RAG-based EEG-to-Text Translation Using Deep Learning and LLMs
Pith reviewed 2026-05-20 12:42 UTC · model grok-4.3
The pith
A retrieval-augmented pipeline decodes sentences from single-trial EEG recordings better than random guessing without access to ground-truth labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
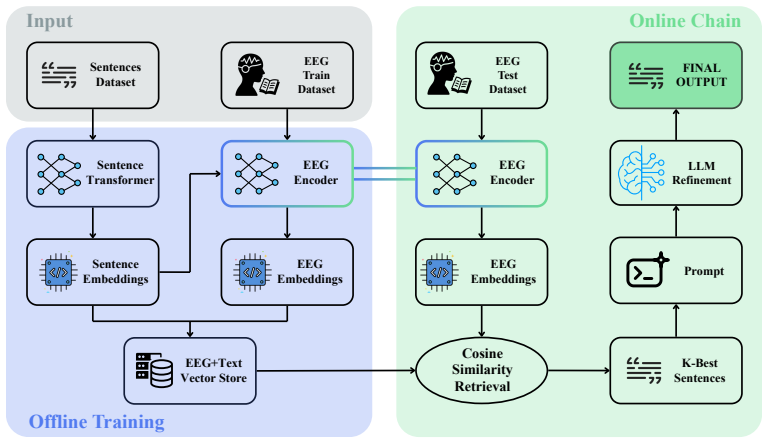
The authors demonstrate a RAG-based EEG-to-text pipeline that first aligns an EEG encoder with pre-trained semantic sentence embeddings, then retrieves candidate sentences via vector search, and finally uses an LLM to refine the retrieved text into fluent output. On the ZuCo dataset of single-trial EEG during silent reading, this pipeline produces outputs with mean cosine similarity 0.181 ± 0.022 across nine subjects, significantly higher than the 0.139 ± 0.029 achieved by a random-retrieval baseline, confirming that the system extracts linguistically relevant information under a no-ground-truth inference regime.
What carries the argument
The RAG pipeline that aligns EEG embeddings with semantic sentence vectors, retrieves nearest-neighbor sentences, and refines them with an LLM.
If this is right
- Meaningful sentence content can be recovered from EEG without teacher forcing or ground-truth labels at test time.
- Retrieval plus LLM refinement can compensate for the low signal-to-noise ratio typical of single-trial EEG.
- The same embedding-alignment step could be reused with other brain-signal modalities that produce vector representations.
- Performance gains are statistically detectable in small cohorts when strict label-free evaluation is enforced.
Where Pith is reading between the lines
- If the alignment generalizes across subjects, the method could support communication aids for people who cannot speak.
- The retrieval database could be expanded with larger text corpora to increase coverage of rare or complex sentences.
- Combining this pipeline with real-time EEG streaming might enable incremental sentence generation during ongoing reading or listening.
Load-bearing premise
The EEG encoder must produce embeddings that align with semantic sentence representations in a way that lets retrieval recover actual linguistic content rather than subject-specific noise.
What would settle it
Run the same pipeline on EEG recordings from a non-language task or on temporally shuffled EEG; if the cosine similarity advantage over random retrieval disappears, the claim that meaningful linguistic information is being extracted would be refuted.
Figures

read the original abstract
The decoding of linguistic information from electroencephalography (EEG) signals remains an extremely challenging problem in brain-computer interface (BCI) research. In particular, sentence-level decoding from EEG is difficult due to the low signal-to-noise ratio of these recordings. Previous studies tackling this problem have typically failed to surpass random baseline performance unless teacher forcing is used during the inference phase. In this work, we propose a retrieval-augmented generation (RAG)-based sentence-level EEG-to-text decoding pipeline that combines an EEG encoder aligned with semantic sentence embeddings, a vector retrieval stage, and a large language model (LLM) to refine retrieved sentences into coherent output. Experiments are conducted on the Zurich Cognitive Language Processing Corpus (ZuCo) dataset, which contains single-trial EEG recordings collected during silent reading. To evaluate whether the system extracts meaningful information from these EEG signals, the results are compared with a random baseline. In nine subjects, the proposed pipeline outperforms the random baseline, achieving a mean cosine similarity of 0.181 +- 0.022 compared to 0.139 +- 0.029 for the baseline, corresponding to a relative improvement of 30.45%. Statistical analysis further confirms that this improvement is significant, following a strict evaluation workflow where inference is performed without access to ground-truth labels.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a RAG-based pipeline for sentence-level EEG-to-text translation. It combines an EEG encoder aligned with semantic sentence embeddings, a vector retrieval stage over a corpus of sentences, and an LLM to refine the retrieved candidates into coherent output. On the ZuCo dataset, the approach is evaluated on nine subjects using single-trial EEG recordings from silent reading. The central result is that the pipeline achieves a mean cosine similarity of 0.181 ± 0.022 versus 0.139 ± 0.029 for a random baseline (30.45% relative improvement), with statistical significance, under an evaluation protocol that performs inference without access to ground-truth labels.
