Learning User-Aware Recall: Personalized Retrieval in Long-Term Conversational Memory
Pith reviewed 2026-07-04 00:35 UTC · model grok-4.3
The pith
User profiles derived from dialogue histories act as explicit priors that improve memory retrieval for individual users in long-term conversational agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
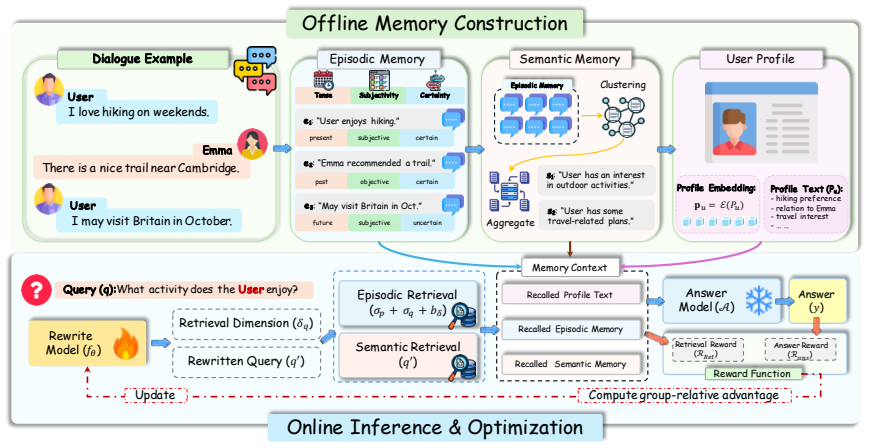
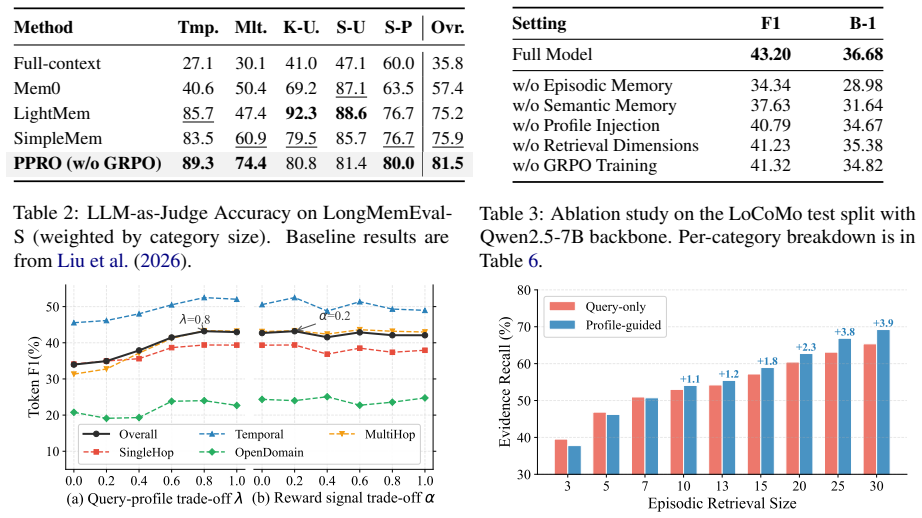
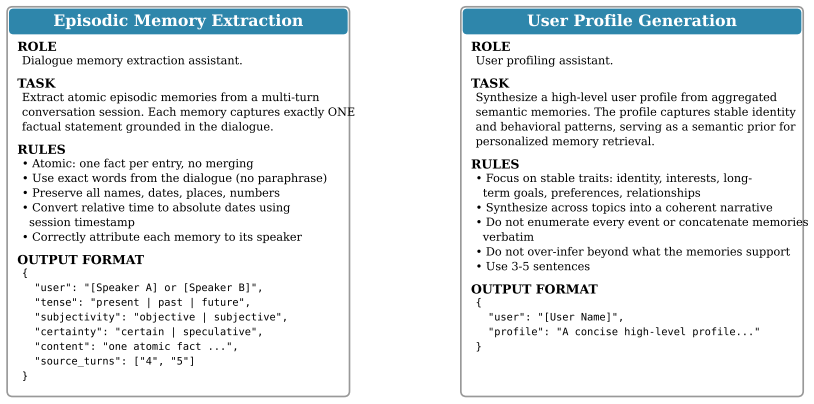
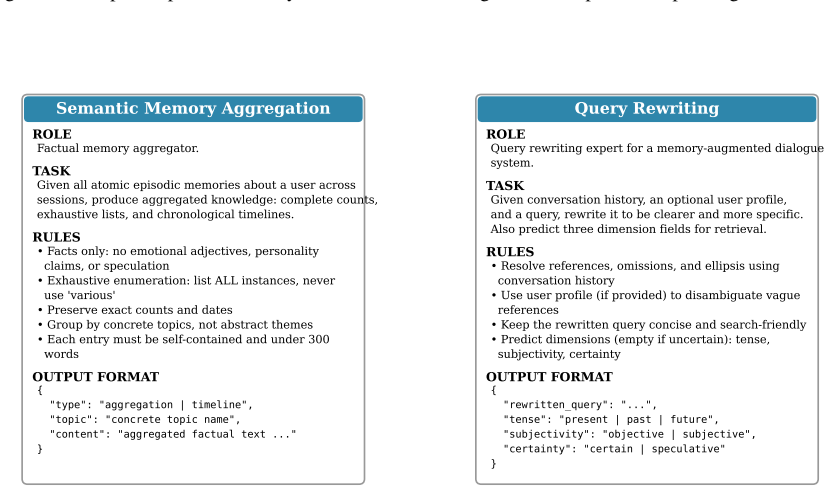
PPRO builds episodic and semantic memory banks from dialogue histories and derives a user profile from accumulated memories. The profile serves as an explicit personalized prior in memory ranking, allowing retrieval to account for stable user attributes, preferences, and relationships. PPRO further trains a query rewriter with Group Relative Policy Optimization, using both evidence retrieval quality and downstream answer quality as feedback while keeping the memory banks and answer model fixed. Experiments on LoCoMo and LongMemEval-S show consistent gains over training-free memory systems and training-based baselines.
What carries the argument
The user profile extracted from accumulated memories, used as an explicit personalized prior inside the memory-ranking step, together with a query rewriter trained by Group Relative Policy Optimization on dual retrieval-and-answer feedback.
If this is right
- Retrieval optimization can be performed independently of changes to the memory banks or the answer generation model.
- Both the profile-guided ranking component and the retrieval-oriented query rewriting component contribute measurably to the observed gains.
- Dual feedback from retrieval quality and final answer quality supplies sufficient supervision for the policy optimization of the rewriter.
- The same framework produces consistent improvements across the two evaluated long-term memory benchmarks.
Where Pith is reading between the lines
- The method could be extended by updating the user profile incrementally after each new conversation rather than deriving it only from the full history.
- Similar profile-guided ranking might apply to non-conversational retrieval settings if user-specific priors can be extracted from other interaction logs.
- Replacing Group Relative Policy Optimization with alternative reinforcement learning objectives would test whether the particular optimizer or the dual-feedback design is the main driver of improvement.
- Evaluating the approach on tasks that require cross-user generalization could reveal whether the derived profiles remain effective when the same memory bank serves multiple distinct users.
Load-bearing premise
