When Good Enough Is Optimal: Multiplication-Only Matrix Inversion Approximation for Quantized Gated DeltaNet
Pith reviewed 2026-06-28 02:32 UTC · model grok-4.3
The pith
Truncated Neumann expansion approximates matrix inversion in chunk-wise linear attention using only multiplications.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A MatMul-based algorithm for strictly lower-triangular matrices in chunk-wise linear attention uses a truncated Neumann expansion with structural masking and parallel residual correction to eliminate sequential dependencies; the approximation order and residual step are tuned to chunk size, and dynamic-range mitigation allows extension to low-bit INT while keeping model accuracy.
What carries the argument
Truncated Neumann expansion with structural masking and parallel residual correction for strictly lower-triangular matrices, adapted per chunk size.
If this is right
- Kernel-level speedups reach up to 5x with a 20% reduction in decode-layer overhead on Qwen3.5-family models.
- The method works under both floating-point and low-precision inference without accuracy loss.
- Adaptation of truncation order to chunk size keeps compute cost low while maintaining fidelity.
- The approach removes the sequential dependency of forward substitution, improving NPU utilization.
Where Pith is reading between the lines
- The same structural properties (diagonal concentration in inverses of lower-triangular attention matrices) may appear in other linear or state-space models, suggesting the technique could transfer beyond Gated DeltaNet.
- Hardware designers could exploit the multiplication-only nature to simplify NPU matrix units for attention workloads.
- Testing the approximation error growth with increasing chunk size would clarify the practical limit on context length.
Load-bearing premise
The inverse matrices exhibit enough diagonal concentration and the Neumann terms grow fast enough that a short truncated expansion plus masking and correction is accurate enough.
What would settle it
