary S Collins, Johannes B Reitsma, Douglas G Alt- man, and Karel GM Moons. Transparent reporting of a multivariable prediction model for individual prognosis or diagnosis (tripod): the tripod statement. Journal of British Surgery, 102(3):148–158, 2015
2015
-
[68]
Tripod+ ai state- ment: updated guidance for reporting clinical predic- tion models that use regression or machine learning methods.bmj, 385, 2024
Gary S Collins, Karel GM Moons, Paula Dhiman, Richard D Riley, Andrew L Beam, Ben Van Calster, Marzyeh Ghassemi, Xiaoxuan Liu, Johannes B Re- itsma, Maarten Van Smeden, et al. Tripod+ ai state- ment: updated guidance for reporting clinical predic- tion models that use regression or machine learning methods.bmj, 385, 2024
2024
-
[69]
The tripod-llm reporting guideline for studies using large language models.Nature medicine, 31(1):60–69, 2025
Jack Gallifant, Majid Afshar, Saleem Ameen, Yin- dalon Aphinyanaphongs, Shan Chen, Giovanni Cac- ciamani, Dina Demner-Fushman, Dmitriy Dligach, Roxana Daneshjou, Chrystinne Fernandes, et al. The tripod-llm reporting guideline for studies using large language models.Nature medicine, 31(1):60–69, 2025
2025
-
[70]
Gram: graph- based attention model for healthcare representation learning
Edward Choi, Mohammad Taha Bahadori, Le Song, Walter F Stewart, and Jimeng Sun. Gram: graph- based attention model for healthcare representation learning. InProceedings of the 23rd ACM SIGKDD international conference on knowledge discovery and data mining, pages 787–795, 2017
2017
-
[71]
Patient subtyping via time- aware lstm networks
Inci M Baytas, Cao Xiao, Xi Zhang, Fei Wang, Anil K Jain, and Jiayu Zhou. Patient subtyping via time- aware lstm networks. InProceedings of the 23rd ACM SIGKDD international conference on knowledge dis- covery and data mining, pages 65–74, 2017
2017
-
[72]
Learn- ing tasks for multitask learning: Heterogenous patient populations in the icu
Harini Suresh, Jen J Gong, and John V Guttag. Learn- ing tasks for multitask learning: Heterogenous patient populations in the icu. InProceedings of the 24th 24 ACM SIGKDD International Conference on Knowl- edge Discovery & Data Mining, pages 802–810, 2018
2018
-
[73]
Protosteer: Steering deep sequence model with prototypes.IEEE transactions on visualization and computer graphics, 26(1):238–248, 2019
Yao Ming, Panpan Xu, Furui Cheng, Huamin Qu, and Liu Ren. Protosteer: Steering deep sequence model with prototypes.IEEE transactions on visualization and computer graphics, 26(1):238–248, 2019
2019
-
[74]
Mime: Multilevel medical embedding of elec- tronic health records for predictive healthcare.Ad- vances in neural information processing systems, 31, 2018
Edward Choi, Cao Xiao, Walter Stewart, and Jimeng Sun. Mime: Multilevel medical embedding of elec- tronic health records for predictive healthcare.Ad- vances in neural information processing systems, 31, 2018
2018
-
[75]
Electronic medical record phenotyping using the anchor and learn framework.Journal of the American Medical Informatics Association, 23(4): 731–740, 2016
Yoni Halpern, Steven Horng, Youngduck Choi, and David Sontag. Electronic medical record phenotyping using the anchor and learn framework.Journal of the American Medical Informatics Association, 23(4): 731–740, 2016
2016
-
[76]
A simple framework for con- trastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for con- trastive learning of visual representations. InInter- national conference on machine learning, pages 1597–
-
[77]
Momentum contrast for unsupervised visual representation learning
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9729–9738, 2020
2020
-
[78]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 9650– 9660, 2021
2021
-
[79]
Elda: learning explicit dual- interactions for healthcare analytics
Qingpeng Cai, Kaiping Zheng, Beng Chin Ooi, Wei Wang, and Chang Yao. Elda: learning explicit dual- interactions for healthcare analytics. In2022 IEEE 38th International Conference on Data Engineering (ICDE), pages 393–406. IEEE, 2022
2022
-
[80]
Arm-net: Adaptive relation modeling network for structured data
Shaofeng Cai, Kaiping Zheng, Gang Chen, HV Ja- gadish, Beng Chin Ooi, and Meihui Zhang. Arm-net: Adaptive relation modeling network for structured data. InProceedings of the 2021 international confer- ence on management of data, pages 207–220, 2021
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.