Significance. If the improvement is shown to arise from semantically meaningful EEG embeddings rather than subject-specific artifacts or dataset correlations, the work would be significant for BCI research. Prior studies have struggled to exceed random baselines at the sentence level without teacher forcing; the reported strict evaluation protocol and integration of retrieval with LLM refinement represent a practical advance. The manuscript earns credit for the reproducible-style evaluation workflow that avoids ground-truth leakage during inference.
major comments (3)
- [§3.2] §3.2 (EEG Encoder and Alignment): The alignment between EEG embeddings and semantic sentence representations is described at a high level, but the loss function, training objective, and any regularization against subject identity are not specified. This detail is load-bearing for the central claim, because without it the 30.45% gain could arise from retrieval of subject-specific recording artifacts that happen to correlate with sentence distributions in the test split rather than linguistic content.
- [§4.3] §4.3 (Data Partitioning and Retrieval Corpus): The construction of the retrieval corpus, the train/test split strategy, and any controls for subject leakage across folds are not reported. These omissions directly affect whether the cosine-similarity improvement can be attributed to the proposed pipeline or to inadvertent leakage of subject or session information.
- [§5.1] §5.1 (Statistical Analysis): The abstract states that the improvement is statistically significant, yet the exact test, degrees of freedom, correction for multiple comparisons across the nine subjects, and effect-size reporting are absent. This information is required to evaluate whether the reported p-value supports the claim that the pipeline extracts linguistically relevant content.
minor comments (2)
- [Abstract] The abstract mentions 'a vector retrieval stage' but does not name the embedding model or similarity metric used for retrieval; adding this in §3.3 would improve reproducibility.
- [Figure 2] Figure 2 (pipeline diagram) would benefit from explicit annotation of the train-time alignment loss versus inference-time retrieval path.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and for recognizing the value of our strict evaluation protocol without teacher forcing or ground-truth access. We address each major comment below and will revise the manuscript accordingly to improve clarity and reproducibility.
read point-by-point responses
-
Referee: [§3.2] §3.2 (EEG Encoder and Alignment): The alignment between EEG embeddings and semantic sentence representations is described at a high level, but the loss function, training objective, and any regularization against subject identity are not specified. This detail is load-bearing for the central claim, because without it the 30.45% gain could arise from retrieval of subject-specific recording artifacts that happen to correlate with sentence distributions in the test split rather than linguistic content.
Authors: We agree that a high-level description is insufficient for evaluating whether the embeddings capture linguistic content rather than artifacts. In the revised manuscript we will expand §3.2 to specify the exact loss function (contrastive alignment between EEG and sentence embeddings), the full training objective, optimization details, and any regularization or subject-identity mitigation steps used during encoder training. These additions will directly address the concern and allow readers to assess the source of the observed improvement. revision: yes
-
Referee: [§4.3] §4.3 (Data Partitioning and Retrieval Corpus): The construction of the retrieval corpus, the train/test split strategy, and any controls for subject leakage across folds are not reported. These omissions directly affect whether the cosine-similarity improvement can be attributed to the proposed pipeline or to inadvertent leakage of subject or session information.
Authors: We concur that explicit reporting of data partitioning is essential to rule out leakage. The revised manuscript will include a detailed description of the retrieval corpus construction, the precise train/test split procedure (including how sentences and subjects were handled to avoid overlap), and the controls implemented to prevent subject or session leakage across folds. This will strengthen the attribution of results to the RAG pipeline. revision: yes
-
Referee: [§5.1] §5.1 (Statistical Analysis): The abstract states that the improvement is statistically significant, yet the exact test, degrees of freedom, correction for multiple comparisons across the nine subjects, and effect-size reporting are absent. This information is required to evaluate whether the reported p-value supports the claim that the pipeline extracts linguistically relevant content.