Measure the element-wise or operator-norm error of the approximated inverse against exact inversion on matrices extracted from real Qwen3.5 attention layers, or compare end-to-end model accuracy when swapping the approximation in and out.
Figures
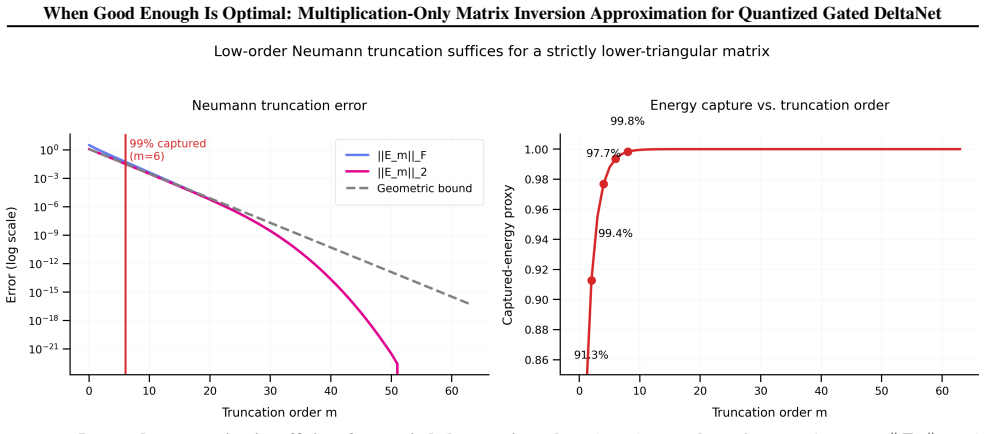
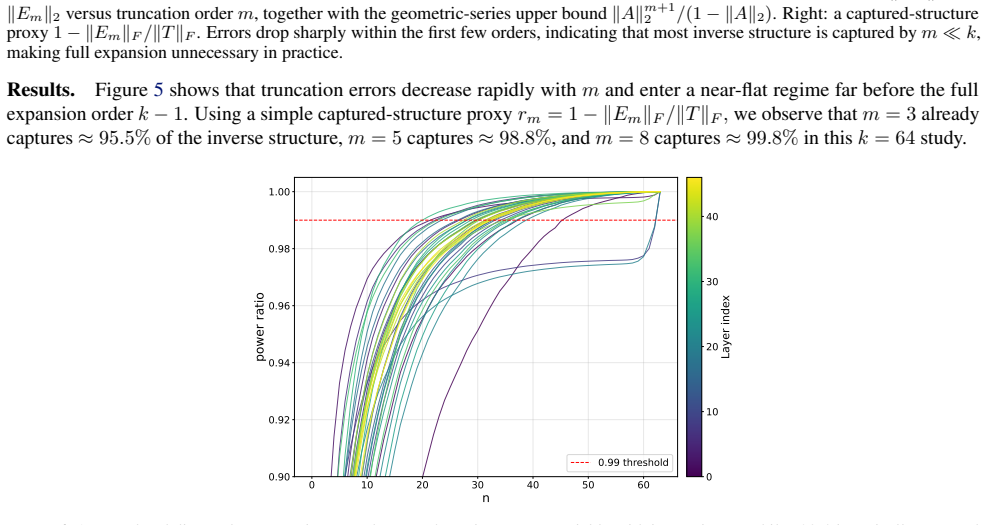
read the original abstract
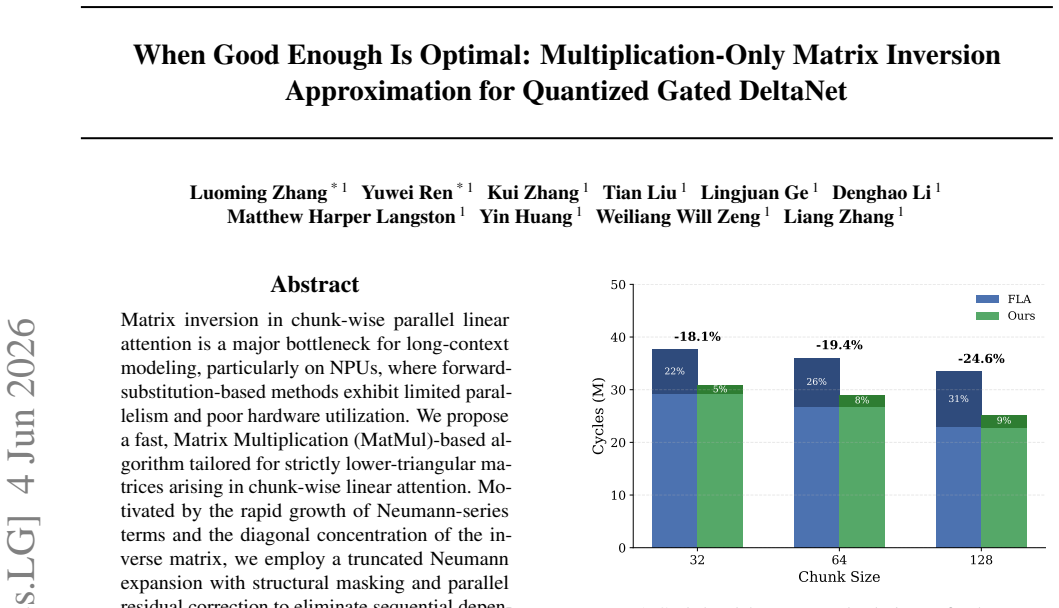
Matrix inversion in chunk-wise parallel linear attention is a major bottleneck for long-context modeling, particularly on NPUs, where forward-substitution-based methods exhibit limited parallelism and poor hardware utilization. We propose a fast, Matrix Multiplication (MatMul)-based algorithm tailored for strictly lower-triangular matrices arising in chunk-wise linear attention. Motivated by the rapid growth of Neumann-series terms and the diagonal concentration of the inverse matrix, we employ a truncated Neumann expansion with structural masking and parallel residual correction to eliminate sequential dependencies. We further extend our method to low-bits INT by mitigating the dynamic range expansion arising from repeated matrix power operations, and adapt the approximation order and residual step to the chunk size to minimize computational cost while preserving the model's accuracy. Experiments on Qwen3.5-family models demonstrate up to 5$\times$ kernel-level speedup and a 20% reduction in decode-layer overhead, while preserving accuracy under both floating-point and low-precision inference. Our method offers an efficient and hardware-friendly solution for scalable linear attention.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a MatMul-only approximation for inverting strictly lower-triangular matrices arising in chunk-wise Gated DeltaNet linear attention. It uses a truncated Neumann series plus structural masking and parallel residual correction to remove sequential dependencies, extends the approach to low-bit INT by controlling dynamic-range growth from matrix powers, and adapts approximation order and residual step size to chunk size. Experiments on Qwen3.5-family models are reported to yield up to 5× kernel speedup and 20% decode-layer overhead reduction while preserving accuracy in both FP and quantized inference.