Automatically derived user profiles from past memories reliably capture stable attributes, preferences, and relationships that remain useful for guiding future retrieval decisions.
What would settle it
A controlled run in which the user profile is removed from the ranking step or the query rewriter is trained without the dual quality feedback signals, yet performance stays the same as the full method, would show that these components are not responsible for the reported gains.
Figures

read the original abstract
Long-term conversational agents are expected to remember past interactions, but memory is useful only when the right evidence is recalled for the right user. Existing memory-augmented LLM agents have made progress in building compact memory banks, yet retrieval is still often driven by query-centered similarity or fixed ranking rules, leaving user-conditioned relevance underexplored. To address this gap, we propose Profile-guided Personalized Retrieval Optimization (PPRO), a retrieval-centric framework that makes memory retrieval both user-aware and optimizable. PPRO builds episodic and semantic memory banks from dialogue histories and derives a user profile from accumulated memories. The profile serves as an explicit personalized prior in memory ranking, allowing retrieval to account for stable user attributes, preferences, and relationships. PPRO further trains a query rewriter with Group Relative Policy Optimization, using both evidence retrieval quality and downstream answer quality as feedback while keeping the memory banks and answer model fixed. Experiments on LoCoMo and LongMemEval-S show consistent gains over training-free memory systems and training-based baselines. Ablation studies further show that both profile-guided ranking and retrieval-oriented rewriting contribute substantially to performance, highlighting retrieval optimization as a key factor in personalized long-term memory use.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Profile-guided Personalized Retrieval Optimization (PPRO), a retrieval-centric framework for long-term conversational agents. It constructs episodic and semantic memory banks from dialogue histories, derives a user profile from accumulated memories to act as an explicit personalized prior during memory ranking, and optimizes a query rewriter via Group Relative Policy Optimization (GRPO) using dual feedback from retrieval quality and downstream answer quality while freezing the memory banks and answer model. Experiments on LoCoMo and LongMemEval-S report consistent gains over training-free memory systems and training-based baselines, with ablations attributing substantial contributions to profile-guided ranking and retrieval-oriented rewriting.
