IntraShuffler: A Privacy Preserving Framework for Heterogeneous DP Federated Learning
Pith reviewed 2026-06-28 15:15 UTC · model grok-4.3
The pith
IntraShuffler groups clients by privacy budget and shuffles parameters inside buckets to block server inference in heterogeneous DP federated learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
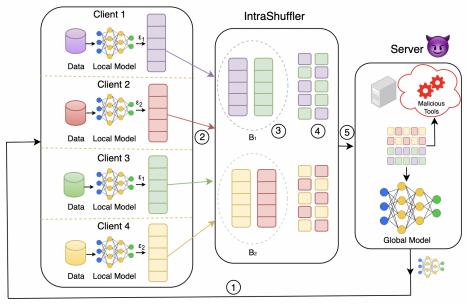
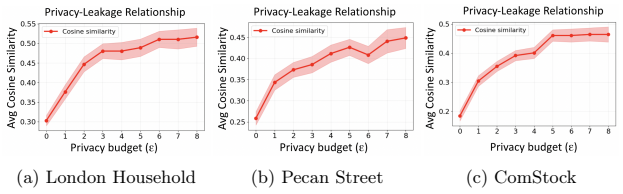
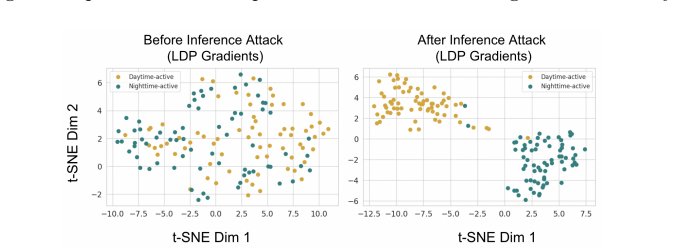
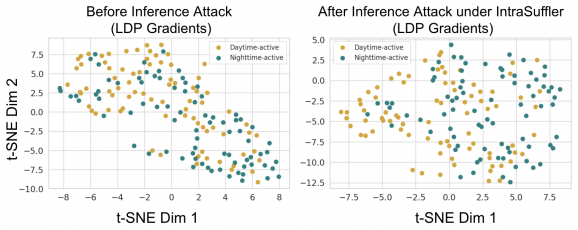
IntraShuffler groups clients into privacy-compatible buckets according to their individual ε values and performs parameter-level shuffling within each bucket. This mechanism breaks the structural signals that allow a server to perform privacy inference attacks while still permitting ε-aware aggregation that re-weights updates by declared privacy budgets. The result is a reduction in gradient recoverability by over 60 percent and a drop in surrogate inference accuracy from 0.78 to 0.33, with model utility remaining comparable to the undefended baseline across four datasets and multiple FL aggregation rules.
What carries the argument
Privacy-aware shuffling mechanism that groups clients into privacy-compatible buckets and performs parameter-level shuffling within each bucket to disrupt gradient structure while preserving ε-aware aggregation.
If this is right
- Gradient recoverability falls by over 60 percent.
- Surrogate inference accuracy drops from 0.78 to 0.33.
- Model utility stays comparable across multiple FL aggregation rules.
- The defense remains compatible with ε-aware server aggregation in HDP-FL.
Where Pith is reading between the lines
- The bucket-and-shuffle approach could be tested on client sets with highly unbalanced data volumes or extreme non-IID partitions.
- IntraShuffler might be stacked with existing noise-addition methods to achieve stronger privacy at the same utility level.
- The same grouping logic could apply to other server-side re-weighting schemes that currently leak client identity through update patterns.
Load-bearing premise
Grouping clients into privacy-compatible buckets and performing parameter-level shuffling within each bucket does not compromise the correctness or utility of ε-aware server aggregation.
What would settle it
An experiment in which IntraShuffler either leaves surrogate inference accuracy above 0.5 or reduces final model accuracy by more than a few percent relative to the baseline would show the central claim does not hold.
