Beyond Skeletons: Learning Animation Directly from Driving Videos with Same2X Training Strategy
Pith reviewed 2026-06-27 22:39 UTC · model grok-4.3
The pith
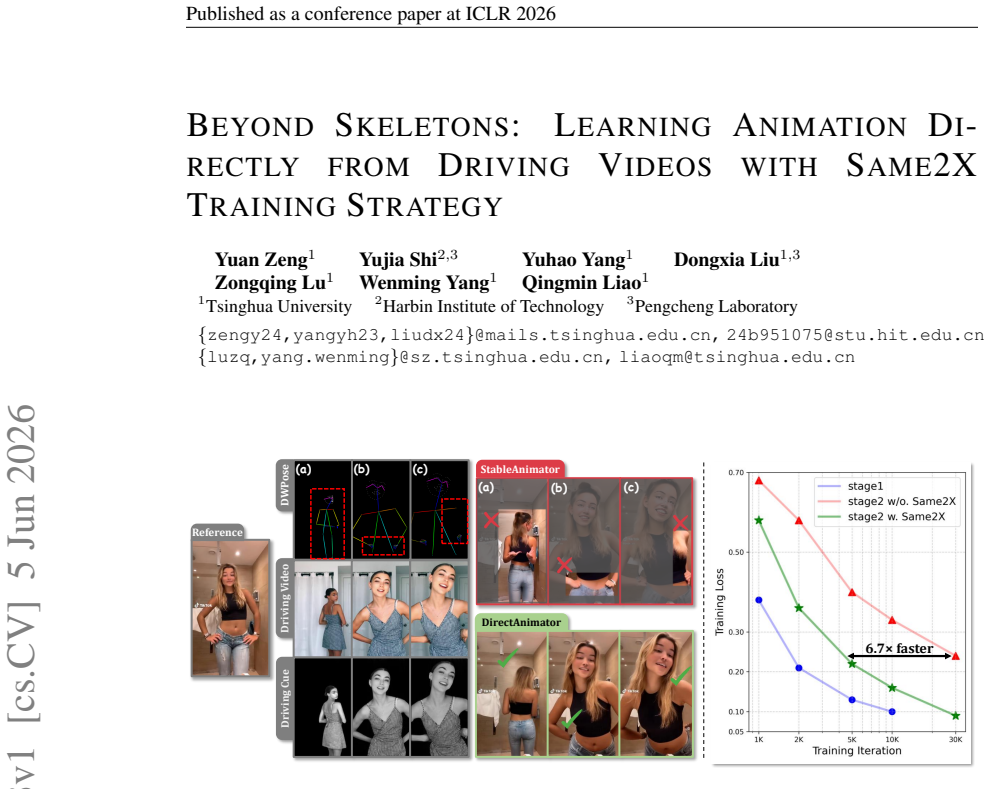
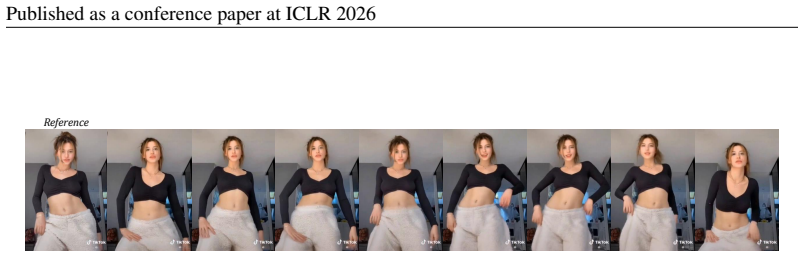
DirectAnimator generates animated videos by learning motion directly from driving videos rather than extracted poses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
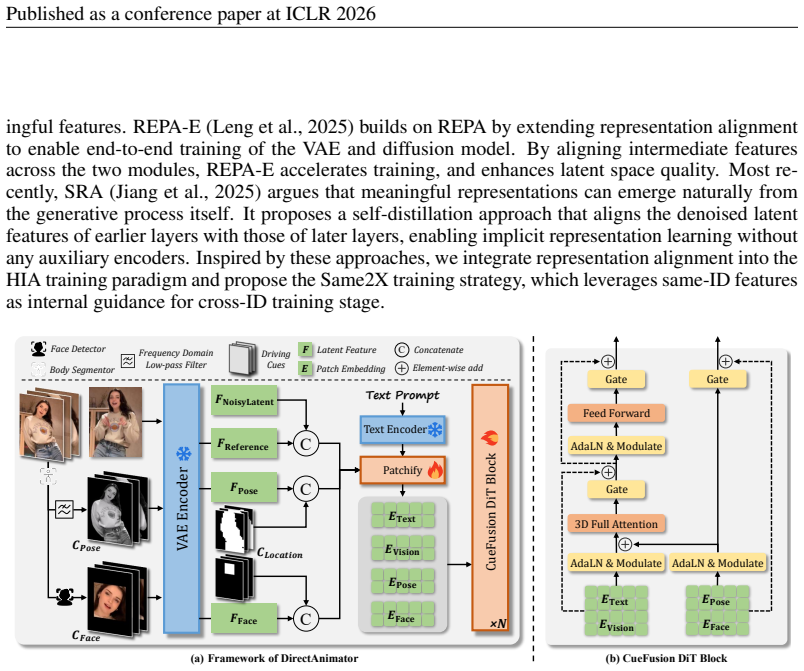
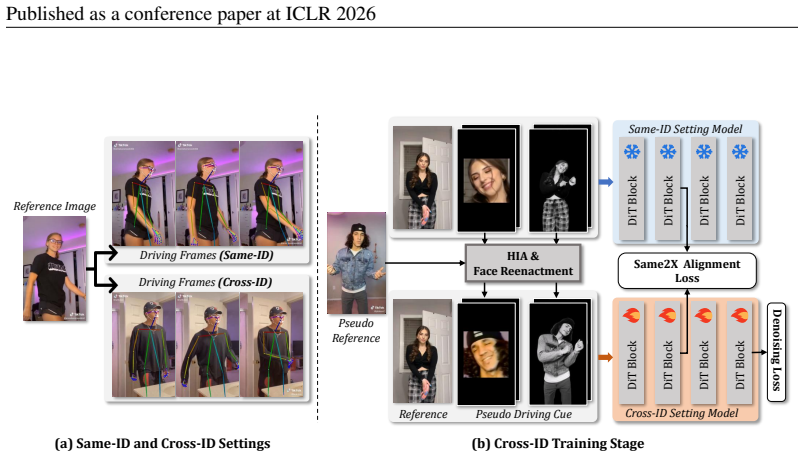
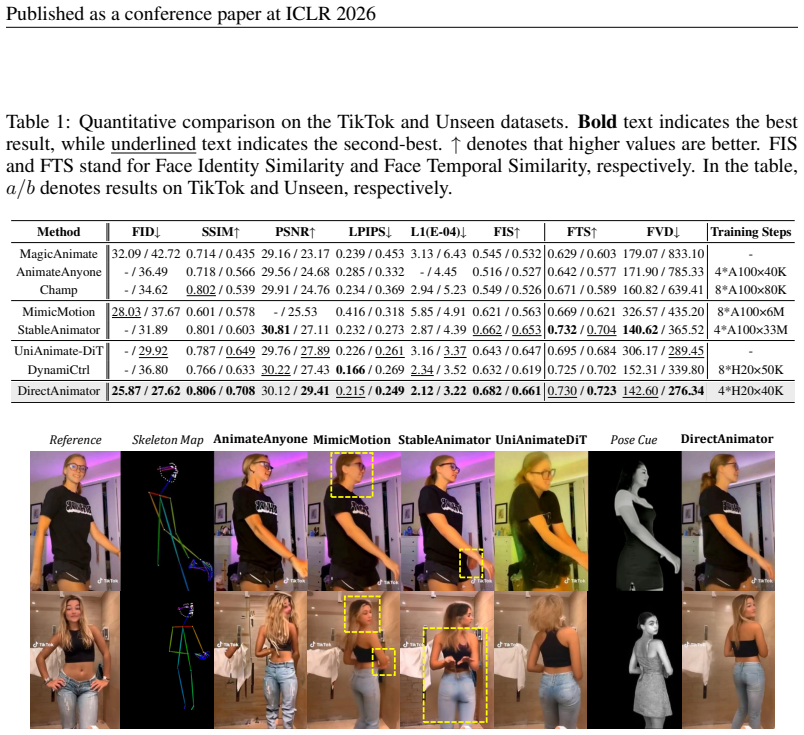
DirectAnimator bypasses pose extraction and directly learns from raw driving videos. It introduces a Driving Cue Triplet that captures motion, expression, and alignment, fused via a CueFusion DiT block for control during denoising. The Same2X training strategy aligns cross-ID features with same-ID data to regularize optimization. Experiments show it achieves state-of-the-art visual quality and identity preservation, robust to occlusions and complex articulation, with fewer computational resources.