Authors: We will revise §5.1 and the abstract to report the exact statistical test, degrees of freedom, any correction for multiple comparisons across subjects, and effect-size statistics. These details will be added to substantiate the significance claim and enable rigorous assessment of whether the pipeline extracts linguistically relevant information. revision: yes
Circularity Check
No circularity: empirical result measured against independent random baseline
full rationale
The paper reports an empirical performance comparison of a RAG-based EEG-to-text pipeline on the ZuCo dataset, with mean cosine similarity of 0.181 versus 0.139 for a random baseline (30.45% relative improvement, statistically significant). This result is obtained via standard embedding alignment, vector retrieval, and LLM refinement followed by evaluation without ground-truth labels at inference. No equations, derivations, or self-citations are presented that reduce the reported metric to a fitted parameter or input by construction. The random baseline is external and independent, rendering the central claim falsifiable rather than tautological. The paper contains no load-bearing uniqueness theorems, ansatzes smuggled via citation, or renaming of known results as novel derivations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A high-performance speech neuroprosthesis,
F. R. Willett, E. M. Kunz, C. Fan, D. T. Avansino, G. H. Wilson, E. Y . Choi, F. Kamdar, M. F. Glasser, L. R. Hochberg, S. Druckmann, K. V . Shenoy, and J. M. Henderson, “A high-performance speech neuroprosthesis,”Nature, 2023
work page 2023
-
[2]
An accurate and rapidly cal- ibrating speech neuroprosthesis,
N. S. Card, M. Wairagkar, C. Iacobacci, X. Hou, T. Singer-Clark, F. R. Willett, E. M. Kunz, C. Fan, M. V . Nia, D. R. Deo, A. Srinivasan, E. Y . Choi, M. F. Glasser, L. R. Hochberg, J. M. Henderson, K. Shahlaie, S. D. Stavisky, and D. M. Brandman, “An accurate and rapidly cal- ibrating speech neuroprosthesis,”New England Journal of Medicine, 2024
work page 2024
-
[3]
Noninvasive brain–machine interfaces for robotic devices,
L. Tonin and J. del R. Mill ´an, “Noninvasive brain–machine interfaces for robotic devices,”Annual Review of Control, Robotics, and Au- tonomous Systems, 2021
work page 2021
-
[4]
Evalu- ating EEG-to-text models through noise-based performance analysis,
H. Jo, Y . Yang, J. Han, Y . Duan, H. Xiong, and W. H. Lee, “Evalu- ating EEG-to-text models through noise-based performance analysis,” Scientific Reports, 2025
work page 2025
-
[5]
Thought2Text: Text generation from EEG signal using large language models (LLMs),
A. Mishra, S. Shukla, J. Torres, J. Gwizdka, and S. Roychowdhury, “Thought2Text: Text generation from EEG signal using large language models (LLMs),” 2025
work page 2025
-
[6]
Decoding brain representations by multimodal learning of neural activity and visual features,
S. Palazzo, C. Spampinato, I. Kavasidis, D. Giordano, J. Schmidt, and M. Shah, “Decoding brain representations by multimodal learning of neural activity and visual features,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021
work page 2021
-
[7]
Learning transferable visual models from natural language supervi- sion,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural language supervi- sion,” inProceedings of the 38th International Conference on Machine Learning, 2021
work page 2021
-
[8]
ZuCo, a simultaneous EEG and eye-tracking resource for natural sentence reading,
N. Hollenstein, J. Rotsztejn, M. Troendle, A. Pedroni, C. Zhang, and N. Langer, “ZuCo, a simultaneous EEG and eye-tracking resource for natural sentence reading,”Scientific Data, 2018
work page 2018
-
[9]
ZuCo 2.0: A dataset of physiological recordings during natural reading and annotation,
N. Hollenstein, M. Troendle, C. Zhang, and N. Langer, “ZuCo 2.0: A dataset of physiological recordings during natural reading and annotation,” 2020
work page 2020
-
[10]
Automagic: Standardized preprocessing of big EEG data,
A. Pedroni, A. Bahreini, and N. Langer, “Automagic: Standardized preprocessing of big EEG data,”NeuroImage, 2019
work page 2019
-
[11]
A. Delorme and S. Makeig, “EEGLAB: an open source toolbox for analysis of single-trial EEG dynamics including independent compo- nent analysis,”Journal of Neuroscience Methods, 2004
work page 2004
-
[12]
Automatic classification of artifactual ICA-components for artifact removal in EEG signals,
I. Winkler, S. Haufe, and M. Tangermann, “Automatic classification of artifactual ICA-components for artifact removal in EEG signals,” Behavioral and Brain Functions, 2011
work page 2011
-
[13]
Sentence-bert: Sentence embeddings using siamese bert-networks,
N. Reimers and I. Gurevych, “Sentence-bert: Sentence embeddings using siamese bert-networks,” inProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2019
work page 2019
-
[14]
Billion-scale similarity search with GPUs,
J. Johnson, M. Douze, and H. J ´egou, “Billion-scale similarity search with GPUs,”IEEE Transactions on Big Data, 2021
work page 2021
-
[15]
A. Grattafiori, A. Dubey, and the Llama Team, “The Llama 3 herd of models,” 2024
work page 2024
-
[16]
Nonparametric statistical infer- ence,
J. D. Gibbons and S. Chakraborti, “Nonparametric statistical infer- ence,” inInternational Encyclopedia of Statistical Science. Springer, 2025
work page 2025
-
[17]
A global analysis of metrics used for measuring performance in natural language processing,
K. Blagec, G. Dorffner, M. Moradi, S. Ott, and M. Samwald, “A global analysis of metrics used for measuring performance in natural language processing,” 2022
work page 2022
-
[18]
Supervised contrastive learning,
P. Khosla, P. Teterwak, C. Wang, A. Sarna, Y . Tian, P. Isola, A. Maschinot, C. Liu, and D. Krishnan, “Supervised contrastive learning,”Advances in Neural Information Processing Systems, 2020
work page 2020
-
[19]
Vision- language-action (VLA) models: Concepts, progress, applications and challenges
R. Sapkota, Y . Cao, K. I. Roumeliotis, and M. Karkee, “Vision- language-action (VLA) models: Concepts, progress, applications and challenges.”
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.