Figures
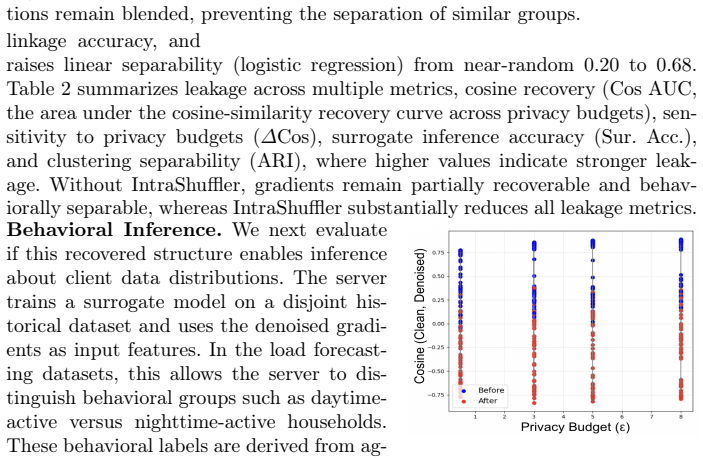
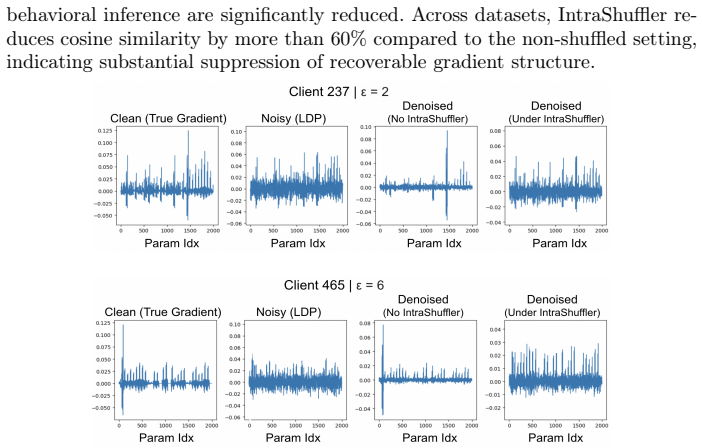
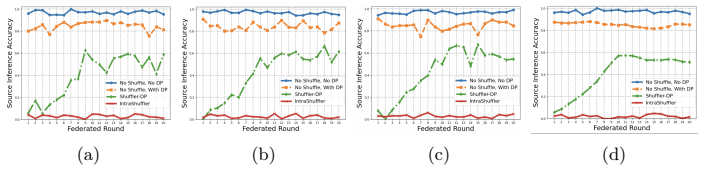
read the original abstract
Heterogeneous Differential Privacy (HDP) in Federated Learning (FL) allows clients to select individual privacy budgets ($\varepsilon_i$) according to institutional policies and data sensitivity. In practice, many HDP-FL systems employ $\varepsilon$-aware server aggregation to improve model utility by re-weighting client updates according to their declared privacy budgets. However, gradient updates in FL retain structural patterns induced by non-independent and identically-distributed (non-IID) data, and these additional signals exposed by $\varepsilon$-aware aggregation create new opportunities for inference by an honest-but-curious server. In this work, we first show that a server equipped with gradient denoising and surrogate modeling can mount a \emph{Privacy Inference Attack} that infers distributional attributes of clients and links updates from the same client across training rounds, measured via surrogate inference accuracy and linkage success, under realistic knowledge constraints. The Shuffle-Model has been widely studied as a defense against such inference risks by anonymizing update sources, but it is fundamentally incompatible with HDP-FL $\varepsilon$-aware aggregation. To address this challenge, we propose \textbf{IntraShuffler}, a middleware defense framework designed for HDP-FL systems. IntraShuffler introduces a privacy-aware shuffling mechanism that groups clients into privacy-compatible buckets and performs parameter-level shuffling within each bucket to disrupt persistent gradient structure while preserving $\varepsilon$-aware aggregation. Experiments across four different datasets show that IntraShuffler reduces gradient recoverability by over 60% and decreases surrogate inference accuracy from 0.78 to 0.33 while maintaining comparable model utility across multiple FL aggregation rules.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes IntraShuffler, a middleware framework for heterogeneous differential privacy federated learning (HDP-FL). Clients are grouped into privacy-compatible buckets and their updates undergo parameter-level shuffling within each bucket to disrupt persistent gradient structures that enable privacy inference attacks by an honest-but-curious server. The framework is claimed to remain compatible with ε-aware server aggregation (re-weighting updates by declared ε_i) while experiments on four datasets report >60% reduction in gradient recoverability, surrogate inference accuracy dropping from 0.78 to 0.33, and comparable model utility across multiple aggregation rules.