What carries the argument
The Driving Cue Triplet of pose, face, and location cues fused through the CueFusion DiT block, regularized by the Same2X training strategy that aligns cross-identity learning.
If this is right
- Generated animations maintain higher visual quality and better identity preservation across different driving scenarios.
- Performance remains stable even with occlusions or intricate body movements in the driving video.
- Training and inference require fewer computational resources than methods relying on pose estimators.
- Convergence during optimization is faster due to the regularization effect of Same2X training.
Where Pith is reading between the lines
- The direct-from-video approach could reduce errors propagated from imperfect pose detectors in other video synthesis tasks.
- Such efficiency gains might allow deployment on consumer hardware for personalized animation creation.
- Future extensions could adapt the cue triplet concept to non-human subjects or 3D animation.
- By avoiding explicit skeletons, the method might handle stylistic or artistic driving videos more gracefully.
Load-bearing premise
The Driving Cue Triplet captures motion, expression, and alignment in a form stable enough to provide reliable control during denoising even across different identities.
What would settle it
Running the model on a set of driving videos with heavy occlusions or extreme poses and checking whether the output videos exhibit more artifacts or identity drift than a pose-based baseline.
Figures





read the original abstract
Human image animation aims to generate a video from a static reference image, guided by pose information extracted from a driving video. Existing approaches often rely on pose estimators to extract intermediate representations, but such signals are prone to errors under occlusion or complex poses. Building on these observations, we present DirectAnimator, a framework that bypasses pose extraction and directly learns from raw driving videos. We introduce a Driving Cue Triplet consisting of pose, face, and location cues that captures motion, expression, and alignment in a semantically rich yet stable form, and we fuse them through a CueFusion DiT block for reliable control during denoising. To make learning dependable when the driving and reference identities differ, we devise a Same2X training strategy that aligns cross-ID features with those learned from same-ID data, regularizing optimization and accelerating convergence. Extensive experiments demonstrate that DirectAnimator attains state-of-the-art visual quality and identity preservation while remaining robust to occlusions and complex articulation, and it does so with fewer computational resources. Our project page is at https://directanimator.github.io/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DirectAnimator, a framework for human image animation that bypasses pose estimators by learning animation signals directly from raw driving videos. It introduces a Driving Cue Triplet (pose, face, and location cues) fused through a CueFusion DiT block during denoising, along with a Same2X training strategy that aligns cross-identity features to same-identity data for regularization. The paper claims this yields state-of-the-art visual quality, identity preservation, robustness to occlusions and complex articulation, and reduced computational cost.
Significance. If the experimental claims hold, the work could meaningfully reduce dependence on error-prone intermediate pose representations in animation pipelines while providing a stable control mechanism via the cue triplet. The Same2X strategy addresses a practical cross-ID training challenge and may generalize to other conditional generation settings. No machine-checked proofs or parameter-free derivations are present.
major comments (2)
- [Abstract] Abstract: the central claims of state-of-the-art visual quality, identity preservation, robustness, and efficiency are asserted without any reported metrics, baselines, ablation studies, or quantitative results, leaving the primary empirical contribution unsupported by visible evidence.
- [Abstract] Abstract (and implied method): the Driving Cue Triplet and CueFusion DiT block are presented as enabling reliable control, yet no equations, extraction procedures, or architectural diagrams are supplied to allow verification that the cues are stable under occlusion or that the fusion mechanism avoids the very errors it claims to bypass.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We provide point-by-point responses to the major comments below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims of state-of-the-art visual quality, identity preservation, robustness, and efficiency are asserted without any reported metrics, baselines, ablation studies, or quantitative results, leaving the primary empirical contribution unsupported by visible evidence.