Significance. If the approximation accuracy holds under the stated conditions, the method supplies a hardware-friendly, parallelizable alternative to forward substitution for linear attention on NPUs and quantized accelerators. The explicit handling of quantization-induced range expansion and the chunk-size adaptation are practical strengths that could aid scalable long-context deployment.
major comments (2)
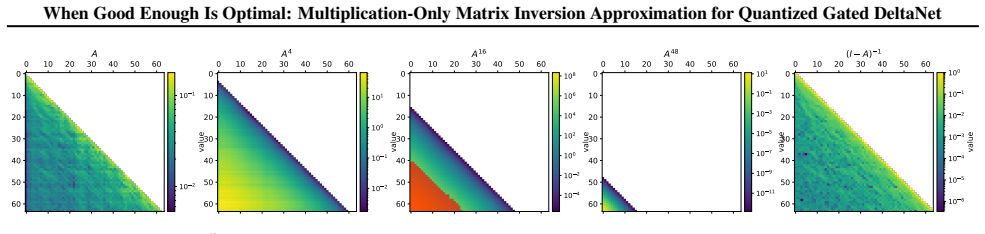
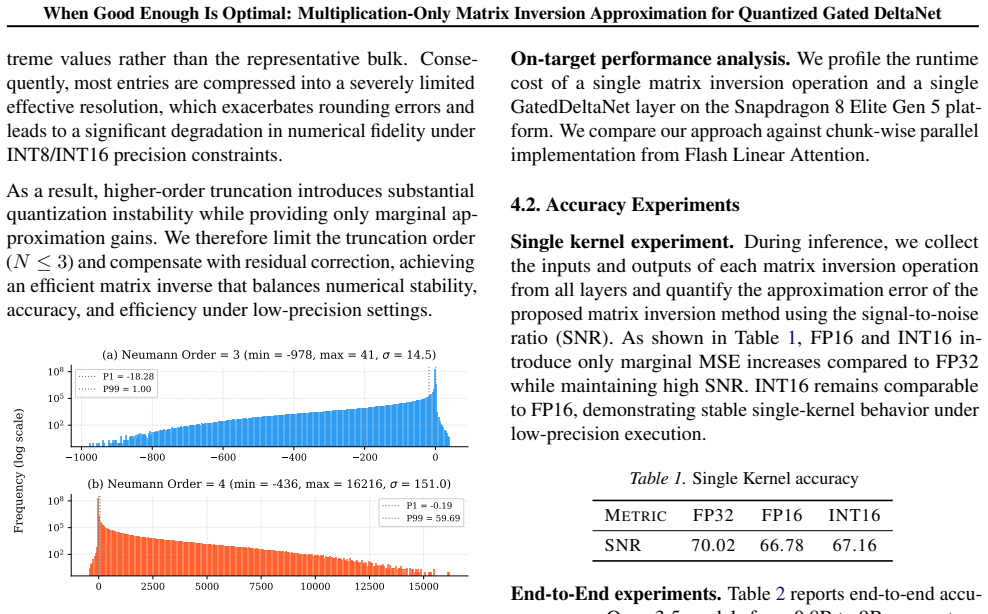
- [Abstract] Abstract (motivation paragraph): The truncation-plus-masking construction is justified by the claims of 'rapid growth of Neumann-series terms' and 'diagonal concentration of the inverse matrix,' yet no quantitative diagnostics (measured ||A^k|| decay rates, spectral-radius bounds, or off-diagonal mass fractions) are supplied for the actual strictly lower-triangular matrices produced by Gated DeltaNet chunks. These properties are load-bearing for the claim that truncation error remains negligible.
