World Feedback for Clinical Agents: Diagnosing RL in FHIR Environments
Pith reviewed 2026-07-03 20:12 UTC · model grok-4.3
The pith
Pure RL reaches 18.2% on clinical FHIR tasks while rule-based SFT reaches 34.1%, with the entire gap due to tasks offering zero gradient or undiscoverable codes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
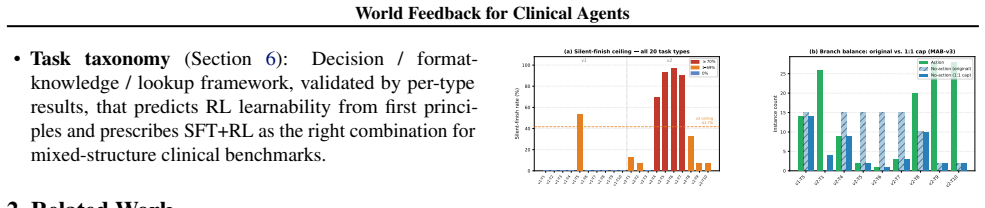
Pure RL reaches 18.2% pass@1 vs. 34.1% for rule-based SFT; the 15.9 pp gap is attributable entirely to these barriers. A decision/format-knowledge/lookup taxonomy predicts RL learnability and prescribes the fix: SFT to inject codes, RL to learn conditionals.
What carries the argument
The decision/format-knowledge/lookup taxonomy that classifies tasks to predict when RL can succeed from world feedback alone.
Load-bearing premise
The twenty task types and the 8.9% silent-finish ceiling in the revised benchmark are representative of real clinical protocol-execution challenges and do not introduce selection effects that would change the measured gap between RL and SFT.
What would settle it
Running the same RL and SFT comparison on a benchmark variant in which every task type has positive base performance and every required clinical code is either supplied or discoverable by the base model.
Figures

read the original abstract
Clinical protocol-execution tasks -- checking a lab value, applying a threshold, placing a correctly structured FHIR order -- are natural candidates for RL from world feedback: once clinical SMEs encode decision logic into a verifier, that verifier grades unlimited rollouts without per-episode annotation. But applying RL requires a sound feedback channel and sufficient base capability. We audit MedAgentBench v1/v2, find a 41.7\% silent-finish ceiling that makes inaction the RL dominant strategy, and construct \textbf{MedAgentBench-v3 (MAB-v3)} (508 tasks, 8.9\% ceiling). Training Qwen3-8B exposes two structural barriers: a \emph{capability ceiling} (10/20 task types have 0\% base performance, zero gradient) and a \emph{format-knowledge barrier} (3/20 types require exact clinical codes undiscoverable by exploration). Pure RL reaches 18.2\% pass@1 vs.\ 34.1\% for rule-based SFT; the 15.9~pp gap is attributable entirely to these barriers. A decision/format-knowledge/lookup taxonomy predicts RL learnability and prescribes the fix: SFT to inject codes, RL to learn conditionals.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper audits MedAgentBench v1/v2 for a 41.7% silent-finish ceiling that favors inaction in RL, constructs MAB-v3 (508 tasks, 8.9% ceiling), and trains Qwen3-8B to show pure RL reaching 18.2% pass@1 versus 34.1% for rule-based SFT. It attributes the entire 15.9 pp gap to a capability ceiling (10/20 task types at 0% base performance) and format-knowledge barrier (3/20 types requiring undiscoverable codes), proposing a decision/format-knowledge/lookup taxonomy that predicts RL learnability and prescribes SFT for codes plus RL for conditionals.
Significance. If the attribution and representativeness hold, the work supplies a concrete diagnostic framework and falsifiable taxonomy for when world feedback suffices for clinical agents, crediting the explicit per-type breakdown and empirical comparison on the constructed benchmark. This could guide hybrid training in FHIR settings and highlights the prerequisite of base capability before RL.
major comments (3)
- [Abstract and Benchmark Construction] Abstract and Benchmark Construction: The claim that the 15.9 pp gap is 'attributable entirely' to the two barriers rests on the 20 task types and 508 tasks being representative of clinical protocol execution; no sampling method, real-world FHIR distribution comparison, or selection-effect analysis is supplied, which is load-bearing for the 'entirely' qualifier and the taxonomy's predictive power.
- [Results] Results: The 18.2% RL and 34.1% SFT figures, the 41.7% to 8.9% ceiling reduction, and the 10/20 + 3/20 breakdowns are stated without per-type tables, variance, seed count, or evaluation protocol, preventing verification that the gap is fully explained by zero-gradient and undiscoverable-code cases rather than other factors.
- [Experimental Setup] Experimental Setup: The assertion that codes are 'undiscoverable by exploration' for the 3 types and that 10 types have zero gradient requires explicit confirmation that exploration budgets and training were sufficient to establish non-learnability; absent this, the taxonomy cannot be confirmed as predictive.
minor comments (2)
- [Abstract] The pass@1 metric is used without a brief definition or reference in the abstract.
- [Abstract] FHIR is not expanded on first use.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and have revised the manuscript accordingly to improve clarity, reporting, and qualification of claims.
read point-by-point responses
-
Referee: [Abstract and Benchmark Construction] Abstract and Benchmark Construction: The claim that the 15.9 pp gap is 'attributable entirely' to the two barriers rests on the 20 task types and 508 tasks being representative of clinical protocol execution; no sampling method, real-world FHIR distribution comparison, or selection-effect analysis is supplied, which is load-bearing for the 'entirely' qualifier and the taxonomy's predictive power.