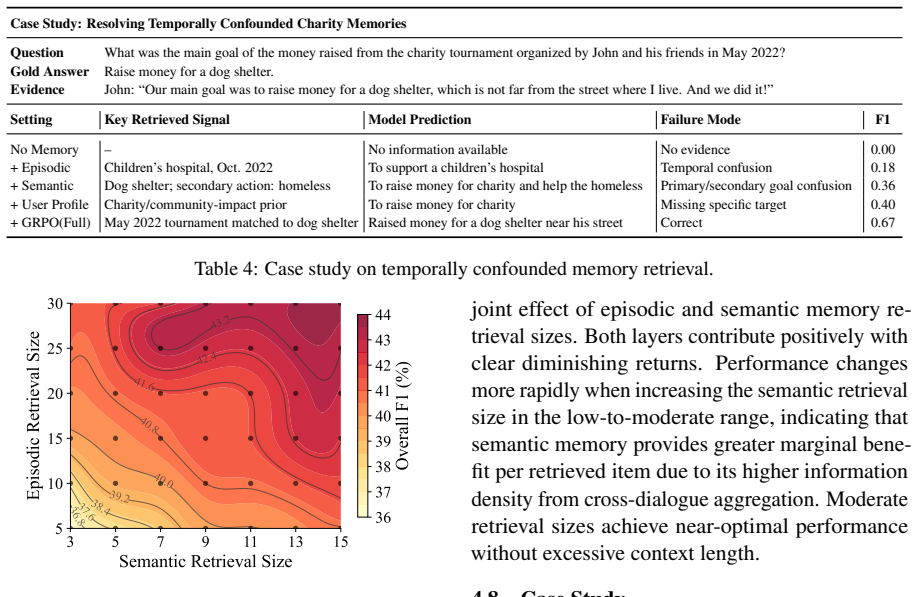
Significance. If the empirical gains hold under scrutiny, the work would advance personalized retrieval in memory-augmented LLMs by explicitly incorporating stable user attributes as a ranking prior and by making the rewriter optimizable via reinforcement signals tied to both retrieval and answer quality. The separation of profile derivation from the GRPO loop and the use of fixed downstream components are methodological strengths that could enable more targeted improvements in conversational memory systems. The paper earns credit for reproducible benchmark evaluations and component ablations that isolate the contributions of profile guidance and rewriting.
major comments (2)
- [Abstract and §3 (Method)] Abstract and §3 (Method): The central claim that the derived user profile functions as a reliable personalized prior in memory ranking is load-bearing and rests on the untested assumption that profiles extracted from episodic/semantic memories encode stable attributes rather than transient or contradictory dialogue content. The manuscript should add targeted analysis (e.g., profile consistency metrics across sessions or sensitivity tests to evolving preferences) to substantiate this; without it the reported ranking gains risk being driven by recency bias or noise.
- [§4 (Experiments) and ablation tables] §4 (Experiments) and ablation tables: The dual-feedback GRPO loop is presented as providing unbiased supervision, yet the frozen memory banks and answer model could embed biases that the policy simply amplifies. A load-bearing clarification is needed on whether additional controls (e.g., an ablation isolating retrieval-quality versus answer-quality rewards) demonstrate that the optimization corrects rather than reinforces existing retrieval shortcomings.
minor comments (2)
- Define all acronyms (PPRO, GRPO, LoCoMo, LongMemEval-S) on first use in the abstract and introduction.