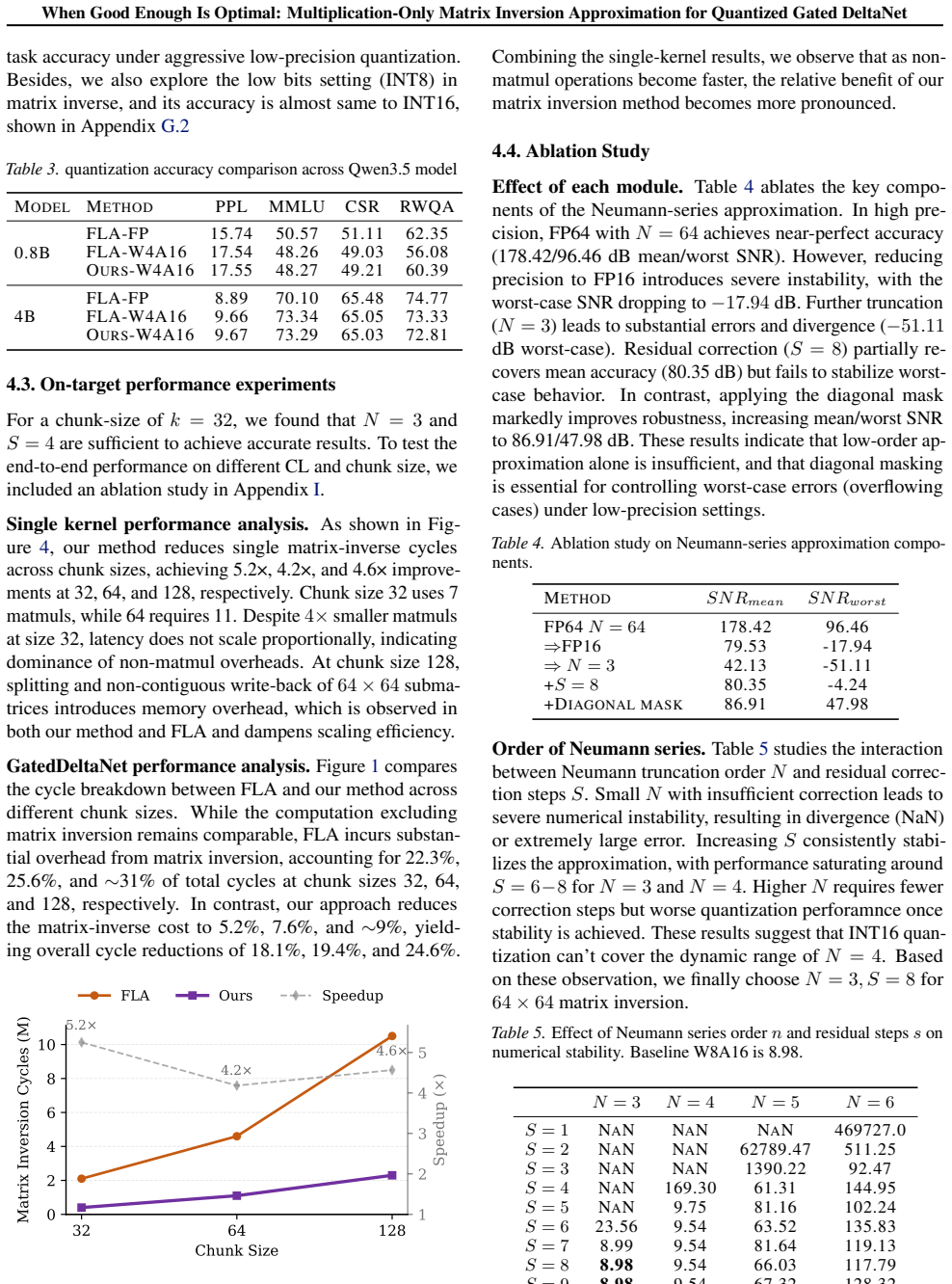
- [Experiments] Experiments (abstract claim): The reported 'up to 5× kernel-level speedup' and 'accuracy preservation' lack explicit baselines (exact forward-substitution timings, relative inversion error metrics, or chunk-size exclusion criteria), so the central empirical result cannot be assessed for robustness across the tested Qwen3.5 variants.