Significance. If the invariance of ε-aware aggregation under the described shuffling holds and the attack reductions are reproducible, the work would address a practical tension in HDP-FL between heterogeneous privacy budgets and inference risks from structural patterns in updates. The empirical focus on multiple datasets and aggregation rules is a strength, but the absence of derivations, attack implementation details, and ablation studies weakens the assessment of whether the central privacy-utility tradeoff is robustly achieved.
major comments (2)
- [Abstract] Abstract and the description of IntraShuffler: the central claim that parameter-level shuffling within privacy buckets leaves the outcome of ε-aware aggregation unchanged is asserted without a derivation or explicit mechanism (e.g., whether weights are applied before shuffling, whether the server restores per-client structure, or how the weighted sum remains invariant). This is load-bearing for both the utility and privacy-accounting claims.
- [Abstract] The reported attack reductions (gradient recoverability >60%, surrogate accuracy 0.78→0.33) rest on empirical measurements whose implementation, hyper-parameters, dataset statistics, and statistical significance are not provided, preventing verification of the quantitative claims.
minor comments (2)
- The abstract mentions experiments across four datasets and multiple FL aggregation rules but provides no table or section reference for the specific results, making it difficult to assess effect sizes or controls.
- Notation for ε_i and the precise definition of privacy-compatible buckets is introduced without an accompanying equation or algorithm listing.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify areas where the manuscript would benefit from additional formal justification and experimental transparency. We address each point below and will incorporate the necessary revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract and the description of IntraShuffler: the central claim that parameter-level shuffling within privacy buckets leaves the outcome of ε-aware aggregation unchanged is asserted without a derivation or explicit mechanism (e.g., whether weights are applied before shuffling, whether the server restores per-client structure, or how the weighted sum remains invariant). This is load-bearing for both the utility and privacy-accounting claims.
Authors: We agree that an explicit derivation is required. In the revised manuscript we will add a formal argument in Section 3 showing invariance: clients are partitioned into buckets sharing identical ε values; within each bucket all updates receive the same aggregation weight determined by that ε; parameter shuffling occurs after local computation but before transmission and is confined to the bucket; the server therefore applies the bucket-level weight to the received (shuffled) updates without restoring per-client ordering. Because shuffling is a permutation internal to a set of identically weighted vectors, the weighted sum is unchanged. The revised text will include the corresponding equations and a short proof of equivalence to the unshuffled case. revision: yes
-
Referee: [Abstract] The reported attack reductions (gradient recoverability >60%, surrogate accuracy 0.78→0.33) rest on empirical measurements whose implementation, hyper-parameters, dataset statistics, and statistical significance are not provided, preventing verification of the quantitative claims.