- Clarify the precise reward formulation and group-relative baseline computation in the GRPO description for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Abstract and §3 (Method)] Abstract and §3 (Method): The central claim that the derived user profile functions as a reliable personalized prior in memory ranking is load-bearing and rests on the untested assumption that profiles extracted from episodic/semantic memories encode stable attributes rather than transient or contradictory dialogue content. The manuscript should add targeted analysis (e.g., profile consistency metrics across sessions or sensitivity tests to evolving preferences) to substantiate this; without it the reported ranking gains risk being driven by recency bias or noise.
Authors: We agree that explicit validation of profile stability would strengthen the central claim. While our ablations already isolate the contribution of profile-guided ranking and show consistent gains, we acknowledge the absence of dedicated consistency metrics. In the revised manuscript we will add profile consistency metrics across sessions together with sensitivity tests to evolving preferences. revision: yes
-
Referee: [§4 (Experiments) and ablation tables] §4 (Experiments) and ablation tables: The dual-feedback GRPO loop is presented as providing unbiased supervision, yet the frozen memory banks and answer model could embed biases that the policy simply amplifies. A load-bearing clarification is needed on whether additional controls (e.g., an ablation isolating retrieval-quality versus answer-quality rewards) demonstrate that the optimization corrects rather than reinforces existing retrieval shortcomings.
Authors: We appreciate the request for clarification on whether dual feedback corrects or amplifies biases. We will add the requested ablation that isolates the retrieval-quality reward from the answer-quality reward. The new results will be reported alongside the existing component ablations to show the effect of each signal. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper constructs episodic/semantic memory banks from dialogue histories, derives a user profile as an explicit prior for ranking, and optimizes a query rewriter via GRPO with external feedback signals while freezing the memory banks and answer model. No equations, definitions, or steps are shown that reduce by construction to fitted inputs, self-referential definitions, or load-bearing self-citations. The reported gains are presented as empirical outcomes on external benchmarks (LoCoMo, LongMemEval-S), making the derivation self-contained against those benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
AMEM4Rec : Leveraging Cross-User Similarity for Memory Evolution in Agentic LLM Recommenders
Nguyen, Minh-Duc and Kieu, Hai-Dang and Le, Dung D. AMEM4Rec : Leveraging Cross-User Similarity for Memory Evolution in Agentic LLM Recommenders. arXiv preprint arXiv:2602.08837. 2026
-
[9]
Inside Out: Evolving User-Centric Core Memory Trees for Long-Term Personalized Dialogue Systems
Zhao, Jihao and Chen, Ding and Fan, Zhaoxin and Xu, Kerun and Hu, Mengting and Tang, Bo and Xiong, Feiyu and Li, Zhiyu. Inside Out: Evolving User-Centric Core Memory Trees for Long-Term Personalized Dialogue Systems. arXiv preprint arXiv:2601.05171. 2026
-
[10]
Evaluating Very Long-Term Conversational Memory of LLM Agents
Maharana, Adyasha and Lee, Dong-Ho and Tulyakov, Sergey and Bansal, Mohit and Barbieri, Francesco and Fang, Yuwei. Evaluating Very Long-Term Conversational Memory of LLM Agents. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.747
-
[11]
Yan, Sikuan and Yang, Xiufeng and Huang, Zuchao and Nie, Ercong and Ding, Zifeng and Li, Zonggen and Ma, Xiaowen and Bi, Jinhe and Kersting, Kristian and Pan, Jeff Z. and Sch \"u tze, Hinrich and Tresp, Volker and Ma, Yunpu. Memory-R1 : Enhancing Large Language Model Agents to Manage and Utilize Memories via Reinforcement Learning. arXiv preprint arXiv:25...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Shao, Zhihong and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Song, Junxiao and Bi, Xiao and Zhang, Haowei and Zhang, Mingchuan and Li, Y. K. and Wu, Y. and Guo, Daya. DeepSeekMath : Pushing the Limits of Mathematical Reasoning in Open Language Models. arXiv preprint arXiv:2402.03300. 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