minor comments (1)
- The abstract refers to 'Qwen3.5-family models' without naming exact sizes or layer counts; adding this detail would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to incorporate the requested evidence and baselines.
read point-by-point responses
-
Referee: [Abstract] Abstract (motivation paragraph): The truncation-plus-masking construction is justified by the claims of 'rapid growth of Neumann-series terms' and 'diagonal concentration of the inverse matrix,' yet no quantitative diagnostics (measured ||A^k|| decay rates, spectral-radius bounds, or off-diagonal mass fractions) are supplied for the actual strictly lower-triangular matrices produced by Gated DeltaNet chunks. These properties are load-bearing for the claim that truncation error remains negligible.
Authors: We agree that explicit quantitative diagnostics on the Gated DeltaNet matrices are needed to support the truncation claims. Although the full manuscript motivates the approach via general properties of strictly lower-triangular matrices, we will add a new analysis subsection (or appendix) with measured ||A^k|| decay rates, spectral-radius bounds, and off-diagonal mass fractions computed directly on representative chunks from the Qwen3.5 models. This will provide the requested load-bearing evidence. revision: yes
-
Referee: [Experiments] Experiments (abstract claim): The reported 'up to 5× kernel-level speedup' and 'accuracy preservation' lack explicit baselines (exact forward-substitution timings, relative inversion error metrics, or chunk-size exclusion criteria), so the central empirical result cannot be assessed for robustness across the tested Qwen3.5 variants.
Authors: We concur that explicit baselines are required for proper assessment. The current experiments compare against a reference implementation, but we will expand the experiments section to report: direct wall-clock timings versus exact forward substitution, relative inversion error (e.g., normalized Frobenius distance to the exact inverse), chunk-size exclusion criteria, and per-variant results across all tested Qwen3.5 models. These additions will enable robustness evaluation. revision: yes
Circularity Check
No circularity; algorithmic proposal validated on external models
full rationale
The paper presents a MatMul-based approximation using truncated Neumann expansion, masking, and residual correction for strictly lower-triangular matrices in chunk-wise Gated DeltaNet. The motivation cites rapid Neumann-term growth and diagonal concentration, but these are treated as empirical properties verified by accuracy preservation on Qwen3.5-family models under FP and low-bit inference. No derivation step reduces a claimed result to a fitted parameter, self-citation chain, or input by construction. Experiments supply independent external benchmarks, so the work is self-contained.