Authors: The abstract is intended as a concise summary of the work. Detailed quantitative results, including metrics, baselines, and ablations, are presented in the Experiments section (Section 5) of the manuscript. To better support the claims in the abstract, we will revise it to include key quantitative highlights from our experiments demonstrating the SOTA performance. revision: yes
-
Referee: [Abstract] Abstract (and implied method): the Driving Cue Triplet and CueFusion DiT block are presented as enabling reliable control, yet no equations, extraction procedures, or architectural diagrams are supplied to allow verification that the cues are stable under occlusion or that the fusion mechanism avoids the very errors it claims to bypass.
Authors: While the abstract offers a high-level overview, the full details are provided in the main text. Section 3.1 defines the Driving Cue Triplet and describes the extraction procedures for each cue. Section 3.2 presents the CueFusion DiT block with the corresponding equations for cue fusion during denoising. Figure 2 shows the architectural diagram. These sections explain how the approach maintains stability. No revision is required for this point. revision: no
Circularity Check
No significant circularity
full rationale
The abstract and available description introduce DirectAnimator, the Driving Cue Triplet, CueFusion DiT block, and Same2X strategy as novel components whose performance is asserted via experiments. No equations, self-citations, or derivations are supplied that reduce any claimed result to a fitted input or prior self-work by construction. The central claims remain framed as empirical outcomes rather than tautological redefinitions or renamings.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pose estimators are prone to errors under occlusion or complex poses
invented entities (3)
-
Driving Cue Triplet
no independent evidence
-
CueFusion DiT block
no independent evidence
-
Same2X training strategy
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127,
-
[2]
X-dyna: Expressive dynamic human image animation
Di Chang, Hongyi Xu, You Xie, Yipeng Gao, Zhengfei Kuang, Shengqu Cai, Chenxu Zhang, Guox- ian Song, Chao Wang, Yichun Shi, et al. X-dyna: Expressive dynamic human image animation. arXiv preprint arXiv:2501.10021,
-
[3]
Qijun Gan, Yi Ren, Chen Zhang, Zhenhui Ye, Pan Xie, Xiang Yin, Zehuan Yuan, Bingyue Peng, and Jianke Zhu. Humandit: Pose-guided diffusion transformer for long-form human motion video generation.arXiv preprint arXiv:2502.04847,
-
[4]
Yuwei Guo, Ceyuan Yang, Anyi Rao, Zhengyang Liang, Yaohui Wang, Yu Qiao, Maneesh Agrawala, Dahua Lin, and Bo Dai. Animatediff: Animate your personalized text-to-image diffu- sion models without specific tuning.arXiv preprint arXiv:2307.04725,
-
[5]
Dengyang Jiang, Mengmeng Wang, Liuzhuozheng Li, Lei Zhang, Haoyu Wang, Wei Wei, Guang Dai, Yanning Zhang, and Jingdong Wang. No other representation component is needed: Diffusion transformers can provide representation guidance by themselves.arXiv preprint arXiv:2505.02831,
-
[6]
Xingjian Leng, Jaskirat Singh, Yunzhong Hou, Zhenchang Xing, Saining Xie, and Liang Zheng. Repa-e: Unlocking vae for end-to-end tuning with latent diffusion transformers.arXiv preprint arXiv:2504.10483,
-
[7]
Anitalker: animate vivid and diverse talking faces through identity-decoupled facial motion encoding
11 Published as a conference paper at ICLR 2026 Tao Liu, Feilong Chen, Shuai Fan, Chenpeng Du, Qi Chen, Xie Chen, and Kai Yu. Anitalker: animate vivid and diverse talking faces through identity-decoupled facial motion encoding. In Proceedings of the 32nd ACM International Conference on Multimedia, pp. 6696–6705,
2026
-
[8]
Dreamactor-m1: Holistic, expressive and robust human image animation with hybrid guidance
Yuxuan Luo, Zhengkun Rong, Lizhen Wang, Longhao Zhang, Tianshu Hu, and Yongming Zhu. Dreamactor-m1: Holistic, expressive and robust human image animation with hybrid guidance. arXiv preprint arXiv:2504.01724,
-
[9]
Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193,
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193,
-
[10]
Grounded sam: Assembling open-world models for diverse visual tasks.arXiv preprint arXiv:2401.14159,
Tianhe Ren, Shilong Liu, Ailing Zeng, Jing Lin, Kunchang Li, He Cao, Jiayu Chen, Xinyu Huang, Yukang Chen, Feng Yan, et al. Grounded sam: Assembling open-world models for diverse visual tasks.arXiv preprint arXiv:2401.14159,
-
[11]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition, pp. 10684–10695, 2022a. Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High- resolutio...