MaFeRw : Query Rewriting with Multi-Aspect Feedbacks for Retrieval-Augmented Large Language Models
Wang, Yujing and Zhang, Hainan and Pang, Liang and Guo, Binghui and Zheng, Hongwei and Zheng, Zhiming. MaFeRw : Query Rewriting with Multi-Aspect Feedbacks for Retrieval-Augmented Large Language Models. arXiv preprint arXiv:2408.17072. 2024
-
[14]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Chhikara, Prateek and Khant, Pankaj and Aryan, Saket and Singh, Taranjeet and Yadav, Deshraj. Mem0 : Building Production-Ready AI Agents with Scalable Long-Term Memory. arXiv preprint arXiv:2504.19413. 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
MemoryOS : A Memory Operating System for AI System
Kang, Zhifeng and Si, Xiaopeng and Zhang, Ziyi and Chen, Hangyu and Li, Peng and Li, Zhengpeng and Jiao, Weizhou and Tu, Zhaopeng. MemoryOS : A Memory Operating System for AI System. arXiv preprint arXiv:2506.06326. 2025
-
[16]
A-Mem : Agentic Memory for LLM Agents
Xu, Wujiang and Liang, Zujie and Mei, Kai and Gao, Hang and Tan, Juntao and Zhang, Yongfeng. A-Mem : Agentic Memory for LLM Agents. Advances in Neural Information Processing Systems. 2025
2025
-
[17]
LightMem : Cutting Token Costs with Efficient Memory Augmentation for LLM Agents
Fang, Xiaomin and Huang, Junjie and Liu, Ziyi and Zhang, Zhaohan and Zhang, Xin and Zhang, Yansong and Chen, Ningyu and Hu, Huajun. LightMem : Cutting Token Costs with Efficient Memory Augmentation for LLM Agents. arXiv preprint arXiv:2505.24845. 2025
-
[18]
On electric fields in hot QCD: infrared regularization dependence
Yue, Yanwei and Peng, Boci and Fan, Xuanbo and Guo, Jiaxin and Li, Qiankun and Zhang, Yan. Mem-T : Learning to Think with Memory for Complex Reasoning Tasks. arXiv preprint arXiv:2601.01478. 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
MEM1 : Learning to Synergize Memory and Reasoning for Efficient Long-Horizon Agents
Zhou, Han and Guo, Zhicheng and Zheng, Jinghan and Lu, Yuxin and Chang, Jonathan and Wang, Zelin and Zhang, Guangsheng and Xie, Tianyi and Feng, Yu and Wang, Xuezhi and Cheng, Chaoran and Wu, Kuan-Hao and Chen, Jiuhai and Cherif, Amine and Talukdar, Partha and Xu, Wenhu and Kong, Lingpeng and Yan, Zhuang. MEM1 : Learning to Synergize Memory and Reasoning ...
-
[20]
SimpleMem: Efficient Lifelong Memory for LLM Agents
Liu, Jiaqi and Su, Yaofeng and Xia, Peng and Han, Siwei and Zheng, Zeyu and Xie, Cihang and Ding, Mingyu and Yao, Huaxiu. SimpleMem : Efficient Lifelong Memory for LLM Agents. arXiv preprint arXiv:2601.02553. 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
MemGPT: Towards LLMs as Operating Systems
Packer, Charles and Fang, Vivian and Patil, Shishir G. and Lin, Kevin and Wooders, Sarah and Gonzalez, Joseph E. MemGPT : Towards LLMs as Operating Systems. arXiv preprint arXiv:2310.08560. 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
MemAgent: Reshaping Long-Context LLM with Multi-Conv RL-based Memory Agent
Lu, Yuhan and Zhang, Zhixin and Chen, Jing and Wang, Tao and Li, Songlin. MemAgent : Reshaping Long-Context LLM with Multi-Conv RL based Memory Agent. arXiv preprint arXiv:2507.02259. 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
SQuAD : 100,000+ Questions for Machine Comprehension of Text
Rajpurkar, Pranav and Zhang, Jian and Lopyrev, Konstantin and Liang, Percy. SQuAD : 100,000+ Questions for Machine Comprehension of Text. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. 2016
2016
-
[24]
BLEU : a Method for Automatic Evaluation of Machine Translation
Papineni, Kishore and Roukos, Salim and Ward, Todd and Zhu, Wei-Jing. BLEU : a Method for Automatic Evaluation of Machine Translation. Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics. 2002
2002
-
[25]
2025 , eprint=
HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models , author=. 2025 , eprint=
2025
-
[26]
2025 , eprint=
Zep: A Temporal Knowledge Graph Architecture for Agent Memory , author=. 2025 , eprint=
2025
-
[27]
2024 , eprint=
Cognitive Architectures for Language Agents , author=. 2024 , eprint=