Axiom & Free-Parameter Ledger
free parameters (2)
- approximation order
- residual correction step size
axioms (2)
- domain assumption Neumann series terms grow rapidly for the matrices in question
- domain assumption Inverse matrix is sufficiently diagonally concentrated
Reference graph
Works this paper leans on
-
[1]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[2]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[3]
M. J. Kearns , title =
-
[4]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[5]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[6]
Suppressed for Anonymity , author=
-
[7]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[8]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
-
[9]
Gomez and Lukasz Kaiser and Illia Polosukhin , editor =
Ashish Vaswani and Noam Shazeer and Niki Parmar and Jakob Uszkoreit and Llion Jones and Aidan N. Gomez and Lukasz Kaiser and Illia Polosukhin , editor =. Attention is All you Need , booktitle =. 2017 , url =
2017
-
[10]
Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention , booktitle =
Angelos Katharopoulos and Apoorv Vyas and Nikolaos Pappas and Fran. Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention , booktitle =. 2020 , url =
2020
-
[11]
Le , editor =
Weizhe Hua and Zihang Dai and Hanxiao Liu and Quoc V. Le , editor =. Transformer Quality in Linear Time , booktitle =. 2022 , url =
2022
-
[12]
The Thirteenth International Conference on Learning Representations,
Songlin Yang and Jan Kautz and Ali Hatamizadeh , title =. The Thirteenth International Conference on Learning Representations,. 2025 , url =
2025
-
[14]
Gated Linear Attention Transformers with Hardware-Efficient Training , booktitle =
Songlin Yang and Bailin Wang and Yikang Shen and Rameswar Panda and Yoon Kim , editor =. Gated Linear Attention Transformers with Hardware-Efficient Training , booktitle =. 2024 , url =
2024
-
[17]
2013 , publisher=
Matrix Computations , author=. 2013 , publisher=
2013
-
[18]
FLA: A Triton-Based Library for Hardware-Efficient Implementations of Linear Attention Mechanism , author =
-
[19]
2026 , howpublished =
Gemma 4: Frontier-Level Open Models , author =. 2026 , howpublished =
2026
-
[20]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[21]
5th International Conference on Learning Representations,
Stephen Merity and Caiming Xiong and James Bradbury and Richard Socher , title =. 5th International Conference on Learning Representations,. 2017 , url =
2017
-
[26]
9th International Conference on Learning Representations,
Dan Hendrycks and Collin Burns and Steven Basart and Andy Zou and Mantas Mazeika and Dawn Song and Jacob Steinhardt , title =. 9th International Conference on Learning Representations,. 2021 , url =
2021
-
[27]
2024 , howpublished =
RealWorldQA: A Real-World Visual Question Answering Benchmark , author =. 2024 , howpublished =
2024
-
[28]
2026 , publisher=
FlashQLA: Flash Qwen Linear Attention , author=. 2026 , publisher=
2026
-
[29]
gdn-tri-inverse: Evaluation of Gated Delta Networks with Triangular Matrix Inversion , howpublished =
-
[30]
Parallelizing Linear Transformers with the Delta Rule over Sequence Length , booktitle =
Songlin Yang and Bailin Wang and Yu Zhang and Yikang Shen and Yoon Kim , editor =. Parallelizing Linear Transformers with the Delta Rule over Sequence Length , booktitle =. 2024 , url =
2024
-
[34]
Efficiently Modeling Long Sequences with Structured State Spaces , booktitle =
Albert Gu and Karan Goel and Christopher R. Efficiently Modeling Long Sequences with Structured State Spaces , booktitle =. 2022 , url =
2022
-
[35]
Liu , title =
Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu , title =. J. Mach. Learn. Res. , volume =. 2020 , url =
2020
-
[38]
PIQA: Reasoning about physical commonsense in natural language
Bisk, Y., Zellers, R., Bras, R. L., Gao, J., and Choi, Y. PIQA: reasoning about physical commonsense in natural language. In The Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020, The Thirty-Second Innovative Applications of Artificial Intelligence Conference, IAAI 2020, The Tenth AAAI Symposium on Educational Advances in Artificial Inte...
-
[39]
B ool Q : Exploring the Surprising Difficulty of Natural Yes/No Questions
Clark, C., Lee, K., Chang, M., Kwiatkowski, T., Collins, M., and Toutanova, K. Boolq: Exploring the surprising difficulty of natural yes/no questions. In Burstein, J., Doran, C., and Solorio, T. (eds.), Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT ...