Authors: We acknowledge the need for greater experimental detail. The revision will expand the evaluation section and add an appendix containing: the surrogate model architecture and training hyperparameters, the gradient-denoising procedure, per-dataset client statistics and non-IID partitioning method, pseudocode for the privacy-inference attack, and results reported with standard deviations over five independent runs. These additions will allow independent verification of the reported reductions while preserving the original experimental conclusions. revision: yes
Circularity Check
No circularity; empirical claims with no self-referential derivations or load-bearing self-citations
full rationale
The paper presents a middleware framework (IntraShuffler) for HDP-FL that groups clients by privacy budget and performs intra-bucket parameter shuffling. All central claims—reduction in gradient recoverability, drop in surrogate inference accuracy from 0.78 to 0.33, and preservation of model utility—are supported solely by experimental measurements across four datasets and multiple aggregation rules. No equations, derivations, or uniqueness theorems appear in the provided text. The preservation of ε-aware aggregation is asserted as a design property of the bucketed shuffling mechanism but is not derived from prior self-citations or fitted parameters; it is treated as an empirical outcome. No steps reduce by construction to inputs, and no self-citation chains are load-bearing. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A survey on federated learning,
C. Zhang, Y. Xie, H. Bai, B. Yu, W. Li, and Y. Gao, “A survey on federated learning,”Knowledge-Based Systems, vol. 216, p. 106775, 2021
2021
-
[2]
Federated learning: Opportunities and challenges,
P. M. Mammen, “Federated learning: Opportunities and challenges,”arXiv preprint arXiv:2101.05428, 2021
arXiv 2021
-
[3]
Exploiting unintended feature leakage in collaborative learning,
L. Melis, C. Song, E. De Cristofaro, and V. Shmatikov, “Exploiting unintended feature leakage in collaborative learning,” in2019 IEEE symposium on security and privacy (SP). IEEE, 2019, pp. 691–706
2019
-
[4]
Inverting gradients – how easy is it to break privacy in federated learning?
J. Geiping, H. Bauermeister, J. Drögemüller, and M. Moeller, “Inverting gradients – how easy is it to break privacy in federated learning?” inNeurIPS, 2020. 16
2020
-
[5]
Deep learning with differential privacy,
M. Abadi, A. Chu, I. Goodfellow, H. B. McMahan, I. Mironov, K. Talwar, and L. Zhang, “Deep learning with differential privacy,” inProceedings of the 2016 ACM SIGSAC conference on computer and communications security, 2016
2016
-
[6]
Federated learning with differential privacy: Algorithms and performance analysis,
K.Wei,J.Li,M.Ding,C.Ma,H.H.Yang,F.Farokhi,S.Jin,T.Q.Quek,andH.V. Poor, “Federated learning with differential privacy: Algorithms and performance analysis,”IEEE transactions on information forensics and security, vol. 15, pp. 3454–3469, 2020
2020
-
[8]
Efficient federated learning privacy preservation method with heterogeneous differential privacy,
J. Ling, J. Zheng, and J. Chen, “Efficient federated learning privacy preservation method with heterogeneous differential privacy,”Computers & Security, vol. 139, p. 103715, 2024
2024
-
[9]
Distributed differential privacy via shuffling,
A. Cheu, A. Smith, J. Ullman, D. Zeber, and M. Zhilyaev, “Distributed differential privacy via shuffling,” inAdvances in Cryptology – EUROCRYPT 2019, ser. LNCS, vol. 11476. Springer, 2019, pp. 375–403
2019
-
[10]
Amplification by shuffling: From local to central differential privacy via anonymity,
Ú. Erlingsson, V. Feldman, I. Mironov, A. Raghunathan, K. Talwar, and A. Thakurta, “Amplification by shuffling: From local to central differential privacy via anonymity,” inProceedings of the Thirtieth Annual ACM-SIAM Symposium on Discrete Algorithms (SODA), 2019, pp. 2468–2479