Pith/arXiv arXiv 2010
-
[12]
Shuyuan Tu, Zhen Xing, Xintong Han, Zhi-Qi Cheng, Qi Dai, Chong Luo, and Zuxuan Wu. Stableanimator: High-quality identity-preserving human image animation.arXiv preprint arXiv:2411.17697,
-
[13]
Towards accurate generative models of video: A new metric & challenges
Thomas Unterthiner, Sjoerd Van Steenkiste, Karol Kurach, Raphael Marinier, Marcin Michalski, and Sylvain Gelly. Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:1812.01717,
-
[14]
Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314,
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314,
-
[15]
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024a. Tan Wang, Linjie Li, Kevin Lin, Yuanhao Zhai, Chung-Ching Lin, Zhengyuan Yang, Hanwang Zhang, Zicheng Liu,...
Pith/arXiv arXiv 2026
-
[16]
Yaohui Wang, Di Yang, Francois Bremond, and Antitza Dantcheva. Latent image animator: Learn- ing to animate images via latent space navigation.arXiv preprint arXiv:2203.09043,
-
[17]
X-portrait: Expres- sive portrait animation with hierarchical motion attention
You Xie, Hongyi Xu, Guoxian Song, Chao Wang, Yichun Shi, and Linjie Luo. X-portrait: Expres- sive portrait animation with hierarchical motion attention. InACM SIGGRAPH 2024 Conference Papers, pp. 1–11,
2024
-
[18]
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072,
-
[19]
Sihyun Yu, Sangkyung Kwak, Huiwon Jang, Jongheon Jeong, Jonathan Huang, Jinwoo Shin, and Saining Xie. Representation alignment for generation: Training diffusion transformers is easier than you think.arXiv preprint arXiv:2410.06940,
-
[20]
Shenghai Yuan, Jinfa Huang, Xianyi He, Yunyuan Ge, Yujun Shi, Liuhan Chen, Jiebo Luo, and Li Yuan. Identity-preserving text-to-video generation by frequency decomposition.arXiv preprint arXiv:2411.17440,
-
[21]
Yuang Zhang, Jiaxi Gu, Li-Wen Wang, Han Wang, Junqi Cheng, Yuefeng Zhu, and Fangyuan Zou. Mimicmotion: High-quality human motion video generation with confidence-aware pose guid- ance.arXiv preprint arXiv:2406.19680,
-
[22]
Haoyu Zhao, Zhongang Qi, Cong Wang, Qingping Zheng, Guansong Lu, Fei Chen, Hang Xu, and Zuxuan Wu. Dynamictrl: Rethinking the basic structure and the role of text for high-quality human image animation.arXiv preprint arXiv:2503.21246,
-
[23]
Open-sora: Democratizing efficient video production for all
Zangwei Zheng, Xiangyu Peng, Tianji Yang, Chenhui Shen, Shenggui Li, Hongxin Liu, Yukun Zhou, Tianyi Li, and Yang You. Open-sora: Democratizing efficient video production for all. arXiv preprint arXiv:2412.20404,
-
[24]
Jingkai Zhou, Benzhi Wang, Weihua Chen, Jingqi Bai, Dongyang Li, Aixi Zhang, Hao Xu, Mingyang Yang, and Fan Wang. Realisdance: Equip controllable character animation with real- istic hands.arXiv preprint arXiv:2409.06202,
-
[25]
Champ: Controllable and consistent human image animation with 3d parametric guidance
Shenhao Zhu, Junming Leo Chen, Zuozhuo Dai, Yinghui Xu, Xun Cao, Yao Yao, Hao Zhu, and Siyu Zhu. Champ: Controllable and consistent human image animation with 3d parametric guidance. arXiv preprint arXiv:2403.14781,
-
[26]
13 Published as a conference paper at ICLR 2026 A APPENDIX In this appendix, we first present the foundational concepts and diffusion-based architectures in Section A.1. Section A.2 then provides an in-depth description of our Driving Cue representation, including the effect of low-pass filtering on pose cues, how spatial alignment is learned from pseudo ...