Authors: We acknowledge that the 'entirely' phrasing depends on the representativeness of the 20 task types. These types were selected to span core clinical protocol elements (lab checks, thresholds, structured orders) drawn from FHIR workflows, but no formal sampling frame or real-world distribution comparison was performed. In revision we have changed the claim to 'primarily attributable within the benchmark' , added a task-selection subsection describing curation criteria, and inserted a limitations paragraph on generalizability. The taxonomy is presented as a predictive framework to be validated on further tasks rather than a universal proof. revision: partial
-
Referee: [Results] Results: The 18.2% RL and 34.1% SFT figures, the 41.7% to 8.9% ceiling reduction, and the 10/20 + 3/20 breakdowns are stated without per-type tables, variance, seed count, or evaluation protocol, preventing verification that the gap is fully explained by zero-gradient and undiscoverable-code cases rather than other factors.
Authors: We agree that verification requires these details. The revised manuscript adds full per-type tables for RL and SFT, reports means and standard deviations across five random seeds, and expands the evaluation protocol section with episode counts, pass@1 definition, and ceiling-calculation method. These additions confirm the gap aligns with the zero-gradient and format-knowledge cases. revision: yes
-
Referee: [Experimental Setup] Experimental Setup: The assertion that codes are 'undiscoverable by exploration' for the 3 types and that 10 types have zero gradient requires explicit confirmation that exploration budgets and training were sufficient to establish non-learnability; absent this, the taxonomy cannot be confirmed as predictive.
Authors: We have expanded the experimental setup to report the precise exploration budgets (1000 episodes per task type), training hyperparameters, and the operational definition of zero gradient (no reward improvement after the budget). For the three format-knowledge types we include summary statistics from the exploration runs showing that the required codes were never emitted despite the budget, thereby supporting the non-learnability classification within the tested regime. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper reports an empirical performance comparison (pure RL at 18.2% pass@1 vs. rule-based SFT at 34.1%) on the explicitly constructed MAB-v3 benchmark of 508 tasks. The identified barriers (10/20 task types at 0% base performance; 3/20 requiring undiscoverable codes) and the taxonomy are derived from direct inspection of those tasks and the observed silent-finish rates, not from any equation or self-citation that reduces the gap to a fitted parameter or prior result by construction. The central attribution remains an external measurement on the benchmark rather than a self-definitional or load-bearing self-citation reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Clinical SMEs can encode decision logic into a verifier that grades unlimited rollouts without per-episode annotation.
Reference graph
Works this paper leans on
-
[1]
2025 , howpublished=
Is Your. 2025 , howpublished=
2025
-
[2]
Advances in Neural Information Processing Systems , volume=
Deep Reinforcement Learning from Human Preferences , author=. Advances in Neural Information Processing Systems , volume=
-
[3]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
DAPO: An Open-Source LLM Reinforcement Learning System at Scale , author=. arXiv preprint arXiv:2503.14476 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
ICLR , year=
LoRA: Low-rank adaptation of large language models , author=. ICLR , year=
-
[7]
2025 , note=
Qwen3 Technical Report , author=. 2025 , note=
2025
-
[8]
MedAgentBench: A Virtual
Jiang, Yixing and Black, Kameron C and Geng, Gloria and Park, Danny and Zou, James and Ng, Andrew Y and Chen, Jonathan H , journal=. MedAgentBench: A Virtual. 2025 , publisher=
2025
-
[9]
2025 , organization=
Chen, Eric and Postelnik, Sam and Black, Kameron and Jiang, Yixing and Chen, Jonathan H , booktitle=. 2025 , organization=
2025
-
[10]
Advances in Neural Information Processing Systems , volume=
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
ICML , year=
Scaling Laws for Reward Model Overoptimization , author=. ICML , year=
-
[12]
Some things are more CRINGE than others: Iterative Preference Optimization with the Pairwise Cringe Loss , author=. arXiv preprint arXiv:2312.16682 , year=
-
[13]
Bedi, Suhana and Welch, Ryan and Steinberg, Ethan and Wornow, Michael and Kim, Taeil Matthew and Ahmed, Haroun and Sterling, Peter and Purohit, Bravim and Akram, Qurat and Acosta, Angelic and others , journal=
-
[14]
Lee, Gyubok and Bach, Elea and Yang, Eric and Pollard, Tom and Johnson, Alistair and Choi, Edward and Lee, Jong Ha and others , journal=
-
[15]
arXiv preprint arXiv:2602.05547 , year=
Multi-Task GRPO: Reliable LLM Reasoning Across Tasks , author=. arXiv preprint arXiv:2602.05547 , year=
-
[16]
GDPO: Group reward-Decoupled Normalization Policy Optimization for Multi-reward RL Optimization
GDPO: Group-Decoupled Policy Optimization for Language Model Alignment , author=. arXiv preprint arXiv:2601.05242 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Findings of the Association for Computational Linguistics: EACL 2026 , pages=
Imbalanced gradients in rl post-training of multi-task llms , author=. Findings of the Association for Computational Linguistics: EACL 2026 , pages=
2026
-
[18]
Proceedings of the National Academy of Sciences , volume=
Overcoming catastrophic forgetting in neural networks , author=. Proceedings of the National Academy of Sciences , volume=
-
[19]
Advances in Neural Information Processing Systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in Neural Information Processing Systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.