2024
-
[28]
2024 , eprint=
Agent Q: Advanced Reasoning and Learning for Autonomous AI Agents , author=. 2024 , eprint=
2024
-
[29]
2025 , eprint=
Agent Planning with World Knowledge Model , author=. 2025 , eprint=
2025
-
[30]
2025 , eprint=
Long Term Memory: The Foundation of AI Self-Evolution , author=. 2025 , eprint=
2025
-
[31]
2026 , eprint=
Mem-T: Densifying Rewards for Long-Horizon Memory Agents , author=. 2026 , eprint=
2026
-
[32]
2024 , eprint=
IDGenRec: LLM-RecSys Alignment with Textual ID Learning , author=. 2024 , eprint=
2024
-
[33]
2025 , eprint=
Customizing Language Models with Instance-wise LoRA for Sequential Recommendation , author=. 2025 , eprint=
2025
-
[34]
2024 , eprint=
On Softmax Direct Preference Optimization for Recommendation , author=. 2024 , eprint=
2024
-
[35]
2024 , eprint=
On Generative Agents in Recommendation , author=. 2024 , eprint=
2024
-
[36]
2024 , eprint=
LEARN: Knowledge Adaptation from Large Language Model to Recommendation for Practical Industrial Application , author=. 2024 , eprint=
2024
-
[37]
Towards Lifelong Dialogue Agents via Timeline-based Memory Management
Bae, Namyoung and Oh, Jungmin and Kim, Yui and Park, Jaewoong and Kim, Gunhee. Towards Lifelong Dialogue Agents via Timeline-based Memory Management. Proceedings of the 2025 Conference of the North American Chapter of the Association for Computational Linguistics. 2025
2025
-
[38]
SynapticRAG : Enhancing Temporal Memory Retrieval in Large Language Models through Synaptic Mechanisms
Kim, Sehyun and Jang, Euisoon. SynapticRAG : Enhancing Temporal Memory Retrieval in Large Language Models through Synaptic Mechanisms. Findings of the Association for Computational Linguistics: ACL 2025. 2025
2025
-
[39]
In Prospect and Retrospect: Reflective Memory Management for Long-term Personalized Dialogue Agents
Liang, Zihao and Yang, Hongcheng and Li, Jing and Xu, Ran. In Prospect and Retrospect: Reflective Memory Management for Long-term Personalized Dialogue Agents. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics. 2025
2025
-
[40]
PRIME : Language Model Personalization with Cognitive Memory and Thought Processes
Zhu, Yiwen and Wang, Kuofeng and Yang, Zifan. PRIME : Language Model Personalization with Cognitive Memory and Thought Processes. arXiv preprint arXiv:2507.04607. 2025
-
[41]
Crafting Personalized Agents through Retrieval-Augmented Generation on Editable Memory Graphs
Lee, Zheng and others. Crafting Personalized Agents through Retrieval-Augmented Generation on Editable Memory Graphs. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024
2024
-
[42]
An Efficient Context-Dependent Memory Framework for LLM -Centric Agents
Wang, Yibin and others. An Efficient Context-Dependent Memory Framework for LLM -Centric Agents. Proceedings of the 2025 Conference of the North American Chapter of the Association for Computational Linguistics: Industry Track. 2025
2025
-
[43]
LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory , booktitle =
Di Wu and Hongwei Wang and Wenhao Yu and Yuwei Zhang and Kai. LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory , booktitle =. 2025 , url =
2025
-
[44]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models , author=
-
[45]
Text summarization branches out , pages=
Rouge: A package for automatic evaluation of summaries , author=. Text summarization branches out , pages=
-
[46]
Steven Bird and Ewan Klein and Edward Loper , title =
-
[47]
C-Pack: Packed Resources For General Chinese Embeddings
Shitao Xiao and Zheng Liu and Peitian Zhang and Niklas Muennighoff and Defu Lian and Jian-Yun Nie , title =. arXiv preprint arXiv:2309.07597 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
HybridFlow: A Flexible and Efficient RLHF Framework
Guangming Sheng and Chi Zhang and Zilingfeng Ye and Xibin Wu and Wang Zhang and Ru Zhang and Yanghua Peng and Haibin Lin and Chuan Wu , title =. arXiv preprint arXiv:2409.19256 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
u ttler, Heinrich and Lewis, Mike and Yih, Wen-tau and Rockt \