2019
-
[11]
Prochlo: Strong privacy for an- alytics in the crowd,
A. Bittau, U. Erlingsson, P. Maniatis, I. Mironov, A. Raghunathan, D. Lie, M. Rudominer, U. Kode, J. Tinnes, and B. Seefeld, “Prochlo: Strong privacy for an- alytics in the crowd,” inProceedings of the 26th Symposium on Operating Systems Principles, ser. SOSP ’17. Association for Computing Machinery, 2017
2017
-
[12]
Projected federated averaging with heterogeneous differential privacy,
J. Liu, J. Lou, L. Xiong, J. Liu, and X. Meng, “Projected federated averaging with heterogeneous differential privacy,”Proceedings of the VLDB Endowment, vol. 15
-
[13]
The power of bias: Optimizing client selection in federated learning with heterogeneous differential privacy,
J. Ma, Y. Zhou, Q. Li, Q. Z. Sheng, L. Cui, and J. Liu, “The power of bias: Optimizing client selection in federated learning with heterogeneous differential privacy,”IEEE Transactions on Dependable and Secure Computing, 2025
2025
-
[14]
Optimal client sampling in federated learning with client-level heterogeneous differential privacy,
J. Xu, R. Hu, and O. Kotevska, “Optimal client sampling in federated learning with client-level heterogeneous differential privacy,”IEEE Internet of Things, 2026
2026
-
[15]
Deep leakage from gradients,
L. Zhu, Z. Liu, and S. Han, “Deep leakage from gradients,” inNeurIPS, 2019
2019
-
[16]
Comprehensive privacy analysis of deep learning: Passive and active white-box inference attacks against centralized and federated learning,
M. Nasr, R. Shokri, and A. Houmansadr, “Comprehensive privacy analysis of deep learning: Passive and active white-box inference attacks against centralized and federated learning,” in2019 IEEE symposium on security and privacy (SP). IEEE, 2019, pp. 739–753
2019
-
[17]
Source inference attacks in federated learning,
H. Hu, Z. Salcic, L. Sun, G. Dobbie, and X. Zhang, “Source inference attacks in federated learning,” in2021 IEEE International Conference on Data Mining (ICDM). IEEE, 2021, pp. 1102–1107
2021
-
[18]
Source infer- ence attacks: Beyond membership inference attacks in federated learning,
H. Hu, X. Zhang, Z. Salcic, L. Sun, K.-K. R. Choo, and G. Dobbie, “Source infer- ence attacks: Beyond membership inference attacks in federated learning,”IEEE Transactions on Dependable and Secure Computing, vol. 21, pp. 3012–3029, 2023
2023
-
[19]
Tor: The second-generation onion router,
R. Dingledine, N. Mathewson, and P. Syverson, “Tor: The second-generation onion router,” inProceedings of the 13th USENIX Security Symposium. USENIX, 2004, pp. 303–320
2004
-
[20]
Practical veri- fiable mix nets,
S. Hohenberger, M. Kohlweiss, A. Lysyanskaya, and H. Shacham, “Practical veri- fiable mix nets,” inIEEE Symposium on Security and Privacy, 2014, pp. 123–137
2014
-
[21]
Riposte:Ananonymousmessaging system handling millions of users,
H.Corrigan-Gibbs,D.Boneh,andD.Mazieres,“Riposte:Ananonymousmessaging system handling millions of users,” inIEEE Symposium on Security and Privacy, 2015, pp. 321–338. 17
2015
-
[22]
Secure multi-party shuffling for privacy- preserving data aggregation,
S. Lu, R. Ostrovsky, and V. Zikas, “Secure multi-party shuffling for privacy- preserving data aggregation,” inAdvances in Cryptology – EUROCRYPT, 2019
2019
-
[23]
Scalable secure shuffling via multi-party computa- tion,
I. Abraham, G. Asharovet al., “Scalable secure shuffling via multi-party computa- tion,” inProceedings of the ACM Conference on Computer and Communications Security (CCS), 2020
2020
-
[24]
Rafls: Rdp-based adaptive federated learning with shuffle model,
S. Wang, K. Gai, J. Yu, L. Zhu, H. Wu, C. Wei, Y. Yan, H. Zhang, and K.-K. R. Choo, “Rafls: Rdp-based adaptive federated learning with shuffle model,”IEEE Transactions on Dependable and Secure Computing, vol. 22, pp. 1181–1194, 2025