-
[40]
Think you have solved question answering? try arc, the AI2 reasoning challenge
Clark, P., Cowhey, I., Etzioni, O., Khot, T., Sabharwal, A., Schoenick, C., and Tafjord, O. Think you have solved question answering? try arc, the AI2 reasoning challenge. CoRR, abs/1803.05457, 2018. URL http://arxiv.org/abs/1803.05457
Pith/arXiv arXiv 2018
-
[41]
Golub, G. H. and Van Loan, C. F. Matrix Computations. Johns Hopkins University Press, 2013
2013
-
[42]
Gemma 4: Frontier-level open models
Google DeepMind . Gemma 4: Frontier-level open models. https://deepmind.google/models/gemma/gemma-4/, 2026. Model card and technical documentation
2026
-
[43]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Gu, A. and Dao, T. Mamba: Linear-time sequence modeling with selective state spaces. CoRR, abs/2312.00752, 2023. doi:10.48550/ARXIV.2312.00752. URL https://doi.org/10.48550/arXiv.2312.00752
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2312.00752 2023
-
[44]
Efficiently modeling long sequences with structured state spaces
Gu, A., Goel, K., and R \' e , C. Efficiently modeling long sequences with structured state spaces. In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022 . OpenReview.net, 2022. URL https://openreview.net/forum?id=uYLFoz1vlAC
2022
-
[45]
Measuring massive multitask language understanding
Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., and Steinhardt, J. Measuring massive multitask language understanding. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021 . OpenReview.net, 2021. URL https://openreview.net/forum?id=d7KBjmI3GmQ
2021
-
[46]
Hua, W., Dai, Z., Liu, H., and Le, Q. V. Transformer quality in linear time. In Chaudhuri, K., Jegelka, S., Song, L., Szepesv \' a ri, C., Niu, G., and Sabato, S. (eds.), International Conference on Machine Learning, ICML 2022, 17-23 July 2022, Baltimore, Maryland, USA , Proceedings of Machine Learning Research, pp.\ 9099--9117. PMLR , 2022. URL https://p...
2022
-
[47]
gdn-tri-inverse: Evaluation of gated delta networks with triangular matrix inversion
Huawei CSL . gdn-tri-inverse: Evaluation of gated delta networks with triangular matrix inversion. https://github.com/huawei-csl/gdn-tri-inverse, 2026
2026
-
[48]
Transformers are rnns: Fast autoregressive transformers with linear attention
Katharopoulos, A., Vyas, A., Pappas, N., and Fleuret, F. Transformers are rnns: Fast autoregressive transformers with linear attention. In Proceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event , Proceedings of Machine Learning Research, pp.\ 5156--5165. PMLR , 2020. URL http://proceedings.mlr.press...
2020
-
[49]
Liu, H., Li, C., Li, Y., and Lee, Y. J. Improved baselines with visual instruction tuning. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024 , pp.\ 26286--26296. IEEE , 2024. doi:10.1109/CVPR52733.2024.02484. URL https://doi.org/10.1109/CVPR52733.2024.02484
-
[50]
Pointer sentinel mixture models
Merity, S., Xiong, C., Bradbury, J., and Socher, R. Pointer sentinel mixture models. In 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings . OpenReview.net, 2017. URL https://openreview.net/forum?id=Byj72udxe
2017
-
[51]
Wind, Tianyi Wu, Daniel Wuttke, and Christian Zhou-Zheng
Peng, B., Zhang, R., Goldstein, D., Alcaide, E., Du, X., Hou, H., Lin, J., Liu, J., Lu, J., Merrill, W., Song, G., Tan, K., Utpala, S., Wilce, N., Wind, J. S., Wu, T., Wuttke, D., and Zhou - Zheng, C. RWKV-7 "goose" with expressive dynamic state evolution. CoRR, abs/2503.14456, 2025. doi:10.48550/ARXIV.2503.14456. URL https://doi.org/10.48550/arXiv.2503.14456
-
[52]
Qwen3.5 : Towards native multimodal agents, February 2026
Qwen Team . Qwen3.5 : Towards native multimodal agents, February 2026. URL https://qwen.ai/blog?id=qwen3.5
2026
-
[53]
Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., and Liu, P. J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res., 21: 0 140:1--140:67, 2020. URL https://jmlr.org/papers/v21/20-074.html
2020
-
[54]
Neural network quantization with AI model efficiency toolkit (AIMET)
Siddegowda, S., Fournarakis, M., Nagel, M., Blankevoort, T., Patel, C., and Khobare, A. Neural network quantization with AI model efficiency toolkit (AIMET) . CoRR, abs/2201.08442, 2022. URL https://arxiv.org/abs/2201.08442
arXiv 2022
-
[55]
Retentive Network: A Successor to Transformer for Large Language Models
Sun, Y., Dong, L., Huang, S., Ma, S., Xia, Y., Xue, J., Wang, J., and Wei, F. Retentive network: A successor to transformer for large language models. CoRR, abs/2307.08621, 2023. doi:10.48550/ARXIV.2307.08621. URL https://doi.org/10.48550/arXiv.2307.08621
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2307.08621 2023
-
[56]
Team, Q. Qwen3 technical report, 2025. URL https://arxiv.org/abs/2505.09388
Pith/arXiv arXiv 2025
-
[57]
N., Kaiser, L., and Polosukhin, I
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., and Polosukhin, I. Attention is all you need. In Guyon, I., von Luxburg, U., Bengio, S., Wallach, H. M., Fergus, R., Vishwanathan, S. V. N., and Garnett, R. (eds.), Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processi...