Lewis, Patrick and Perez, Ethan and Piktus, Aleksandra and Petroni, Fabio and Karpukhin, Vladimir and Goyal, Naman and K \"u ttler, Heinrich and Lewis, Mike and Yih, Wen-tau and Rockt \"a schel, Tim and Riedel, Sebastian and Kiela, Douwe. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. Advances in Neural Information Processing Systems. 2020
2020
-
[50]
Dense Passage Retrieval for Open-Domain Question Answering
Karpukhin, Vladimir and Oguz, Barlas and Min, Sewon and Lewis, Patrick and Wu, Ledell and Edunov, Sergey and Chen, Danqi and Yih, Wen-tau. Dense Passage Retrieval for Open-Domain Question Answering. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. 2020
2020
-
[51]
Query Rewriting in Retrieval-Augmented Large Language Models
Ma, Xinbei and Gong, Yeyun and He, Pengcheng and Zhao, Hai and Duan, Nan. Query Rewriting in Retrieval-Augmented Large Language Models. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023
2023
-
[52]
Training Language Models to Follow Instructions with Human Feedback
Ouyang, Long and Wu, Jeff and Jiang, Xu and Almeida, Diogo and Wainwright, Carroll and Mishkin, Pamela and Zhang, Chong and Agarwal, Sandhini and Slama, Katarina and Ray, Alex and Schulman, John and others. Training Language Models to Follow Instructions with Human Feedback. Advances in Neural Information Processing Systems. 2022
2022
-
[53]
Proximal Policy Optimization Algorithms
Schulman, John and Wolski, Filip and Dhariwal, Prafulla and Radford, Alec and Klimov, Oleg. Proximal Policy Optimization Algorithms. arXiv preprint arXiv:1707.06347. 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[54]
Personalizing Dialogue Agents: I have a dog, do you have pets too?
Zhang, Saizheng and Dinan, Emily and Urbanek, Jack and Szlam, Arthur and Kiela, Douwe and Weston, Jason. Personalizing Dialogue Agents: I have a dog, do you have pets too?. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2018
2018
-
[55]
Self- RAG : Learning to Retrieve, Generate, and Critique through Self-Reflection
Asai, Akari and Wu, Zeqiu and Wang, Yizhong and Sil, Avirup and Hajishirzi, Hannaneh. Self- RAG : Learning to Retrieve, Generate, and Critique through Self-Reflection. The Twelfth International Conference on Learning Representations. 2024
2024
- [56]
-
[57]
Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering
Izacard, Gautier and Grave, Edouard. Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering. Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics. 2021
2021
-
[58]
Query2doc: Query Expansion with Large Language Models
Wang, Liang and Yang, Nan and Wei, Furu. Query2doc: Query Expansion with Large Language Models. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023
2023
-
[59]
arXiv preprint arXiv:2602.13234 , year=
Stay in Character, Stay Safe: Dual-Cycle Adversarial Self-Evolution for Safety Role-Playing Agents , author=. arXiv preprint arXiv:2602.13234 , year=
-
[60]
2026 , publisher=
True-to-Role, Tailored-to-You: A Survey of LLM-based Role-Playing Agents , author=. 2026 , publisher=
2026
-
[61]
arXiv preprint arXiv:2603.19248 , year=
DuCCAE: A Hybrid Engine for Immersive Conversation via Collaboration, Augmentation, and Evolution , author=. arXiv preprint arXiv:2603.19248 , year=
-
[62]
Proceedings of the 29th ACM International Conference on Multimedia , pages=
Text is not enough: Integrating visual impressions into open-domain dialogue generation , author=. Proceedings of the 29th ACM International Conference on Multimedia , pages=
-
[63]
Proceedings of the 30th ACM International Conference on Information & Knowledge Management , pages=
Identifying untrustworthy samples: Data filtering for open-domain dialogues with bayesian optimization , author=. Proceedings of the 30th ACM International Conference on Information & Knowledge Management , pages=
-
[64]
ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Learning to select context in a hierarchical and global perspective for open-domain dialogue generation , author=. ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2021 , organization=
2021
-
[65]
Proceedings of the ACM on Web Conference 2025 , pages=
Auslanweb: A scalable web-based australian sign language communication system for deaf and hearing individuals , author=. Proceedings of the ACM on Web Conference 2025 , pages=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.