2025
-
[25]
Secure shuffling for federated learning,
R. Sunet al., “Secure shuffling for federated learning,” inNeurIPS Workshop, 2020
2020
-
[26]
Privacy amplification in federated learning via shuffle mecha- nisms,
M. Lebrunet al., “Privacy amplification in federated learning via shuffle mecha- nisms,”arXiv preprint, 2022
2022
-
[27]
Shufflefl: Improving privacy in federated learning via shuffling,
Z. Yanget al., “Shufflefl: Improving privacy in federated learning via shuffling,” arXiv preprint, 2023
2023
-
[28]
Flame: Differentially private federated learning in the shuffle model,
R. Liu, Y. Cao, H. Chen, R. Guo, and M. Yoshikawa, “Flame: Differentially private federated learning in the shuffle model,” inAAAI, 2021, pp. 8686–8694
2021
-
[29]
Conservative or liberal? personalized dif- ferential privacy,
Z. Jorgensen, T. Yu, and G. Cormode, “Conservative or liberal? personalized dif- ferential privacy,” inICDE, 2015
2015
-
[30]
Heterogeneous differential- private federated learning: Trading privacy for utility truthfully,
X. Lin, J. Wu, J. Li, C. Sang, S. Hu, and M. J. Deen, “Heterogeneous differential- private federated learning: Trading privacy for utility truthfully,”IEEE Transac- tions on Dependable and Secure Computing, vol. 20, no. 6, pp. 5113–5129, 2023
2023
-
[31]
Tight bounds for privacy amplification by shuffling,
V. Balceret al., “Tight bounds for privacy amplification by shuffling,”arXiv preprint, 2022
2022
-
[32]
Echo of neighbors: Privacy amplification for personalized private federated learning with shuffle model,
Y. Liu, S. Zhao, L. Xiong, Y. Liu, and H. Chen, “Echo of neighbors: Privacy amplification for personalized private federated learning with shuffle model,” in Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2023
2023
-
[33]
Clustered federated learning with adaptive local differential privacy on heterogeneous iot data,
Z. He, L. Wang, and Z. Cai, “Clustered federated learning with adaptive local differential privacy on heterogeneous iot data,”IEEE Internet of Things Journal, vol. 11, no. 1, pp. 137–146, 2023
2023
-
[34]
Protection against source infer- ence attacks in federated learning,
A. Athanasiou, K. Jung, and C. Palamidessi, “Protection against source infer- ence attacks in federated learning,” inThe fourteenth International Conference on Learning Representations (ICLR), 2026
2026
-
[35]
Federated learning with hetero- geneous differential privacy,
T. Li, A. K. Sahu, A. Talwalkar, and V. Smith, “Federated learning with hetero- geneous differential privacy,” inInternational Conference on Artificial Intelligence and Statistics (AISTATS), 2022
2022
-
[36]
Differential privacy in the shuffle model: A survey of separations,
A. Cheu, “Differential privacy in the shuffle model: A survey of separations,” 2022. [Online]. Available: https://arxiv.org/abs/2107.11839
arXiv 2022
-
[37]
Im- proving utility and security of the shuffler-based differential privacy,
T. Wang, B. Ding, M. Xu, Z. Huang, C. Hong, J. Zhou, N. Li, and S. Jha, “Im- proving utility and security of the shuffler-based differential privacy,”Proc. VLDB Endow., vol. 13, no. 13, p. 3545–3558, 2020. Acknowledgment This material is based upon work supported by the U.S. Department of En- ergy, Office of Science, Office of Advanced Scientific Computin...
2020
-
[38]
In theIID case, clients receive balanced class mix- tures, while in thenon-IIDcase, clients exhibit class-skew with imbalanced label distributions
Both settings use the same number of clients and samples per client. In theIID case, clients receive balanced class mix- tures, while in thenon-IIDcase, clients exhibit class-skew with imbalanced label distributions. Partition Plain Shuffle Intra IID ≈1/n t ≈1/n t ≈1/n t Non-IID 0.42 0.31 0.12 Table 11: IID vs non-IID Cross-round linkage. Random baseline ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.