2017
-
[58]
Realworldqa: A real-world visual question answering benchmark
xAI . Realworldqa: A real-world visual question answering benchmark. https://huggingface.co/datasets/xai-org/RealworldQA, 2024. Released with Grok-1.5 Vision
2024
-
[59]
and Zhang, Y
Yang, S. and Zhang, Y. Fla: A triton-based library for hardware-efficient implementations of linear attention mechanism, January 2024. URL https://github.com/fla-org/flash-linear-attention
2024
-
[60]
Gated linear attention transformers with hardware-efficient training
Yang, S., Wang, B., Shen, Y., Panda, R., and Kim, Y. Gated linear attention transformers with hardware-efficient training. In Salakhutdinov, R., Kolter, Z., Heller, K. A., Weller, A., Oliver, N., Scarlett, J., and Berkenkamp, F. (eds.), Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024 , Proceedings of ...
2024
-
[61]
Gated delta networks: Improving mamba2 with delta rule
Yang, S., Kautz, J., and Hatamizadeh, A. Gated delta networks: Improving mamba2 with delta rule. In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025 . OpenReview.net, 2025 a . URL https://openreview.net/forum?id=r8H7xhYPwz
2025
-
[62]
Path attention: Position encoding via accumulating householder transformations
Yang, S., Shen, Y., Wen, K., Tan, S., Mishra, M., Ren, L., Panda, R., and Kim, Y. Path attention: Position encoding via accumulating householder transformations. CoRR, abs/2505.16381, 2025 b . doi:10.48550/ARXIV.2505.16381. URL https://doi.org/10.48550/arXiv.2505.16381
-
[63]
Zellers, R., Holtzman, A., Bisk, Y., Farhadi, A., and Choi, Y. Hellaswag: Can a machine really finish your sentence? In Korhonen, A., Traum, D. R., and M \` a rquez, L. (eds.), Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, July 28- August 2, 2019, Volume 1: Long Papers , pp.\ 4791--4800. As...
-
[64]
Flashqla: Flash qwen linear attention
Zhang, C., Lin, X., Jiang, H., Wang, Z., Li, X., Cao, Y., Zhuang, B., Men, R., Zhang, J., Zheng, B., Lin, J., Liu, D., and Zhou, J. Flashqla: Flash qwen linear attention. https://github.com/QwenLM/FlashQLA, 2026
2026
-
[65]
Zhang, Y., Lin, Z., Yao, X., Hu, J., Meng, F., Liu, C., Men, X., Yang, S., Li, Z., Li, W., Lu, E., Liu, W., Chen, Y., Xu, W., Yu, L., Wang, Y., Fan, Y., Zhong, L., Yuan, E., Zhang, D., Zhang, Y., Liu, T. Y., Wang, H., Fang, S., He, W., Liu, S., Li, Y., Su, J., Qiu, J., Pang, B., Yan, J., Jiang, Z., Huang, W., Yin, B., You, J., Wei, C., Wang, Z., Hong, C.,...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2510.26692 2025
-
[66]
Zhong, S., Xu, M., Ao, T., and Shi, G. Understanding transformer from the perspective of associative memory. CoRR, abs/2505.19488, 2025. doi:10.48550/ARXIV.2505.19488. URL https://doi.org/10.48550/arXiv.2505.19488
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.