2026
-
[27]
present a fully Transformer-based backbone for diffusion models, replacing the conventional convolutional U-Net architecture. Built upon the latent space framework of Stable Diffusion (Rombach et al., 2022b), DiT processes image representations encoded by a fixed V AE encoder into low-dimensional fea- ture maps. These latent tensors are segmented into non...
2026
-
[28]
emerges as a scalable and high-performing diffusion Transformer architecture tailored for long-duration, text-conditioned video generation. Built upon the Diffusion Transformer (DiT) backbone (Peebles & Xie, 2023), CogVideoX integrates several critical innovations that address longstanding challenges in temporal coherence and cross-modal alignment. To eff...
2023
-
[29]
To further suppress redundant information, we apply a low-pass filter in the frequency domain to eliminate high-frequency image details
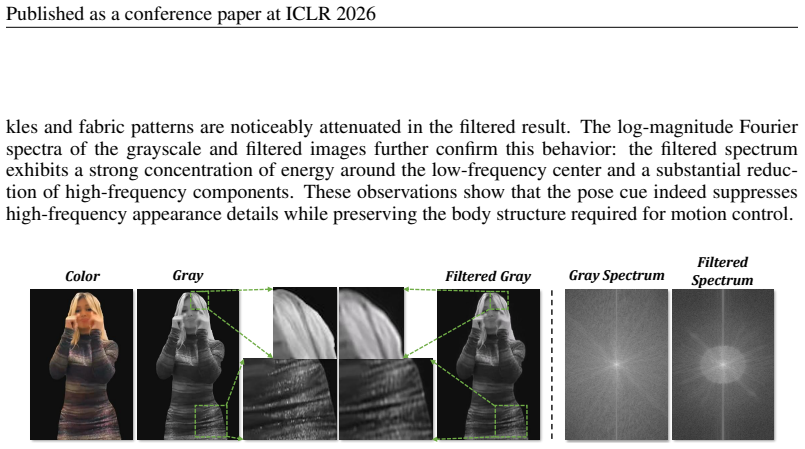
to segment out the foreground human subject. To further suppress redundant information, we apply a low-pass filter in the frequency domain to eliminate high-frequency image details. The resulting foreground image is used as the Pose Cue. While most prior methods adopt 68 facial landmarks as the driving signal for expression transfer, such sparse represent...
2025
-
[30]
to the pose and face masks in the driving video, aligning their spatial layout and scale with that of the reference identity. To prevent potential information leakage during training, we further apply a grid-based softening operation on the pose mask, blurring the mask boundaries while retaining the coarse silhouette. These aligned pose and face masks tog...
2026
-
[31]
In addition to the data used for same-ID training, we collect an extra set of 1,000 images featuring diverse identities as the pseudo reference set
and MimicMotion (Zhang et al., 2024), two of the most competitive human image animation methods to date. In addition to the data used for same-ID training, we collect an extra set of 1,000 images featuring diverse identities as the pseudo reference set. For each driving video sampled from the same-ID training set, we randomly select 0 to 3 images from the...
2024
-
[32]
and compute the average cosine similarity between corresponding pairs.Face Temporal Similarity (FTS)measures how temporally consistent the facial appearance remains within a generated video. We compute face embeddings for each frame using ArcFace and average the cosine similarity between embeddings of adjacent frames.Pose Landmark Consistency (PLC)measure...
2026
-
[33]
Third, low video quality also degrades performance. For example, poor lighting conditions as in Case 3(1) or low spatial resolution as in Case 3(2) make it difficult to accurately infer the subject’s motion, resulting in noticeably lower animation quality. A.7 LIMITATIONS ANDFUTUREWORK While DirectAnimator demonstrates strong performance across various be...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.